python 数据分析面试题:求分组排第n名的记录数据
近期面试遇到一个面试题,分享给大家。
文中会提供详细的解题思路以及问题延伸
一、面试题
- 面试题:输出各学科总分第一名的学员姓名、年龄、分数
- 数据:
class_a= {'name': ['学员1', '学员2', '学员3', '学员4','学员5'],
'age': [23, 24, 26, 27,25],
'course_subject': ['数学', '英语', '语文', '语文','数学'],
'score': [100,50,40,30,99]}
class_b= {'name': ['学员6', '学员7', '学员8', '学员9'],
'age': [23, 24, 26, 27],
'course_subject': ['数学', '数学', '语文', '英语'],
'score': [18,99,77,30]}
二、解题过程
- 字典转变为DataFrame,合并,重置索引
df_a = pd.DataFrame(class_a)
df_b = pd.DataFrame(class_b)
df = pd.concat([df_a,df_b])
df.reset_index(drop=True,inplace=True)

- groupby分组 + labmda函数 得出结果
df.idxmax() :该函数作用是返回每一列中最大值的索引(所以为什么前文的数据处理中需要重置索引)。
df.groupby('course_subject').apply(lambda x: x.loc[x['score'].idxmax(), ['name', 'age', 'score']])
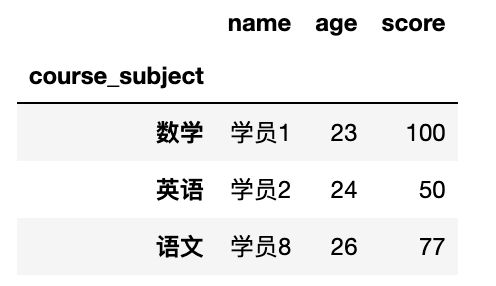
延伸:df.idxmin() 取最小
df.nlargest():返回指定列排序后的前 N 个最大值所对应的行。
df.groupby('course_subject').apply(lambda x: x.nlargest(1, 'score'))[['name','age']]

注意⚠️:遇到相同值的情况,返回结果可能与预期不一致,如原数据中,数学成绩=99的有两位学员,此时当n=2时,只返回其中一位学员的记录;n=3才会返回两位学员的记录数。
所以,如果某一课程中,有两位学员都获得100分,那么此方法并不能解决该面试题。
 (n=2)
(n=2)
df.rank():排名函数
df.groupby('course_subject').apply(
lambda x:x.loc[
x['score'].rank(ascending=False,method='min')==1,
['name', 'age', 'score']
]
)

说明:method='min'主要是考虑遇到同值的情形,详解参考:python Pandas.rank() 排名函数详解
延伸:该方法可以延伸至求分组排名、分组排第n名的记录数据等问题,是比较完善的答案。
当然,还有其他解决方法,欢迎大家留言补充~