Cortex-M3权威指南(中文)个人纪录
STM32F103 FreeRTOS开发手册V1.1.pdf-免费下载
阿里云盘:https://www.aliyundrive.com/s/usDAT7UyNCy 提取码:jwQw
单指令流多数据流(Single Instruction Multiple Data,SIMD)指令是一种并行计算的方式,它可以执行相同的指令,但对不同的数据进行操作,实现高效的数据处理。
SIMD指令通常在向量处理器、图形处理器(GPU)、数字信号处理器(DSP)等硬件中广泛使用。它可以将多个数据元素打包成一个向量(或者矩阵),并以单条指令的形式对向量中的每个元素并行地进行相同的操作。
举例来说,对于一个长度为N的向量V和一个标量s,如果需要对向量V中的每个元素都加上s,则传统的CPU需要使用循环结构并对每个元素依次进行加法运算。而使用SIMD指令则可以将V中的多个元素打包成向量,以单条指令的形式对整个向量进行加法运算,从而大大提高了运算速度。
同时,SIMD指令还支持多种数据类型和操作,如整数、浮点数、乘法、除法、逻辑运算等,可以适用于各种不同类型的应用场景。
处理器命名法 以前,ARM使用一种基于数字的命名法。在早期(1990s),还在数字后面添加字母后 缀,用来进一步明细该处理器支持的特性。就拿ARM7TDMI来说,T代表Thumb指令集,D是 说支持JTAG调试(Debugging),M意指快速乘法器,I则对应一个嵌入式ICE模块。
由于历史原因(从ARM7TDMI开始),ARM处理器一直支持两种形式上相对独立的指令集,它们分别是:
32位的ARM指令集。对应处理器状态:ARM状态
16位的Thumb指令集。对应处理器状态:Thumb状态
A:可以做到这样,主要是因为在ARM处理器的架构中,Thumb指令集是基于ARM指令集的一个子集。也就是说,所有的Thumb指令都可以被解释为对应的ARM指令,而且它们之间的转换是可以在硬件上直接实现的。通过这种方式,处理器就可以在不同的指令集之间自由切换,而不需要进行复杂的状态切换操作,从而提高了处理器的效率,并且简化了开发人员的工作。另外,通过这种方式,处理器还能够更好地适应不同的应用场景和需求,达到更好的性能和功耗平衡。
CM3的出现, 还在ARM处理器中破天荒地支持了“非对齐数据访问支持”
A:在ARM处理器架构中,Cortex-M3处理器的出现让“非对齐数据访问支持”成为了可能。在之前的ARM体系结构中,如果使用LDR或STR指令来访问非对齐的数据,就会导致系统异常。但是,在Cortex-M3处理器中,引入了硬件支持的“非对齐数据访问”,使得处理器可以直接访问非对齐的内存数据,这样就可以提高数据的读写效率,同时也可以方便地处理一些特定的应用场景,比如网络通信、多媒体处理等。需要注意的是,尽管Cortex-M3处理器支持非对齐数据访问,但在某些处理器中,对于非对齐的数据访问仍然可能会导致异常。因此,在进行非对齐访问时,需要根据具体的处理器类型和应用需求进行判断,并进行相应的处理。
Cortex-M3处理器采用了哈佛结构,这是一种存储器结构,它将指令内存和数据内存分开存放,从而可以在同一时间内同时访问指令和数据。这样做有助于提高处理器的执行效率,因为数据和指令可以分别被加载到不同的缓存中,从而避免了不同类型数据之间的竞争访问。
具体来说,Cortex-M3处理器使用了两个独立的存储器总线,一个用于访问指令内存,另一个用于访问数据内存。这样就可以实现指令和数据的同时访问,并且可以提高处理器的吞吐量。
需要注意的是,哈佛结构虽然可以提高处理器的执行效率,但也存在一些限制。比如,由于指令和数据存储器是分开的,所以不能直接在指令中访问数据存储器中的数据,必须通过特定的指令进行访问,从而增加了编程的复杂度。此外,由于存储器的物理地址不同,还需要进行地址映射等相关工作,从而增加了处理器的设计难度。
比较复杂的应用可能需要更多的存储系统功能,为此 CM3 提供一个可选的 MPU,而且在需要 的情况下也可以使用外部的 cache。另外在 CM3 中,Both 小端模式和大端模式都是支持的。
A:
Little-Endian(小端模式)和Big-Endian(大端模式)是两种不同的字节序,用于确定多字节数据的存储顺序。在计算机系统中,多字节数据(如32位整数、64位浮点数等)通常需要分成多个字节进行存储。字节序指定了这些字节在内存中的排列顺序。
在Little-Endian模式下,较低的字节先存储在内存的低地址处,而较高的字节则存储在更高的地址处。例如,一个32位整数0x12345678,在内存中的表示为0x78 0x56 0x34 0x12。
在Big-Endian模式下,较高的字节先存储在内存的低地址处,而较低的字节则存储在更高的地址处。例如,同样是一个32位整数0x12345678,在内存中的表示为0x12 0x34 0x56 0x78。
这两种字节序在不同的处理器架构和操作系统中都有应用。在一些系统中,如Intel x86架构的计算机和Windows操作系统,使用的是Little-Endian模式;而在一些其他系统中,如PowerPC架构的计算机和Mac OSX操作系统,使用的是Big-Endian模式
Q:访问寄存器和堆栈有什么区别
A:访问寄存器和堆栈是计算机中两种不同的数据访问方式,它们有一些区别。
寄存器是计算机硬件中的一种高速存储器,通常位于处理器内部。寄存器可以直接被CPU指令访问和操作,读写速度非常快,因此可以被用来存储频繁使用的变量、计数器等数据。由于寄存器数量有限,通常只有几十个或者更少,因此寄存器主要用于存储CPU运算过程中的中间结果和临时数据,以提高计算效率。
堆栈是一种后进先出(Last In First Out,LIFO)的数据结构,通常用于存储程序调用、中断处理等过程中的局部变量、函数参数、返回地址等数据。堆栈在程序运行时,可以随着局部变量的作用域结束而弹出(释放),并且可以动态地分配和释放内存空间。然而,由于堆栈位于内存中,因此其访问速度不如寄存器快。
因此,访问寄存器比访问堆栈速度更快,但可用的空间较少;而堆栈则可动态分配空间,但访问速度比寄存器慢。
原文:操作模式和特权极别 Cortex‐M3 处理器支持两种处理器的操作模式,还支持两级特权操作。 两种操作模式分别为:处理者模式(handler mode,以后不再把 handler 中译——译注)和线程模 式(thread mode)。引入两个模式的本意,是用于区别普通应用程序的代码和异常服务例程的代码 ——包括中断服务例程的代码。
解释:
在ARM Cortex-M处理器中,有两种不同的工作模式:处理者模式和线程模式。处理者模式是用于处理中断和异常的,运行在特权级别高的模式下,具备访问系统资源和特殊指令的权限,可以执行所有指令集。而线程模式则是普通的应用程序运行模式,运行在特权级别低的模式下,只有受限的指令集和资源访问权限。
处理者模式主要用于处理中断和异常服务例程的代码,因为这些代码需要优先级最高的CPU执行时间,并且可能需要访问特权级别更高的系统资源。当处理器进入处理者模式时,MSP指向主堆栈,处理器会自动切换到处理者模式堆栈空间分配的堆栈顶部,从而保护当前执行状态。在处理者模式中,中断嵌套也是支持的,可以响应多个中断,并且通过硬件支持的堆栈自动保存和恢复现场。
线程模式则是普通的应用程序运行模式,可供应用程序代码使用,运行在特权级别低的模式下,具有受限的指令集和资源访问权限。在线程模式下,PSP指向当前线程的堆栈,处理器可以为每个线程分配独立的堆栈空间。当线程被调度时,处理器会自动将PSP指向线程堆栈,并恢复线程的执行状态。在线程模式下,中断仍然可以发生,但它们必须安排在某个任务的上下文中处理,无法像在处理者模式下那样立即处理。
总之,处理者模式和线程模式是用于区分异常服务例程和普通应用程序代码的两种不同操作模式。处理者模式拥有更高的特权级别和全权访问系统资源的权限,适合于高优先级的中断服务例程和异常处理;而线程模式则是供普通应用程序使用的模式,可运行多个线程并且支持多任务处理。

Q:ARM Cortex-M3处理器自动定位向量表的含义。
A:ARM Cortex-M3处理器中采用了一种基于向量表(Vector Table)的中断处理方式。当一个中断请求被触发时,ARM Cortex-M3处理器会自动找到配置在系统中的向量表,并从中读取对应的中断服务程序(ISR)入口地址。这里的"自动定位"指的是处理器在硬件层面自动定位向量表的位置,而不需要任何软件干预。由于中断向量表通常需要配置在固定的地址位置上,因此处理器可以通过固定的地址寻址方式来读取中断向量表。
一般情况下,向量表包含了一组中断服务程序的入口地址,每个入口地址对应着一个中断号。当一个中断请求被触发时,ARM Cortex-M3处理器会将中断号作为索引,从向量表中读取对应的中断服务程序入口地址,并跳转至该地址开始执行中断服务程序。这样,就不需要在软件中再额外进行中断类型的判断和寻址操作,大大提高了中断响应速度和系统实时性。
总之,"自动定位一张向量表"表明了ARM Cortex-M3处理器具备了硬件自动定位向量表的能力,能够通过固定地址的方式自动读取对应中断号的中断服务程序入口地址,从而加速中断响应过程。

1mb=1024kb=1024*1024b。
存储器保护单元(MPU):最常见的就是由操作系统使用 MPU,以使特权级代码的数据,包括操作系 统本身的数据不被其它用户程序弄坏。MPU 在保护内存时是按区管理的(“区”的原文是 region,以 后不再中译此名词——译注)。它可以把某些内存 region 设置成只读,从而避免了那里的内容意外被 更改;还可以在多任务系统中把不同任务之间的数据区隔离。
原文:堆栈的 PUSH 与 POP
A:堆栈的 PUSH 和 POP 指令是用来向堆栈中压入数据或者弹出数据的指令。
PUSH 指令通常使用寻址模式和数据大小来决定将哪些数据压入堆栈中。在 Cortex-M3 处理器中,PUSH 指令默认使用当前的堆栈指针(SP 或 PSP),先将 SP 或 PSP 的值减去 4 (32 位处理器),然后将数据存储到新分配的内存位置。如果 PUSH 操作成功,堆栈指针会自动减去相应的偏移量,指向新的堆栈位置。
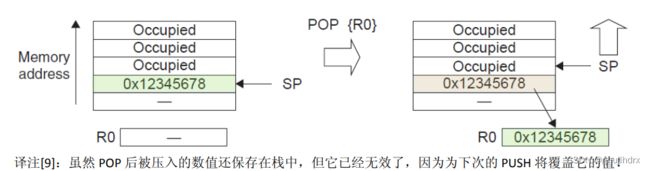
POP 指令的作用与 PUSH 相反,用于从堆栈中弹出数据。POP 指令也可以通过设置寻址模式和数据大小来弹出不同类型的数据。在 Cortex-M3 处理器中,POP 指令也默认使用当前的堆栈指针(SP 或 PSP),从指定地址(SP 或 PSP 加上偏移量)读取数据,并将堆栈指针加上偏移量,恢复之前的堆栈位置。
需要注意的是,在使用堆栈时,需要遵循特定的堆栈规则以确保堆栈操作的正确性和安全性。例如,在 PUSH 操作之前需要检查堆栈指针是否越界,以及在 POP 操作之后需要对弹出的数据进行适当的清理和释放。同时,在多任务应用程序中,还需要考虑到堆栈的切换和保护问题,以确保任务之间不会发生数据冲突或者竞争问题。
Q:先将 SP 或 PSP 的值减去 4 (32 位处理器)为甚么这样做
A:在 Cortex-M3 处理器中,使用 PUSH 指令将数据压入堆栈时,通常会先将 SP 或 PSP 的值减去 4 (32 位处理器),然后将数据存储到新分配的内存位置。
这样做是因为,在堆栈结构中,每个单元通常只能存储一个数据,而在 Cortex-M3 处理器中,每个数据项的大小为 4 个字节(32 位处理器)。因此,需要将堆栈指针减去 4,以分配一个新的堆栈单元,用于存储下一个数据项。
例如,假设当前的堆栈指针值为 0x2000 0000,如果要将一个 32 位的整数值 0xABCD 存储到堆栈中,那么先将堆栈指针减去 4,即变为 0x1FFF FFFC,然后将整数值 0xABCD 存储到该地址中。这样做的结果是,堆栈指针现在指向了刚刚存储的整数值的地址,同时预留了下一个堆栈单元的空间。
需要注意的是,在使用 PUSH 操作时,一定要确保堆栈指针没有越界,以及新分配的堆栈单元不会与其他数据项重叠或者覆盖。否则,可能会导致数据损坏或者系统崩溃等问题。
Q:当前堆栈指针的值就指向了刚刚存储的整数值的位置为甚么
A:当前堆栈指针的值指向了刚刚存储的整数值的位置,是因为在存储一个数据项时,需要在堆栈中分配一段内存来保存这个数据项。根据堆栈的特性,数据项需要按照后进先出的顺序放置在堆栈中,所以对于每一个新的数据项,都需要将堆栈指针向下移动,以便为新的数据项腾出空间。同时,当前堆栈指针的位置就是最新入栈的数据项的地址。
具体来说,当需要将一个数据项入栈(例如一个 32 位的整数值)时,首先需要将堆栈指针减去 4,这样当前堆栈指针就指向了即将存储数据项的内存位置。然后,将要存储的数据项存储到当前堆栈指针所指向的位置。由于数据项的大小为 4 字节,所以当前堆栈指针的值就指向了刚刚存储的整数值的位置。
这种方式可以确保每一个数据项都被正确地存储在堆栈中,并且堆栈指针始终指向最新入栈的数据项的地址,以便可以方便地操作这些数据项。在后续的程序执行过程中,如果需要访问堆栈中的数据项,只需要使用堆栈指针偏移量的方式即可,如 POP 操作就是通过增加堆栈指针来弹出最新入栈的数据项。
原文:因为 CM3 内部 使用了指令流水线,读 PC 时返回的值是当前指令的地址+4。
A:在 CM3 中,读取程序计数器寄存器(PC)时会返回当前指令的地址加上 4。这是因为在指令执行过程中,下一条指令已经被预取出并准备好执行,所以当前指令的地址加上 4 就对应着下一条指令的地址。
原文:如果向 PC 中写数据,就会引起一次程序的分支(但是不更新 LR 寄存器)。CM3 中的指 令至少是半字对齐的,所以 PC 的 LSB 总是读回 0。然而,在分支时,无论是直接写 PC 的值 还是使用分支指令,都必须保证加载到 PC 的数值是奇数(即 LSB=1),用以表明这是在 Thumb 状态下执行。倘若写了 0,则视为企图转入 ARM 模式,CM3 将产生一个 fault 异 常。
原文:在特权级下的代码可以通过置位 CONTROL[0]来进入用户级。而不管是任何原因产生了 任何异常,处理器都将以特权级来运行其服务例程,异常返回后将回到产生异常之前的特权 级。用户级下的代码不能再试图修改 CONTROL[0]来回到特权级。它必须通过一个异常 handler, 由那个异常 handler 来修改 CONTROL[0],才能在返回到线程模式后拿到特权级。
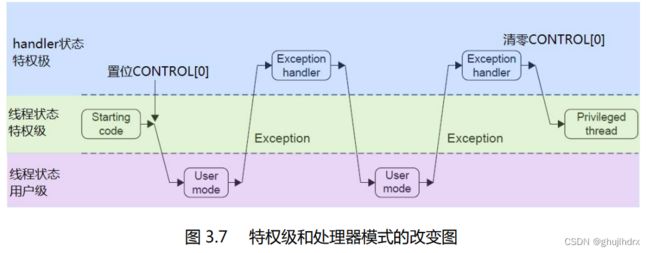
线程状态是处理器正常运行时所处的工作模式,也称为用户模式或者非特权模式。在线程状态下,CPU 可以访问所有的寄存器、内存区域、外设设备等资源,并且可以执行所有的 ARM 指令和 Thumb 指令。线程状态下所有的中断都是可用的,但中断处理程序会在返回时重新启用中断。
handler 状态是当处理器响应中断、异常或者其他外部事件时所处的工作模式,也称为特权模式或者异常模式。在 handler 状态下,CPU 进入特殊的执行流程,必须遵循一些额外的约束和限制。首先,CPU 会切换到另一个堆栈中,以保护当前线程的堆栈不被破坏。其次,CPU 只能访问一些受限的寄存器和内存区域,例如 PRIMASK、FAULTMASK、BASEPRI 等特殊寄存器和用于异常处理的向量表等。此外,在 handler 状态下,所有的中断都是禁止的,直到中断处理程序执行完毕并从 handler 状态返回到线程状态时才会重新启用中断。
Q:MPU是什么
A:MPU 即 Memory Protection Unit,是一种硬件辅助的内存保护机制,在 ARM Cortex-M 处理器中很常见。
MPU 的作用是检测和阻止非法的内存访问请求,从而保护系统的安全性和稳定性。通过配置 MPU,可以将系统内存划分为多个独立的、不重叠的区域,并为每个区域分别设置读、写、执行等访问属性和权限。当 CPU 执行内存访问指令时,MPU 会自动检查该指令所涉及的内存地址和操作类型,如果存在非法的访问请求(例如读取或者写入受保护的内存区域,或者执行位于只读内存区域的代码),则会产生一个异常并向上报告,由 CPU 或者异常处理程序来处理这个异常。
原文:Cortex‐M3 支持大量异常,包括 16‐4‐1=11 个系统异常
Q:哪些异常?
A:Cortex-M3 确实支持大量异常。具体来说,Cortex-M3 支持 15 种可编程异常和 1 种固定异常,共计 16 种异常。
其中,可编程异常分为 4 类,每类异常都有自己的编号,并且可以被用户进行配置和使用。这 4 类异常包括:
- 2 种优先级非唯一的中断请求(IRQ):可以被外部中断或者内部软件触发,分别对应编号 0 和 1。
- 2 种优先级唯一的中断请求(NMI):可以被外部中断触发,但无法被软件触发,分别对应编号 2 和 3。
- 12 种硬件故障异常(Faults):可以被由硬件触发的异常事件(如内存访问错误、数据解析错误等)触发,分别对应编号 4 至 15。
另外,Cortex-M3 中还有一种固定的异常 SVC(Supervisor Call),它是用于实现进程间通信和系统调用的机制,编号为 11。因此,Cortex-M3 一共支持 16-4-1=11 个系统异常
Q:发生了异常 11(SVC),则 NVIC 会计算出偏移移量是 11x4=0x2C为什么是x4
A:在 Cortex-M 系列中,每个异常向量表的项大小为 4 字节。这意味着,每个向量表中的条目地址都是按照 4 字节对齐的。
当发生 SVC 异常时,CPU 会将当前的指令地址存储到特定的寄存器中,并切换到处理模式。此时,NVIC 将会根据发生的异常类型 11(SVC)来计算该异常在向量表中的偏移量。由于每个向量表中的条目地址都是按照 4 字节对齐的,因此,NVIC 计算得出的偏移量需要乘以 4 才能得到正确的字节偏移量。
具体来说,对于异常类型为 i 的向量表项,在向量表中的偏移量为 i×4,其中 ×4 表示每个向量表项的大小为 4 字节。因此,在本例中,异常类型为 11(即 SVC 异常)的向量表项在向量表中的偏移量为 11×4=0x2C,也就是 44 字节的位置。在计算完偏移量之后,NVIC 将从向量表的 0x2C 处读取 SVC 异常处理程序的入口地址,然后开始执行该程序。
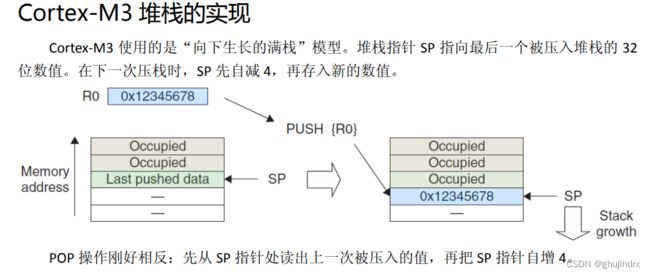
“向下生长的满栈”(Full Descending Stack)是一种常见的栈数据结构模型,通常用于描述一些计算机体系结构的堆栈实现。在该模型中,堆栈的内存地址是向下生长的,即栈顶的地址比栈底的地址要小。
具体来说,在该模型下,当程序首次启动时,整个内存空间都可以被认为是栈空间。栈指针(Stack Pointer)指向栈顶的地址,而栈底的地址是固定的(如某个固定内存区域的起始地址),所有的数据都从栈顶地址开始往下生长。