SQL力扣练习(十)
目录
1.体育馆的人流量(501)
示例 1
解法一(row_number())
解法二(自定义变量)
解法三
2.好友申请(602)
示例
解法一(union all)
解法二
3.销售员(607)
示例
解法一
解法二
1.体育馆的人流量(501)
表:Stadium
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | visit_date | date | | people | int | +---------------+---------+ visit_date 是表的主键 每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people) 每天只有一行记录,日期随着 id 的增加而增加
编写一个 SQL 查询以找出每行的人数大于或等于 100 且 id 连续的三行或更多行记录。
返回按 visit_date 升序排列 的结果表。
查询结果格式如下所示。
示例 1
表: +------+------------+-----------+ | id | visit_date | people | +------+------------+-----------+ | 1 | 2017-01-01 | 10 | | 2 | 2017-01-02 | 109 | | 3 | 2017-01-03 | 150 | | 4 | 2017-01-04 | 99 | | 5 | 2017-01-05 | 145 | | 6 | 2017-01-06 | 1455 | | 7 | 2017-01-07 | 199 | | 8 | 2017-01-09 | 188 | +------+------------+-----------+ 输出: +------+------------+-----------+ | id | visit_date | people | +------+------------+-----------+ | 5 | 2017-01-05 | 145 | | 6 | 2017-01-06 | 1455 | | 7 | 2017-01-07 | 199 | | 8 | 2017-01-09 | 188 | +------+------------+-----------+ 解释: id 为 5、6、7、8 的四行 id 连续,并且每行都有 >= 100 的人数记录。 请注意,即使第 7 行和第 8 行的 visit_date 不是连续的,输出也应当包含第 8 行,因为我们只需要考虑 id 连续的记录。 不输出 id 为 2 和 3 的行,因为至少需要三条 id 连续的记录。
解法一(row_number())
首先使用窗口函数row_number()对大于等于100的进行标序号,然后我们可以发现此时id和 row_number()之间存在一个规律,即id-row_number()可以为连续的大于等于100的进行分组。然后将它作为一个临时表,再从中选出每组数量大于等于3的即可。
# Write your MySQL query statement below
with t as(
select *,
id-row_number() over (order by id) c
from stadium where people>=100
)
select id,visit_date,people from t where c in(
select c from t group by c having count(c)>=3
)
解法二(自定义变量)
首先用自定义变量@count为大于等于100的排序,
然后从第一步的表中筛选出数量大于三的,如下图,这里重点是从大到小排序。
然后再筛选即可得到答案。
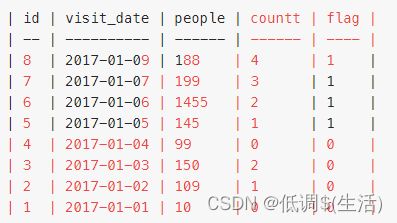
SELECT id, visit_date, people
FROM (
SELECT r1.*, @flag := if((r1.countt >= 3 OR @flag = 1) AND r1.countt != 0, 1, 0) AS flag
FROM (
SELECT s.*, @count := if(s.people >= 100, @count + 1, 0) AS `countt`
FROM stadium s, (SELECT @count := 0) b
) r1, (SELECT @flag := 0) c
ORDER BY id DESC
) result
WHERE flag = 1 ORDER BY id;解法三
自连接
SELECT distinct a.*
FROM stadium as a,stadium as b,stadium as c
where ((a.id = b.id-1 and b.id+1 = c.id) or
(a.id-1 = b.id and a.id+1 = c.id) or
(a.id-1 = c.id and c.id-1 = b.id))
and (a.people>=100 and b.people>=100 and c.people>=100)
order by a.id;2.好友申请(602)
在 Facebook 或者 Twitter 这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。
RequestAccepted 表:
+----------------+---------+ | Column Name | Type | +----------------+---------+ | requester_id | int | | accepter_id | int | | accept_date | date | +----------------+---------+ (requester_id, accepter_id) 是这张表的主键。 这张表包含发送好友请求的人的 ID ,接收好友请求的人的 ID ,以及好友请求通过的日期。
写一个查询语句,找出拥有最多的好友的人和他拥有的好友数目。
生成的测试用例保证拥有最多好友数目的只有 1 个人。
查询结果格式如下例所示。
示例
输入: RequestAccepted 表: +--------------+-------------+-------------+ | requester_id | accepter_id | accept_date | +--------------+-------------+-------------+ | 1 | 2 | 2016/06/03 | | 1 | 3 | 2016/06/08 | | 2 | 3 | 2016/06/08 | | 3 | 4 | 2016/06/09 | +--------------+-------------+-------------+ 输出: +----+-----+ | id | num | +----+-----+ | 3 | 3 | +----+-----+ 解释: 编号为 3 的人是编号为 1 ,2 和 4 的人的好友,所以他总共有 3 个好友,比其他人都多。
解法一(union all)
用union all将所有的请求id和接受id拼在一起。然后分组计数即可
select id, count(*) as num
from (
select requester_id as id from RequestAccepted
union all
select accepter_id from RequestAccepted
) as A
group by id
order by count(*) desc
limit 1;解法二
实际跟方法一差不多,只是在外层筛选数据方式不一样
with cte as
(select
requester_id as id
from RequestAccepted
union all
select
accepter_id
from RequestAccepted)
# 子查询筛选(group by having count >= all)
select
id,
count(*) as num
from cte
group by id
having count(*) >= all(select count(*) from cte group by id)
# order by limit 1
select
id,
count(*) as num
from cte
group by id
order by num desc
limit 1
# 窗口函数
select
id,num
from
(select
id,
count(*) as num,
dense_rank() over(order by count(*) desc) as rnk
from cte
group by id) t
where rnk=13.销售员(607)
表: SalesPerson
+-----------------+---------+ | Column Name | Type | +-----------------+---------+ | sales_id | int | | name | varchar | | salary | int | | commission_rate | int | | hire_date | date | +-----------------+---------+ 在 SQL 中,sales_id 是该表的主键列。 该表的每一行都显示了销售人员的姓名和 ID ,以及他们的工资、佣金率和雇佣日期。
表: Company
+-------------+---------+ | Column Name | Type | +-------------+---------+ | com_id | int | | name | varchar | | city | varchar | +-------------+---------+ 在 SQL 中,com_id 是该表的主键列。 该表的每一行都表示公司的名称和 ID ,以及公司所在的城市。
表: Orders
+-------------+------+ | Column Name | Type | +-------------+------+ | order_id | int | | order_date | date | | com_id | int | | sales_id | int | | amount | int | +-------------+------+ 在 SQL 中,order_id 是该表的主键列。 com_id 是 Company 表中 com_id 的外键。 sales_id 是来自销售员表 sales_id 的外键。 该表的每一行包含一个订单的信息。这包括公司的 ID 、销售人员的 ID 、订单日期和支付的金额。
查询没有任何与名为 “RED” 的公司相关的订单的所有销售人员的姓名。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例
输入: SalesPerson 表: +----------+------+--------+-----------------+------------+ | sales_id | name | salary | commission_rate | hire_date | +----------+------+--------+-----------------+------------+ | 1 | John | 100000 | 6 | 4/1/2006 | | 2 | Amy | 12000 | 5 | 5/1/2010 | | 3 | Mark | 65000 | 12 | 12/25/2008 | | 4 | Pam | 25000 | 25 | 1/1/2005 | | 5 | Alex | 5000 | 10 | 2/3/2007 | +----------+------+--------+-----------------+------------+ Company 表: +--------+--------+----------+ | com_id | name | city | +--------+--------+----------+ | 1 | RED | Boston | | 2 | ORANGE | New York | | 3 | YELLOW | Boston | | 4 | GREEN | Austin | +--------+--------+----------+ Orders 表: +----------+------------+--------+----------+--------+ | order_id | order_date | com_id | sales_id | amount | +----------+------------+--------+----------+--------+ | 1 | 1/1/2014 | 3 | 4 | 10000 | | 2 | 2/1/2014 | 4 | 5 | 5000 | | 3 | 3/1/2014 | 1 | 1 | 50000 | | 4 | 4/1/2014 | 1 | 4 | 25000 | +----------+------------+--------+----------+--------+ 输出: +------+ | name | +------+ | Amy | | Mark | | Alex | +------+ 解释: 根据表 orders中的订单 '3' 和 '4' ,容易看出只有 'John' 和 'Pam' 两个销售员曾经向公司 'RED' 销售过。 所以我们需要输出表 salesperson中所有其他人的名字。
解法一
先选出不符合的cname,然后not in即可
select name from SalesPerson where name not in(
select a.name from SalesPerson a
left join orders b on a.sales_id=b.sales_id
left join company c on b.com_id=c.com_id
where c.name ='RED' )解法二
先选出不符合的销售id,然后not in即可,比方法一简单点
select name from SalesPerson
where sales_id not in(
select a.sales_id
from orders a join company b
on a.com_id=b.com_id
where b.name="RED")