反反爬之python爬虫实例加分析过程
如何突破常规的反爬限制
今天要记录的这个爬虫是我到新工作的第5天接的一个需求,也是我从Java转Python的第5天写的一个爬虫脚本。这个还有脚本有很多可以完善的地方,但也有一些值得参考的地方,下面进行详细的介绍。
目标网站和爬取素材
目标网站:拍信网 https://www.paixin.com/ (如有冒犯之处,敬请谅解)
爬取素材:各种图片(在搜索栏中输入关键字,进行查询得到图片)
分析过程
怎样找到目标的url?
首先在搜索栏中输入关键字,进入结果页面,F12打开谷歌开发者工具,选择中network面板,刷新页面;
在选择xhr(xmlHttpRequest)
图1
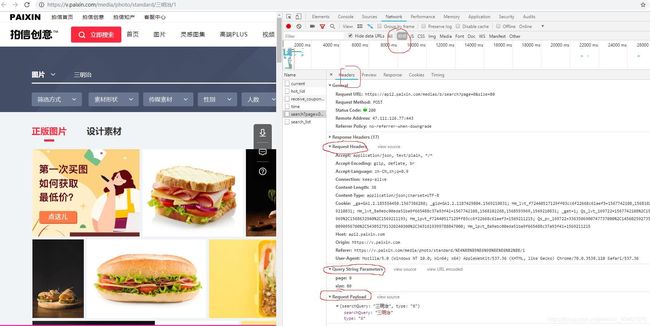
图2

图3
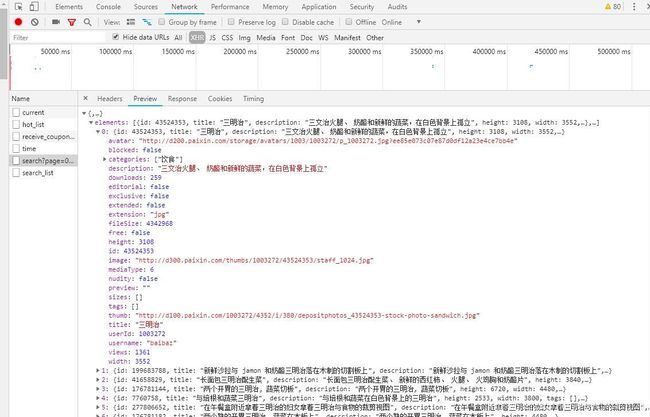
分析图3,根据里面的请求可知"…search?page=XXX…“请求可以获取图片描述和地址以及其他信息,所以该请求就是我们要找的目标url。注意该请求是一个异步请求,返回的数据是json格式的数据。这里其实有一个坑,看图2,我从第1页开始翻页,翻到第4页正常来说应该是发送4个请求才对,但是这里面却有6个”…search?page=XXX…"请求,且每翻一页还有“…search_list…”这样的请求,这是怎么回事呢?看看这些请求有没有返回数据,尝试着在浏览器地址栏中发送一下看有什么结果,综合分析对比即可发现正确的URL。其实这里面的一些无用的请求是故意用来迷惑我们的双眼的,这也是网站的反爬手段之一。
然后我们就可以伪造请求了,刚开始时我在请求头里面就写了一个User-Agent,然后发送请求看一下能否返回数据,结果请求失败,没有任何数据返回,然后我又仔细的看了一下Request Headers,里面的信息的信息很多,我猜测应该是请求头里面缺少信息,所以服务器拒绝了请求,既然这样那就把这些信息放在请求头里面,这么多都需要放吗?它们分别代表的是什么意思呢?
headers中的每一项的意义
headers信息中这个referer代表的是referer防盗链,是一种常见的反爬手段,指的是该链接请求的来源页面
就这样我又运行修改后的程序,结果还是没有返回结果,这到底是怎么回事?一定是漏掉了什么,继续查看检查了一下headers里面的信息,发现headers下面有一个Request Playload里面还有一些参数,那这个Request Playload是什么呢?
request playload详解
于是把request playload里面的数据带上,发送请求成功返回数据,至此这个爬虫的难点全部解决。
代码
分析完了,就直接上代码吧。
import json
import urllib
import jsonpath
import requests
#拍信创意
def getBlackman(startPage,endPage,path):
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Accept': 'application/json, text/plain, */*', 'Accept - Encoding': 'gzip, deflate, br',
'Accept - Language': 'zh - CN, zh;q = 0.9', 'Connection': 'keep-alive', 'Content-Length': '41',
'Content-Type': 'application/json;charset=UTF-8',
'Host': 'api2.paixin.com', 'Origin': 'https://v.paixin.com',
'Referer': 'https://v.paixin.com/media/photo/standard/%E9%BB%91%E4%BA%BA%E5%A4%B4%E5%83%8F/2',
}
requests.packages.urllib3.disable_warnings() #禁用https安全证书的验证
playloadData = {
'searchQuery':'三明治',
'type': '6',
'searchQuery': '三明治',
'type': '6'
}
for num in range(startPage,(endPage+1)):
images = requests.post('https://api2.paixin.com/medias/b/search?page=' + str((num-1)) + '&size=80',
data=json.dumps(playloadData), headers=header, verify=False,timeout=5)
#data=json.dumps(playloadData) 将dict转化为str格式
jsonObjs = json.loads(images.text)
# print(jsonObjs)
images = jsonpath.jsonpath(jsonObjs, '$..image')
i = 1
for image_url in images:
try:
print('*' * 10 + '正在下载第' + str((num - 1) * 80 + i) + '张图片' + '*' * 10)
res=urllib.request.urlopen(image_url,timeout=5).read()
with open(path + '拍信网第'+str((num-1)*80+i) + '张.jpg','wb') as file:
file.write(res)
file.close()
except Exception as e:
print('第'+str((num-1)*80+i)+'张图片下载出错,错误信息如下:')
print(' '*10+str(e))
print('')
continue
finally:
i += 1
print('*'*15+'下载完成'+'*'*15)
# def save_image(url,path):
# try:
# res=urllib.request.urlopen(url,timeout=5).read()
if __name__ == '__main__':
getBlackman(1, 16, 'd:/download/拍信/三明治/') # 1页80张,getBlackman(开始页,结束页,图片存储路径)