Redis 核心知识——01
目录标题
-
- 一、redis基础
-
- 1、docker搭建rides
- 2、共有的命令
-
- 2.1对key
- 2.2对db库
- 3、redis——Value的五种数据类型
-
- 3.1、String(字符串)
- 3.2、list(列表)
-
- list常用命令
- 3.3、hash(哈希)
- 3.4、set(集合)
- 3.5、zset(有序集合)
- 发布订阅
- 二、Jedis
-
- 1、导入依赖
- 2、使用Jedis
- 三、spring-boot整合redis
-
- 1、导入依赖
- 2、配置(config)bean
- 3、配置redis基础信息
- 4、测试
- 四、redis事务
-
- 1、Multi(开启事务)、Exec(执行事务)、discard(放弃组队)
- 五、锁——watch()
- 六、redis秒杀demo
-
- 1、有库存遗留
- 2、使用lua脚本解决库存遗留问题
- 七、持久化redis数据
-
- 1、RDB——每隔一段时间备份redis的数据
-
- 1.1、首先找到这几个文件
- 1.2、修改redis.conf的rdb持久化方式的配置
- 1.3、开启备份
- 1.4、恢复数据
- 2、AOF——每次修改key都会向aof文件中追加数据和记录操作指令
-
- 2.1、开启AOF持久化模式
- 2.2、恢复数据
- 2.3、AOF文件损坏恢复
- 2.4、AOF同步备份频率
- 2.5、AOF的优缺点
- 2.6、AOF于RDB的区别
- 2.7、如何选择AOF于RDB
- 八、面试笔记
redis2(主从复制、集群、分布式锁)
一、redis基础
1、docker搭建rides
docker搭建rides
2、共有的命令
- redis-cli —— 开打redis客户端
- auth 密码 —— 登录redis
2.1对key
- del key —— 删除key,也可以同时删除多个key
- dump key —— 序列化指定的key的值,并返回(转换成byte[ ])
- exists key ——判断key是否存在
- expire key seconds 以秒为单位,设置过期时间
- expireat key timestamp 以毫秒为单位(时间戳),设置过期时间
- persist key —— 移除过期时间
- ttl key —— 返回过期时间,以秒为单位
- pttl key —— 返回过期时间,以毫秒为单位
- keys (str)检索规则 —— 查询所有符合规则的key,这里的检索规则似乎只能用*, 表示多个
- randomkey ——从当前库中 随机返回一个key
- renamenx key newkey —— 当newkey不存在时,将key的名字改成newkey
- type key —— 返回key的数据类型
127.0.0.1:6379> keys *
1) "a22"
2) "s"
3) "1as1"
4) "as11"
127.0.0.1:6379> keys a*
1) "a22"
2) "as11"
127.0.0.1:6379> keys *s*
1) "s"
2) "1as1"
3) "as11"
127.0.0.1:6379> keys *1
1) "1as1"
2) "as11"
127.0.0.1:6379>
- move key db —— 将key移到指定的库
2.2对db库
- flushall —— 清空所有库的所有key
- flushdb —— 清空当前库的所有key
- select index —— 切换库,一共有16个库,默认为0库,index:[0,15]
3、redis——Value的五种数据类型
3.1、String(字符串)
- String类型常用命令
- set key value
- setex key time value ——设置一个key的同时设置过期时间,以秒为单位
- get key
- getrange key start end ——截取指定key的值的一段值(双闭区间)
- mget key1 key2… ——获取多个key的值
- mset key1 value1 key2 value2 key3 value3…——设置一组key value
- incr key(要求key里面的value为数字)——自增1
- incrby key increment —— 指定要增加多少值
- decr key(要求key里面的value为数字) —— 自减1
- decrby key decrement——指定要减少多少值
- strtlen key ——返回key中的值的长度
- getset key newvalue ——返回指定key的旧值,设置新值
- append key value——在后面追加值
127.0.0.1:6379> set sum 0 #注意:这里的数字虽然没有加引号,但是也会默认为String类型
OK
127.0.0.1:6379> INCR sum
(integer) 1
127.0.0.1:6379> get sum
"1"
127.0.0.1:6379> set str_sum "2"
OK
127.0.0.1:6379> INCR str_sum
(integer) 3
127.0.0.1:6379>
127.0.0.1:6379> set str "123ad李"
OK
127.0.0.1:6379> INCR str #String类型只有当value全为数字时才能就自增(行算数运算)
(error) ERR value is not an integer or out of range
127.0.0.1:6379>
注意:
1、incr 和decr 只有当字符串里面全为数字时才能自增自减成功
3.2、list(列表)
- list 相当于堆栈,具有先进后出的特点。list类型value为一个列表,里面有许多单列元素,hash是两列
注意:
- 创建:当push第一个元素是就会创建key
- 销毁:当pop最后一个元素后key就会消失
list常用命令
- 增 :lpush key value1 (也可以同时增加多个)
- 删:lrem count value
(注:count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
count = 0 : 移除表中所有与 VALUE 相等的值。) - 改:lset key index value (根据指定的下标位置修改值)
- 查:lindex key index (根据下标位置查找元素)
- 入栈:lpush key value
- 出栈:lpop key
3.3、hash(哈希)
- hash常用于存储java对象
- hash类型中value是一个集合,每个元素都是一个key,value对
127.0.0.1:6379> hset person id 1 name lihua age 18
(integer) 3
127.0.0.1:6379> hget person id
"1"
127.0.0.1:6379> hgetall person
1) "id"
2) "1"
3) "name"
4) "lihua"
5) "age"
6) "18"
127.0.0.1:6379>
- hash常用命令(与String的命令相似,命令前面多了一个h)
- hset key hash_key1 hash_value1 hash_key2 hash_value2 —— 设置一个hash类型的key
127.0.0.1:6379> hset person id 1 name lihua age 18
(integer) 3
- hget key hash_key —— 获取key中指定hash值的hash_value
127.0.0.1:6379> hget person id
"1"
- hgetall key —— 获取指定key的所有hash值的value
127.0.0.1:6379> hgetall person
1) "id"
2) "1"
3) "name"
4) "lihua"
5) "age"
6) "18"
- hdel key hash_key —— 删除key中hash表中的指定字段,可以删除多个
127.0.0.1:6379> hdel person age
(integer) 1
127.0.0.1:6379> hgetall person
1) "id"
2) "1"
3) "name"
4) "lihua"
- hexists key hash_key —— 查看key中的hash表是否存在指定的字段
127.0.0.1:6379> hexists person aaa
(integer) 0
- hkeys key —— 指定key的hash表中所有的hash_key
- hvals key —— 指定key的hash表中所有的hash_value
- hmset key hash_set1 hash_value1 hash_set2 hash_value2 —— 与hset的功能相似,设置多个[ hash_set,hash_value ]
- hmget key hash_key1 hash_key2… —— 获取hash表中的多个字段
3.4、set(集合)
- set无序、不可重复的集合。当添加重复元素时会添加失败并返回0(添加成功返回1)。
- 常见命令:
- 增:sadd key value1 value2… ( 当添加第一个是会创建set集合 )
- 查:smembers key (查询所有元素)
- 删:srem key value (删除指定的元素)
- 差集:sdiff key1 key2 (返回两个集合的差集)
- 存储差集:sdiffstore key key1 key2 (返回两个集合的差集,并保存到key中,如果key已经存在会覆盖key,不存在会创建)
- 交集 sinter key1 key2 key3… (返回指定集合的交集)
- 并集:sunion key1 key2 key3… (返回并集)
- 存储并集:sunionstore key key1 key2 key3… (返回并集,并存储到key中,如果key已经存在会覆盖key,不存在会创建)
- 移除返回一个随机的元素:spop key (获取一个元素,因为是无序的所以随机返回一个)
- 移动元素到另一个集合:smove source_key destination_key value
3.5、zset(有序集合)
- zset 有序、不可重复的集合
zset 通过给每个元素一个“分数”进行排序。
| 序号 | 命令及描述 |
|---|---|
| 1 add | zadd key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | zcard key 获取有序集合的成员数 |
| 3 | zcount key min max 计算在有序集合中指定区间分数的成员数 |
| 4 | zincrby key increment member 有序集合中对指定成员的分数加上增量 increment |
| 5 | zinterstore destination numkeys key [key ...] 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 destination 中 |
| 6 | zlexcount key min max 在有序集合中计算指定字典区间内成员数量 |
| 7 | zrange key start stop [WITHSCORES] 通过索引区间返回有序集合指定区间内的成员 |
| 8 | zrangebylex key min max [LIMIT offset count] 通过字典区间返回有序集合的成员 |
| 9 | zrangebyscore key min max [WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员 |
| 11 del | zrem key member [member ...] 移除有序集合中的一个或多个成员 |
| 12 del | zremrangebylex key min max 移除有序集合中给定的字典区间的所有成员 |
| 13 del | zremrangebyrank key start stop 移除有序集合中给定的排名区间的所有成员 |
| 14 del | zremrangebyscore key min max 移除有序集合中给定的分数区间的所有成员 |
| 10 query | zrank key member 返回有序集合中指定成员的索引 |
| 15 queryAll | zrevrange key start stop [WITHSCORES] 返回有序集中指定区间内的成员,通过索引,分数从高到低 从0开始,-1为最后一个。 |
| 16 query | zrevrangebyscore key max min [WITHSCORES] 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 17 query | zrevrank key member 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 18 query | zscore key member 返回有序集中,成员的分数值 |
| 19 | zunionstore destination numkeys key [key ...] 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| 20 | zscan key cursor [MATCH pattern] [COUNT count] 迭代有序集合中的元素(包括元素成员和元素分值) |
发布订阅
| 序号 | 命令及描述 |
|---|---|
| 1 | subscribe channel [channel ...] 订阅给定的一个或多个频道的信息。 |
| 2 | unsubscribe [channel [channel ...]] 指退订给定的频道。 |
| 3 | publish channel message 将信息发送到指定的频道。 |
| 4 | pubsub subcommand [argument [argument ...]] 查看订阅与发布系统状态。 |
| 5 | psubscribe pattern [pattern ...] 订阅一个或多个符合给定模式的频道。 |
| 6 | punsubscribe [pattern [pattern ...]] 退订所有给定模式的频道。 |
二、Jedis
1、导入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
<version>2.3.7.RELEASEversion>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
<version>2.6.2version>
dependency>
2、使用Jedis
package com.lihua.jedis;
import redis.clients.jedis.Jedis;
import java.util.List;
import java.util.Random;
/**
* 通过Jedis操作redis
* @author 15594
*/
public class JedisTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("ip",6379);
jedis.auth("123");
jedis.set("key","value");
String value = jedis.get("key");
jedis.mset("1","2","3","4");
List<String> mget = jedis.mget("*");
}
}
三、spring-boot整合redis
1、导入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
<version>2.3.7.RELEASEversion>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
<version>2.6.2version>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.3version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.2.5version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.47version>
dependency>
2、配置(config)bean
package com.lihua.springbootredis.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
/**
* rides配置类
* @author 15594
*/
@EnableCaching
@Configuration
public class RidesConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
3、配置redis基础信息
server.port=8090
#Redis服务器地址
spring.redis.host=主机ip
#Redis服务器连接端口
spring.redis.port=6379
#登录服务器的代码
spring.redis.password=123
#Redis数据库索引(默认位0)
spring.redis.database=0
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(复数表示没有限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
4、测试
package com.lihua.springbootredis.controller;
import com.lihua.springbootredis.utils.RedisUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.stereotype.Repository;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
/**
* @author 15594
*/
@RestController
public class HelloRedisController {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private RedisUtils redisUtils;
@GetMapping("/hello")
public String helloRedis(){
redisTemplate.opsForValue().set("name","lihua");
String name = (String) redisTemplate.opsForValue().get("name");
return name;
}
}
四、redis事务
- redis事务时一个单独的操作,redis的事务在执行过程中不会被其他命令打断
- redis的事务主要作用是串联多个命令(多个操作),将他们加入队列,让他们依次执行。过程中不会没其他命令打断
- redis在组队过程中,命令并不会执行,只有执行Exec操作时才会执行队列里面的命令
- 队列里面的命令会按照加入的顺序依次执行
- 当加入队列的命令出错时:
1、加入队列的命令有语法上的错误(类似于java的编译错误),加入队列的命令(操作)全部都不会执行
2、加入队列的命令有逻辑上的错误(类似于java的运行时错误),加入队列的命令(操作)没有错误的命令(操作)会执行成功,有错误的命令会执行失败
总结:
1、单独的隔离操作,事务执行过程中不会被打断。
2、没有隔离级别。
3、不保证原子性,即当加入事务的某些操作出错时,不影响其他操作。(原子性:不会存在一些操作成功,一些失败,这些操作宏观上是一个整体。)
4、单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
127.0.0.1:6379(TX)> set 1 123
QUEUED
127.0.0.1:6379(TX)> set 2
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379(TX)> set 3 123
QUEUED
127.0.0.1:6379(TX)> exec # 有编译错误,队列的命令全部执行失败
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379>
127.0.0.1:6379(TX)> set str v1
QUEUED
127.0.0.1:6379(TX)> INCR str # 让str自增,因为无法确认str的类型,因此自增会失败
QUEUED
127.0.0.1:6379(TX)> set i 1
QUEUED
127.0.0.1:6379(TX)> INCR i
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) (error) ERR value is not an integer or out of range # 只有一个执行失败
3) OK
4) (integer) 2
127.0.0.1:6379>
1、Multi(开启事务)、Exec(执行事务)、discard(放弃组队)
127.0.0.1:6379> MULTI # 开启事务
OK
127.0.0.1:6379(TX)> set key1 1 #在执行事务前,会将每个操作加入事务的队列
QUEUED
127.0.0.1:6379(TX)> set key2 3 #在执行事务前,会将每个操作加入事务的队列
QUEUED
127.0.0.1:6379(TX)> set key3 2 #在执行事务前,会将每个操作加入事务的队列
QUEUED
127.0.0.1:6379(TX)> exec # 执行事务
1) OK
2) OK
3) OK
五、锁——watch()
1、redis里面的锁是乐观锁,但是这个乐观锁,没有实现自旋。即只进行一次cas算法,当失败时会中断事务。
2、Redis Watch 命令用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断,也就是当被加锁的key被其他线程修改后,那么该线程的所有命令会被中断,全部执行失败。相当于加了锁之后让redis有了原子性,能够回滚事务。
六、redis秒杀demo
1、有库存遗留
/**
* 有库存遗留,因为redis的乐观锁,没有实现自旋,因此当线程同时抢购失败后就不会再次发起抢购,所有会有库存遗留
* */
@GetMapping("/spike")
public JsonData spike(){
//获取随机userId
String userId = new Random().nextInt(50000) +"" ;
//本次抢购商品的id
String goodsId = "goods001";
//商品库存——用String类型存放
String kc = "sk:"+goodsId+":ck";
//抢购成功名单——用set类型存放
String successList= "sk:"+goodsId+":user";
JedisPool jedisPoolInstance = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = jedisPoolInstance.getResource();
//表示秒杀还没有开始
if (jedis.get(kc)==null){
System.out.println("秒杀还没有开始");
jedis.close();
return JsonData.buildSuccess(new String("秒杀还没有开始"));
}
/**
对key上乐观锁,注意加了锁后,后面所有对这个key的所有操作都会被监视,包括get 。
jedis.watch(kc);必须放到判断是否有库存前,否则会超卖,我也不知道为社么。
可能是,对key进行watch之后,线程就会拿到key的值、当进行CAS时就会拿此时这个值进行比较
**/
jedis.watch(kc);
if (Integer.parseInt(jedis.get(kc))<=0){
System.out.println("库存不足");
jedis.close();
return JsonData.buildSuccess(new String("库存不足"));
}
//用户是否秒杀过
if (jedis.sismember(successList,userId)){
System.out.println("不能重复秒杀");
jedis.close();
return JsonData.buildSuccess(new String("不能重复秒杀"));
}
System.out.println(jedis.get(kc));
//用户可以进行秒杀了,开启事务
Transaction multi = jedis.multi();
//组队操作
//库存减一
multi.decr(kc);
//如果还有库存那么将用户id加入秒杀成功表
multi.sadd(successList,userId);
//执行事务
List<Object> exec = multi.exec();
if(exec == null || exec.size()==0) {
System.out.println("秒杀失败了....");
jedis.close();
return JsonData.buildSuccess(new String("秒杀失败"));
}
System.out.println("秒杀成功");
jedis.close();
return JsonData.buildSuccess(new String("秒杀成功"));
}
2、使用lua脚本解决库存遗留问题
local userid=KEYS[1]; # 传入的参数
local prodid=KEYS[2]; # 传入的参数
local qtkey="sk:"..prodid..":ck";
local usersKey="sk:"..prodid..":user";
local userExists=redis.call("sismember",usersKey,userid);
if tonumber(userExists)== 1 then # 是否抢购过
return 2;
end
local num= redis.call("get" ,qtkey); # 获取库存
if tonumber(num)<=0 then # 判断是否有库存
return 0;
else
redis.call("decr",qtkey); # 库存减一
redis.call("sadd",usersKey,userid); # 将抢购成功的用户加入抢购表
end
return 1;
static String secKillScript ="local userid=KEYS[1];\r\n" +
"local prodid=KEYS[2];\r\n" +
"local qtkey='sk:'..prodid..\":ck\";\r\n" +
"local usersKey='sk:'..prodid..\":user\";\r\n" +
"local userExists=redis.call(\"sismember\",usersKey,userid);\r\n" +
"if tonumber(userExists)==1 then \r\n" +
" return 2;\r\n" +
"end\r\n" +
"local num= redis.call(\"get\" ,qtkey);\r\n" +
"if tonumber(num)<=0 then \r\n" +
" return 0;\r\n" +
"else \r\n" +
" redis.call(\"decr\",qtkey);\r\n" +
" redis.call(\"sadd\",usersKey,userid);\r\n" +
"end\r\n" +
"return 1" ;
/**
* 解决库存遗留,
* 1、最最简单的方法是让每个线程多抢几次(使用递归调用),但是必须设置重复抢购的次数。
* 2、使用lua脚本
* */
@GetMapping("/spikePlus2")
public JsonData spikePlus2(){
JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis=jedispool.getResource();
//获取随机userId
String userId = new Random().nextInt(50000) +"" ;
//本次抢购商品的id
String goodsId = "goods001";
//加载lua脚本
String sha1= jedis.scriptLoad(secKillScript);
Object result= jedis.evalsha(sha1, 2, userId ,goodsId);
String reString=String.valueOf(result);
if ("0".equals( reString ) ) {
System.err.println("已抢空!!");
}else if("1".equals( reString ) ) {
System.out.println("抢购成功!!!!");
}else if("2".equals( reString ) ) {
System.err.println("该用户已抢过!!");
}else{
System.err.println("抢购异常!!");
}
jedis.close();
return JsonData.buildSuccess();
}
七、持久化redis数据
1、RDB——每隔一段时间备份redis的数据
1.1、首先找到这几个文件
- dump.rdb (redis通过rdb进行持久化存放数据的文件,也就是快照)
这个文件会自动生成在你你启动redis的目录下,在哪里启动redis就在哪里生成这个文件。
比如:
root@598fef497cec:/data# redis-cli #在data目录下启动redis,那么就在这里生成rdb这个文件
127.0.0.1:6379> exit
root@598fef497cec:/data# ls
appendonly.aof dump.rdb
root@598fef497cec:/data#
如果使用docker安装的话
可以通过docker inspect 容器名/容器id查看
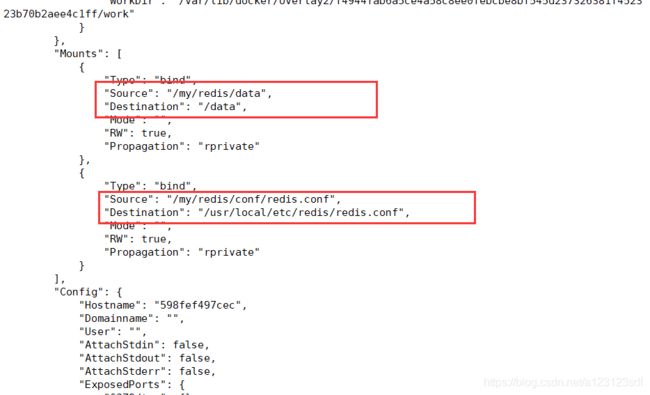
- redis.conf (redis的配置文件)
这个文件在:/usr/local/etc/redis/下
1.2、修改redis.conf的rdb持久化方式的配置
- 找到redis.conf这个文件
[root@iz2zedg4ylq9iqtwm11wecz conf]# cd /my/redis/conf/
[root@iz2zedg4ylq9iqtwm11wecz conf]# ls
redis.conf
[root@iz2zedg4ylq9iqtwm11wecz conf]# pwd
/my/redis/conf
[root@iz2zedg4ylq9iqtwm11wecz conf]#
注意这里时使用docker安装的,因为docker容器自带的Linux系统是阉割版的,没有vim、vi这些编译器,因此通过数据卷,在宿主主机进行修改,配置文件。
[root@iz2zedg4ylq9iqtwm11wecz conf]# vim redis.conf
# 1、然后按/进入搜索模式
# 2、输入save
# 3、按小n查找下一个,大N(shift+n)搜索上一个
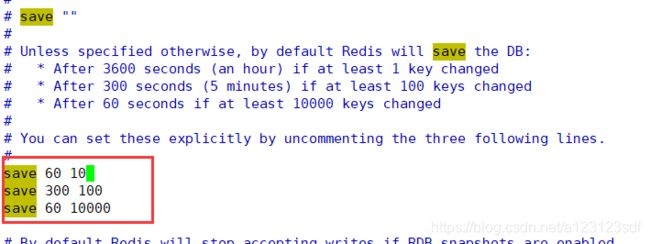
找到他们,这里有rdb存储方式的规则,注意:这些设置默认没有生效,需要我们将注释去掉才能生效
- 在3600秒,如果至少有1个key发生变化(包括修改,新增…key),那么进行一次备份
- 300秒内,至少有100个key发生变化,那么进行一次备份
- 60秒内,至少有10000个key发生变化,那么进行一次备份
- 总结:默认的提供的规则是key变化越多备份的时间间隔越快

1.3、开启备份
-
将上面的注释去掉
-
保存退出
-
重启redis

-
注意rdb方式备份,会丢失最后一次的数据
因为save 60 10 是指,60秒内变化10个key就会备份10个key,假如变化了12个key,那么后面2个key会留到下次备份。

1.4、恢复数据
当重新启动redis后会自动加载rdb文件,就行自动恢复数据。
mset 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 11 12 12
2、AOF——每次修改key都会向aof文件中追加数据和记录操作指令
AOF默认是关闭的。
AOF以日志的形式来记录每个写操作(追加写),不记录读操作。AOF不仅仅会记录数据,还会记录写操作的指令
AOF在启动redis时安照日志,从头到尾执行一次记录的指令,通过这种方式恢复数据
2.1、开启AOF持久化模式
- 修改redis.conf文件
[root@iz2zedg4ylq9iqtwm11wecz conf]# pwd
/my/redis/conf
[root@iz2zedg4ylq9iqtwm11wecz conf]# vim redis.conf
- 搜索appendonly,将no改为yes,就能开启AOF模式。
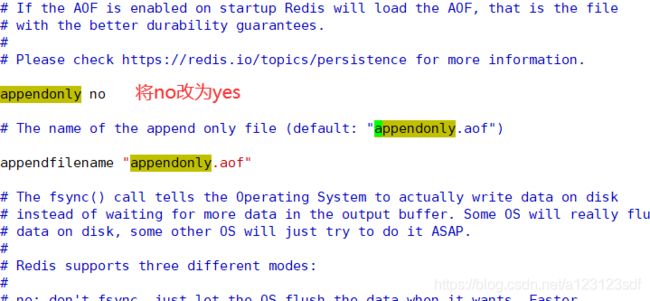
- AOF文件的默认存放路径根RDB一样在redis的启动目录下生成
- 当AOF和RDB同时开启时默认使用AOF
2.2、恢复数据
启动redis时就会根据AOF文件进行恢复数据。
2.3、AOF文件损坏恢复
异常恢复,也就是文件发生异常损坏后,能恢复文件。
-
vim appendonly.aof
-
在后面添加一个没有意义的hello,使得这个aof文件损坏。

-
重启redis-cli
我们会发现redis-cli无法启动。 -
我们找到redis的安装目录
注意:
这里使用docker安装的redis如果aof损坏后是无法打开容器的,也就是无法找到redis的安装目录,除非进行目录挂载。
如果使用docke如果没有将/usr/local/bin这个目录挂载是无法就行修复文件的
root@598fef497cec:/usr/local/bin# pwd
/usr/local/bin
root@598fef497cec:/usr/local/bin# ls
docker-entrypoint.sh redis-benchmark redis-check-rdb redis-sentinel
gosu redis-check-aof redis-cli redis-server
-
在里面的redis-check-aof就是修复aof文件的命令
-
开始修复文件
root@598fef497cec:/data# redis-check-aof --fix /data/appendonly.aof # 注意这里要给出appendonly.aof文件所在目录
0x 7d: Expected prefix '*', got: 'h'
AOF analyzed: size=132, ok_up_to=125, ok_up_to_line=30, diff=7
This will shrink the AOF from 132 bytes, with 7 bytes, to 125 bytes
Continue? [y/N]: y
Successfully truncated AOF # 修复成功
root@598fef497cec:/data#
2.4、AOF同步备份频率
-
在redis.conf 中搜索 appendfsync
-
找到下面的属性
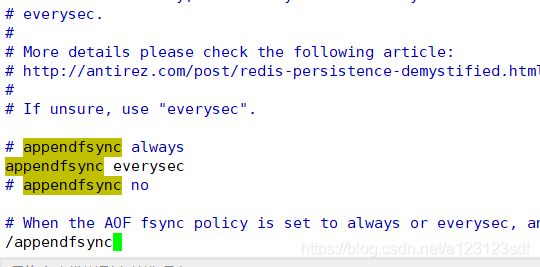
- appendfsync always (每次写入都会立刻计入日记:性能比较差)
- appendfsync everysec (每秒同步,按秒就行同步,本秒的数据可能丢失)
- appendfsync no (不会主动同步,交给操作系统决定)
2.5、AOF的优缺点
缺点:
- 比起RDB占用更多的磁盘空间。(因为里面不仅仅有数据还有写操作的指令)
- 恢复速度慢,因为AOF恢复数据是通过记录的写指令,再次重头运行来达到恢复数据的效果
- 性能比较查(如果启用每次写操作都写入日志的方式)
- 存在个别bug,会使aof不能恢复
优点: - 数据健壮性比较好,相比rdb丢失数据可能性小(或者不丢失)
- 可读的日志文本,可以通过aof文件处理误操作。
aof是默认关闭的。
当rdb和aof同时开启时以aof方式实现持久化。
2.6、AOF于RDB的区别
- rdb是默认的持久化方式
- rdb是同过将要实现持久化的数据写道一个临时文件(写时覆盖技术)中,再将这个临时文件覆盖rdb文件,也就是通过将新数据写入临时文件(临时文件中存在旧的数据),再将临时文件覆盖rdb文件。
- aof是通过追加写的方式实现持久化。
2.7、如何选择AOF于RDB
- 官方两个都推荐开启
- 数据完整性要求不高,使用rdb
- 不推荐直接使用AOF,因为AOF存在bug,可能无法恢复数据
- 如果自作缓存两个都可以不用
注意:当进行flushdb、flushall时会将rdb文件保留的数据清空,但是aof不会清空
八、面试笔记
面试笔记:https://www.cnblogs.com/javazhiyin/p/13839357.html