大家好,我是Iggi。
今天我给大家分享的是MapReduce2-3.1.1版本的Word Count Ver2.0实验。
关于MapReduce的一段文字简介请自行查阅我的上一篇实验示例:MapReduce2-3.1.1 实验示例 单词计数(一)
好,下面进入正题。介绍Java操作MapReduce2组件完成Word Count Ver2.0的操作。
首先,使用IDE建立Maven工程,建立工程时没有特殊说明,按照向导提示点击完成即可。重要的是在pom.xml文件中添加依赖包,内容如下图:
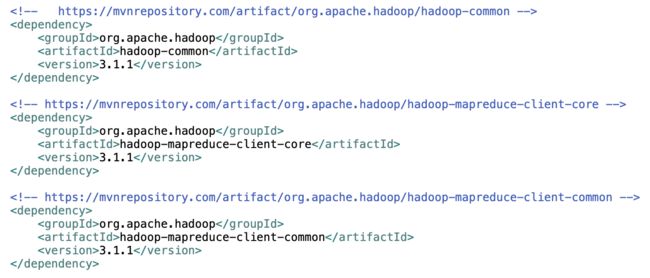
image.png
待系统下载好依赖的jar包后便可以编写程序了。
展示实验代码:
package linose.mapreduce;
import java.io.IOException;
import java.io.OutputStreamWriter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//import org.apache.log4j.BasicConfigurator;
/**
* Hello MapReduce!
* Word Count V2.0
* 本示例演示如何使用MapReduce组件,添加忽略词文件来统计单词出现的个数
* 关于示例中出现的API方法可以参考如下连接:http://hadoop.apache.org/docs/r3.1.1/api/index.html
*/
public class AppVer2
{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
{
/**
* 设定MapReduce示例拥有HDFS的操作权限
*/
System.setProperty("HADOOP_USER_NAME", "hdfs");
/**
* 为了清楚的看到输出结果,暂将集群调试信息缺省。
* 如果想查阅集群调试信息,取消注释即可。
*/
//BasicConfigurator.configure();
/**
* MapReude实验准备阶段:
* 定义HDFS文件路径
*/
String defaultFS = "hdfs://master2.linose.cloud.beijing.com:8020";
String inputPath = defaultFS + "/index.dirs/inputV2.txt";
String outputPath = defaultFS + "/index.dirs/outputV2";
String skipPath = defaultFS + "/index.dirs/patterns.txt";
/**
* 生产配置,并获取HDFS对象
*/
Configuration conf = new Configuration();
conf.set("fs.defaultFS", defaultFS);
FileSystem system = FileSystem.get(conf);
/**
* 定义输入路径,输出路径
*/
Path inputHdfsPath = new Path(inputPath);
Path outputHdfsPath = new Path(outputPath);
Path stopWordPath = new Path(skipPath);
/**
* 如果实验数据文件不存在则创建数据文件
*/
if (!system.exists(inputHdfsPath)) {
FSDataOutputStream outputStream = system.create(inputHdfsPath);
OutputStreamWriter file = new OutputStreamWriter(outputStream);
file.write("芒果 菠萝 西瓜! 橘子, 草莓. \n");
file.write("草莓 橘子 苹果! 荔枝, 蓝莓. \n");
file.write("天天 菇娘 释迦! 软枣子, 癞瓜, 蛇皮果. \n");
file.write("香蕉 菠萝 鸭梨! 柚子, 苹果. \n");
file.write("草莓 橘子 桂圆! 荔枝, 香蕉. \n");
file.write("苹果 菠萝 草莓! 弥猴桃, 芒果. \n");
file.write("苹果 香蕉 提子! 橘子, 菠萝. \n");
file.write("西瓜 苹果 香蕉! 橙子, 提子. \n");
file.write("香蕉 鸭梨 西瓜! 葡萄, 芒果. \n");
file.write("苹果 樱桃 香蕉! 葡萄, 橘子. \n");
file.write("西瓜 葡萄 桃! 车厘子, 香蕉, 榴莲, 瓜, 火龙果, 荔枝. \n");
file.close();
outputStream.close();
}
/**
* 如果实验结果目录存在,遍历文件内容全部删除
*/
if (system.exists(outputHdfsPath)) {
RemoteIterator fsIterator = system.listFiles(outputHdfsPath, true);
LocatedFileStatus fileStatus;
while (fsIterator.hasNext()) {
fileStatus = fsIterator.next();
system.delete(fileStatus.getPath(), false);
}
system.delete(outputHdfsPath, false);
}
/**
* 创建忽略单词文件,除了要过滤标点符号外,我希望过滤掉:天天、菇娘、释迦、软枣子、癞瓜、蛇皮果这几个水果
*/
system.delete(stopWordPath, false);
if (!system.exists(stopWordPath)) {
FSDataOutputStream outputStream = system.create(stopWordPath);
OutputStreamWriter file = new OutputStreamWriter(outputStream);
file.write("\\,\n");
file.write("\\.\n");
file.write("\\!\n");
file.write("天天\n");
file.write("菇娘\n");
file.write("释迦\n");
file.write("软枣子\n");
file.write("癞瓜\n");
file.write("蛇皮果\n");
file.close();
outputStream.close();
}
/**
* 创建MapReduce任务并设定Job名称
*/
Job job = Job.getInstance(conf, "Word Count Ver2:");
job.setJarByClass(WordCountVer2.class);
/**
* 设置输入文件、输出文件、缓存文件
*/
FileInputFormat.addInputPath(job, inputHdfsPath);
FileOutputFormat.setOutputPath(job, outputHdfsPath);
job.addCacheFile(stopWordPath.toUri());
job.getConfiguration().setBoolean("wordcount.skip.patterns", true);
/**
* 指定Reduce类输出类型Key类型与Value类型
*/
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
/**
* 指定自定义Map类,Reduce类,开启Combiner函数。
*/
job.setMapperClass(WordCountVer2.TokenizerMapper.class);
job.setCombinerClass(WordCountVer2.IntSumReducer.class);
job.setReducerClass(WordCountVer2.IntSumReducer.class);
/**
* 提交作业
*/
job.waitForCompletion(true);
/**
* 然后轮询进度,直到作业完成。
*/
float progress = 0.0f;
do {
progress = job.setupProgress();
System.out.println("Word Count Ver2: 的当前进度:" + progress * 100);
Thread.sleep(1000);
} while (progress != 1.0f && !job.isComplete());
/**
* 如果成功,查看输出文件内容
*/
if (job.isSuccessful()) {
RemoteIterator fsIterator = system.listFiles(outputHdfsPath, true);
LocatedFileStatus fileStatus;
while (fsIterator.hasNext()) {
fileStatus = fsIterator.next();
FSDataInputStream outputStream = system.open(fileStatus.getPath());
IOUtils.copyBytes(outputStream, System.out, conf, false);
outputStream.close();
System.out.println("--------------------------------------------");
}
}
}
}
展示MapReduce2-3.1.1组件编写Word Count Ver2.0测试类:
package linose.mapreduce;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashSet;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.StringUtils;
public class WordCountVer2 {
public static class TokenizerMapper extends Mapper {
static enum CountersEnum { INPUT_WORDS }
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive;
private Set patternsToSkip = new HashSet();
private Configuration conf;
private BufferedReader fis;
@Override
public void setup(Context context) throws IOException, InterruptedException {
conf = context.getConfiguration();
caseSensitive = conf.getBoolean("wordcount.case.sensitive", true);
if (conf.getBoolean("wordcount.skip.patterns", false)) {
URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();
for (URI patternsURI : patternsURIs) {
Path patternsPath = new Path(patternsURI.getPath());
String patternsFileName = patternsPath.getName().toString();
parseSkipFile(patternsFileName);
}
}
}
private void parseSkipFile(String fileName) {
try {
fis = new BufferedReader(new FileReader(fileName));
String pattern = null;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern);
}
} catch (IOException ioe) {
System.err.println("Caught exception while parsing the cached file '" + StringUtils.stringifyException(ioe));
}
}
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = (caseSensitive) ? value.toString() : value.toString().toLowerCase();
for (String pattern : patternsToSkip) {
line = line.replaceAll(pattern, "");
}
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
Counter counter = context.getCounter(CountersEnum.class.getName(), CountersEnum.INPUT_WORDS.toString()); counter.increment(1);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
下图为测试结果:
image.png
至此,MapReduce2-3.1.1 Word Count Ver2.0 实验示例演示完毕。