X86汇编语言从实模式到保护模式20:平坦模型
1 引入平坦模型(Flat Model)的原因
1.1 内存管理模型变迁
1.1.1 分段模型
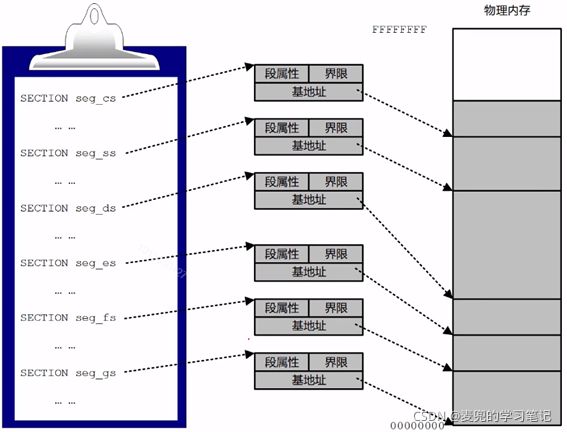
1.1.1.1 基本特点
1. 在程序中按结构组织为多个段
2. 在加载程序时,为程序中的每个段创建段描述符,其中,
① 基地址给出段的起始物理地址
② 界限值给出段的长度(或者说是边界)
③ 段属性标识段的类型、特权级别等性质
此时段部件产生的线性地址就是物理地址
1.1.1.2 虚拟内存管理机制
1. 每个任务最多可以拥有8192 * 2个段(GDT中8192个段 + LDT中8192个段),每个段最大4GB,因此每个任务的虚拟地址空间为64TB
2. 当物理内存不足时,虚拟内存的管理机制是段的换入换出
1.1.2 分页模型
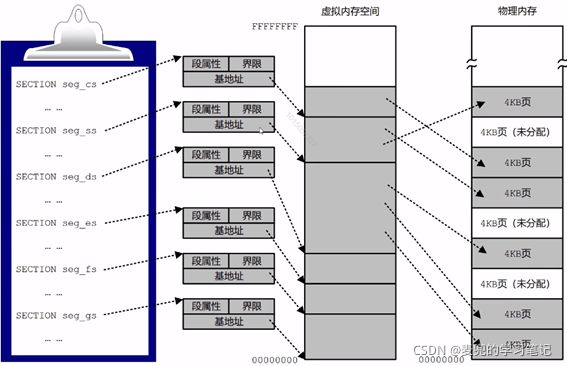
1.1.2.1 基本特点
1. 在程序中按结构组织为多个段
2. 在程序加载时,为程序中的每个段创建段描述符,其中,
① 基地址给出段的起始线性地址
② 界限值给出段的长度(或者说是边界)
③ 段属性标识段的类型、特权级别等性质
此时段部件产生的线性地址,还需要经过页部件才能转换为物理地址。所以此时的段是在任务自己的虚拟地址空间中分配,而不是在物理内存中分配
3. 在程序加载时,为程序创建页目录和页表,根据需要为程序分配物理页,并在页目录和页表中登记虚拟页和物理页的映射关系
4. 在虚拟内存空间中的分段是连续的,但是他所占用的物理页不要求是连续的
1.1.2.2 虚拟内存管理机制
1. 由于引入了分页功能,为每个任务增加了页目录和页表,加重了虚拟内存管理的负担。由于每个任务的虚拟内存是64TB,可以划分8192 * 2个段,因此当物理内存不足时,操作系统既要执行段的换入换出,也要执行页的换入换出
2. 为了简化内存管理模型,我们对分页模型下任务虚拟内存的大小进行了限制。每个任务虚拟内存的大小不再由段的数量决定,而是固定的4GB虚拟内存空间。此时,虚拟内存的管理机制就只需要进行页的换入换出
说明:从这里可以看出,随着分页机制的引入,分段机制已经被弱化
1.2 分段机制的弱化
1.2.1 为什么要分段
1. 分段机制随着8086处理器引入,该处理器拥有16位数据总线和20位地址总线,通过分段机制可以实现对1MB内存空间的访问(分段实施访问)
2. 引入分段机制带来的额外好处,是可以用很简单的方法实现程序的浮动和重定位(不分段也可以实现,只是会麻烦很多)
下面就通过3个步骤来说明这个额外的好处
说明:通过分段机制实现运行时重定位
① 程序重定位就是可以将程序加载到内存中的任何位置,并正确运行
② 在有分段机制的情况下,程序中的每个段按如下方式组织,
- 每个段的汇编地址从0开始(通过vstart = 0子句)
- 代码使用段内偏移地址(不使用硬编码地址)
③ 将程序加载到内存的任意地址时,可以计算出程序中各段在内存中的起始地址
- 如果没有开启分页功能,此时得到的是各段在物理内存中的起始地址
- 如果开启分页功能,此时得到的是各段在4GB线性地址空间中的起始地址
④ 将上一步计算得到的段的起始地址赋值给段寄存器,或者在保护模式下构造段描述符并将对应的段选择子赋值给段寄存器,就可以实现程序的重定位
1.2.2 分段机制弱化的原因
在32位时代,分段机制依然被保留下来,并且在此基础上构建了保护模式,但是随着分页机制的引入,由于以下原因,分段机制被逐渐弱化
1. 和8086处理器不同,32 / 64位处理器有完整的数据 / 地址总线,不需要分段就可以访问全部物理内存,也就是说当时8086处理器引入分段机制的基础没有了
2. 如上文所述,为了简化内存管理模型,在分页模型中已经限制了分段机制的作用,将任务的虚拟地址限制在4GB
3. 分页机制中,物理页也有属性值,也可以进行特权级管理
说明:在分页模型中,分段机制带来的程序重定位优势也被弱化
① 在之前章节的示例代码中,我们在分页模式下还保留了分段机制。在加载程序时,会先在4GB线性地址空间中分段,然后再通过分页机制将线性地址映射到物理地址
② 但是你仔细想一想,这里的分段是没有必要的。现在每个任务拥有4GB线性地址空间,任务的大小也被限制在4GB,而一个段的最大尺寸也是4GB,因此可以一次性完成程序到4GB线性地址空间的映射
而这种不分段(准确说是只分一个段)的方法,就是平坦模型的思路
1.3 平坦模型下内存管理模型

首先需要强调如下2点,
1. 分段机制作为X86处理器的固有机制,是无法绕过的。处理器总是按照[段基址 + 段内偏移]的方式生成线性地址
2. 平坦模型一定是在开启分页机制的情况下使用的,因为平坦模型的基础就是分页模型带来的4GB线性地址空间,而平坦模型就是在这个空间中平坦
平坦模型下的内存管理模型基本特点如下,
1. 在程序中实质上不分段,实际上就是只保留一个段,代码和数据都在这个段内
2. 系统中仍然需要构造段描述符,但是每个段的线性基地址均为0,段界限均为0xFFFFF,段粒度均为4KB,也就是说每个段描述符都指向完整的4GB线性地址空间
3. 在程序加载时,将程序一次性加载到线性地址空间中,同时创建页目录和页表,建立线性地址空间到物理内存的映射
说明1:什么叫程序中实质上不分段
① 在平坦模型中,程序中依然可以分段。但是此时程序中分段的作用只是一个容器,用于在逻辑上组织不同功能的代码,而不具备内存管理上的意义
② 那么什么叫不具备内存管理上的意义呢?就是在加载程序时,不会为这些程序中的段构建段描述符
说明2:在平坦模型中构造段描述符
① 平坦模型不是不构造段描述符,也不是只构造一个段描述符,而是所有段描述符描述的段都是4GB的
② 实际上,根据需要一个程序至少要构建数据段描述符和代码段描述符,这是因为这2个段描述符虽然描述符的段都是4GB的,但是类型不同
③ 在这种模式下,程序无法完全得到段机制的保护,因为所有的代码执行和数据访问都不会越界(但是段机制的特权级保护还是生效的,只是界限检查失效了)
2 平坦模型下MBR加载内核
2.1 在MBR中创建段描述符

2.1.1 定义mbr段的作用
1. BIOS将MBR加载到物理内存的[0x0000:0x7C00]处运行,MBR开始运行时,处理器处于实模式
2. MBR中定义了mbr段,该段不具备内存管理上的意义,因为此时还处于实模式。该段的作用是组织代码,用来计算段内代码的汇编地址(vstart=0x00007c00子句的作用)
2.1.2 计算GDT逻辑地址
1. MBR中定义了pgdt标号,用于存储GDT的起始地址和表界限,其中将GDT规划存储在物理内存0x00008000处,表界限则根据实际情况填写

2. MBR从pgdt标号处取出MBR的物理地址后,将其分解为逻辑地址,用于在实模式下访问
2.1.3 创建段描述符
1. MBR中共创建了2个段描述符,一个是代码段描述符,一个是数据段描述符,他们描述符的段均为4GB
2. 之所以创建2个4GB的段,是因为段是有类型的。代码段只能用来执行,数据段只能用来读写,因此需要根据不同的用途来创建
说明1:在平坦模式下每个段均为4GB,不需要创建多个段就能访问全部内存,因此只创建一个代码段和一个数据段即可
说明2:尽管栈段是特殊的数据段,但是也可以用普通的数据段作为栈段,所以这里只创建了一个数据段,既作为数据段也作为栈段使用
说明3:此时的栈段是向上扩展的,需要注意栈指针的设置方式,应该在栈段高端,而不是0x0
需要注意的是,栈段类型的向上扩展只是影响段界限的检查方式,并不影响栈的推进方向,栈的推进方向依然是从高地址向低地址使用
2.2 进入保护模式

1. 通过远跳转指令刷新CS段寄存器,使用的是4GB代码段选择子
2. 使用4GB数据段选择子刷新DS / ES / FS / GS / SS段寄存器
3. 栈指针初始化为0x7000,这是使用向上扩展的数据段作为栈段时的栈指针初始化方式(作为对比,如果使用向下扩展的数据段作为栈段,栈指针应初始化为0x0)
说明1:至此就可以看出平坦模型的优势,因为所有段都是4GB的,所有段寄存器都指向当前任务的全部线性地址空间,所以不再需要在段之间进行切换。体现在代码上,就是不再有保存 & 加载段寄存器的操作
说明2:物理内存布局

接下来MBR就要开始加载内核了,因此需要先知道内核程序的布局
2.3 内核程序布局
2.3.1 内核加载目标
1. MBR在开启分页机制的情况下加载内核
2. 内核加载到物理内存0x00040000处
3. 开启分页后,任务全局部分的线性地址从0x80000000开始,对应物理内存低端1MB。那么物理内存0x00040000对应的线性地址是0x80040000
根据上述目标,内核程序的汇编地址必须从0x80040000开始
说明:MBR加载内核的物理地址,在MBR中已定义为常量
![]()
2.3.2 如何让内核汇编地址从0x80040000开始
2.3.2.1 内核不分段 + org指令
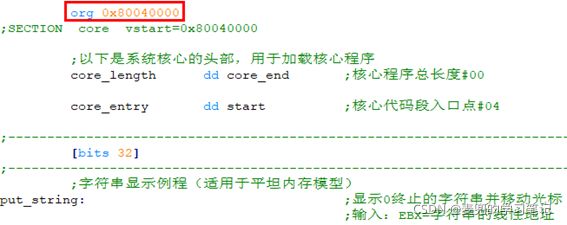
1. 注释掉内核程序中所有的段定义语句(SECTION语句)
2. 在内核程序起始处使用org伪指令定义起始汇编地址
2.3.2.2 内核分为一个段 + vstart子句

这种方式与上一种方式类似,
1. 内核所有的代码和数据都定义在core段中
2. 使用vstart子句将core段的起始汇编地址设置为0x80040000
2.3.2.3 内核分为多个段 + vstart子句 + vfollows子句
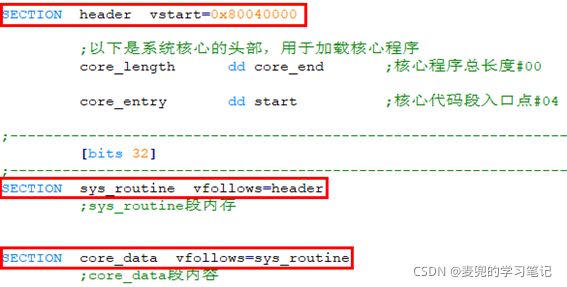
1. 内核依然按结构定义多个段,首个段使用vstart子句指定起始汇编地址为0x80040000
2. 后续段使用vfollows子句指定段内起始汇编地址接续上一个段
说明1:从内核分为多个段的示例可以看出,这些段只是用来分割程序中的不同部分,没有内存管理上的意义,并不会为这些段建立段描述符
说明2:无论程序中是不分段,只分一个段,还是分多个段,目的就是要让程序中的标号统一编址,都具有连续的汇编地址
由于程序的代码和数据是连续编址的,当我们将程序加载到任务的线性地址空间时,每条指令和每个数据在4GB线性地址空间中的偏移量也就确定了
因为段的线性基地址始终为0,这些偏移量也就是他们的线性地址,而程序中只需要按照往常的方式(也就是使用段内偏移量的方式)来访问数据和执行指令即可
说明3:Linux操作系统在i386体系结构中就使用了平坦模型,从而"绕过"了处理器的分段机制,使得段内偏移量在数值上等于线性地址。这样Linux操作系统就可以同时兼容那些不支持分段机制的处理器(其实大多数处理器在硬件上均不支持分段机制)
说明4:在平坦模型下,编译系统需要处理程序各组件的汇编地址在4GB地址空间中的布局
而可以这么做,又是因为引入了分页机制之后,所有任务都有自己独立的4GB线性地址空间。因此所有任务可以使用相同的线性地址空间布局,然后依靠分页机制映射到不同的物理内存
2.4 加载内核流程
2.4.1 读取内核到物理内存

说明:内核程序头部信息

需要注意的是,在平坦模型下,内核入口点(core_entry)只需要偏移量,不再需要段选择子
2.4.2 开启分页机制

说明:为何还需要恒等映射?
① 此处将物理内存低端1MB同时映射到4GB线性地址空间的0x00000000 ~ 0x00100000(恒等映射)和0x80000000 ~ 0x080100000(线性映射)
② 之前需要恒等映射,是因为MBR先将内核加载到物理内存的低端1MB,之后在内核中使能分页功能。此时内核的物理地址在低端1MB,段部件产生的线性地址也在低端1MB(因为在没有开启分页功能时,段部件产生的线性地址就是物理地址,所以该线性地址在低端1MB)
因此需要恒等映射,才能确保在使能分页机制后内核仍能正常工作
③ 目前是在加载内核之前开启分页功能,那么恒等映射就肯定是给MBR用的了,而需要的原因和之前是一样的。在MBR从无分页的保护模式切换到有分页的保护模式时,段部件产生的线性地址仍然在低端1MB继续执行MBR
当执行流从MBR跳转到内核运行时,恒等映射将完成自己的使命
2.4.3 修改GDT线性地址

1. GDT被部署在物理地址0x00008000处,在未开启分页的保护模式下,段部件产生的线性地址就是物理地址,因此加载到GDTR中的GDT线性地址就是物理地址0x00008000
2. 由于内核最终是要使用0x80000000处的高端线性映射(低端的恒等映射将被后续用户任务的页表替换),因此GDTR中记录的GDT线性地址也要更新为高端线性地址
3. 当有加载段寄存器的操作时,处理器会根据GDTR中记录的线性地址查询GDT,因此在内核加载段寄存器之前,需要完成上述更新GDTR的操作
说明:由于GDT中的段描述符均指向4GB线性地址空间,所以此处不需要修改段描述符中的线性基地址,也就不需要重新加载CS / DS / ES / SS等段寄存器
2.4.4 开启分页功能

注意此处设置了栈指针,将内核栈映射到高端线性地址
2.4.5 跳转到内核执行
![]()
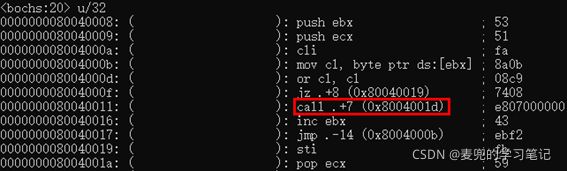
1. 这是一个32位段内间接绝对转移,因为在平坦模型下,代码都是在一个段内
2. 转移的目标地址是内核头部定义的内核入口点

3. jmp指令在此处有2个功能
① 转移到内核执行
② 将处理器的执行流转移到线性地址高端
说明:平坦模式下如何解决程序重定位?
① 从MBR加载内核并跳转到内核执行的过程可见,在平坦模式下,加载程序的目标线性地址就是程序的汇编地址。这样就可以确保跳转到被加载的程序时,可以正确运行
② 而可以将程序直接加载到其汇编地址的基础就是分页机制,他使得每个程序都有独立的4GB线性地址空间,相当于将编译程序时的地址空间布局直接映射到4GB线性地址空间
③ 由此也可以看出,在现代操作系统中,程序的运行需要编译器和加载器的配合。例如在Linux环境下,在编译器和加载器之间约定了ELF文件格式
3 平坦模型下内核初始化
说明:平坦模式下的内核初始化与之前类似,此处仅记录重要的差异部分
3.1 初始化中断系统


在平坦模式下初始化IDT与之前类似,
1. 0 ~ 19号中断使用general_exception_handler处理
2. 20 ~ 255号中断使用general_interrupt_handler处理
3. 修改0x70号中断,使用rtm_0x70_interrupt_handle处理
说明1:IDT的线性地址
参考之前的物理内存布局,IDT被布署在物理内存的0x0001F000处,因此对应的高端线性地址为0x8001F000
说明2:在调用make_gate_descriptor例程时使用的不再是内核段选择子,而是平坦模型的4GB代码段选择子
说明3:在平坦模型中为什么还需要flat_4gb_code_seg_sel段选择子?
经过上机验证,如果没有flat_4gb_code_seg_sel段选择子,运行会失败,下面调试一下该过程
① 有代码段选择子
使用有代码段选择子的段间跳转时,是绝对跳转,可以跳转成功


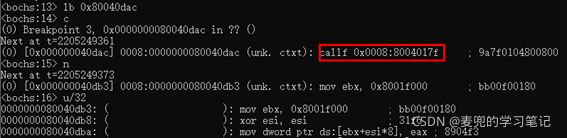
② 没有代码段选择子
使用没有代码段选择子的段内跳转时,是相对跳转,跳转失败



③ 原因分析
- 猜测是相对跳转的偏移量超过call指令编码范围,导致跳转失败
- 因为内核代码中也有使用call指令相对跳转,但是跳转范围较小

3.2 打印字符串

在打印字符串时,使用高端线性地址访问显存
3.3 安装调用门

在SALT表中设置的段选择子也是内核4GB代码段,而不是内核例程段
3.4 确立内核任务

说明1:简化后的TCB格式
由于采用了平坦模型,任务的创建过程得到了简化,所以我们对TCB格式也进行了简化

我们可以对比一下之前的TCB格式

说明2:TSS段内存分配
此处使用alloc_core_linear宏分配TSS段所需内存空间,该宏实现如下

该宏在内核任务的线性地址空间分配一个虚拟页,同时分配一个物理页,并修改页表建立映射关系。调用完成后,EBX中保存着分配的虚拟页的起始线性地址
3.5 宏汇编技术
3.5.1 宏汇编概述
1. 宏(Macro)是一种简化汇编语言程序编写的方法,作用是代替复杂的表达式
2. 宏是一种预处理指令,在编译期间先被编译器展开,之后再被编译成机器指令
3. 宏定义不占用程序的地址空间
4. 宏定义不能滥用,否则代码将既难阅读,又难维护
3.5.2 单行宏汇编
单行宏汇编使用%define定义,格式如下
%define 宏名(参数列表) 宏的具体内容宏参数要放在括号内,如果有多个参数,需要用逗号分开
示例:
%define vrm(x) 0xb8000+x
;宏调用
mov byte [(vrm(0x02))], 'h'
;宏展开
mov byte [0xb8000+0x02], 'h'3.5.3 多行宏汇编
多行宏使用%macro定义,格式如下
%macro 宏名字 参数个数
宏的具体内容
%endmacro示例:
%macro dostack 2
push ebp
mov ebp, esp
sub esp, %1 ;使用第1个参数
add dword [0x2000], %2 ;使用第2个参数,参数编号依此类推
%endmacro
;宏调用
dostack 8, 0x55aa
;宏展开
push ebp
mov ebp, esp
sub esp, 8 ;使用第1个参数
add dword [0x2000], 0x55aa ;使用第2个参数,参数编号依此类推说明:内核中定义的alloc_core_linear宏,则是一个没有参数的多行宏
4 平坦模型下内核加载用户程序
4.1 平坦模型下的用户程序结构

在平坦模型下,用户程序的结构非常简单
1. 用户程序也是不分段,或只分为一个段,目的也是统一程序中标号的汇编地址
2. 由于没有进行其他设置,用户程序汇编地址从0开始。这就要求用户程序在加载时,不但要加载到他自己的线性地址空间,而且起始的线性地址必须是0
说明:在平坦模型下,用户程序的入口点也不需要段选择子,用户代码段也是4GB
4.2 加载用户程序流程
4.2.1 分配用户任务TCB

1. 用户任务TCB也使用alloc_core_linear宏在内核任务的线性地址空间中分配,因为需要在内核中管理所有任务的TCB
2. 用户任务内存分配的起始线性地址为0
说明:在平坦模型下,如下线性地址之间需要相互匹配
① 用户任务内存分配的起始线性地址,决定了用户程序可用的线性地址范围
② 用户程序的汇编地址,决定了用户程序中标号的汇编地址
③ 用户程序的加载线性地址,用户程序的加载线性地址必须和用户程序的汇编地址一致
4.2.2 清空内核页目录低2GB
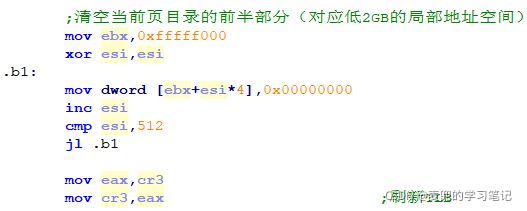
由于要借用内核页目录低2GB创建用户页表,所以此处先行清空,同时刷新TLB
4.2.3 加载用户程序

说明:alloc_user_linear宏

alloc_user_linear宏在指定任务的线性地址空间中分配一个虚拟页,同时分配一个物理页,并修改页表建立映射关系。其中,指定任务的TCB保存在ESI寄存器中
4.2.4 分配用户任务TSS & LDT段

1. 用户任务TSS段使用alloc_core_linear宏在内核任务线性地址中分配
2. 用户任务LDT段使用alloc_user_linear宏在用户任务的局部线性地址中分配
4.2.5 创建用户代码段 & 用户数据段

1. 为使用户程序也工作在平坦模型,此处创建了4GB用户代码段 & 用户数据段,他们和4GB内核代码段 & 内核数据段的区别在于
① 4GB用户代码段 & 数据段的段描述符特权级为3(内核段特权级为0)
② 4GB用户代码段 & 数据段的段描述符安装在用户任务的LDT中(内核段安装在GDT中)
2. 需要将生成的用户代码段 & 数据段选择子填写到TSS段中的相应字段,当切换到该任务执行时,处理器会将TSS段中的内容加载到相应的段寄存器
4.2.5 创建用户任务栈

1. 用户程序的栈段不是在用户程序中指定的,而是在加载并创建用户程序时分配
2. 用户程序的栈段在用户任务的线性地址空间中分配,示例代码中分配了4KB
3. TSS段中的SS域设置为4GB用户数据段选择子,虽然栈段很大,但是实际可用的栈空间只有分配的4KB,因此存在栈越界访问的问题
4. 由于使用向上扩展的数据段作为栈段,因此初始栈指针应该是分配的栈内存空间的高端线性地址,也就是下一次内存分配时的起始线性地址
说明:栈越界了怎么办?
栈越界会触发缺页异常,操作系统需要在缺页异常处理中判断出栈越界的情况,同时进行相应的处理(e.g. 直接返回错误或动态扩展栈的大小)
4.2.6 创建各特权级栈
无论是用户程序使用调用门,还是进行中断 & 异常处理,都会进行特权级切换,因此需要为各特权级建立栈(实际只用到了特权级3和特权级0)

1. 各特权级栈段也是在用户任务的线性地址空间中分配,示例程序均分配了4KB
2. 需要为各特权级栈创建段描述符,均为4GB数据段,只是特权级不同
3. 这些段描述符均安装在用户任务的LDT中,因此用户任务的LDT中安装了如下段的描述符
① 4GB用户代码段
② 4GB用户数据段,同时用作用户任务本级栈段
③ 特权级0、1、2的4GB数据段,用作各特权级栈段
4.2.7 重定位SALT

在平坦模型下重定位SALT的过程与之前类似,此处说明2点
1. 由于使用平坦模型,在使用cmpsd指令进行比较时,不再需要重新设置DS & ES段寄存器,他们目前均指向4GB内核数据段
2. 可以通过[0x0c]获取用户程序的SALT条目数,是因为此时用户程序已经被加载到线性地址0处。需要注意的是,此时是通过4GB内核数据段访问低端线性地址空间,这也体现了借用内核任务页表创建用户任务页表的特征
4.2.8 创建TSS & LDT段描述符

4.2.9 创建用户页目录

创建用户页目录仍然是调用create_copy_cur_pdir例程,分配一个物理页作为用户任务的页目录,之后将内核任务页目录中的内容拷贝到用于任务页目录
4.2.10 将用户任务加入TCB链表

至此,用户任务就创建完成了,并可以参与调度
5 平坦模型总结
1. 平坦模型的要义就是系统中创建的段,都是起始线性地址为0,范围为4GB,覆盖整个任务的线性地址空间
2. 由于段的线性起始地址为0,就失去了分段机制进行程序浮动和重定位的作用。因为分段机制实现程序浮动和重定位依靠如下2点,
① 程序中使用相对于段起始处的地址(程序中段的起始线性地址一般设置为0),而不是绝对地址
② 在加载程序中的段时,根据实际的加载位置设置相应段描述符的起始线性地址
3. 那么在平坦模型中,加载程序的目的线性地址就必须是程序的汇编地址