ip integrator
“ Lambda体系结构是一种数据处理体系结构,旨在通过利用批处理和流处理方法来处理大量数据。 这种体系结构方法尝试通过使用批处理提供批处理数据的全面而准确的视图,同时使用实时流处理提供在线数据的视图来平衡延迟 , 吞吐量和容错 。 在演示之前,可以将两个视图输出合并。 lambda体系结构的兴起与大数据的增长,实时分析以及减轻地图缩减延迟的驱动力有关。” –维基百科

以前,我已经写了一些博客,涉及许多用例,这些用例是使用Oracle Data Integrator(ODI)在MapR分发之上进行批处理,以及使用Oracle GoldenGate(OGG)将事务数据流式传输到MapR Streams和其他Hadoop组件中。 最新的ODI(12.2.1.2.6)结合了这两种产品以完全适合lambda架构,同时具有许多新的强大功能,包括能够将Kafka流作为ODI本身的源和目标进行处理。 通过简化我们在一种产品下以相同逻辑设计处理和处理批处理和快速数据的方式,此功能对已经拥有或计划拥有lambda架构的任何人都具有巨大的优势。 现在,如果我们将OGG流传输功能和ODI批处理/流传输功能结合在一起,则可能性是无限的。
在本博客中,我将向您展示如何使用Spark Streaming在Oracle Data Integrator上配置MapR流(又名Kafka)以创建真正的lambda体系结构:补充批处理和服务层的快速层。
在本文中,我将跳过ODI的“赞扬和称赞”部分,但我只想强调一点:自从ODI首次发布以来,为该博客设计的映射就像您要设计的所有其他映射一样,都是您可以立即使用Hadoop / Spark集群上的本机代码运行100%的代码,无需编写零行代码,也不必担心如何以及在何处编码。

我已经在MapR上完成了此操作,因此我可以制作“两只鸟一块石头”。 向您展示MapR Streams步骤和Kafka。 由于两者在概念或API实现上并没有太大差异,因此如果您使用的是Kafka,则可以轻松地应用相同的步骤。
如果您不熟悉MapR Streams和/或Kafka概念,建议您花一些时间来阅读它们。 以下内容假定您知道什么是MapR Streams和Kafka(当然还有ODI)。 否则,您仍然会对可能的功能有个好主意。
准备工作
MapR Streams(aka Kafka)相关的准备工作
显然,我们需要创建MapR Streams路径和主题。 与Kafka不同,MapR通过“ maprcli”命令行实用程序使用自己的API来创建和定义主题。 因此,如果您使用商品Kafka,则此步骤将略有不同。 Web上有很多有关如何创建和配置Kafka主题和服务器的示例,因此您并不孤单。
为了进行此演示,我创建了一个路径和该路径下的两个主题。 我们将让ODI从其中一个主题(注册)进行消费,并生成另一个主题(registrations2)。 这样,您将看到它如何通过ODI起作用。
创建一个名为“ users-stream”的MapR Streams路径和一个名为“ registrations”的主题:
![]()
在我之前定义的相同路径上创建第二个主题“ registrations2”:
![]()
Hadoop相关准备
由于我正在使用已安装并正在运行MapR的个人预配置VM,因此此处的准备工作不多。 但是,需要一些步骤才能成功完成ODI映射。 如果您想知道我是如何使ODI从事MapR发行的,那么您可以参考此博客文章 。
- Spark:我已经在Spark 1.6.1上进行了测试,您也应该这样做。 至少不要转到任何较低版本。 此外,您需要针对Spark构建具有特定的标签版本。 我从标签1605(这是MapR发布约定)开始测试,但是我的工作失败了。 究其原因,我发现PySpark库不是MapR Streams API的最新版本。 他们可以使用商品Kafka,但不能使用MapR。 这是我使用过的RPM的链接 。
- Spark日志记录:在spark路径下,有一个“ config”文件夹,其中包含不同的配置文件。 如果需要的话,我们只对其中一项感兴趣。 文件名为“ log4j.properties”。 您需要确保将“ rootCategory”参数设置为INFO,否则,当您运行提交到Spark的任何ODI映射时,都会出现异常:

- Hadoop凭证存储:在提交的任何作业中需要特定密码时,ODI将引用Hadoop凭证存储。 这样,我们就不会在参数/属性文件或代码本身中包含任何明确的密码。 在此演示中,我们将在某个时候使用MySQL,因此我需要创建一个存储并为MySQL密码添加别名。 首先,您需要确保core-site.xml中存在凭证存储的条目,然后实际上为密码值创建别名:

上一张图片是我的“ site-core.xml”的摘要,向您显示了我添加的凭据存储。 下一步将是验证商店是否存在,然后为密码值创建别名:

更改之后,即使在编辑core-site.xml之后,也无需重新启动任何hadoop组件。
注意:如果遇到“操作系统异常”(例如137),请确保有足够的可用内存。
ODI相关准备
您将在ODI中进行的常规准备工作。 我将在此博客中显示相关内容。
Hadoop数据服务器
以下配置特定于MapR。 如果使用其他发行版,则需要输入相关的端口号和路径:
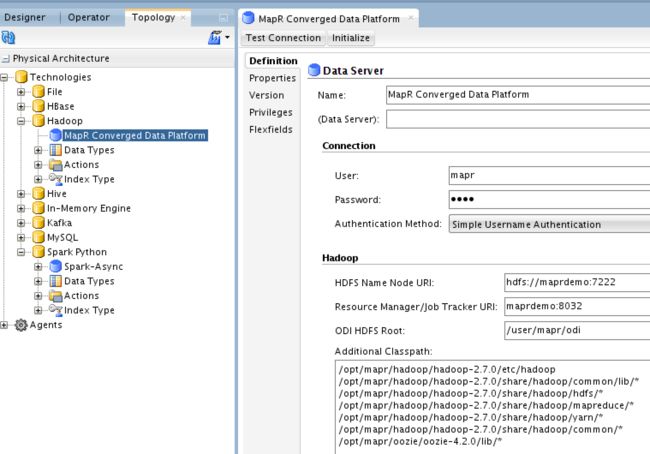
Spark-Python数据服务器
在此ODI版本12.2.1.2.6中,如果要使用Spark Streaming和常规Spark服务器/群集,则需要创建多个Spark数据服务器。 在此演示中,我仅创建了Spark Streaming服务器,并将其称为Spark-Async。
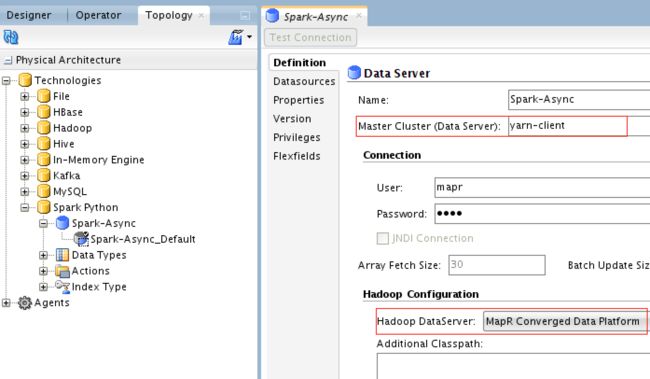
您需要将“主群集”值更改为实际使用的值:yarn-client或yarn-cluster,然后选择我们之前创建的Hadoop DataServer。
现在,这里配置的有趣部分是Spark-Async数据服务器的属性:

我已经强调了您需要注意的最重要的部分。 之所以使用ASYNC,是因为我们将使用Spark Streaming。 其余属性与性能有关。
卡夫卡数据服务器
在这里,我们将定义MapR Streams数据服务器:
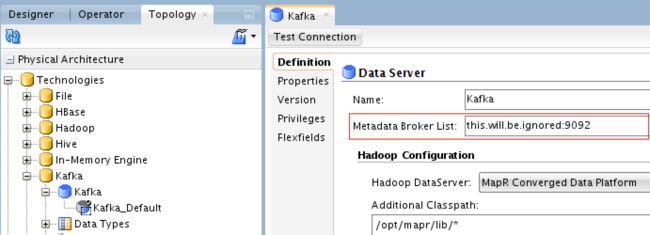
元数据代理具有一个“虚拟”地址,仅符合Kafka API。 MapR Streams客户端将为您提供连接到MapR Streams所需的服务。 您不能在此处测试数据服务器,因为在MapR上没有运行这样的Kafka服务器。 因此,请安全地忽略此处的测试连接,因为它将失败(这样就可以了)。
对于属性,您需要定义以下内容:
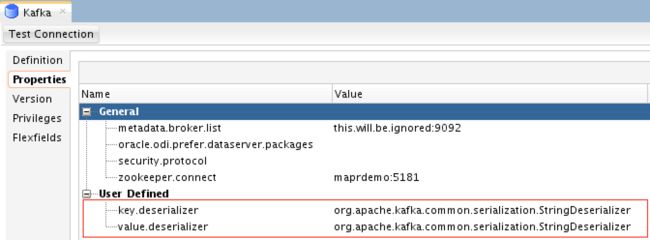
您需要手动定义“ key.deserializer”和“ value.deserializer”。 MapR Streams都需要两者,如果未定义作业,作业将失败。
ODI映射设计
我已经在这里进行了测试,涵盖了五个用例。 但是,我将仅介绍一个完整的内容,并突出显示其他内容,以免您阅读多余和常识性的步骤。
1)MapR Streams(Kafka)=> Spark Streaming => MapR Streams(Kafka):
在此映射中,我们将从先前创建的主题之一中读取流数据,应用一些函数(简单的函数),然后将结果生成到另一个主题。 这是映射的逻辑设计:

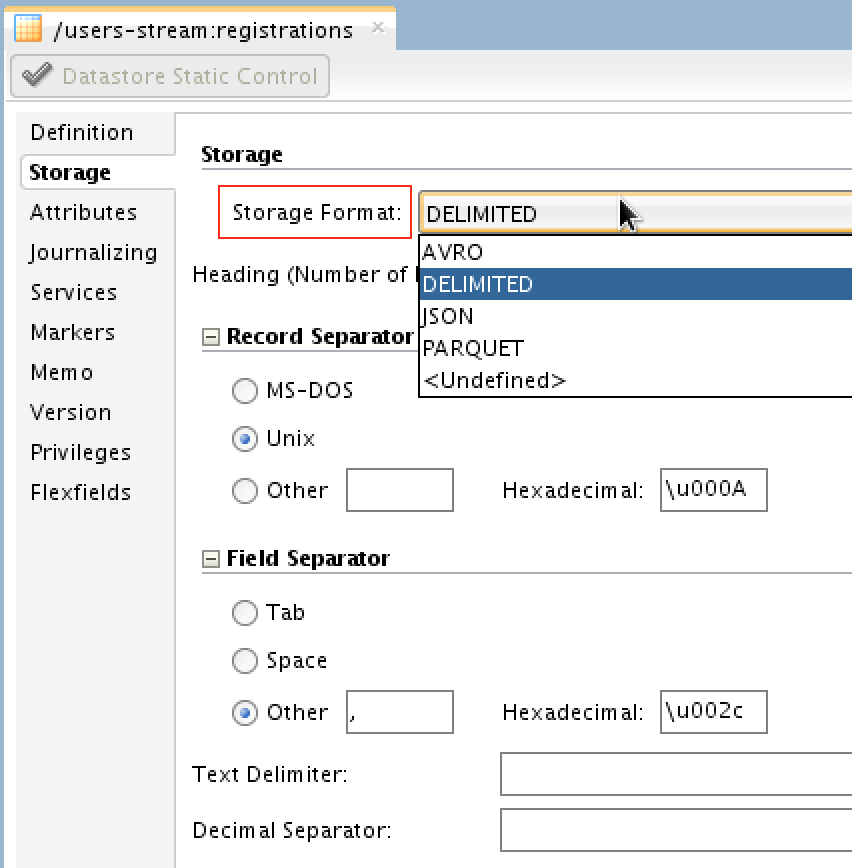
我通过复制已经为MySQL反向工程设计的模型之一(结构相同)定义了MapR_Streams_Registrations1模型,但是在这种情况下,当然选择的技术是Kafka。 您将能够选择流数据的格式:Avro,JSON,Parquet或Delimited:
物理设计如下所示:

- SOURCE_GROUP:这是我们的MapR Streams主题“注册”
- TRANS_GROUP:这是我们的Spark异步服务器
- TARGET_GROUP:这是我们的MapR Streams主题“ registrations2”
物理实现的属性为:

您需要选择暂存位置作为Spark Async并启用“流式传输”。
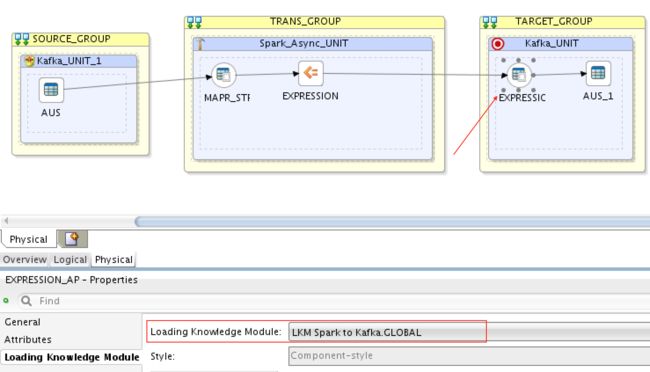
要将主题(注册)中的流数据加载到Spark Streaming,我们需要选择合适的LKM,即LKM Kafka到Spark:

然后从Spark Streaming加载到MapR Stream目标主题registrations2,我们需要选择LKM Spark到Kafka:
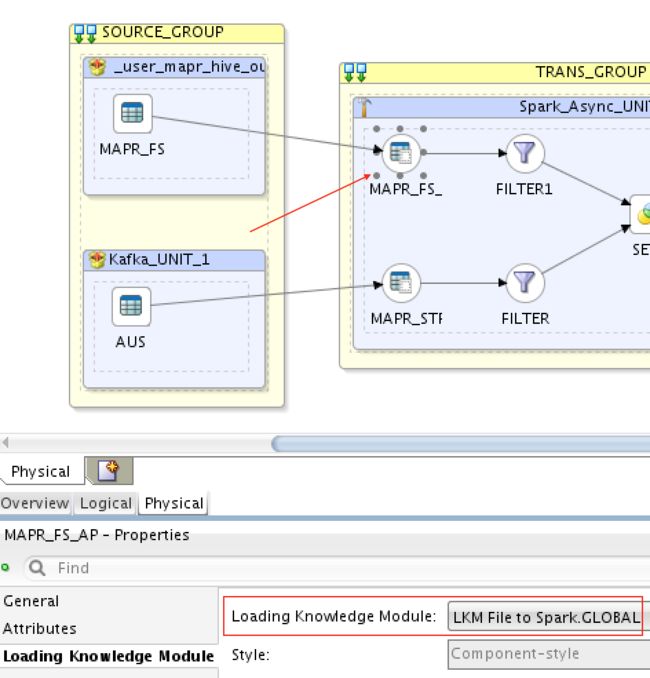
2)MapR-FS(HDFS)=> Spark Streaming => MapR Streams(Kafka):
除了使用的知识模块之外,我在这里不会向您展示太多。 要将MapR-FS(HDFS)加载到Spark Streaming,我使用了LKM File来Spark:
为了从Spark Streaming加载到MapR Streams,我像以前的映射一样使用LKM Spark到Kafka。
注意:LKM File to Spark将充当一个流,一个文件流(显然)。 ODI将仅接收任何更新/新文件,而不是静态文件。
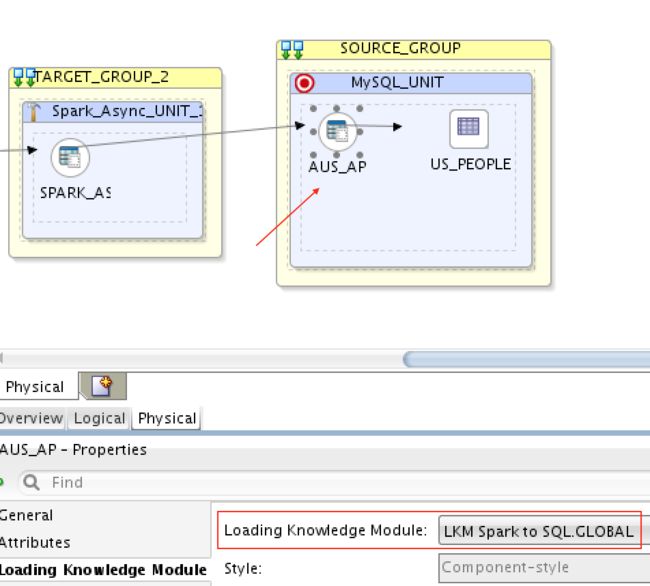
3)MapR Streams(Kafka)=> Spark Streaming => MySQL:
要将MapR Streams(Kafka)加载到Spark Streaming,就像在第一个映射中一样,我使用了LKM Kafka到Spark。 然后从Spark Streaming加载到MySQL,我使用了LKM Spark到SQL:
4)MapR流(Kafka)=> Spark流=> MapR-FS(HDFS)
为了从MapR流加载到Spark流,我像以前一样使用LKM Kafka到Spark,然后从Spark流加载到MapR-FS(HDFS),我已经使用LKM Spark到File:
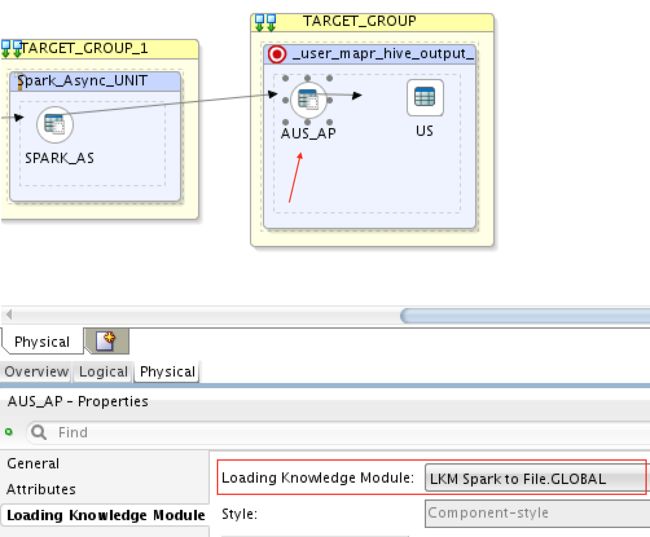
5)MapR Streams(Kafka)和Oracle DB => Spark Streaming => MySQL
这是另一个有趣的用例,您实际上可以在现场将Kafka流与SQL源一起加入。 这仅(当前)适用于查找组件:
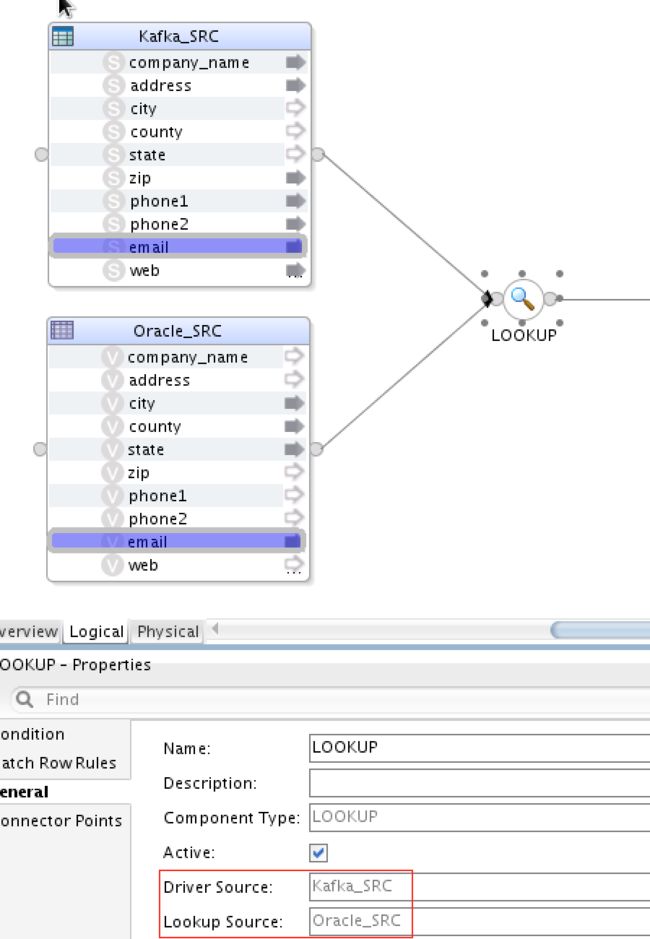
请注意,驱动程序源必须是Kafka(在我们的示例中为MapR流),而查找源必须是SQL数据库。 我使用了与以前的映射几乎相同的LKM:从LKM SQL到Spark,从LKM Kafka到Spark和从LKM Spark到SQL。
行刑
我将仅向您展示第一个用例的执行步骤,即MapR Streams(Kafka)=> Spark Streaming => MapR Streams(Kafka)。 为了模拟这种情况,我创建了一个Kafka生产者控制台和另一个Kafka消费者控制台,以便可以监视结果。 查看下面的生产者,我粘贴了一些记录:

我已经突出显示了其中一个URL,以确保您注意到它是小写的。 等待几秒钟,Spark将处理这些消息并将其发送到目标MapR Streams主题:

请注意,所有URL均大写。 成功!
通过映射,结果与预期的一样。 我不会为他们展示测试步骤,因为它们很简单。 这里的想法是向您展示如何使用MapR Streams(Kafka)配置ODI。

最后的话
值得一提的是,在执行任何映射时,您都可以深入查看日志并查看正在发生的事情(生成的代码等)。 此外,您将获得指向工作历史URL的链接,以在Spark UI上进行访问:
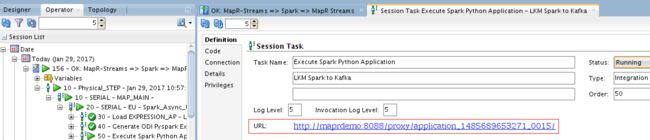
打开链接将带我们到Spark UI:
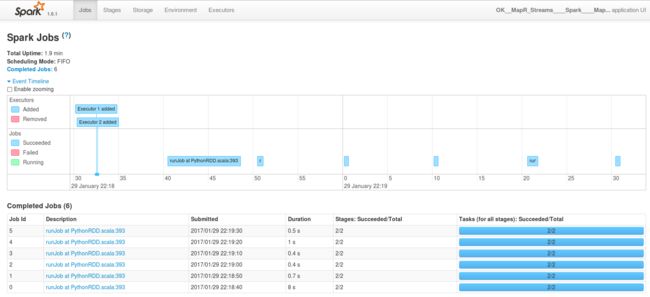
如果要控制流作业可以生存多长时间,则需要增加Spark-Async数据服务器的“ spark.streaming.timeout”属性,或从映射配置本身覆盖它。 您可能还需要创建一个ODI程序包,该程序包具有一个循环和其他有用的组件来满足您的业务需求。
结论
ODI可以处理lambda架构中的两个层:批处理层和快速层。 这不仅是ODI在其非常长的综合功能列表中添加的一项重要功能,而且还将提高从一个统一,易于使用的界面设计数据管道的生产率和效率。 显然,ODI可以像使用商品Kafka一样轻松地与MapR Streams一起使用,这要感谢MapR的二进制文件与Kafka API兼容,以及ODI不需要依赖于一个框架。 这向您保证ODI是与众不同的真正开放和模块化的E-LT工具。
其他一些相关职位:
- Oracle Data Integrator和MapR融合数据平台:请检查!
- 使用Oracle GoldenGate将事务数据流式传输到MapR流中
- 使用Oracle GoldenGate进行MapR-FS实时事务数据提取
- 带有ODI的逆向工程师MapR-DB
免责声明
这里表达的思想,实践和观点仅是作者的观点,不一定反映Oracle的观点。
翻译自: https://www.javacodegeeks.com/2017/02/perfecting-lambda-architecture-oracle-data-integrator-kafka-mapr-streams.html
ip integrator