Linux mmap系统调用视角看缺页中断
问题
1. mmap具体是怎么实现比read/write少一次内存copy的
2.mmap共享映射和私有映射在内核实现的时候到底有什么区别
3.mmap的文件映射和匿名映射在内核实现的时候到底有什么区别
4.父子进程的COW具体怎么实现的
概述
实际开发过程中经常使用或者看到mmap函数,具体细节可以man mmap查看相关细节。这个系统调用是个多面手,应用空间申请内存(比如glibc库申请大内存使用的是mmap),还是读写大文件,链接动态库,多进程间共享内存都可以看到mmap的身影,要想真正的理解这个系统一方面是从这几种使用场景的需求上理解mmap,更重要的必须基于内核源码,深入剖析其每个参数具体对应的内核实现。
内存拷贝次数
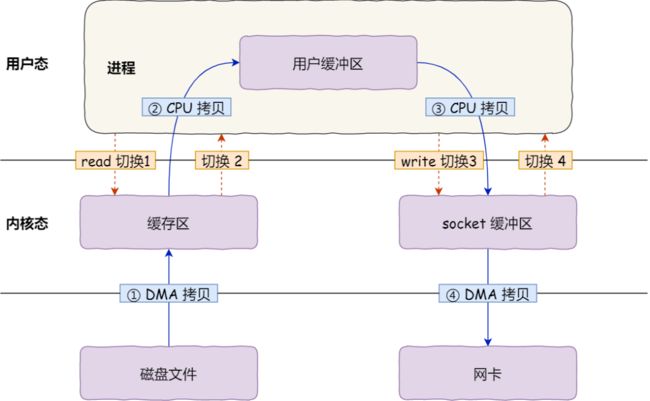
以mmap映射文件场景来讲,mmap读写文件与read/write的相比少一次内存拷贝,如果想真正理解这句话最好亲自去看下read/write系统调用的实现流程。以read系统调用来讲其声明如下:
NAME
read - read from a file descriptor
SYNOPSIS
#include
ssize_t read(int fd, void *buf, size_t count); 传入一个用户态空间的虚拟地址指针buf,最终内核实现的时候要将文件内容copy到该buf中,我们的都知道内核为了加速读写文件速度会在内核中创建page cache内存(不考虑direct io),那么文件内容首先是读取到了内核的page cache内存中,page cache再拷贝到用户态地址buf当中,而mmap的内核page直接跟用户态地址实现映射,那么只要缺页异常时候(文件缺页异常读取数据时mm/filemap.c::filemap_fault函数实现)将数据读取到对应的page中,自然用户态虚拟地址就可以读取到(因为用户态的虚拟地址通过页表直接映射了filemap_fault缺页中断生成的page)。
重点:mmap和read/write生成的page有什么区别?
我们看到mmap和read/write系统调用在内核态都会创建物理页page。mmap是缺页中断时候创建的,如果匿名映射(MAP_ANON)创建的匿名页面;如果文件映射创建的file-back page页面;这两种页面都通过用户态页表完成映射。而read/write系统调用创建的page则不同,这种page cache从某种角度来讲是"临时工",因为并没有用户态页表映射该page,write函数为例,内核系统调用实现的时候只把用户态buf copy给"临时工" page cache返回即可。那么临时工是怎么体现的?
read/write既然没有通过用户态页表,而内核把用户态buf拷贝给内核中的page cache又必须使用内核态虚拟地址,最终内核是通过kmap将page cache临时映射到内核虚拟地址:
//write系统调用会调用到该函数
ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
...
//iov_iter封装了用户态地址buf,该函数将用户态buf copy到内核page cache中
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
...
}
size_t iov_iter_copy_from_user_atomic(struct page *page,
struct iov_iter *i, unsigned long offset, size_t bytes)
{
//通过kmap_atomic将内核page cache临时映射到内核态虚拟地址
char *kaddr = kmap_atomic(page), *p = kaddr + offset;
if (unlikely(!page_copy_sane(page, offset, bytes))) {
kunmap_atomic(kaddr);
return 0;
}
if (unlikely(i->type & ITER_PIPE)) {
kunmap_atomic(kaddr);
WARN_ON(1);
return 0;
}
iterate_all_kinds(i, bytes, v,
copyin((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len),
memcpy_from_page((p += v.bv_len) - v.bv_len, v.bv_page,
v.bv_offset, v.bv_len),
memcpy((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len)
)
//因为是临时映射的,使用完该虚拟地址通过kunmap,因为这段虚拟地址还是有限的(32位应该是4M)
kunmap_atomic(kaddr);
return bytes;
}通过上面场景我们同时也学习到kmap的典型使用场景,经常中文书籍中将kmap翻译成“永久映射”这完全是一种误导,恰恰相反,kmap使用场景是临时映射。
对于mmap这种文件读写情况不太想画图了,引用网络上一张图把:
mmap函数参数详解
NAME
mmap, munmap - map or unmap files or devices into memory
SYNOPSIS
#include
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length); - prot : 设置内存映射区域vma的读写属性(vma中的vma_flags),最终也会影响页表项pte的读写属性。取值范围:
PROT_EXEC Pages may be executed.
PROT_READ Pages may be read.
PROT_WRITE Pages may be written.
PROT_NONE Pages may not be accessed.- flags: 设置映射共享等属性。比如MAP_SHARED,MAP_PRIVATE,MAP_ANONYMOUS等。
PRIVATE:私有意味着修改内容触发写时复制,进程独自拥有不共享物理page。
MAP_SHARED:何谓共享,即缺页时不会触发写时复制,只要在原来的page内容上修改即可。分为文件共享和匿名共享:
文件共享:其中任何已进程的改动其他进程可见(因为多个进程映射的是一样的物理page,自然互相可见),且内容的修改会同步磁盘文件。
匿名共享:跟文件共享的区别没有映射磁盘文件,多进程之间还是映射一样的物理page,所以也可以互相可见,经常用来进程间通信。内核底层通过shmem实现。
MAP_PRIVATE: 何谓私有,修改页面触发写时复制,这样每个进程有自己独立的物理内存page,也就是私有。分为文件私有和匿名私有:
文件私有:一个进程修改文件会触发写时复制,其他进程不会看到映射内容的改变,修改内容也不会回写磁盘,最常见的场景是加载动态库。
匿名私有:不映射文件,修改内容触发写时复制。
mmap内核系统调用源码剖析之prot和flags
我们看下flags和prot两个参数具体是怎么影响vma和pte的:
mm/mmap.c
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate, struct list_head *uf)
{
...
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
//prot是mmap函数的prot参数,下面函数将prot转换成vm_flags相关的flag
vm_flags = calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (file) {
...
switch (flags & MAP_TYPE) {
case MAP_SHARED:
/*
* Force use of MAP_SHARED_VALIDATE with non-legacy
* flags. E.g. MAP_SYNC is dangerous to use with
* MAP_SHARED as you don't know which consistency model
* you will get. We silently ignore unsupported flags
* with MAP_SHARED to preserve backward compatibility.
*/
flags &= LEGACY_MAP_MASK;
fallthrough;
case MAP_SHARED_VALIDATE:
...
vm_flags |= VM_SHARED | VM_MAYSHARE;
...
case MAP_PRIVATE:
...
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
...
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
...
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf);
...
return addr;
}
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
...
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
//将vm_flags转换成vm_page_prot,看下面mk_pte函数知道,vm_page_prot最终会影响页表项
//读写属性。
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
...
if(file) {
...
//触发fs中的mmap,比如ext4_file_mmap
call_mmap(...);
}
...
}
//内核缺页时候创建pte一般调用mk_pte函数,就是通过vma->vm_page_prot生成pte的相关flag
//比如匿名缺页中断:
static int do_anonymous_page(struct vm_fault *vmf)
{
...
//如果vm_flags没有设置
entry = mk_pte(page, vma->vm_page_prot);
...
}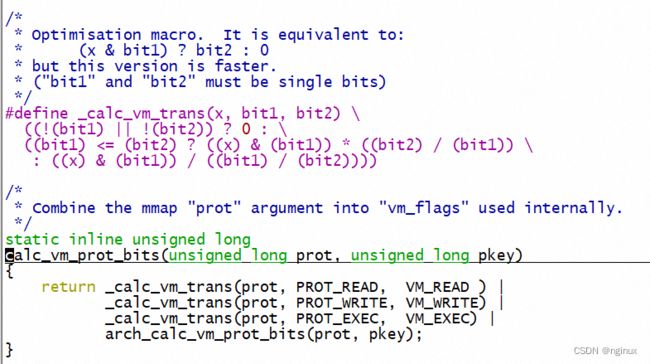
cal_vm_prot_bits转换prot的逻辑也简单,我们知道prot取值为PROT_READ/PROT_WRITE/PROT_EXEC,该函数把prot分别兑换成VM_READ/VM_WRITE/VM_EXEC。
总结:最终vm_flags融合了读写相关的属性(来自cal_vm_prot_bits转换的mmap函数的prot参数)和共享属性(源自mmap函数flag参数),最终vm_flags影响vma和pte的flag。
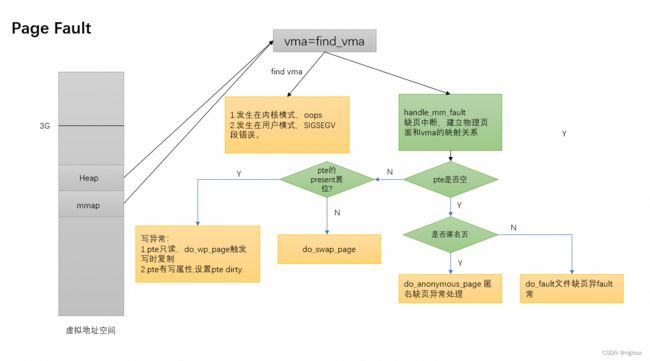
缺页中断流程层次图
 源码:
源码:
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
* RISC architectures). The early dirtying is also good on the i386.
*
* There is also a hook called "update_mmu_cache()" that architectures
* with external mmu caches can use to update those (ie the Sparc or
* PowerPC hashed page tables that act as extended TLBs).
*
* We enter with non-exclusive mmap_lock (to exclude vma changes, but allow
* concurrent faults).
*
* The mmap_lock may have been released depending on flags and our return value.
* See filemap_fault() and __lock_page_or_retry().
*/
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
...
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry))) {
update_mmu_tlb(vmf->vma, vmf->address, vmf->pte);
goto unlock;
}
if (vmf->flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(vmf);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
/* Skip spurious TLB flush for retried page fault */
if (vmf->flags & FAULT_FLAG_TRIED)
goto unlock;
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}调用栈(以匿名页缺页中断为例):
#0 0xffffffff813988ff in do_anonymous_page (vmf=) at mm/memory.c:4409
#1 handle_pte_fault (vmf=) at mm/memory.c:4367
#2 __handle_mm_fault (flags=, address=, vma=) at mm/memory.c:4504
#3 handle_mm_fault (vma=, address=12040240, flags=, regs=) at mm/memory.c:4602
#4 0xffffffff8114b2a4 in do_user_addr_fault (regs=0xffff8880045fff58, hw_error_code=6, address=12040240) at arch/x86/mm/fault.c:1372
#5 0xffffffff824e4c09 in handle_page_fault (address=, error_code=, regs=) at arch/x86/mm/fault.c:1429
#6 exc_page_fault (regs=0xffff8880045fff58, error_code=6) at arch/x86/mm/fault.c:1482
#7 0xffffffff82600ace in asm_exc_page_fault () at ./arch/x86/include/asm/idtentry.h:538
我们知道缺页中断本质上也是一个缺页异常,cpu处理这种异常会分发到特定的异常处理函数,比如这里调用到exc_page_fault,最终就会调用进入do_anonymous_page匿名缺页中断。
匿名缺页中断
pte不存在的情况下,如果vma_is_anonymous返回true判定是匿名页:
static inline bool vma_is_anonymous(struct vm_area_struct *vma)
{
return !vma->vm_ops;
}即设置了vma->vm_ops就不是匿名页,vm_ops又是哪里设置的呢? 向上看mmap_region中有call_mmap调用,最终会调用到ext4中具体的mmap函数设置:
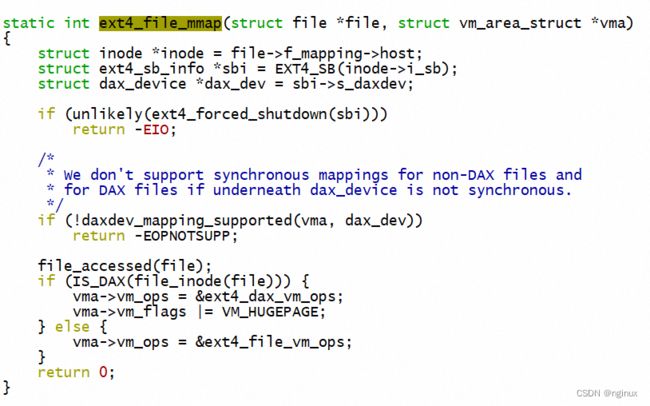
OK,经过上面判定最终确认是匿名缺页(比如mmap函数使用的时候指定了file 映射设置vm_ops,自然不会进入匿名缺页逻辑)。具体匿名缺页函数可以参照如下文章:
Linux 匿名页的生命周期_nginux的博客-CSDN博客
文件缺页中断
如果上面逻辑没有进入匿名缺页,自然进入文件缺页的处理流程,即do_fault函数,文件缺页根据mmap中的flag又多为多种逻辑:
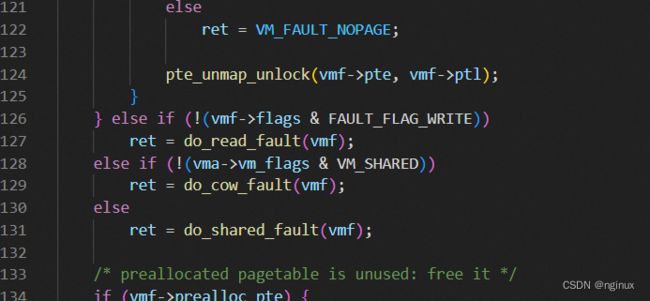
FAULT_FLAG_WRITE根据cpu状态而设置的一个flag,没有置位说明是只读异常,那么调用do_read_fault;否则意味是写异常,又要细分是否为写时复制,如果vm_flags没有设置VM_SHARED意味PRIVATE,调用do_cow_fault触发写时复制,否则为do_share_fault共享。
根据前面分析vm_flags就来自于mmap函数的flag,对这里的写异常,如果设置了MAP_SHARED,那么这里就进入了do_shared_fault,否则是do_cow_fault。
根据mmap使用MAP_SHARED的文件映射,写时缺页会把内容也会写回磁盘,所以我们推测do_shared_fault内部会进行文件回写逻辑:
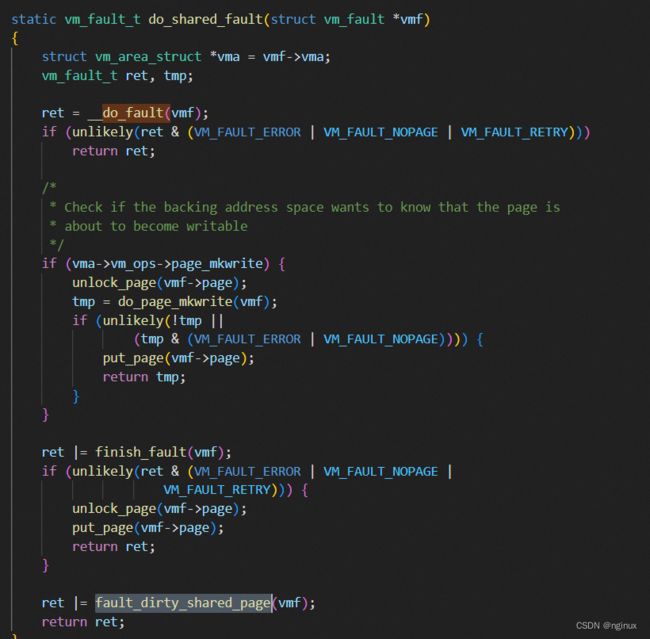
fault_dirty_shared_page来实现这部分逻辑。
do_wp_page
留个坑后面补上
父子进程写时复制的场景
学过操作系统都知道,linux为了性能考虑,fork系统调用子进程并不会完全复制父进程的物理page,两者共享物理内存,同时也比较省内存。只有等任何一方写数据的时候才会触发COW。我们思考如下问题:
如果父进程执行如下流程:
1. addr = mmap(PROT_READ|PROT_WRITE, MAP_PRIVATE)先创建了一个虚拟地址的映射
2. 向addr 写入了数据.
3.fork一个子进程.
4.子进程向addr写入数据触发COW。
理论推导第四步应该会走do_wp_page逻辑,但是要走入整个逻辑要满足如下条件:
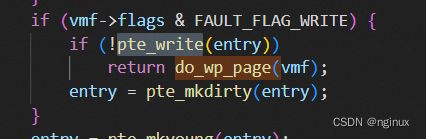
就是说entry页表项必须是不可写的,我们知道我们mmap的时候明明是设置了PROT_READ | PROT_WRITE明明是可读写,那么第一次缺页创建pte的时候pte也是可读写的,那么到底是哪里将pte修改成只读的?答案:fork系统调用发现是private的私有映射,就会将相应的pte修改成只读。
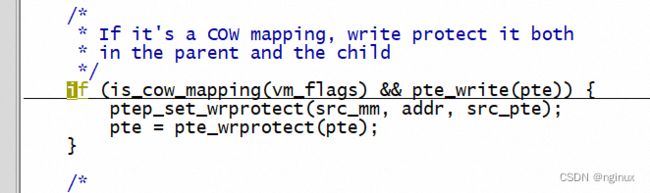

参考文章:
Linux内核虚拟内存管理之匿名映射缺页异常分析_vm_get_page_prot_零声教育的博客-CSDN博客
详细讲解Linux内核写时复制技术COW机制(手撕源代码) - 知乎