爬虫入门指南(2):如何使用正则表达式进行数据提取和处理
文章目录
- 正则表达式
- 正则表达式中常用的元字符和特殊序列
-
- 案例
- 使用正则表达式提取数据
- 案例
- 存储数据到文件或数据库
-
- 使用SQLite数据库存储数据的示例代码
- SQLite基本语法
-
- 创建表格:
- 插入数据:
- 查询数据:
- 更新数据:
- 删除数据:
- 条件查询:
- 排序:
- 代码案例
- 未完待续…
正则表达式

正则表达式是一种用于匹配和处理文本的工具,可以定义规则和模式来查找、替换和提取目标数据。Python中内置的
re模块可用于操作正则表达式。
正则表达式中常用的元字符和特殊序列
.:匹配任意字符(除了换行符)。\d:匹配任意数字。\w:匹配任意字母数字字符(包括下划线)。\s:匹配任意空白字符(包括空格、制表符等)。+:匹配前面的元素一次或多次。*:匹配前面的元素零次或多次。?:匹配前面的元素零次或一次。{n}:匹配前面的元素恰好n次。{n,}:匹配前面的元素至少n次。{n,m}:匹配前面的元素至少n次且不超过m次。
正则表达式还支持分组、贪婪与非贪婪匹配、边界匹配等高级功能。
案例
假设我们有一个字符串text = "Hello, my phone number is 123-456-7890",我们想从中提取出手机号码。可以使用正则表达式\d{3}-\d{3}-\d{4}进行匹配。
import re
text = "Hello, my phone number is 123-456-7890"
match = re.search(r"\d{3}-\d{3}-\d{4}", text)
if match:
phone_number = match.group()
print(phone_number)
输出结果为:123-456-7890
分析说明 :
代码中,正则表达式模式\d{3}-\d{3}-\d{4}用于匹配电话号码的格式。这个模式由以下部分组成:
- \d{3}:匹配三个连续的数字。
- -:匹配一个横线字符。
- \d{3}:匹配三个连续的数字。
- -:匹配一个横线字符。
- \d{4}:匹配四个连续的数字。
注意:\d代表数字字符。
如果re.search()函数找到了匹配的结果,它将返回一个Match对象,否则返回None。
接着,使用条件语句if match来检查是否找到了匹配结果。如果找到了匹配,就执行以下代码块。
match.group()方法用于获取匹配结果的字符串表示。
使用正则表达式提取数据
Python中,我们可以利用
re模块的函数使用正则表达式进行数据提取。常用的函数有:
re.search(pattern, string):在给定字符串中查找第一个匹配项,并返回一个匹配对象。通过匹配对象的方法如group()、start()和end(),可以获取具体的匹配结果。re.findall(pattern, string):在给定字符串中查找所有匹配项,并以列表形式返回所有结果。re.sub(pattern, repl, string):在给定字符串中查找匹配项,并将其替换为指定内容。re.split(pattern, string):根据给定模式对字符串进行拆分,并以列表形式返回拆分后的结果。
案例
假设我们有一个包含多个电子邮件地址的字符串text = "Contact us at [email protected] or [email protected]",我们想提取出其中的电子邮件地址。可以使用正则表达式\w+@\w+\.\w+进行匹配。
import re
text = "Contact us at [email protected] or [email protected]"
emails = re.findall(r"\w+@\w+\.\w+", text)
print(emails)
输出结果为:
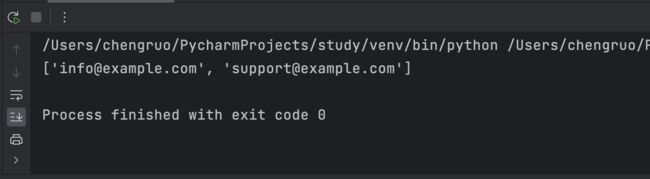
分析说明:
正则表达式模式\w+@\w+.\w+用于匹配电子邮件地址的格式。这个模式由以下部分组成:
- \w+:匹配一个或多个字母、数字或下划线字符(即匹配邮箱地址的用户名部分)。
- @:匹配一个 @ 符号。
- \w+:匹配一个或多个字母、数字或下划线字符(即匹配邮箱地址的域名部分)。
- .:匹配一个点(.)字符。
- \w+:匹配一个或多个字母、数字或下划线字符(即匹配邮箱地址的顶级域名部分)。
注意:\w代表字母、数字或下划线字符。
re.findall()函数将返回一个包含所有匹配的字符串列表。
存储数据到文件或数据库

在Python中,我们可以使用内置的文件操作函数来将数据保存到文件中。
首先,使用open()函数打开一个文件,传入两个参数:文件名和打开模式。打开模式可以是 “w”(写入)、“a”(追加)、“r”(只读)等。如果文件不存在,将会创建一个新的文件。
with open("data.txt", "w") as file:
file.write("这是要保存的数据")
代码中,我们使用
open()函数打开名为"data.txt"的文件,并指定打开模式为"w"(写入)。然后,使用文件对象的write()方法将数据写入文件中。
如果需要更复杂的数据管理和查询,可以使用数据库系统来存储数据。常见的数据库系统包括MySQL、SQLite和MongoDB等。
在Python中,我们可以使用相应的数据库驱动程序(如mysql-connector-python、sqlite3和pymongo)来连接数据库并执行操作。
使用SQLite数据库存储数据的示例代码
SQLite基本语法

创建表格:
使用CREATE TABLE语句创建新的表格。指定表格的名称和列定义。每个列都包括列名和数据类型。你还可以为特定的列指定约束条件。例如:
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER DEFAULT 0
);
示例中,我们创建了一个名为"users"的表格,包含id、name和age三个列。id列被定义为主键(PRIMARY KEY),name列被定义为非空(NOT NULL),age列设置了默认值为0。
插入数据:
使用INSERT INTO语句插入新的数据行。指定表格名称和要插入的值。你可以插入指定的列或者省略列名插入所有列。例如:
INSERT INTO users (name, age) VALUES ('Alice', 25);
或者省略列名插入所有列:
INSERT INTO users VALUES (1, 'Alice', 25);
这将在"users"表格中插入一行数据,其中name列的值为’Alice’,age列的值为25。
查询数据:
使用SELECT语句从表格中检索数据。指定所需的列和表格名称。你还可以使用WHERE子句添加筛选条件。例如:
SELECT * FROM users;
这将检索出"users"表格中的所有列和行。
SELECT name, age FROM users WHERE age >= 20;
这将返回"users"表格中age列大于或等于20的行,并且只包括name和age两列。
更新数据:
使用UPDATE语句更新表格中的数据。指定表格名称、要更新的列和新值,以及更新条件。例如:
UPDATE users SET age = 30 WHERE name = 'Alice';
这将把"users"表格中名为’Alice’的行的age列更新为30。
删除数据:
使用DELETE FROM语句从表格中删除数据。指定表格名称和删除条件。例如:
DELETE FROM users WHERE age < 18;
这将从"users"表格中删除所有age列小于18的行。
条件查询:
使用WHERE子句来添加条件,对查询结果进行筛选。可以使用比较运算符(如=、<、>)和逻辑运算符(如AND、OR、NOT)组合多个条件。例如:
SELECT * FROM users WHERE age >= 20 AND age < 30;
这将返回"users"表格中age列大于等于20且小于30的行。
排序:
使用ORDER BY子句对查询结果进行排序。指定要排序的列和排序顺序(升序ASC或降序DESC)。例如:
SELECT * FROM users ORDER BY age DESC;
这将按照age列的降序对"users"表格中的行进行排序。
这里只是对常用的SQLite语法进行了介绍。实际上,SQLite还支持更多的功能和语法,例如连接操作、聚合函数(如SUM、AVG等)、子查询、联合查询等等。
代码案例
import sqlite3
conn = sqlite3.connect("data.db")
cursor = conn.cursor()
sql = "INSERT INTO users (name, age) VALUES (?, ?)"
data = [("Alice", 25), ("Bob", 30), ("Charlie", 35)]
cursor.executemany(sql, data)
conn.commit()
conn.close()
例子中,我们首先使用
sqlite3.connect()函数连接到名为"data.db"的SQLite数据库,并创建一个游标对象。然后,我们定义了一条SQL语句,用于向名为"users"的表中插入数据。最后,我们使用cursor.executemany()方法批量执行插入操作,并通过conn.commit()保存更改。
未完待续…
