Wireshark TS | 循序渐进看系统访问偶发失败
前言
某日研发中心一同事反馈系统访问发生异常,时不时的会出现系统打不开现象。出现生产问题影响业务正常运行,自然是紧急响应,遂配合研发同事一起排查和处理,整个过程一波三折,总结下来该案例还是挺有意思的。
问题描述
会同研发同事一起梳理业务系统故障相关信息后,整理说明如下:
- 故障现象是业务使用人员使用系统时,偶发的会出现系统打不开现象,不定时发生;
- 业务访问路径是从互联网 DMZ 区域至内网区域;
- 同一套业务系统在测试环境中使用正常;
- 外购业务系统,技术支持人员不给力,无法提供相关有效信息。
因为在测试环境中系统使用正常,而生产环境却出现问题的缘故,所以研发同事一开始就怀疑网络有问题,情何以堪,咋能这样判断呢?锅从天上来,当然不能随随便便接之。简单了解了下问题发生的同时,两端服务器的 Ping 等其他监控均是正常的,心里感觉踏实了一半,隐约感觉不像是网络的问题。
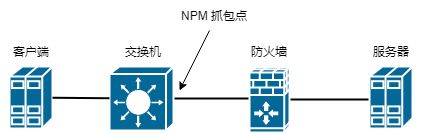
因为网络在重点 DMZ 区域部署有 NPM (刚好是客户端所在接入交换机上的镜像节点),所以根据所提供的故障时间点和业务 IP 通讯对回溯了该流量,进入实质分析。
问题分析
阶段一
通过 NPM 回溯分析设备导出的数据包文件,基本信息如下:
λ capinfos test.pcapng
File name: test.pcapng
File type: Wireshark/... - pcapng
File encapsulation: Ethernet
File timestamp precision: nanoseconds (9)
Packet size limit: file hdr: (not set)
Packet size limit: inferred: 70 bytes - 1518 bytes (range)
Number of packets: 6463
File size: 2174 kB
Data size: 1906 kB
Capture duration: 5990.797626192 seconds
First packet time: 2022-11-18 16:45:07.192079642
Last packet time: 2022-11-18 18:24:57.989705834
Data byte rate: 318 bytes/s
Data bit rate: 2545 bits/s
Average packet size: 294.95 bytes
Average packet rate: 1 packets/s
SHA256: e97bbdffd9f98d0805737cb93d6d8255acd045241aa716a8af3966b0ae5ca76f
RIPEMD160: 0329186f9145dcf38fac739077219a3d93298b34
SHA1: 9a3f06a04163f388b8800889d46fe3db04453c26
Strict time order: True
Capture comment: Sanitized by TraceWrangler v0.6.8 build 949
Number of interfaces in file: 1
Interface #0 info:
Encapsulation = Ethernet (1 - ether)
Capture length = 2048
Time precision = nanoseconds (9)
Time ticks per second = 1000000000
Time resolution = 0x09
Number of stat entries = 0
Number of packets = 6463
数据包文件通过 NPM 回溯分析下载,并根据 IP 通讯对做过特定过滤,且经过 TraceWrangler 匿名化软件处理。捕获总时长 5990 秒,数据包数量 6463 个,速率 2545 bps 很低。
- 关于 TraceWrangler 匿名化软件简介,可以查看之前的文章《Wireshark 提示和技巧 | 如何匿名化数据包》
- 另外一个比较特别的地方是
Packet size limit: inferred: 70 bytes - 1518 bytes (range),通常来说根据 snaplen 做截断,应该是一个统一的数值,也就是所有的数据包捕获长度应该是一样的,而不是一个范围值,这里是 NPM 回溯分析设备所处理设置的原因。
专家信息如下,有部分协议解析的 Error 问题,以及先前分段未被捕获到、ACK 确认了未被捕获到的分段等 Warning 问题,考虑到 ACKed unseen segment 的现象,更多是包没有捕获到,并不是什么问题。

在业务所提供的故障时间节点 16:45 - 16:48,展开了相关数据包详细信息,如下,会很明显的看到客户端 192.168.0.1 间隔很长时间才会发送数据包。

再增加 TCP 流信息列,可以看到是分属不同的 TCP 数据流(此处和业务应用相关,不做深究),单流之间上下数据包的间隔时间就更多了。
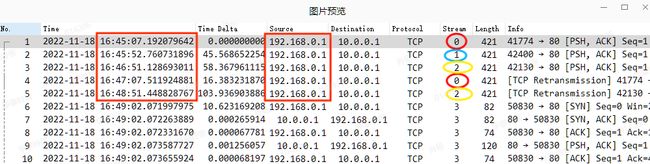
沟通当中,业务又反馈了一次打不开异常,遂向后拉长了数据包捕获时间,根据客户端的源地址进行过滤,同时增加了间隔时间从大到小排序,基本全是大时间间隔。但整体观察规律,一些流中的固定时间间隔(如 60s)更像是 GRPC 调用本身的应用逻辑,貌似不是根本问题所在。
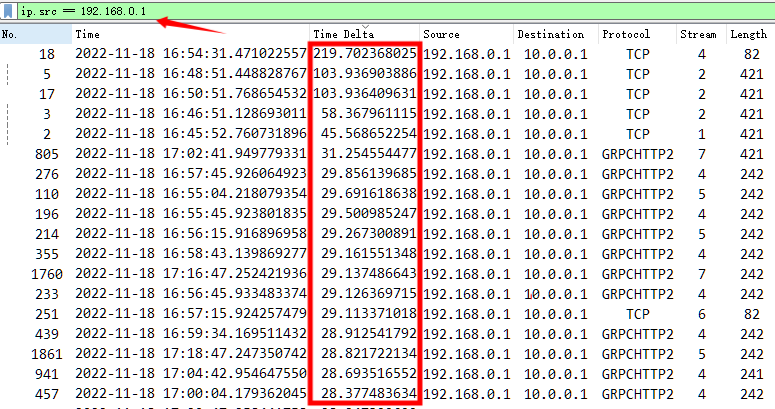
因此基于此阶段的信息,给到研发同事的意见是检查客户端 192.168.0.1 ,因为它在故障时点陷入了沉寂,并无任何数据包发出,疑似问题所在。
阶段二
研发同事带着问题和建议回去,又和技术厂商沟通了两三天,未能有实质性的原因发现,且同时问题仍在不定时的发生。继又带着疑问而来,说是 DMZ 区域的客户端请求确实发出了,但是服务器端收不到,而且强调了每天故障最开始发生的时间,都是第一次进系统时就会有异常现象,应用上现象显示就是点击页面请求发出去,但是接口一直 pending,错误日志 Connection timed out。

基于上述现象,又再次取了数据包跟踪文件,从数据包角度来看,在故障时点 11-20 15:09:33 左右,仍然是没有产生任何数据包。考虑到捕获数据包的位置就在客户端所在接入交换机上,客户端一直说发了请求,但是直连交换机在发出去的时候就根本没有看到相关数据包,真是离了大谱,难道直连丢包。。。
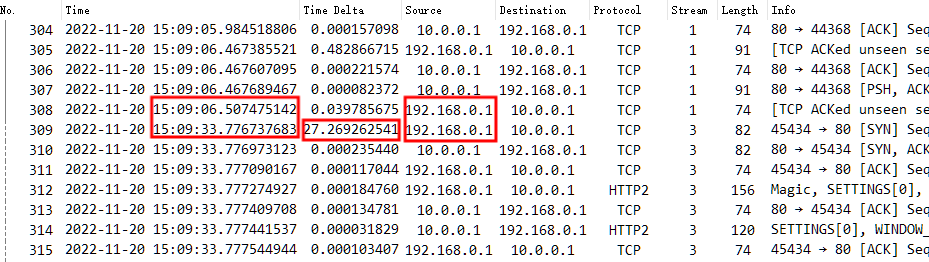
交换机上的抓包确实在 15:09:06 - 15:09:33 没有任何数据包,遂坚持之前的结论,检查客户端应用,并要求在故障发生时点在客户端上直接抓包,用来佐证客户端请求是否有发出来。
阶段三
来了来了,研发带着本地数据包来了,在客户端和服务器两端同时抓包(做了客户端 -> 服务器单方向的过滤),说是在系统故障打不开的时候,很明显看到客户端发了请求,但是服务器没收到。
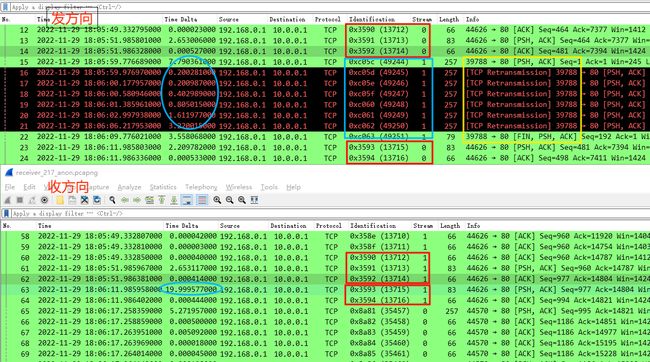
客户端发方向和服务器端收方向数据包对比如下:
- 可以看到同一条 TCP 数据流(以 ip.id 为联系),在发方向 0x3590-0x3592 与 0x3593-0x3594 连续数据包的之间,还存在着另外一条 TCP 数据流 0xc05c - 0xc063 存在,但是在收方向则仅有 0x3590-0x3594 的数据包,并没有另外一条 TCP 数据流的数据包存在;
- 这条 TCP 数据流仅仅是客户端 192.168.0.1 所发送的 PSH/ACK 数据包,因为服务器并没有收到因此无法返回确认 ACK,所以客户端不断重传共 6 次后,FIN 结束了该连接;
- 此后前一条 TCP 数据流才开始 0x3593 之后的数据包传输,整整间隔了将近 20s。
大无语事件,难道真的是啪啪打脸了嘛。。网络交换机丢包?这很不科学,既然有客户端与服务器的数据包这种交互,那么在 NPM 同样回溯分析,是否是同样的现象呢。通过下图 NPM 回溯,发现现象确实一样,同样看到了客户端所发的另一条数据流,可见上层交换机是正常将数据包转发出去了,难道是后面的网络路径中有丢包,这也不可能啊。

此时慢慢理清三个阶段的故障现象以及数据包,得出以下结论:
- 阶段一和二的结论,判断是客户端有问题,发送间隔时间长,疑似系统故障时无请求发出,但实际上当时也忽略了一个重要的问题,并没有看到服务器端的任何回包,因为不管是不是客户端有问题,服务器在收到请求的时候至少会有响应;
- 阶段三在客户端、上层交换机以及服务器端的抓包现象来看,确实客户端发送且重传了请求,但服务器没有收到,结合一直偶发的故障现象判断,不可能是网络交换机丢包,因为交换机不会很特定的只丢掉某条 TCP 数据流;
- 故障发生的同时必定有另一条数据流开始传输,它并不是凭空产生,而是直接以 PSH/ACK 开始,说明该连接在之前是一直存在,那么该数据流会是怎么样一个交互情况呢?!
带着上述疑问,又在 NPM 上往前回溯了一个小时的数据,即 17:00 至故障时间点 18:05 的数据包,发现了一个重要的现象,在如此长的时间内,该数据流空空如也,没有任何数据包交互,仅是在故障时间节点客户端单方向产生了 0xc05c - 0xc063 几个数据包,毫无响应后 FIN 结束连接。
至此我突然明白了问题所在,我一直忽略掉了一个关键环节,防火墙。在想到防火墙的时候,又回顾了整个排障过程,最终定位到了原因,综合整理如下:
- 该系统应用是个长连接应用,但应用层面以及 TCP 层面并没有开启保活机制,在该 TCP 连接空闲了一定时间后,达到了防火墙会话最大空闲时间的限制,因此防火墙拆除了该会话,而客户端和服务器仍保持有该连接,没有一个很好的结束机制;
- 对应业务反馈,每天故障最开始发生的时间,都是第一次进系统时就会有异常现象,说明是在原有的长连接上继续发送数据包,但由于防火墙无此会话信息,所以丢弃该数据包,服务器因此无法正常收到,而客户端在不断重传尝试失败后,FIN 关闭连接。
- 业务人员退出系统应用再次登录后,又可正常打开,但是如果没有任何操作,也就是再次空闲过久,防火墙仍然会删除会话,系统再次使用就又会打不开,所以这就是业务所反馈的系统访问偶发失败问题。
问题总结
因防火墙并不在网络组维护,后转至了安全组处理,之后了解到在防火墙上针对该应用 IP 通讯对单独调整了空闲会话时间限制(默认为一小时),至此业务系统恢复正常。