SpringBoot集成Logback日志
SpringBoot集成Logback日志
文章目录
- SpringBoot集成Logback日志
-
- 一、什么是日志
- 二、Logback简单介绍
- 三、SpringBoot项目中使用Logback
- 四、概念介绍
-
- 一、日志记录器Logger
-
- 1.1、日志记录器对象生成
- 1.2、记录器的层级结构
- 1.3、过滤器
- 1.4、logger设置日志级别
- 1.5、java代码演示
- 1.6、使用配置文件演示
- 二、附加器
-
- 2.1、什么是附加器?
- 2.2、附加器使用方式
- 2.3、输出格式
- 2.4、记录器的可加性
-
- 问题产生
- 解决方法
- 五、SpringBoot中使用Logback日志
-
- 5.1、日志文件命名和位置
- 5.2、logback.xml中使用环境变量信息
- 六、日志记录中的一些坑
-
- 6.1、情景一
- 6.2、情景二
- 6.3、情景三
- 6.4、情景四
- 6.5、情景五:日志无法删除情况
- 七、SpringBoot中切换日志
- 八、阿里巴巴日志规约
一、什么是日志
日志的作用是用来追踪和记录我们的程序运行中的信息,我们可以利用日志很快定位问题,追踪分析。
如果没有日志,程序一旦出现问题,很难一下子就能定位问题。尤其是访问第三方接口、随机或偶尔出现的问题、很难再现的问题。
之前听说过一句话:“只有在程序出问题以后才会知道打一个好的日志有多么重要。”
二、Logback简单介绍
目前比较常用的Java日志框架: Logback、log4j、log4j2、JUL等等。
Logback是在log4j 的基础上重新开发的一套日志框架,是完全实现SLF4J接口API(也叫日志门面)。
Logback 的架构非常通用,可以应用于不同的环境。目前logback分为三个模块,logback-core、logback-classic和logback-access。logback-core 模块为其他两个模块奠定了基础。logback-classic模块原生实现了SLF4J API,因此您可以轻松地在 logback 和其他日志记录框架(例如 log4j 1.x 或 java.util.logging (JUL))之间来回切换。
logback-access 模块与 Tomcat 和 Jetty 等 Servlet 容器集成,以提供 HTTP 访问日志功能。请注意,您可以轻松地在 logback-core 之上构建自己的模块。
三、SpringBoot项目中使用Logback
logback是springboot-web自带的,无需引入外部依赖即可使用。可以来看下对应的依赖:
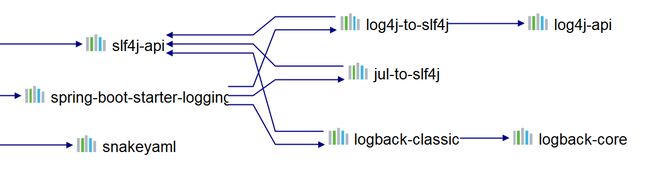
四、概念介绍
一、日志记录器Logger
日志记录器(Logger):控制要输出哪些日志记录语句,对日志信息进行级别限制。
1.1、日志记录器对象生成
如何生成记录器:
final static Logger logger = LoggerFactory.getLogger(“名称”);
这里有两个点需要说明的是:
1、日志记录器是单例的。也就是说第一次发现是没有的,那么创建;第二次直接拿到日志记录器进行使用即可;
2、括号中的无论是字符串还是对应的class类型,最终都会打印成当前的类的全限定类名(正常逻辑)
如下所示:
private static Logger logger = LoggerFactory.getLogger(UserController.class);
private static Logger logger = LoggerFactory.getLogger("com.guang.springbootlogback.user.controller.UserController");
上面二者相同,如果传递的是Class,那么最终也会调用getName来获取得到最终的值。
1.2、记录器的层级结构
类似于java中的体系结构,记录器也是有对应的层级结构的:
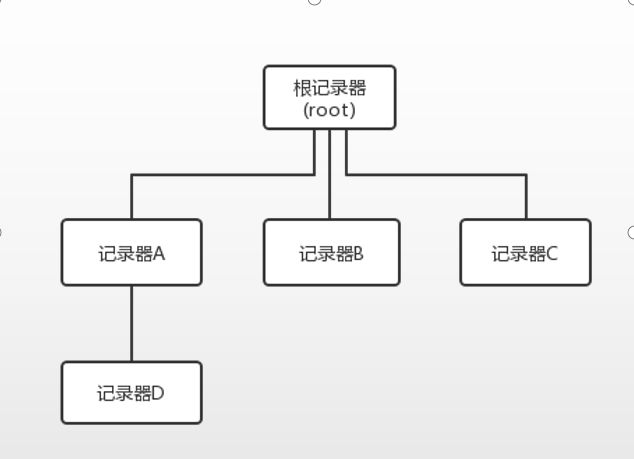
根记录器是logback自带的,本身就已经存在。而对于记录器A、B、C来说,根记录器是其父类,对于记录器D来说,是其祖先记录器。
如果对于记录器ABCD都没有设置自身的日志级别的话,那么默认都是继承了根记录器的日志级别。
如果任意一个子记录器设置了自己的日志级别,那么子记录器就可以使用使用对应级别的打印输出内容了。
比如记录器A,继承了根记录器,默认是DEBUG,如果记录器A设置了日志级别为INFO,如果记录器D没有设置的话,将会来继承记录器A的日志级别。
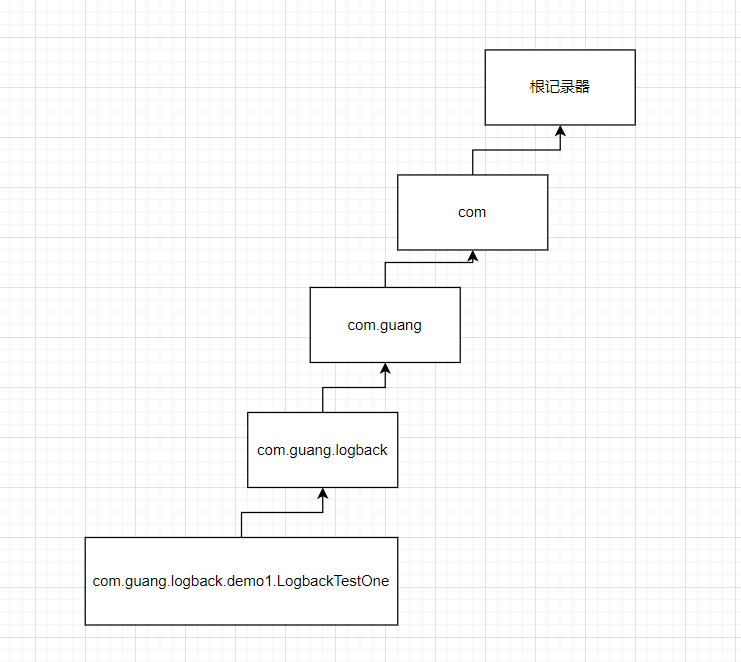
那么分别来创建几个记录器:
private static final Logger logger = LoggerFactory.getLogger("com.guang.logback.demo1.LogbackTestOne");
private static final Logger logger1 = LoggerFactory.getLogger("com.guang.logback");
private static final Logger logger2 = LoggerFactory.getLogger("com.guang");
private static final Logger logger3 = LoggerFactory.getLogger("com");
说明:
1、上面创建了四个记录器,对于logger、logger1、logger2来说,都是继承于logger3的,因为记录器的层级关系是通过包名来进行设置的。
2、对于记录器logger来说,它会创建出来一个具备这层级关系的记录器;
3、对于记录器logger3来说,是继承于根记录器的;
对应图如下所示:
1.3、过滤器
filter中最重要的两个过滤器为:LevelFilter、ThresholdFilter。
LevelFilter根据精确的级别匹配过滤事件。如果事件的级别等于配置的级别,则筛选器接受或拒绝该事件,具体取决于onMatch和onMismatch属性的配置。
例如下面配置将只打印INFO级别的日志,其余的全部禁止打印输出:
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFOlevel>
<onMatch>ACCEPTonMatch>
<onMismatch>DENYonMismatch>
filter>
<encoder>
<pattern>
%-4relative [%thread] %-5level %logger{30} - %msg%n
pattern>
encoder>
appender>
<root level="DEBUG">
<appender-ref ref="CONSOLE" />
root>
configuration>
ThresholdFilter过滤低于指定阈值的事件。 对于等于或高于阈值的事件,ThresholdFilter将在调用其decision()方法时响应NEUTRAL。
但是,将拒绝级别低于阈值的事件,例如下面的配置将拒绝所有低于INFO级别的日志,只输出INFO以及以上级别的日志:
<configuration>
<appender name="CONSOLE"
class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFOlevel>
filter>
<encoder>
<pattern>
%-4relative [%thread] %-5level %logger{30} - %msg%n
pattern>
encoder>
appender>
<root level="DEBUG">
<appender-ref ref="CONSOLE" />
root>
configuration>
1.4、logger设置日志级别
在logback中有五大日志级别,按照从小到大的顺序进行排列:TRACE < DEBUG < INFO < WARN < ERROR
如果设置的级别是DEBUG,那么在程序打印出来的级别只能够大于等于DEBUG的,而不会打印TRACE。
那么logback中默认日志级别是DEBUG
首先需要明确的是对于每个记录器来说,都有日志记录器的名称、级别和获取得到日志级别的方法。
1、name:记录器的名称
2、level:日志记录器的级别,也是日志的级别。五个日志级别:TRACE < DEBUG < INFO < WARN < ERROR
设置的时候可以通过配置文件,也可以通过代码来进行设置。如果没有设置级别,那么将会从父记录器或者是祖先记录器中来进行继承日志级别
3、获取得到级别的方法:
logger.setLevel():设置的级别,只会对这个级别及其之上的起作用
logger.getLevel():获取得到设置的级别
logger.getEffectiveLevel():和getLevel相同
additivity:是否允许叠加打印日志,true或者是false。也就是子记录器和父记录器进行叠加打印,可以理解成是重复打印问题。
后续会来解决这个问题
1.5、java代码演示
来利用java代码来设置日志级别,做一个案例演示:
public static void main(String[] args) {
// 不能够使用接口,因为接口中没有这个方法,需要找到具体的实现类
ch.qos.logback.classic.Logger logger = (ch.qos.logback.classic.Logger) LoggerFactory.getLogger(LogbackTestThree.class);
// 在设置之前看下本身的日志级别 为什么?因为直接继承了父记录器都没有设置,那么最终都将会继承根记录器,因为根记录器设置
// 的日志级别是DEBUG,所以默认级别是DEBUG
System.out.println("默认的记录器级别:"+logger.getEffectiveLevel());
// 可以修改父记录器的级别,然后让子记录器来进行继承,子记录器打印的是父记录器的级别
logger.setLevel(Level.INFO);
// 当前级别
logger.info("hello,world");
// 输出更高级别
logger.error("hello,world");
// 输出比当前级别低的 不会来打印
logger.debug("hello,logback---debug");
}
1.6、使用配置文件演示
使用java代码来设置日志级别是不方便的,所以最方便的使用方式是使用配置文件来进行输出
这里需要使用到附加器的内容,所以看完附加器再来看这个:
<configuration>
<appender name="File" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>C:\\Users\\lig\\Desktop\\log\\out.logFile>
<append>trueappend>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<FileNamePattern>log_/date-%d{yyyy-MM-dd HH-mm-ss}-%i.logFileNamePattern>
<MaxHistory>30MaxHistory>
<totalSizeCap>3MBtotalSizeCap>
<maxFileSize>500MBmaxFileSize>
rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{60} - %msg%npattern>
<charset>UTF-8charset>
encoder>
appender>
<logger name="com.guang.logback.demo2">
<appender-ref ref="File"/>
logger>
<root level="info"/>
configuration>
二、附加器
2.1、什么是附加器?
记录器会将输出日志的任务交给附加器完成,不同的附加器会将日志记录器中记录的信息输出到不同的地方。比如控制台附加器、文件附加器、网络附加器等等。
不同的附加器会将logger.info(“xxx”)中的输出信息输出到不同的地方中去
常用的附加器控制台附加器:
| 附加器实现类 | 说明 | 作用 |
|---|---|---|
| ch.qos.logback.core.ConsoleAppender | 控制台附加器 | 将输出信息输出到控制台 |
| ch.qos.logback.core.FileAppender | 文件附加器 | 将输出信息输出到文件中去,文件只有一个 |
| ch.qos.logback.core.rolling.RollingFileAppender | 滚动文件附加器,是文件附加器的子类 | 将输出信息输出到文件中去,可以输出到不同文件中去 |
也就是说将日志输出在哪里?是由附加器来进行完成的
2.2、附加器使用方式
附加器就是将信息输出到哪里,但是需要得到日志记录器的支持。所以二者要联合来进行使用。
<configuration debug="true">
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %highlight(%-5level) --- [%15.15(%thread)] %cyan(%-40.40(%logger{40})) : %msg%npattern>
<charset>UTF-8charset>
encoder>
appender>
<appender name="info_log" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>logs/project_info.logFile>
<append>trueappend>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERRORlevel>
<onMatch>DENYonMatch>
<onMismatch>ACCEPTonMismatch>
filter>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>logs/project_info.%d.%i.logfileNamePattern>
<maxHistory>30maxHistory>
<totalSizeCap>20GBtotalSizeCap>
<maxFileSize>10MBmaxFileSize>
rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level --- [%15.15(%thread)] %-40.40(%logger{40}) : %msg%npattern>
<charset>UTF-8charset>
encoder>
appender>
<appender name="error_log" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>logs/project_error.logFile>
<append>trueappend>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERRORlevel>
filter>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>logs/project_error.%d.%i.logfileNamePattern>
<maxHistory>30maxHistory>
<totalSizeCap>20GBtotalSizeCap>
<maxFileSize>10MBmaxFileSize>
rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level --- [%15.15(%thread)] %-40.40(%logger{40}) : %msg%npattern>
<charset>UTF-8charset>
encoder>
appender>
<root level="INFO">
<appender-ref ref="STDOUT" />
root>
<logger name="com.sailing.springbootmybatis" level="INFO">
<appender-ref ref="info_log" />
<appender-ref ref="error_log" />
logger>
<logger name="com.sailing.springbootmybatis.mapper" level="DEBUG" additivity="false">
<appender-ref ref="info_log" />
<appender-ref ref="error_log" />
logger>
<logger name="com.atomikos" level="INFO" additivity="false">
<appender-ref ref="info_log" />
<appender-ref ref="error_log" />
logger>
configuration>
2.3、输出格式
如果将输出设置的单调,那么将无法来进行定位问题,所以需要对日志产生的时间、位置、进程名称、日志级别等等信息进行打印,方便我们来定位问题。我们可以指定输出信息的模板,将输出信息进行模板格式化,而Pattern标签就是用来做这个事情的
Pattern由文字文本和转换说明符的格式控制表达式组成 。您可以在其中自由插入任何文字文本。每个转换说明符都以百分号 ‘%’ ,后跟可选的 格式修饰符、转换字和大括号之间的可选参数。转换字控制要转换的数据字段,例如记录器名称、级别、日期或线程名称。格式修饰符控制字段宽度、填充以及左对齐或右对齐。
常见的有如下所示:

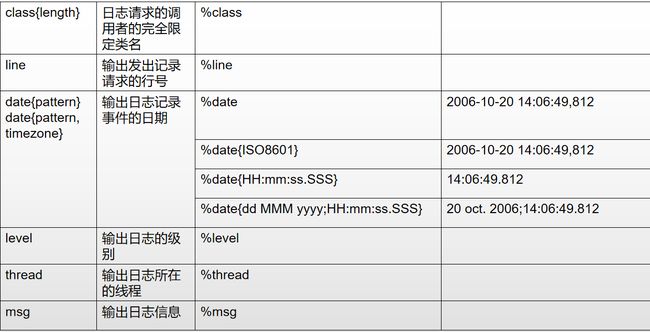
2.4、记录器的可加性
之前还有一个属性没有来得及进行介绍,这里也来介绍下,记录器的可加性指的就是日志的重复输出问题。
问题产生
分别看下对应的问题和解决方式:
<configuration scan="true" scanPeriod="10 seconds">
<appender name="STOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%10date %level [%thread] %logger{60} %line %msg %npattern>
encoder>
appender>
<logger name="com.guang.springbootlogback.controller" level="debug">
<appender-ref ref="STOUT"/>
logger>
<root level="info">
<appender-ref ref="STOUT"/>
root>
configuration>
对应的案例:
@RequestMapping("deleteUser")
public String deleteUser(){
logger.info("hello,world");
return "hello,logback";
}
访问的时候会打印两次,根记录器和父记录器分别户打印一次:
2022-04-20 11:54:59,543 INFO [http-nio-8080-exec-1] com.guang.springbootlogback.user.controller.UserController 32 hello,world
2022-04-20 11:54:59,543 INFO [http-nio-8080-exec-1] com.guang.springbootlogback.user.controller.UserController 32 hello,world
查看一下对应的记录器树层次结构:

产生原因解释:如果子记录器中的附加器来进行打印的时候,父类记录器中的附加器也会打印日志,直到根记录器中的附加器也会来打印;
解决方法
那么为了防止这种重复打印的情况,直接建议使用下面这种方式:
来自阿里巴巴规范中
【强制】避免重复打印日志,浪费磁盘空间,务必在 log4j.xml 中设置 additivity=false。
正例:
直接设置只有当前记录器可输出
<configuration scan="true" scanPeriod="10 seconds">
<appender name="STOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%10date %level [%thread] %logger{60} %line %msg %npattern>
encoder>
appender>
<logger name="com.guang.springbootlogback" level="debug" additivity="false">
<appender-ref ref="STOUT"/>
logger>
<root level="info">
<appender-ref ref="STOUT"/>
root>
configuration>
五、SpringBoot中使用Logback日志
直接参考官方文档:https://docs.spring.io/spring-boot/docs/2.5.14/reference/html/features.html#features.logging
5.1、日志文件命名和位置
Spring Boot官方推荐优先使用带有-spring的文件名作为你的日志配置(如使用logback-spring.xml,而不是logback.xml),命名为logback-spring.xml的日志配置文件,将xml放至 src/main/resource下面。
也可以使用自定义的名称,比如logback-config.xml,只需要在application.properties文件中使用logging.config=classpath:logback-config.xml指定即可。
5.2、logback.xml中使用环境变量信息
<springProfile name="staging">
springProfile>
<springProfile name="dev | staging">
springProfile>
<springProfile name="!production">
springProfile>
<springProperty scope="context" name="fluentHost" source="myapp.fluentd.host"
defaultValue="localhost"/>
<appender name="FLUENT" class="ch.qos.logback.more.appenders.DataFluentAppender">
<remoteHost>${fluentHost}remoteHost>
...
appender>
六、日志记录中的一些坑
6.1、情景一
这里再说下log日志输出代码,一般有人可能在代码中使用如下方式输出:
Object entry = new SomeObject();
logger.debug("The entry is " + entry);
上面看起来没什么问题,但是会存在两个问题:
1、构造消息参数的成本,即将entry转换成字符串相加;
2、无论是否记录消息,都是如此,即:那怕日志级别为INFO,也会执行括号里面的操作,但是日志不会输出,下面是优化后的写法:
if(logger.isDebugEnabled()) {
Object entry = new SomeObject();
logger.debug("The entry is " + entry);
}
6.2、情景二
针对上面的写法,首先对设置的日志级别进行了判断,如果为debug模式,才进行参数的构造,对第一种写法进行了改善。
不过还有最好的写法,使用占位符:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
只有在评估是否记录之后,并且只有在决策是肯定的情况下,记录器实现才会格式化消息并将“{}”对替换为条目的字符串值。 换句话说,当禁用日志语句时,此表单不会产生参数构造的成本。
logback作者进行测试得出:第一种和第三种写法将产生完全相同的输出。 但是,在禁用日志记录语句的情况下,第三个变体将比第一个变体优于至少30倍。
6.3、情景三
如果有多个参数,写法如下:
logger.debug("The new entry is {}. It replaces {}.", entry, oldEntry);
如果需要传递三个或更多参数,则还可以使用Object []变体:
Object[] paramArray = {newVal, below, above};
logger.debug("Value {} was inserted between {} and {}.", paramArray);
6.4、情景四
记录日志的时候我们可能需要在文件中记录下异常的堆栈信息,经过测试,logger.error(e) 不会打印出堆栈信息,正确的写法是:
logger.error("程序异常, 详细信息:{}", e.getLocalizedMessage() , e);
6.5、情景五:日志无法删除情况
看下下面的情况:
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>/root/demo/logs/hornet_%d{yyyyMMdd}.%i.logfileNamePattern>
<maxFileSize>10mbmaxFileSize>
<maxHistory>30maxHistory>
<totalSizeCap>20GBtotalSizeCap>
rollingPolicy>
从配置可以看出,可以从 SizeAndTimeBasedRollingPolicy.class 着手
public class SizeAndTimeBasedRollingPolicy<E> extends TimeBasedRollingPolicy<E> {
FileSize maxFileSize;
@Override
public void start() {
SizeAndTimeBasedFNATP<E> sizeAndTimeBasedFNATP = new SizeAndTimeBasedFNATP<E>(Usage.EMBEDDED);
if(maxFileSize == null) {
addError("maxFileSize property is mandatory.");
return;
} else {
// 每个文件大小限制在maxFileSize大小
addInfo("Archive files will be limited to ["+maxFileSize+"] each.");
}
sizeAndTimeBasedFNATP.setMaxFileSize(maxFileSize);
timeBasedFileNamingAndTriggeringPolicy = sizeAndTimeBasedFNATP;
// 1、totalSizeCap不能为0
// 2、如果总大小小于其中一个文件大小,抛出异常
if(!isUnboundedTotalSizeCap() && totalSizeCap.getSize() < maxFileSize.getSize()) {
addError("totalSizeCap of ["+totalSizeCap+"] is smaller than maxFileSize ["+maxFileSize+"] which is non-sensical");
return;
}
// most work is done by the parent
// 执行父类中的方法
super.start();
}
// ....
}
然后执行父类中的方法:ch.qos.logback.core.rolling.TimeBasedRollingPolicy#start
public void start() {
// set the LR for our utility object
renameUtil.setContext(this.context);
// find out period from the filename pattern
if (fileNamePatternStr != null) {
fileNamePattern = new FileNamePattern(fileNamePatternStr, this.context);
determineCompressionMode();
} else {
addWarn(FNP_NOT_SET);
addWarn(CoreConstants.SEE_FNP_NOT_SET);
throw new IllegalStateException(FNP_NOT_SET + CoreConstants.SEE_FNP_NOT_SET);
}
compressor = new Compressor(compressionMode);
compressor.setContext(context);
// wcs : without compression suffix
fileNamePatternWithoutCompSuffix = new FileNamePattern(Compressor.computeFileNameStrWithoutCompSuffix(fileNamePatternStr, compressionMode), this.context);
addInfo("Will use the pattern " + fileNamePatternWithoutCompSuffix + " for the active file");
if (compressionMode == CompressionMode.ZIP) {
String zipEntryFileNamePatternStr = transformFileNamePattern2ZipEntry(fileNamePatternStr);
zipEntryFileNamePattern = new FileNamePattern(zipEntryFileNamePatternStr, context);
}
if (timeBasedFileNamingAndTriggeringPolicy == null) {
timeBasedFileNamingAndTriggeringPolicy = new DefaultTimeBasedFileNamingAndTriggeringPolicy<E>();
}
timeBasedFileNamingAndTriggeringPolicy.setContext(context);
timeBasedFileNamingAndTriggeringPolicy.setTimeBasedRollingPolicy(this);
timeBasedFileNamingAndTriggeringPolicy.start();
if (!timeBasedFileNamingAndTriggeringPolicy.isStarted()) {
addWarn("Subcomponent did not start. TimeBasedRollingPolicy will not start.");
return;
}
//*********** 可以看到这里有 maxHistory,也就是最大保留天数
//*********** 可以看到这里有 maxHistory,也就是最大保留天数
//*********** 可以看到这里有 maxHistory,也就是最大保留天数
//*********** 大概意思就是判断是否初始化,然后把参数设置到archiveRemover中,
//*********** 后面调用archiveRemover.cleanAsynchronously方法进行清理!!!
// the maxHistory property is given to TimeBasedRollingPolicy instead of to
// the TimeBasedFileNamingAndTriggeringPolicy. This makes it more convenient
// for the user at the cost of inconsistency here.
if (maxHistory != UNBOUND_HISTORY) {
archiveRemover = timeBasedFileNamingAndTriggeringPolicy.getArchiveRemover();
archiveRemover.setMaxHistory(maxHistory);
archiveRemover.setTotalSizeCap(totalSizeCap.getSize());
if (cleanHistoryOnStart) {
addInfo("Cleaning on start up");
Date now = new Date(timeBasedFileNamingAndTriggeringPolicy.getCurrentTime());
cleanUpFuture = archiveRemover.cleanAsynchronously(now);
}
} else if (!isUnboundedTotalSizeCap()) {
addWarn("'maxHistory' is not set, ignoring 'totalSizeCap' option with value ["+totalSizeCap+"]");
}
super.start();
}
进入 TimeBasedArchiveRemover.class,可以看到这是一个异步任务,重点在 clean()
public Future<?> cleanAsynchronously(Date now) {
ArhiveRemoverRunnable runnable = new ArhiveRemoverRunnable(now);
ExecutorService executorService = context.getScheduledExecutorService();
Future<?> future = executorService.submit(runnable);
return future;
}
public class ArhiveRemoverRunnable implements Runnable {
Date now;
ArhiveRemoverRunnable(Date now) {
this.now = now;
}
@Override
public void run() {
clean(now);
if (totalSizeCap != UNBOUNDED_TOTAL_SIZE_CAP && totalSizeCap > 0) {
capTotalSize(now);
}
}
}
重点在 clean() ,清理,得到 periodsElapsed 天数,然后遍历清理 (-maxHistory+1)+i 天
public void clean(Date now) {
// 获取得到现在的时间
long nowInMillis = now.getTime();
// for a live appender periodsElapsed is expected to be 1
// 如何进行计算的?
int periodsElapsed = computeElapsedPeriodsSinceLastClean(nowInMillis);
lastHeartBeat = nowInMillis;
if (periodsElapsed > 1) {
addInfo("Multiple periods, i.e. " + periodsElapsed + " periods, seem to have elapsed. This is expected at application start.");
}
for (int i = 0; i < periodsElapsed; i++) {
int offset = getPeriodOffsetForDeletionTarget() - i;
// 获取需要删除的日志日期 如今天是2022-09-15 maxHistory为30
// 则dateOfPeriodToClean是从2022-08-15到2022-07-15 过早的日志则需要手动删除
Date dateOfPeriodToClean = rc.getEndOfNextNthPeriod(now, offset);
cleanPeriod(dateOfPeriodToClean);
}
}
重要 computeElapsedPeriodsSinceLastClean() 计算 periodsElapsed 天数
int computeElapsedPeriodsSinceLastClean(long nowInMillis) {
long periodsElapsed = 0;
// UNINITIALIZED判断是否没有进行初始化
if (lastHeartBeat == UNINITIALIZED) {
addInfo("first clean up after appender initialization");
// periodBarriersCrossed 计算过期出天数
// 默认32天?
periodsElapsed = rc.periodBarriersCrossed(nowInMillis, nowInMillis + INACTIVITY_TOLERANCE_IN_MILLIS);
periodsElapsed = Math.min(periodsElapsed, MAX_VALUE_FOR_INACTIVITY_PERIODS);
} else {
periodsElapsed = rc.periodBarriersCrossed(lastHeartBeat, nowInMillis);
// periodsElapsed of zero is possible for size and time based policies
}
return (int) periodsElapsed;
}
结论:
如果要在项目启动时就删除历史日志文件,需要在logback-spring.xml中添加true。
另外,过于古老的日志是无法自动清除的。logback只能删除最近maxHistory天到maxHistory-32天的日志文件。
如今天是2022-09-15 maxHistory为30 则日志删除的范围是从 2022-07-15 到 2022-08-15 ,过早的日志则需要手动删除
七、SpringBoot中切换日志
因为SpringBoot默认的Logback,在springboot中默认在spring-boot-starter-web中自动引入了spring-boot-starter-logging
如果想要切换到log4j2,那么只需要在spring-boot-starter-web排除掉spring-boot-starter-logging,然后引入新的日志框架对应的坐标。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-loggingartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-log4j2artifactId>
dependency>
这里涉及到的步骤有如下所示:
1、在依赖中先从spring-boot-starter-web中点进去,找到spring-boot-starter;
2、再从spring-boot-starter中点进去,找到spring-boot-starter-logging;
3、然后在spring-boot-starter-web下写下排除的坐标;直接从第二步中拷贝下来;
八、阿里巴巴日志规约
1、【强制】应用中不可直接使用日志系统(Log4j、Logback)中的 API,而应依赖使用日志框架
(SLF4J、JCL–Jakarta Commons Logging)中的 API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
说明:日志框架(SLF4J、JCL–Jakarta Commons Logging)的使用方式(推荐使用 SLF4J)
使用 SLF4J:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(Test.class);
使用 JCL:
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
private static final Log log = LogFactory.getLog(Test.class);
2、【强制】所有日志文件至少保存 15 天,因为有些异常具备以“周”为频次发生的特点。对于当天日志,以“应用名.log”来保存,保存在/home/admin/应用名/logs/目录下,过往日志格式为: {logname}.log.{保存日期},日期格式:yyyy-MM-dd
说明:以 mppserver 应用为例,日志保存在/home/admin/mppserver/logs/mppserver.log,历史日志名称为 mppserver.log.2016-08-01
3、【强制】在日志输出时,字符串变量之间的拼接使用占位符的方式。
说明:因为 String 字符串的拼接会使用 StringBuilder 的 append()方式,有一定的性能损耗。使用占位符仅是替换动作,可以有效提升性能。
正例:logger.debug(“Processing trade with id: {} and symbol: {}”, id, symbol);
4、【强制】对于 trace/debug/info 级别的日志输出,必须进行日志级别的开关判断。
说明:虽然在 debug(参数)的方法体内第一行代码 isDisabled(Level.DEBUG_INT)为真时(Slf4j 的常见实现Log4j 和 Logback),就直接 return,但是参数可能会进行字符串拼接运算。此外,如果 debug(getName()),这种参数内有 getName()方法调用,无谓浪费方法调用的开销。
正例:
// 如果判断为真,那么可以输出 trace 和 debug 级别的日志
if (logger.isDebugEnabled()) {
logger.debug(“Current ID is: {} and name is: {}”, id, getName());
}
5、【强制】避免重复打印日志,浪费磁盘空间,务必在 log4j.xml 中设置 additivity=false。
正例:
6、【强制】生产环境禁止直接使用 System.out 或 System.err 输出日志或使用e.printStackTrace()打印异常堆栈。
说明:标准日志输出与标准错误输出文件每次 Jboss 重启时才滚动,如果大量输出送往这两个文件,容易造成文件大小超过操作系统大小限制。
7、【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字 throws 往上抛出。
正例:logger.error(各类参数或者对象 toString() + “_” + e.getMessage(), e);
8、【强制】日志打印时禁止直接用 JSON 工具将对象转换成 String。
说明:如果对象里某些 get 方法被重写,存在抛出异常的情况,则可能会因为打印日志而影响正常业务流程的执行。
正例:打印日志时仅打印出业务相关属性值或者调用其对象的 toString()方法。
9、【推荐】谨慎地记录日志。生产环境禁止输出 debug 日志;有选择地输出 info 日志;如果使用
warn 来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘撑爆,并记得及时删除这些观察日志。
说明:大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。
记录日志时请思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
10、【推荐】可以使用 warn 日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从。如非必要,请不要在此场景打出 error 级别,避免频繁报警。
说明:注意日志输出的级别,error 级别只记录系统逻辑出错、异常或者重要的错误信息。