PostgreSQL:使用 JSON 函数和正则表达式,带你轻松高效处理半结构化数据
目录
- 一、前言
- 二、JSON 数据处理场景
-
- 2.1 场景一:JSON 取值
- 2.2 场景二:拆分键值对
- 2.3 场景三:拆分字符串
- 2.4 场景四:批量匹配字符串
- 三、总结
一、前言
Postgresql是一款功能强大、易于使用、稳定可靠的关系型数据库管理系统,广泛应用于各种规模的企业级应用中。
它采用了面向对象的数据模型,提供了丰富的扩展性和灵活性
- 支持复杂的查询和操作,包括全文搜索、JSON数据处理和事务处理等功能。
- 支持数据分析、图形处理、时间序列分析等高级功能,
- 支持数据备份和恢复、数据分片、水平扩展等功能,可以帮助企业有效地管理和维护海量数据。
- 支持高并发、高性能的数据读写,能够处理大量的数据,而且非常稳定可靠。
此外,Postgresql还有着广泛的社区支持和生态系统,可以方便地与其他开源工具和应用程序集成。
本文主要介绍这两天在开发一些数据模型的时候,遇到的一些数组的处理。
环境:postgresql 14.1, windows 11
二、JSON 数据处理场景
在处理数据之前,首先需要有 JSON 数据,先介绍两个生成 JSON 类型数据的方法:::json和to_json()。二者有一些区别:
::json:要求被转化的字段有严格的 JSON 格式,而且必须是字符串;to_json():被转化的字段,除了字符串,还支持数值、数组等。
举例说明:
使用::json将字符串'["12","ab"]'转化为一个 JSON 类型的值:
select '["12","ab"]'::json ary;

取第一个值:
使用to_json()将数组array['12','ab']转化为一个 JSON 类型的值:
select to_json(array['12','ab']) ary;

取第一个值
了解这两个方法之后,下面分四个场景来叙述
2.1 场景一:JSON 取值
任务一:提取字符串'{"a":"1","b":"2"}'中键a对应的值。
这个相对比较简单,上面已经基本介绍过相关的取值方法了,就是使用->>进行取值。SQL 如下:
select '{"a":"1","b":"2"}'::json->>'a' as "a值";
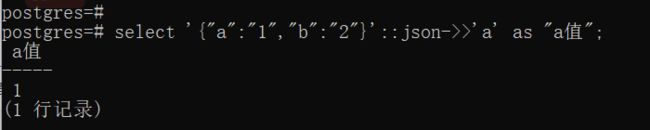
需要留意的就是,使用该方法返回的是一个 text 类型,如果要返回的是一个 JSON 类型,使用->,SQL 如下:
select '{"a":"1","b":"2"}'::json-> 'a' as "a值";

任务二:提取字符串'[{"a":"1","b":"2"}]'中键a对应的值。
这个多嵌套了一层,所以取值的时候也需要多取一层,取法如下:
需要注意的是,第一层需要使用->,返回 JSON 类型,以便可以继续取值。不管是数组结果还是键值对结构,都是使用->和->>取值,前者返回 JSON 类型,后者返回 TEXT 类型。
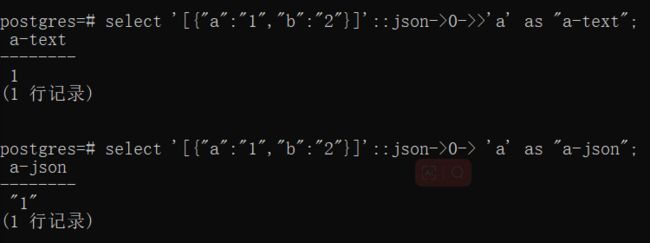
select '[{"a":"1","b":"2"}]'::json->0->>'a' as "a-text";
select '[{"a":"1","b":"2"}]'::json->0-> 'a' as "a-json";
2.2 场景二:拆分键值对
将字符串'{"a":"1","b":"2"}'中的键值对拆分出来一行一个键值对,键和值各分一列。
| 键 | 值 |
|---|---|
| a | 1 |
| b | 2 |
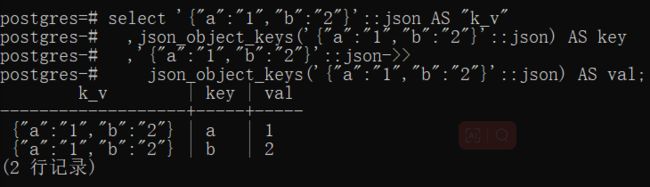
要取键值结构的 JSON 类型的键,可以通过json_object_keys()提取,返回的数据结构为一行一个键,结果如下:
select '{"a":"1","b":"2"}'::json "k_v",json_object_keys('{"a":"1","b":"2"}'::json) AS key;

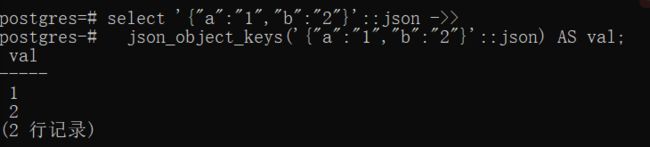
获取值没有类似的函数,不过能够拿到键,便可以通过键进行取值,即在下面的k_v列按key列取值。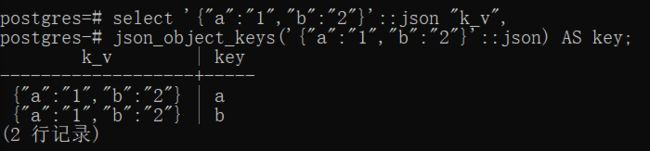
取值 SQL 如下:
select '{"a":"1","b":"2"}'::json ->> json_object_keys('{"a":"1","b":"2"}'::json) AS val;
最终把三者放到一起来看看:
select '{"a":"1","b":"2"}'::json AS "k_v"
,json_object_keys('{"a":"1","b":"2"}'::json) AS key
,'{"a":"1","b":"2"}'::json->>
json_object_keys('{"a":"1","b":"2"}'::json) AS val;
2.3 场景三:拆分字符串
任务:将字符串'分数: 5'键值对分开为两列,注意中间可能有空格。
这个和上面不同,上面是一个键值对且是标准 JSON 格式的结构,这个只是字符串,结构像键值对,但它的“键”和“值”没有双引号括起来,所以不是键值对格式的数据。
所以要使用切割的方式将值分开,切割前还需要考虑空格的处理。
处理方式可能会有多种,比如先使用replace('分数: 5',' ','')将空格去掉,然后使用regexp_split_to_array(将字符串按照冒号切割,为了避免中英文混合使用,使用两种冒号,这个函数返回了一个数组,最后再使用to_json()转化为 JSON 类型进行取值。直接通过数组进行取值也是可以。看下面例子(以取首个为例)
需要注意的是 JSON 类型的索引从 0 开始,而数组类型从 1 开始。
-- 转化为 JSON 类型取值
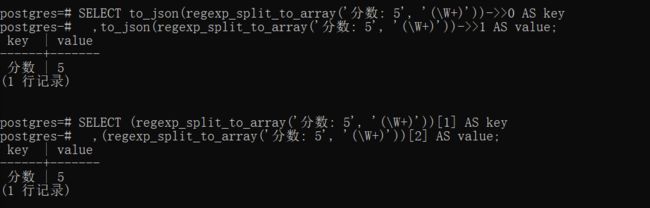
SELECT to_json(regexp_split_to_array(replace('分数: 5',' ',''), '[::]'))->>0;
-- 转化为 数组类型取值
SELECT (regexp_split_to_array(replace('分数: 5',' ',''), '[::]'))[1];

以上的方法是先替换再切割,使用正则还可以实现一步到位取值,也是通过regexp_split_to_array()方法取值,不过匹配方式不一样,采用'(\W+)',这个匹配模式的含义是:
\W:匹配不是字母、数字、中文和_的字符+:匹配一个或多个():按组匹配,把括号内的内容视为一个整体
所以'(\W+)'的含义是匹配一个或多个不是字母、数字、中文和_的字符,如果中间有空格和冒号,都会被一次匹配到。
使用'(\W+)'匹配结果如下:
-- 转化为 JSON 类型取值
SELECT to_json(regexp_split_to_array('分数: 5', '(\W+)'))->>0;
-- 转化为 数组类型取值
SELECT (regexp_split_to_array('分数: 5', '(\W+)'))[1];

最终是要将'分数: 5'分开两列,以第二种方法示例,最终的 SQL 如下:
-- 转化为 JSON 类型取值
SELECT to_json(regexp_split_to_array('分数: 5', '(\W+)'))->>0 AS key,to_json(regexp_split_to_array('分数: 5', '(\W+)'))->>1 AS value;
-- 转化为 数组类型取值
SELECT (regexp_split_to_array('分数: 5', '(\W+)'))[1] AS key,(regexp_split_to_array('分数: 5', '(\W+)'))[2] AS value;
2.4 场景四:批量匹配字符串
任务:将字符串 等级3:一般'的尖括号标签1
\n<>以及尖括号内的字符全部去掉,仅保留文字。
去掉字符可以使用regexp_replace()函数,支持正则表达式。要将所有尖括号及其内的字符串去掉,就需要匹配尖括号,匹配方式有多种,这里提供两种方式:'<[^>]+>'和'<.*?>'。
<和>分别表示左尖括号和右尖括号。[^>]表示除了右尖括号之外的任意字符。+表示前面的字符可以出现一次或多次。.*?是一个非贪恋匹配,即匹配每一组尖括号及其内的字符串
以第一个为例,查看下匹配结果:
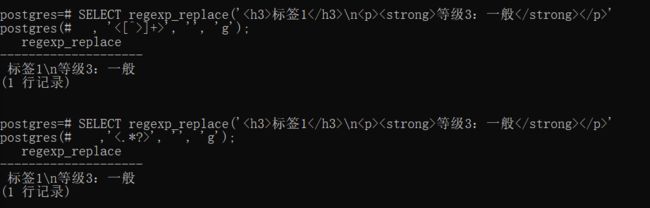
SELECT regexp_replace('标签1
\n等级3:一般
', '<[^>]+>', '');

从结果上看,第一个已经被正确匹配并去除了,说明该逻辑可行。
但是目标是要匹配所有尖括号及其内的字符串并去除,这就需要使用到regexp_replace()的可选参数flags,默认情况下,该函数仅匹配一个值,可以将匹配模式改为'g',匹配所有的值。
常用的几种模式如下:
'g':全局匹配模式,即在整个字符串中查找所有匹配项并进行替换。默认模式仅匹配一个。'i':不区分大小写匹配模式,即在匹配时忽略大小写。默认模式匹配时会区分大小写。'm':多行模式,即在多行文本中查找匹配项并进行替换。默认模式只在单行文本中查找匹配项。's':贪婪模式,即尽可能多地匹配字符。默认模式会尽可能少地匹配字符。
最终两种匹配方式示例如下:
SELECT regexp_replace('标签1
\n等级3:一般
', '<[^>]+>', '', 'g');
SELECT regexp_replace('标签1
\n等级3:一般
', '<.*?>', '', 'g');
三、总结
本文围绕PostgreSQL数据库中的JSON函数和正则表达式的运用,由浅入深介绍了几种常用数据处理方法,分别是JSON 取值、拆分键值对、拆分字符串和批量匹配字符串。
PostgreSQL的JSON数据类型表现出极大的灵活性,支持键值对和嵌套数组结构,使得我们能够方便地存储和检索非结构化数据。而且,再结合具有优秀处理字符串能力的正则表达式,处理非结构化数据就变得轻而易举。
由于文章篇幅的限制,仅介绍了JSON 函数和正则表达式很小的一部分内容。如果你想获取更多信息,了解更全面的知识点,可查阅官方文档。
相关阅读:
正则表达式(虽然是讲解 Python 的正则表达式,但是正则的底层知识点是相通的。)