数据解析——Jsonpath
目录
一、JsonPath安装
二、JsonPath使用
2.1、JsonPath和xpath语法对比
2.2、jsonpath具体使用方法
2.2.1、jsonpath 获取参数
2.2.2、对应的 json 字符串:
2.2.3、对应的python代码
三、Jsonpath解析淘票票
3.1、python代码
3.1.1、获取 json 数据并保存至本地
3.1.2、根据本地 json 文件获取相应信息
3.2、结果
一、JsonPath安装

二、JsonPath使用
注意:JsonPath只能解析本地文件,不能解析服务器响应的文件
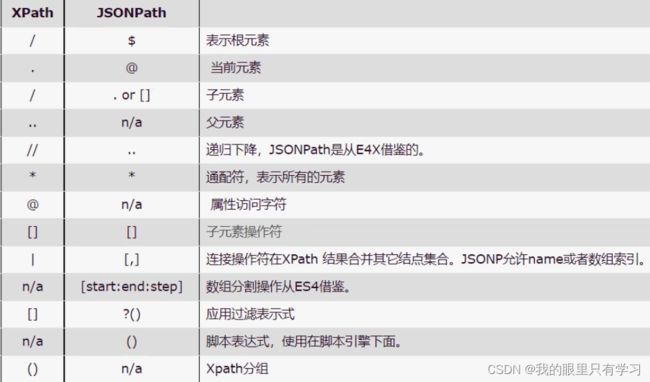
2.1、JsonPath和xpath语法对比
2.2、jsonpath具体使用方法
2.2.1、jsonpath 获取参数

2.2.2、对应的 json 字符串:
{
"store": {
"book":[
{
"category": "修真",
"author": "六道",
"title": "坏蛋是怎样炼成的",
"price": 8.95
},
{
"category": "修真",
"author": "天蚕土豆",
"title": "斗破苍穹",
"price": 12.99
},
{
"category": "修真",
"author": "唐家三少",
"title": "斗罗大陆",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "修真",
"author": "南派三叔",
"title": "皇辰变",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "黑色",
"price": 19.95
}
}
}2.2.3、对应的python代码
import jsonpath
import json
obj = json.load(open('20_爬虫_解析_jsonpath.json', 'r', encoding='utf8'))
# 书店所有书的作者(xpath:/store/book/author)
author_list = jsonpath.jsonpath(obj, '$.store.book[*].author')
# 书店第一本书
book_first = jsonpath.jsonpath(obj, '$..book[0]')
# 书店最后一本书
book_last = jsonpath.jsonpath(obj, '$..book[(@.length-1)]')
# 书店前两本书
book_list_second1 = jsonpath.jsonpath(obj, '$..book[0,1]')
book_list_second2 = jsonpath.jsonpath(obj, '$..book[:2]')
# 所有的作者(xpath://author)
author_allList = jsonpath.jsonpath(obj, '$..author')
# store下面的所有元素
tag_list = jsonpath.jsonpath(obj, '$.store.*')
# store里面的所有钱
price_list = jsonpath.jsonpath(obj, '$.store..price')
# 条件过滤,需要在()前加"?"
# 过滤出所有包含isbn的书
book_list_isbn = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
# 条件过滤,需要在()前加"?"
# 哪本书超过10块钱
book_list_overTen = jsonpath.jsonpath(obj, '$..book[?(@.price>10)]')
print(book_list_overTen)三、Jsonpath解析淘票票
3.1、python代码
3.1.1、获取 json 数据并保存至本地
import urllib.request
import json
import jsonpath
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1662563919541_108&jsoncallback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# 带:的属性会报错,不能使用
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?city=110100&_ksTS=1662562312158_19&jsoncallback=jsonp20&action=cityAction&n_s=new&event_submit_doLocate=true',
# ':scheme': 'https',
# 编码格式与爬虫不符
# 'accept-encoding': 'gzip, deflate, br',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
# 结果:jsonp20({"returnCode":"0","returnValue":{"city":110100,"name":"北京"}}); 需要去掉”jsonp20();“
# 切割,获取json字符串
content = content.split('(')[1].split(')')[0]
with open('21_爬虫_解析_jsonpath淘票票.json', 'w', encoding='utf8') as fp:
fp.write(content)
3.1.2、根据本地 json 文件获取相应信息
import json
import jsonpath
obj = json.load(open('21_爬虫_解析_jsonpath淘票票.json', 'r', encoding='utf8'))
city_list = jsonpath.jsonpath(obj, '$..regionName')
print(city_list)3.2、结果
![]()
注意:红框内为有效json,其他字符串为非json字符串,在进行json识别时,需要去掉。
