【Hive】学习与优化2(含常用面试)
目录
hive的查询注意事项以及优化总结
hivesql 分组拼接同一列的字符串 / 分组多行拼接为一行
hive分组取随机数
Hive随机取某几行数据
Hive Ntile分析函数学习,用来取前30% 带有百分之多少比例的记录
Hive SQL--如何使用分位数函数(percentile)
一些concat的区别
大小厂面试题汇总
1、腾讯面试题:table_A ( 用户userid和登录时间time)求连续登录3天的用户数
日期减少函数: date_sub
2、原始座次表 ‘seat’如下,现需要更换相邻位置学生的座次。
mod(m,n),MOD返回m除以n的余数,如果n是0,返回m
3、现在需要找出语文课中成绩第二高的学生成绩。如果不存在第二高成绩的学生,那么查询应返回 null。
4、如何提高SQL查询的效率?
5、用户访问次数表,列名包括用户编号、用户类型、访问量。要求在剔除访问次数前20%的用户后,每类用户的平均访问次数。(拼多多、网易面试题)
6、查询每门课都大于80分的学生姓名
7、查询编号不同,其他都相同的学生冗余信息
8、行转列,但是是多个字段
9、获取定制字符串的当月第一天,本月的最后一天,取三个月前的今天
10、如何将20190215100000转换为标准日期格式
11、统计每门学科的成绩排名情况
12、给出每个员工每年薪水涨幅超过5000的员工编号emp_no、薪水变更开始日期from_date以及薪水涨幅值salary_growth,并按照salary_growth逆序排列。
13、查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序
14、获取员工其当前的薪水比其manager当前薪水还高的相关信息
15、对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
16、如何去重 distinct(distinct效率不行,且大数据量的时候都禁止用distinct,建议用group by解决重复问题) 和 group by】查找入职员工时间排名倒数第三的员工所有信息
17、SQL是支持集合运算:EXPECT 集合差运算、 UNION 集合并运算、 INTERSECT 集合交运算】获取所有非manager的员工emp_no
18、获取所有部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary
-
hive的查询注意事项以及优化总结
如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,实际测试过程中,执行时间能提升50%
insert overwite table tablename partition (dt= ....)
select ..... from (
select ... from A
union all
select ... from B
union all
select ... from C
) R
where ...;
可以改写为:
insert into table tablename partition (dt= ....)
select .... from A
WHERE ...;
insert into table tablename partition (dt= ....)
select .... from B
WHERE ...;
insert into table tablename partition (dt= ....)
select .... from C
WHERE ...; 具体使用如下:
-
hivesql 分组拼接同一列的字符串 / 分组多行拼接为一行
concat是行的维度进行拼接
concat_ws是列的维度进行拼接
select id, concat_ws('_',collect_set(col1)) as concatcol1 from table group by idgroupconcat在组内列的维度拼接,如下:
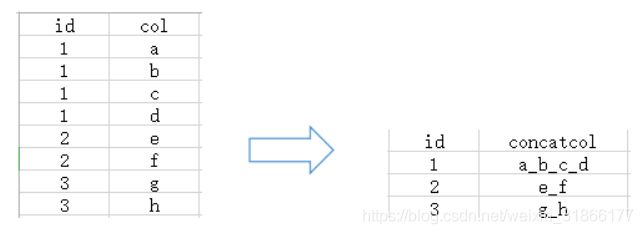
select id,group_concat(distinct(col1),'_') as concatcol1 from table group by id-
hive分组取随机数
hive取随机的数据,可以使用rand()函数,用rand()对数据排序,取topN
如果要用到分组取随机数,比如每个班级随机取10人,针对这种每个分组取topN的情况,可以使用
row_number() over(partition by fieldx order by rand()) as rn
select date,imei
from(
select date,imei,row_number() over(partition by sp_modify order by rand()) as rn
from tmp_mod ) mod
where mod.rn <= 1000-
Hive随机取某几行数据
order by rand() limit 100
1. 可用于普通随机筛选
2. 也可用于row_number() 等函数的排序里作为随机排序。
-
Hive Ntile分析函数学习,用来取前30% 带有百分之多少比例的记录
NTILE(n) 用于将分组数据按照顺序切分成n片,返回当前记录所在的切片值。
举例:有1000家店铺的价格数据。求 价格排名前30%的店铺的平均价格,和后70%的平均价格。
思路:把店铺均匀的按价格递减顺序分成10片。然后取切片数=1,2,3的即为前30%。
-- 1 把记录按价格顺序拆分成10片
drop table if exists test_dp_price_rk;
create table test_dp_price_rk
as
select
id,
price,
NTILE(10) OVER (order by price desc) as rn
from test_dp_price;
-- 2 按片取30%和70%,分别计算平均值
select
new_rn,
max(case when new_rn=1 then 'avg_price_first_30%' when new_rn=2 then 'avg_price_last_70%' end) as avg_price_name,
avg(price) avg_price
from
(
select
id,
price,
rn,
case when rn in (1,2,3) then 1 else 2 end as new_rn
from test_dp_price_rk
)a
group by new_rn;-
Hive SQL--如何使用分位数函数(percentile)
使用第一四分位数是0.25,中位数的话就取0.5。这里需要注意示例中的sales字段需要是int类型。
SELECT
*,
percentile(sales, 0.25) over(PARTITION BY item_third_cate_cd) AS q1_sales
FROM
tableHIVE中有两个关于分为数的函数:percentile 和 percentile_approx。
使用方式:
percentile:percentile(col, p) col是要计算的列(值必须为int类型),p的取值为0-1,若为0.2,那么就是2分位数,依次类推。
percentile_approx:percentile_approx(col, p)。列为数值类型都可以。
percentile_approx 还有一种形式percentile_approx(col, p,B),参数B控制内存消耗的近似精度,B越大,结果的精度越高。默认值为10000。当col字段中的distinct值的个数小于B时,结果就为准确的百分位数。
如果需要多个分位数,可以一次性取出来,案例如下:
去每天的UV的2分位数、4分位数、6分位数、8分位数:
select d,
percentile_approx(uv, array(0.2,0.4,0.6,0.8), 9999) as uv --2%分位数作为最小值
from aa
group by d结果如下:
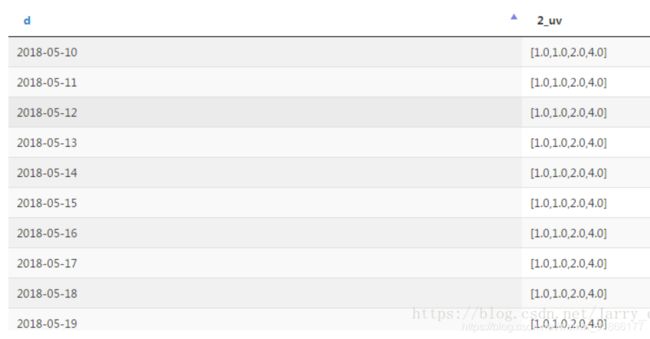
如果出现高分位数异常(0.7、0.8、0.9分位数值相同),可以调大percentile_approx(col, p,B)中的B值。
-
一些concat的区别
concat要注意有null时候的拼接,concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL。
执行 concat('11','22',null),结果NULL 。
concat_ws函数在执行的时候,不会因为NULL值而返回NULL。
执行 concat_ws(',','11','22',NULL) ,11,22
-
大小厂面试题汇总
-
1、腾讯面试题:table_A ( 用户userid和登录时间time)求连续登录3天的用户数
【解析】:用窗口函数row_number 进行排序,日期函数DATESUB,将(日期-排序数)得到一个相等的日期
【解析:用窗口函数row_number 进行排序,日期函数DATESUB,将(日期-排序数)得到一个相等的日期
SELECT
userid,
date_sub(TIME, interval t.rn DAY) AS flag_date,
COUNT( *)
FROM
(
SELECT
userid,
TIME,
row_number() over(partition BY userid order by TIME) AS rn
FROM
table_A
)
t
GROUP BY
userid,
flag_date
HAVING
COUNT( *) >= 3-
日期减少函数: date_sub
语法: date_sub (string startdate, int days)
返回值: string
说明:返回开始日期startdate减少days天后的日期。
举例:
hive> select date_sub('2012-12-08',10) from lxw_dual;
2012-11-28-
2、原始座次表 ‘seat’如下,现需要更换相邻位置学生的座次。
-
mod(m,n),MOD返回m除以n的余数,如果n是0,返回m
SELECT
(
CASE
WHEN mod(id, 2) != 0
AND c != id
THEN id + 1
WHEN mod(id, 2) != 0
AND c = id
THEN id
ELSE id - 1
END) AS id2,
student
FROM
seat,
(
SELECT COUNT( *) AS c FROM seat
) AS b
ORDER BY
id2-
3、现在需要找出语文课中成绩第二高的学生成绩。如果不存在第二高成绩的学生,那么查询应返回 null。
题目要求,如果没有第二高的成绩,返回空值,
所以这里用判断空值的函数(ifnull)函数来处理特殊情况。
select ifnull(第2步的sql,null) as '语文课第二名成绩';
SELECT
ifnull(
(
SELECT
MAX(DISTINCT 成绩)
FROM
成绩表
WHERE
课程 = '语文'
AND 成绩 <
(
SELECT MAX(DISTINCT 成绩) FROM 成绩表 WHERE 课程 = '语文'
)
)
, NULL) AS '语文课第二名成绩';- IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值。
- hive没有SQL Server 的
isnull和MySQLd的ifnull函数,可以用if()函数替代 if(条件,值1,值2)条件为真:值1,否则值2(相当于c++里的三目运算?:)-
4、如何提高SQL查询的效率?
1. select子句中尽量避免使用*
2、为了提高效率,where子句中遇到函数或加减乘除的运算,应当将其移到比较符号的右侧。
where 成绩 > 90 – 5(表达式在比较符号的右侧)
3、 尽量避免使用in和not in【会导致数据库进行全表搜索,增加运行时间】
4. 尽量避免使用or
select 学号
from 成绩表
where 成绩 = 88 or 成绩 = 89
优化后:
select 学号 from 成绩表 where 成绩 = 88
union
select 学号 from 成绩表 where 成绩 = 89-
5、用户访问次数表,列名包括用户编号、用户类型、访问量。要求在剔除访问次数前20%的用户后,每类用户的平均访问次数。(拼多多、网易面试题)
SELECT
用户类型,
AVG(访问量)
FROM
(
SELECT
*
FROM
(
SELECT *, row_number() over(order by 访问量 DESC) AS 排名 FROM 用户访问次数表
) AS a
WHERE
排名 >
(
SELECT MAX(排名) FROM a
)
* 0.2
) AS b
GROUP BY
用户类型;-
6、查询每门课都大于80分的学生姓名

-
7、查询编号不同,其他都相同的学生冗余信息
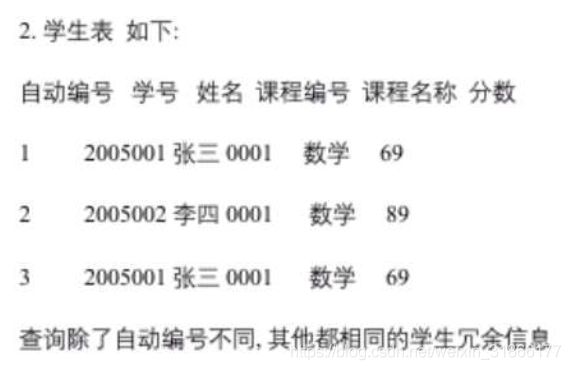
-
8、行转列,但是是多个字段
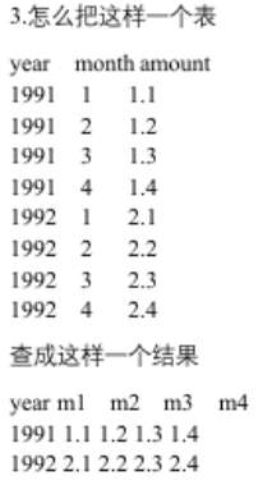
-
9、获取定制字符串的当月第一天,本月的最后一天,取三个月前的今天
-
10、如何将20190215100000转换为标准日期格式
-
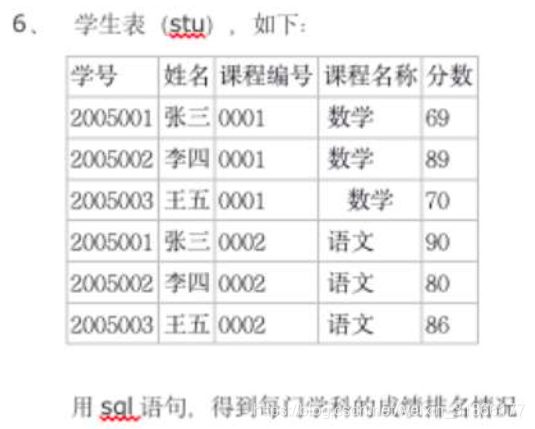
11、统计每门学科的成绩排名情况
-
12、给出每个员工每年薪水涨幅超过5000的员工编号emp_no、薪水变更开始日期from_date以及薪水涨幅值salary_growth,并按照salary_growth逆序排列。
-
13、查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序
SELECT
a.emp_no,
c.salary - b.salary AS growth
FROM
employees a
INNER JOIN salaries b
ON
a.emp_no = b.emp_no
AND a.hire_date = b.from_date
INNER JOIN salaries c
ON
a.emp_no = c.emp_no
AND c.to_date = '9999-01-01'
ORDER BY
c.salary - b.salary ASC
-
14、获取员工其当前的薪水比其manager当前薪水还高的相关信息
-
15、对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
【正确写法——按照一个标准来排序order BY salary DESC 】
SELECT
emp_no,
salary,
dense_rank() over(order by salary DESC) AS rank
FROM
salaries
WHERE
to_date = '9999-01-01'
ORDER BY
salary DESC,
emp_no ASC
-
16、如何去重 distinct(distinct效率不行,且大数据量的时候都禁止用distinct,建议用group by解决重复问题) 和 group by】查找入职员工时间排名倒数第三的员工所有信息
【法1:groupby来去重】
select * from employees
where hire_date = (
select hire_date from employees
group by hire_date
order by hire_date desc
limit 2,1)
【法2:distinct来去重】
select * from employees
where hire_date = (
select distinct hire_date from employees order by hire_date desc limit 2,1)
-
17、SQL是支持集合运算:EXPECT 集合差运算、 UNION 集合并运算、 INTERSECT 集合交运算】获取所有非manager的员工emp_no
SELECT employees.emp_no FROM salaries
EXCEPT
SELECT dept_manager.emp_no FROM dept_manager;
-
18、获取所有部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary
参考:
【SQL刷题】SQL语法学习与面试题练习
常用的hive sql函数总结