【小白必看】Python爬取NBA球员数据示例
文章目录
- 前言
- 导入需要的库和模块
- 设置请求头和请求地址
- 发送HTTP请求并获取响应
- 处理响应结果
- 解析数据
- 将结果保存到文件
- 完整代码
-
- 详细解析
- 运行效果
- 结束语
前言
使用 Python 爬取 NBA 球员数据的示例代码。通过发送 HTTP 请求,解析 HTML 页面,然后提取出需要的排名、姓名、球队和得分信息,并将结果保存到文件中。
导入需要的库和模块
import requests
from lxml import etree
- 使用
requests库发送HTTP请求。 - 使用
lxml库进行HTML解析。
设置请求头和请求地址
url = 'https://nba.hupu.com/stats/players'
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
- 设置请求头信息,包括用户代理(User-Agent)。
- 设置请求的地址为’https://nba.hupu.com/stats/players’。
发送HTTP请求并获取响应
resp = requests.get(url, headers=headers)
- 使用
requests库发送HTTP GET请求,并传入请求地址和请求头信息。 - 将返回的响应保存在变量
resp中。
处理响应结果
e = etree.HTML(resp.text)
- 使用
etree.HTML函数将返回的响应文本解析为一个可操作的HTML元素树对象。 - 将解析后的结果保存在变量
e中。
解析数据
nos = e.xpath('//table[@class="players_table"]//tr/td[1]/text()')
names = e.xpath('//table[@class="players_table"]//tr/td[2]/a/text()')
teams = e.xpath('//table[@class="players_table"]//tr/td[3]/a/text()')
scores = e.xpath('//table[@class="players_table"]//tr/td[4]/text()')
- 使用XPath表达式从HTML元素树中提取需要的数据。
- 分别将排名(nos)、姓名(names)、球队(teams)和得分(scores)保存在对应的变量中。
将结果保存到文件
with open('nba.txt', 'w', encoding='utf-8') as f:
for no, name, team, score in zip(nos, names, teams, scores):
f.write(f'排名:{no} 姓名:{name} 球队:{team} 得分:{score}\n')
- 打开一个文件
nba.txt,以写入模式(‘w’)进行操作,编码方式为UTF-8。 - 使用
zip函数同时遍历排名、姓名、球队和得分,将它们合并成一个元组。 - 将每一行的数据按照指定格式写入文件中。
完整代码
# 引入 requests 库,用于发送 HTTP 请求
import requests
# 引入 lxml 库,用于解析 HTML
from lxml import etree
# 设置请求的地址
url = 'https://nba.hupu.com/stats/players'
# 设置请求头信息,包括用户代理(User-Agent)
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
# 发送HTTP GET请求,并传入请求地址和请求头信息,将返回的响应保存在变量resp中
resp = requests.get(url, headers=headers)
# 使用etree.HTML函数将返回的响应文本解析为一个可操作的HTML元素树对象
e = etree.HTML(resp.text)
# 使用XPath表达式从HTML元素树中提取需要的数据
nos = e.xpath('//table[@class="players_table"]//tr/td[1]/text()')
names = e.xpath('//table[@class="players_table"]//tr/td[2]/a/text()')
teams = e.xpath('//table[@class="players_table"]//tr/td[3]/a/text()')
scores = e.xpath('//table[@class="players_table"]//tr/td[4]/text()')
# 打开一个文件`nba.txt`,以写入模式('w')进行操作,编码方式为UTF-8
with open('nba.txt', 'w', encoding='utf-8') as f:
# 使用zip函数同时遍历排名、姓名、球队和得分,将它们合并成一个元组
for no, name, team, score in zip(nos, names, teams, scores):
# 将每一行的数据按照指定格式写入文件中
f.write(f'排名:{no} 姓名:{name} 球队:{team} 得分:{score}\n')
详细解析
# pip install requests
import requests
导入 requests 库,该库用于发送 HTTP 请求。
# pip install lxml
from lxml import etree
导入 lxml 库,该库用于解析 HTML。
# 发送的地址
url = 'https://nba.hupu.com/stats/players'
设置需要发送请求的地址。
headers ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
设置请求头信息,包括用户代理(User-Agent)。这个信息告诉服务器我们的请求是从一个浏览器发出的,而不是爬虫,这样可以避免被反爬虫机制阻止。
# 发送请求
resp = requests.get(url,headers = headers)
使用 requests.get 方法发送 HTTP GET 请求,并传入请求地址和请求头信息。将返回的响应保存在变量 resp 中。
e = etree.HTML(resp.text)
使用 etree.HTML 函数将返回的响应文本解析为一个可操作的 HTML 元素树对象。etree.HTML 接受一个字符串类型的参数,这里使用 resp.text 来获取响应的文本内容。
nos = e.xpath('//table[@class="players_table"]//tr/td[1]/text()')
names = e.xpath('//table[@class="players_table"]//tr/td[2]/a/text()')
teams = e.xpath('//table[@class="players_table"]//tr/td[3]/a/text()')
scores = e.xpath('//table[@class="players_table"]//tr/td[4]/text()')
使用 XPath 表达式从 HTML 元素树中提取需要的数据。这里分别使用了四个 XPath 表达式来提取排名、姓名、球队和得分的数据,并将它们分别保存在 nos、names、teams 和 scores 变量中。
with open('nba.txt','w',encoding='utf-8') as f:
for no,name,team,score in zip(nos,names,teams,scores):
f.write(f'排名:{no} 姓名:{name} 球队:{team} 得分:{score}\n')
以写入模式(‘w’)打开一个名为 nba.txt 的文件,并使用 UTF-8 编码。然后,使用 zip 函数同时遍历排名、姓名、球队和得分,将它们合并成一个元组。通过循环遍历每个元组,将每行的数据按照指定格式写入文件中。
这样,代码就实现了对 NBA 球员数据进行爬取,并将结果保存到 nba.txt 文件中。
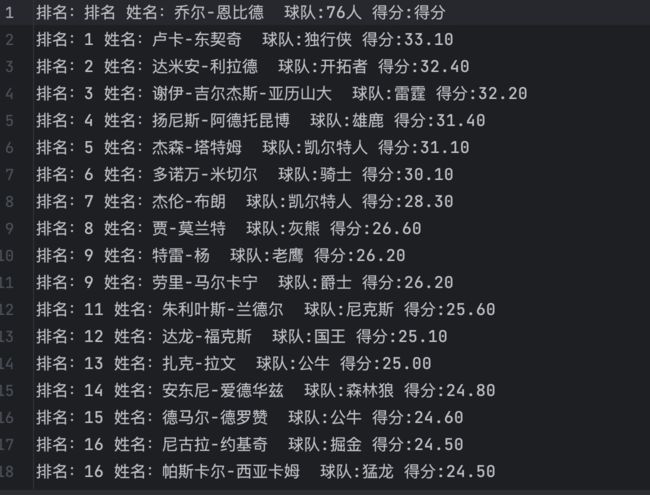
运行效果
结束语
通过本文的示例代码,你可以学习使用Python爬取NBA球员数据的方法。我们使用了requests库发送HTTP请求,lxml库进行HTML解析,以及XPath表达式提取需要的数据。最后将结果保存到文件中。这个示例可以帮助你了解爬虫的基本原理和操作步骤,同时也能够获取到有关NBA球员的数据。希望本文对你理解和掌握Python爬虫技术有所帮助。