手写Spring,理解SpringBean生命周期
按照Spring使用习惯,准备环境
首先,写一个TigerApplicationContext,模拟Spring的Annotation Application。然后写一个config,接着写一个UserService。


由于Spring需要扫描bean,所以我们得定义一个扫描注解ComponentScan,如下:

有了这个扫描注解,我们就可以模拟spring,在config类上写我们需要的扫描路径,如下:
由于我们还需要扫描Service类,所以还需定义一个注解:@Component

通过上面的一些步骤,基本把我们平时该做的一些步骤都设置好了,
例如,通过注解@Component,让Spring扫描,通过在main函数中,获取Spring容器上下文,使用如下语句:
TigerApplicationContext applicationContext = new TigerApplicationContext(AppConfig.class);
以及通过如下语句,从容器中获取bean.
UserService userService = (UserService)applicationContext.getBean("userService");
Spring 扫描字节码文件
但是,我们要知道,这些注解,只是作为给代码看的注释,实际并没有什么真正的作用。像上面的注解:@ComponentScan(“com.tiger.service”),只是告诉Spring需要扫描的路径是:com.tiger.service,至于要怎么扫描,还得通过Spring来实现。下面就说一下,TigerApplicationContext是怎么实现的。
在创建Spring容器的过程中,需要创建非懒加载的单例bean。这个过程是在下面构造方法的过程中实现的:
TigerApplicationContext applicationContext = new TigerApplicationContext(AppConfig.class);
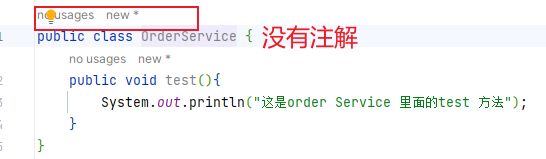
你让Spring去创建单例bean(通过类的构造函数),那么我得知道哪些是要创建的,那么怎么找到他们?比如说,系统里面有个OrderService类,什么东西也没有加,它就是一个普通的Java类,如下:

所以,Spring得通过扫描注解,才能知道哪些是归Spring容器管理的。那么怎么去扫描呢?
上面的AppConfig类已经很明确的说了,需要在路径com.tiger.service下扫描。扫描的时候,只要加了@Component注解,都需要Spring去创建Bean。
下面看下,在TigerApplicationContext中,是怎么进行扫描的。

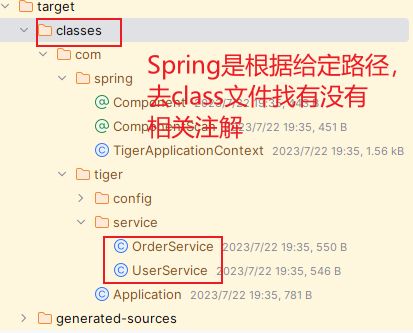
好了,通过上面的步骤,我们拿到了扫描路径:com.tiger.service。Spring就是通过解析包路径:com.tiger.service下的类,看看这些类上面,是否有注解。当前我们的项目中,有两个类:OrderService、UserService,由于OrderService没有对应的注解,所以它不是bean。
我们要取的是编译后的class文件。那我们怎么拿到呢?通过class loader去加载Java字节码文件。
java 的类加载系统,分三大类:bootstrap,extend,app。我们程序中的TigerApplicationContext.class 是由App Class loader加载的。
从idea的控制台可以看出,指定的classpath:D:\code\TigerSpring\TigerSpring\target\classes

所以,通过ClassLoader classLoader = TigerApplicationContext.class.getClassLoader(); 来获取对应的类加载器。因为获取到路径是带点号(.)的,但是我们现在是要去文件系统找,所以我们转换一下,把点(.)换成斜杆:path = path.replace(“.”, “/”);

所以通过相对路径,很快就找到了Service文件夹。下面就把resource转换成File 对象,然后再通过File,拿到类的绝对路径。到这里,结合绝对路径,其实可以通过ASM技术操作字节码。但我们本次不使用这个ASM,而是使用Class Loader。

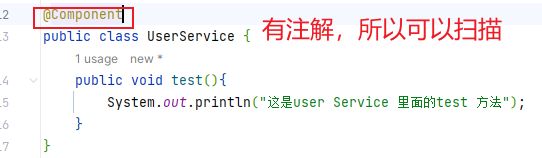
通过Class Loader获取到Class对象,然后再通过class的方法,判断当前的类是否含有@Component注解,如下,打印出了含有注解的类。

而order Service因为没有注解,所以没扫描出来。
那到了这里,可以直接创建bean了吗?还不行,还要判断,他是单例bean,还是原型bean。那怎么判断呢?我们这里新加一个@Scope注解,然后把这个注解添加到类中,如下所示:


接下来就是对@Scope注解写逻辑,通过class判断这个类,有没有使用@Scope注解,主要逻辑如下:

我们先跳过Scope判断逻辑,回到创建bean的地方:

传进来一个字符串,返回一个对象,实现逻辑是什么呢?看一下getBean方法:

大概逻辑可以是这样子:通过字符串bean name,然后扫描文件,再去获取user service的class文件,这个步骤(扫描、加载字节码文件),跟上面扫描注解的步骤,是重复的,由此,我们引入BeanDefinition的概念。
引入BeanDefinition
BeanDefinition主要说明一个bean的类型是什么,作用域是什么(单例还是原型),bean是否是懒加载的,具体bean定义如下:

这个bean的定义,是定义所有bean通用的属性。
所以,到这里,我们再回到那个Component注解判断的地方,如果判断了这是一个bean(即使用了@Component注解),那么,就得定义一下BeanDefinition,如下:

由于在扫描方法里面,要扫描整个项目的字节码文件,所用使用的是for循环(有很多的意思),所以我们要把定义好的BeanDefinition放到一个map里面存储,后面我们创建bean的时候,就从这个map里面获取。

小结
传入配置类,获取到配置类上面的扫描路径:com.tiger.service,然后根据扫描路径,去遍历路径下面的每个class文件,通过class loader加载每个class字节码文件,得到一个class对象,得到class对象之后,判断有没有对应的从@Component注解,如果有注解,则定义对应BeanDefinition,然后把BeanDefinition存入到一个map中,这就是扫描包做的事情。
引入单例池
接下来说创建bean。
创建的时候,先做异常判断。由于上面在扫描的时候,我们已经把所有的注解,都扫描出来,放入map里面了。如果bean的名字这个key不在BeanDefinition的keyset中,那么说明这个bean是一个非法的,不存在的bean,所以可以直接把异常抛出来,如下:
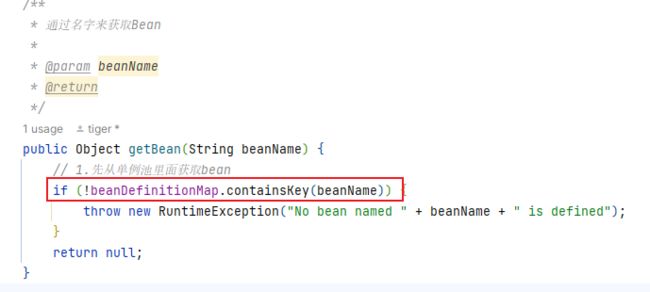
如果map里面有这个beanName的key,就接着判断,它是单例的,还是原型的。如果是原型的,直接创建。
为了达到复用的目的,我们不直接在getBean(String beanName)这个方法里面直接创建bean,而是新建一个createBean(String beanName, BeanDefinition beanDefinition)方法。因为单例bean只创建一次,所以在创建的时候,我们可以使用一个map来存储:
private Map<String, Object> singletonObjects = new HashMap<>();
由于我们所有的bean定义在beanDefinitionMap已经有了,我们再次遍历这个map,把所有单例bean拿出来,然后新建,并存入单例map: singletonObjects ,如下:

所以,再回到getBean(String beanName)方法:当判断是单例bean的时候,直接从singletonObjects 中根据bean name 从map取出即可,如果是原型的bean,那么直接调用createBean(String beanName, BeanDefinition beanDefinition) 方法。通过这样子,方法createBean就可以被重用了,拆解成小的函数,便于代码重用。

通过上面,就完整解释了,怎么获取bean。
创建Bean
接下来,说说怎么创建bean,也就是方法:createBean(String beanName, BeanDefinition beanDefinition)
先来个简单版的创建bean:

直接通过class的无参构造函数获取对象。
在main函数运行结果如下:

我们使用orderService再测试一下,给它加上 对应的注解:

在main函数中从容器获取OrderServicebean,并打印,结果如下:

看看OrderService,只有注解,注解里面并没有给bean加名字,和userService有点不一样。


所以,在扫描注解,发现有@Component注解的时候,如果发现没有名字,那就默认给它生成一个名字。

在运行代码,不报错了,如下:

属性注入:引入新的注解@Autowire
我们把orderService注入到userService中,看看打印结果:

打印出来orderService是空值。
下面说说怎么把orderService注入UserService。
![]()
按照这个逻辑,通过无参构造函数得到一个对象之后,就开始依赖注入,如下:

注:图怕中有错别字,兑现---->应该是对象
那我要注入什么东西?通过class对象,可以获取到这个类有哪些属性,遍历一下这些属性,看看哪个属性是有@Autowire注解的,如下:
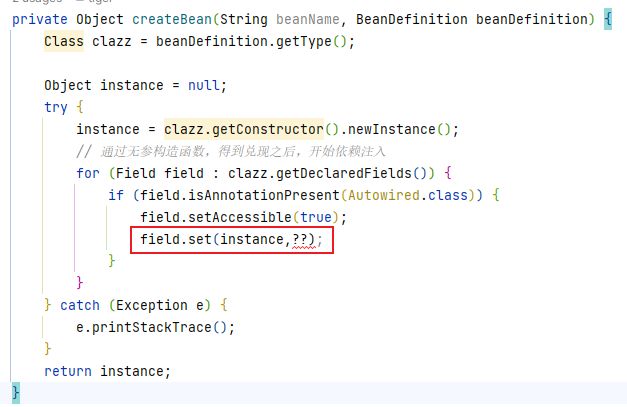
拿到Autowire注解之后,要给这个属性注入什么内容呢?问号这里该给一个什么值?可以根据当前属性的bean类型(也就是UserService这个类的OrderService这个类型)去单例池找,但是,这个时候,orderService在容器中,可能还没有创建好,那此时,只能依赖BeanDefinition。这里先忽略,默认容器中已经有orderService这个bean。但是,如果容器中有多个orderService的bean,那就先通过名字找。找的过程是这样,先根据类型,如果多个,则在根据名字找bean。
综上所述,这里简单点,直接通过名字找bean,调用getBean方法,传入属性名字,如下:

但是,这里可能有一个问题,就是,在调用getBean方法的时候,有可能获取不到。
我们重新梳理一下整个流程。
假设我们在扫描bean的时候,是先创建的UserService这个bean,然后给它的属orderService性赋值,但是这个时候,OrderService并没被扫描到,还没成为Spring IOC容器中的一个bean,那怎么办呢?那上面获取bean的时候,就会返回空,所以我们得加一个判断,如下:

此时,在运行代码,可以看到orderService已经注入到UserService中,如下:

初始化:实现InitializingBean接口
沿着主线继续讲,依赖注入完之后,开始初始化。
![]()
我们下面接着模拟InitializingBean接口,接口定义如下:
public interface InitializingBean {
void afterPropertiesSet();
}
然后让UserService实现接口InitializingBean并重写方法: afterPropertiesSet(),如下:
@Component("userService")
@Scope("prototype")
public class UserService implements InitializingBean {
@Autowired
private OrderService orderService;
public void test(){
System.out.println("这是user Service 里面的test 方法");
System.out.println("打印orderService属性:"+ orderService);
}
@Override
public void afterPropertiesSet() {
}
}
接下来我们把InitializingBean的功能实现一下。这个过程,还是在创建bean的时候实现的,具体代码如下:
判断当前这个bean的实例是否实现了接口InitializingBean,如果实现了,就把bean强制转换为InitializingBean,然后调用afterPropertiesSet方法
if (instance instanceof InitializingBean){
((InitializingBean)instance).afterPropertiesSet();
}
在任意一个bean(UserService)里面实现InitializingBean接口,Spring就会自动的去调用afterPropertiesSet()方法,这就是初始化的一个简单实现。
初始化前、初始化后:BeanPostProcessor
接下来再讲另外一个重点:BeanPostProcessor,这是我们仿造Spring BeanPostProcessor的一个接口。
public interface BeanPostProcessor {
default Object postProcessBeforeInitialization(Object bean, String beanName) {
return bean;
}
default Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}
Spring提供了接口BeanPostProcessor,我们就可以去弄一个它的实现类,如下:
public class TigerBeanPostProcessor implements BeanPostProcessor{
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}
类TigerBeanPostProcessor重写了初始化后的方法,那么我们就可以在方法:postProcessAfterInitialization()随意写我们想要实现的逻辑。
这里的逻辑,应该在bean初始化之后调用的。那我们要使用下面的方式调用吗?

这种方式,就是把我们的代码,直接写死到Spring源码里面,肯定不行。
换另外一种方式,使用接口。
大体的思路是这样的:我们不能直接把TigerBeanPostProcessor写死到Spring源码中,但可以通过它的接口:BeanPostProcessor。但是,Spring怎么知道我们有TigerBeanPostProcessor这个类呢?通过注解@Component,如下:

然后回到扫描逻辑,再看方法scan(configClass);
当Spring扫描到有Component注解之后,会判断是否实现了BeanPostProcessor接口,判断方式如下:

如果类实现了接口,那么再通过class获取到类的无参构造函数,从而new一个实例对象出来,这样,通过
BeanPostProcessor instance = (BeanPostProcessor)clazz.getConstructor().newInstance();
就可以替代上面写的硬编码,轻松解耦,不用在Spring源码中new 我们自己业务的实现类。

这个过程是在扫描的方法里面的,但是我们是在创建bean的时候用的,所以,需要把它缓存起来,这个时候,需要新增一个list: beanPostProcessorList接收它。
private List<BeanPostProcessor> beanPostProcessorList = new ArrayList<>();
if (BeanPostProcessor.class.isAssignableFrom(clazz)) {
BeanPostProcessor instance = (BeanPostProcessor)clazz.getConstructor().newInstance();
beanPostProcessorList.add(instance);
}
小结:
在扫描的时候,会额外的生成一些beanDefinition,然后存起来,然后呢,这里扫描又额外的做了一些事情,发现如果bean实现了接口BeanPostProcessor,也会把它存起来。

现在通过beanPostProcessorList,我们就可以获取到整个容器中,实现了BeanPostProcessor的实例了。
基于BeanPostProcessor的Spring AOP
Spring AOP的底层是基于BeanPostProcessor来实现的。下面来具体说说。
写一个接口:UserInterface
public interface UserInterface {
public void testAop();
}
然后让UserService实现这个接口,有了接口之后,就可以使用JDK的动态代理了。

回到TigerBeanPostProcessor,写动态代理逻辑,也就是切面逻辑:
@Component
public class TigerBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
System.out.println("BeanPostProcessor相关的");
Object proxyInstance = Proxy.newProxyInstance(bean.getClass().getClassLoader(), bean.getClass().getInterfaces(), new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("在调用原始方法之前,执行切面逻辑。。。");
return method.invoke(bean,args);
}
});
return proxyInstance;
}
}
使用Proxy的静态方法newProxyInstance(ClassLoader loader,Class[] interfaces,InvocationHandler h)生成一个代理对象,返回值:proxyInstance就是生成的代理对象。在这里我们可以看到,最后面返回给容器的bean,是代理对象!
返回到主函数看看执行效果:

Spring的这个BeanPostProcessor机制非常的牛逼,我们可以基于这个机制,做很多的事情。
例如下面的需求:
我希望在项目中定义一个注解:@TigerValue,使用这个注解后,能把注解里面的value,赋值对加了这个注解的属性。
新增了注解,并运行项目,发现获取到空值:
运行程序:

下面是实现逻辑。增加一个bean初始化前的实现类。
@Component
public class TigerValueBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
for (Field field : bean.getClass().getDeclaredFields()) {
if (field.isAnnotationPresent(TigerValue.class)) {
field.setAccessible(true);
try {
// 把注解里面的值,赋值给变量
field.set(bean, field.getAnnotation(TigerValue.class).value());
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
return bean;
}
}
然后在创建bean之前,调用这个TigerValueBeanPostProcessor实例方法,具体逻辑,跟上面那个初始化后的操作一样,只不过位置放在了bean初始化之前,如下所示:

我们实现BeanPostProcessor接口里面的两个方法,相当于在Spring注册了两个回调函数。当Spring在创建bean的时候,执行到BeanPostProcessor相关的逻辑,就会调用我们实现类里面具体的逻辑。

总结
在main函数中,通过TigerApplicationContext的构造函数,拿到配置类上的扫描路径,然后就去编译好的class文件中扫描,看看哪些类使用了注解。在扫描的过程中,会生成一个BeanDefinition map,把生成的的BeanDefinition 放入Map中,这个map在后面创建bean的时候会用到。此外,在扫描的过程中,还会检查类中是否实现了BeanPostProcessor接口,如果实现了,就把实例化的对象放入到List 中,这个list也是在创建bean的过程中会使用。此外,扫描的时候,还会检查这个是不是单例bean,如果是单例bean,就放入到Map: Map
所以,扫描主要做三件事情:生成BeanDefinition ,放入map;把实例化的BeanPostProcessor,放入list;把单例放入Map。
然后开始创建bean。先看下是否有Autowire注解,如果有,从容器中获取bean,注入到属性中然后再看看是否实现了BeanPostProcessor接口,如果实现了,就执行接口的实现方法里面的逻辑,最后生成一个bean实例。这个bean实例,如果有做AOP的话,那么生成的代理对象才是最后返回的bean。