【玩转python系列】【小白必看】使用Python爬虫技术获取代理IP并保存到文件中
文章目录
- 前言
-
- 导入依赖库
- 打开文件准备写入数据
- 循环爬取多个页面
- 完整代码
- 运行效果
- 结束语

前言
这篇文章介绍了如何使用 Python 爬虫技术获取代理IP并保存到文件中。通过使用第三方库 requests 发送HTTP请求,并使用 lxml 库解析HTML,我们可以从多个网页上获取IP、Port和地址信息。本文将逐步解析代码的每一部分,帮助读者更好地理解爬虫的工作原理。
导入依赖库

import requests
from lxml import etree
导入 requests 库用于发送 HTTP 请求,以及 lxml 库用于解析 HTML。
打开文件准备写入数据
with open('IP代理.txt','w',encoding='utf-8') as f:
使用 open 函数创建文件对象 f,指定文件名为 'IP代理.txt',以写入模式打开文件。编码方式设置为 'utf-8'。
循环爬取多个页面
for i in range(1,10):
url = f'http://www.66ip.cn/{i}.html'
print(f'正在获取{url}')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
resp = requests.get(url,headers = headers)
resp.encoding ='gbk'
e = etree.HTML(resp.text)
ips = e.xpath('//div[1]/table//tr/td[1]/text()')
ports = e.xpath('//div[1]/table//tr/td[2]/text()')
addrs = e.xpath('//div[1]/table//tr/td[3]/text()')
for i,p,a in zip(ips,ports,addrs):
f.write(f'IP地址:{i}----port端口号:{p}-----地址:{a}\n')
该部分代码使用循环爬取了多个页面的代理信息。循环变量 i 的范围是从 1 到 9。对于每个页面,首先构造了完整的 URL:http://www.66ip.cn/{i}.html,其中 {i} 是页面的页码。然后,使用 print 函数打印出正在获取的页面 URL。
接下来,为了伪装自己的浏览器,定义了一个 headers 字典,包含了浏览器的 User-Agent 信息。
通过 requests 库发送 GET 请求,使用 headers 字典中的 User-Agent 信息。得到的响应内容保存在 resp 变量中。
设置响应的编码为 'gbk',因为目标网站使用的是 GBK 编码。
将响应内容解析成可操作的 HTML 对象,赋值给变量 e,使用的是 lxml 库的 etree.HTML 函数。
通过 XPath 表达式,从 HTML 对象中提取出 IP、Port 和地址的列表。IP 列表存储在 ips 中,Port 列表存储在 ports 中,地址列表存储在 addrs 中。
使用 zip 函数将三个列表一一对应地打包在一起,然后使用 for 循环遍历打包后的数据。在循环中,使用文件对象 f 的 write 方法将每一条代理信息写入文件,写入格式为 'IP地址:{i}----port端口号:{p}-----地址:{a}\n'。
整个代码的作用是爬取多个网页中的 IP、Port 和地址信息,并将结果保存在名为 'IP代理.txt' 的文件中。
完整代码
import requests
from lxml import etree
# 定义保存结果的文件
with open('IP代理.txt', 'w', encoding='utf-8') as f:
# 循环爬取多个页面
for i in range(1, 10):
# 构造完整的URL
url = f'http://www.66ip.cn/{i}.html'
print(f'正在获取{url}')
# 伪装浏览器请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
# 发送GET请求
resp = requests.get(url, headers=headers)
# 设置响应的编码为GBK
resp.encoding = 'gbk'
# 解析HTML
e = etree.HTML(resp.text)
# 提取IP、Port和地址信息
ips = e.xpath('//div[1]/table//tr/td[1]/text()')
ports = e.xpath('//div[1]/table//tr/td[2]/text()')
addrs = e.xpath('//div[1]/table//tr/td[3]/text()')
# 将提取的代理信息写入文件
for ip, port, addr in zip(ips, ports, addrs):
f.write(f'IP地址:{ip}----port端口号:{port}-----地址:{addr}\n')
运行效果
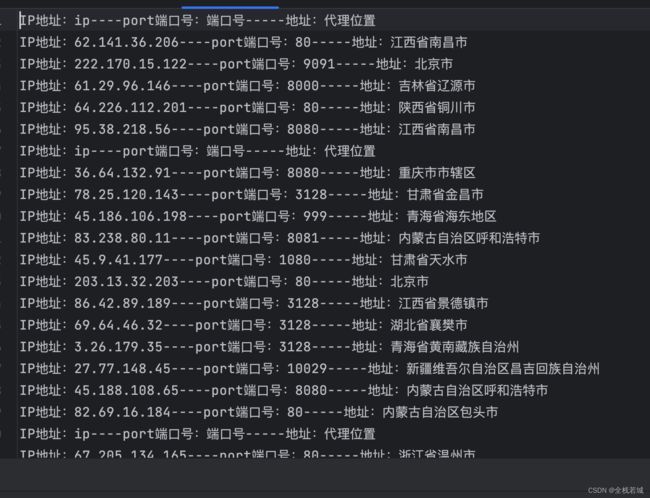
结束语
通过本文介绍的Python爬虫技术,您可以轻松地获取代理IP并保存到文件中。这对于需要使用代理IP进行数据采集、反爬虫处理或其他网络爬虫应用非常有用。希望本文能够帮助您更好地理解爬虫的工作原理,并在实际项目中发挥作用。