zabbix
zabbix是什么(重点)
- 定义:
- 组成:
- zabbix server可以通过SNMP,zabbix
- zabbix agent
- zabbix监控原理
-
- URL监控部署在系统中,包含常见的五个程序:
- 主要特点:
- zabbix工作原理
- 服务端
-
- 1、关闭防火墙,修改主机名
- 2、获取 zabbix 的下载源
- 3、更换 zabbix.repo 为阿里源,安装zabbix-server-mysql、zabbix-agent和SCL
- 4.修改zabbix-front前端源,安装zabbix前端环境到scl环境下
- 5.安装zabbix所需要的数据库
- 6.添加数据库用户,以及zabbix所需要数据库信息
- 7.查询已安装的zabbix-server-mysql的文件列表,找到sql.gz文件位置
- 8、修改 zabbix-server 配置文件/etc/zabbix/zabbix_server.conf,修改数据库的密码。
- 9.修改zabbix的php配置文件,/etc/opt/rh/rh-php72/php-fpm.d/zabbix.conf
- 10.启动zabbix相关服务
- 11.浏览器访问http://192.168.109.1/zabbix
- 12、解决zabbix-server Web页面中乱码问题
- 部署zabbix客户端(端口号10050)
-
- 1.关闭防火墙、修改主机名
- 2.服务端和客户端都配置时间同步
- 3.客户端配置时区,与服务器保持一致
- 4.设置zabbix的下载源,安装zabbix-agent2
- 5.修改agent2配置文件,/etc/zabbix/zabbix_agent2.conf
- 6.启动zabbix-agent2
- 7.在服务端验证zabbix-agent2的连通性
- 总结:
zabbix版本5.0 4.6 6.4
定义:
zabbix是一个基于web界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。
组成:
zabbix 由⒉部分构成,zabbix server与可选组件 zabbix agent。J通过c/s模式采集数据,通过B/s模式在 web端展示和配置。
zabbix server可以通过SNMP,zabbix
agent,ping,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能,它可以运行在Linux等平台上。
zabbix agent
需要安装在被监视的目标服务器上,它主要完成对硬件信息或与操作系统有关的内存,cPU等信息的收集。
zabbix监控原理
zabbix agent安装在被监控的主机上,zabbix
agent负责定期收集客户端本地各项数据,并发送至 zabbix server端,zabbix server收到数据后,将数据存储到数据库中,用户基于Zabbix WEB可以看到数据在前端展现图像。当zabbix 监控某个具体的项目,该项目会设置一个触发器阈值,当被监控的指标超过该触发器设定的阈值,会进行一些必要的动作,动作包括:发送信息(邮件、微信、短信)、发送命令(shell命令、 reboot、 restart、 install等)。
监控对象:硬件监控 系统监控 java监控 网络设备监控 应用服务监控 mysql数据库监控
URL监控部署在系统中,包含常见的五个程序:
zabbix_server、zabbix_agent、zabbix_get、zabbix_sender等
zabbix server: zabbix服务端守护进程,其中 zabbix_agent、zabbix_get、zabbix_sender、zabbix proxy的数据最终都提交给zabbix server;
zabbix agent:客户端守护进程,负责收集客户端数据,例如:收集cPU负载、内存、硬盘使用情况等;
zabbix proxy: zabbix分布式代理守护进程,通常大于500台主机,需要进行分布式监控架构部署;
zabbix get: zabbix数据接收工具,单独使用的命令,通常在server或者 proxy
zabbix sender: zabbix 数据发送工具,用户发送数据给 server 或 proxy端,通常用户耗时比较长的检查。
主要特点:
安装与配置简单 学习成本低 支持多种语言(包括中文)
免费开源 自动发现服务器 通知功能 email 微信 电话 钉钉
主要功能:监控cpu内存 IO 网络 端口 日志等
运行机制 c/s zabbix_server zabbix_agent(安装在被监控端)
zabbix工作原理

采用了两种模式(面试)
主动模式:agent向server发起连接
被动模式:server向agent发起连接
监控架构
zabbix分布式架构
server-client架构
server-proxy-client架构
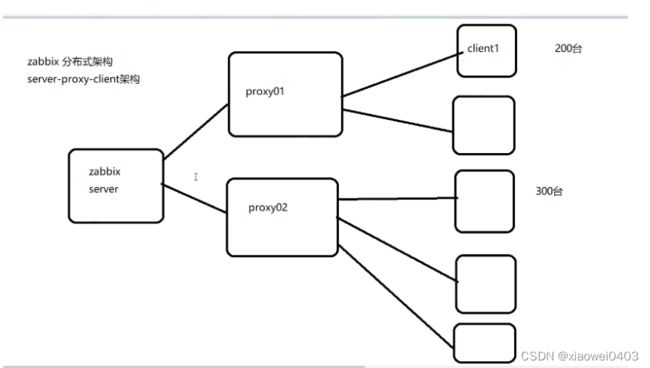
其实proxy是server和client沟通之间的桥梁,proxy本身就没有前端,而且其本身并不存放数据,只是将agent发来的数据暂时存放,而后再提交给server,这种架构是和master-node-client架构做比较的架构,一般适用于跨机房、跨网络或中型网络架构的监控
master-node-client架构
master和node其中一个挂了,没什么关系

zabbix五个应用程序
zabbix 5.0 4.6 6.4
安装zabbix
1.yum安装
2.编译安装 lamp lnmp
服务端
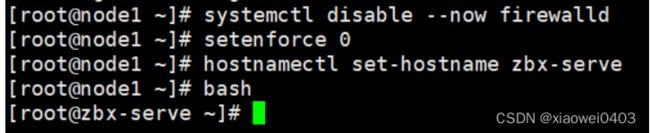
1、关闭防火墙,修改主机名
systemctl disable --now firewalld
setenforce 0
hostnamectl set-hostname zbx-server
2、获取 zabbix 的下载源
rpm -ivh https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/zabbix-release-5.0-1.el7.noarch.rpm

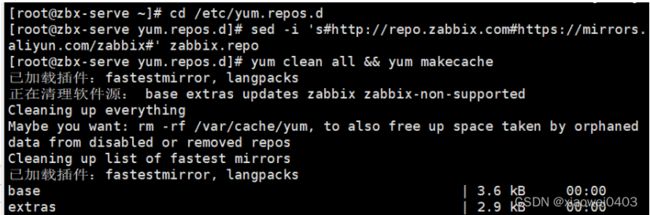
3、更换 zabbix.repo 为阿里源,安装zabbix-server-mysql、zabbix-agent和SCL
cd /etc/yum.repos.d
sed -i 's#http://repo.zabbix.com#https://mirrors.aliyun.com/zabbix#' zabbix.repo
yum clean all && yum makecache
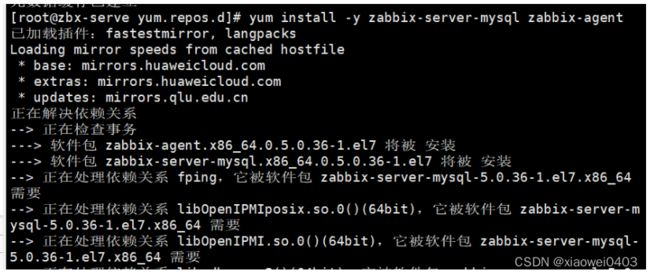
安装zabbix-server-mysql和zabbix-agent
yum install -y zabbix-server-mysql zabbix-agent
安装SCL(Software Collections),便于后续安装高版本php
yum install -y centos-release-scl

4.修改zabbix-front前端源,安装zabbix前端环境到scl环境下
修改/etc/yum.repos.d/zabbix.repo
vim /etc/yum.repos.d/zabbix.repo

yum install -y zabbix-web-mysql-scl zabbix-apache-conf-scl

5.安装zabbix所需要的数据库
yum install -y mariadb-server mariadb

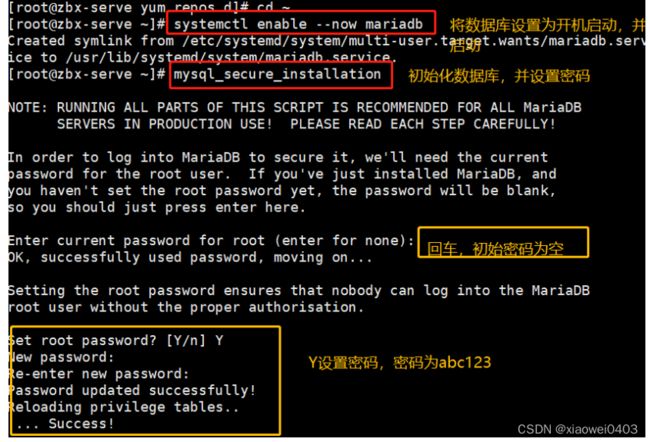

6.添加数据库用户,以及zabbix所需要数据库信息
mysql -u root -pabc123
create database zabbix character set utf8 collate utf8_bin;
grant all on zabbix.* to 'zabbix'@'%' identified by 'zabbix';
flush privileges;

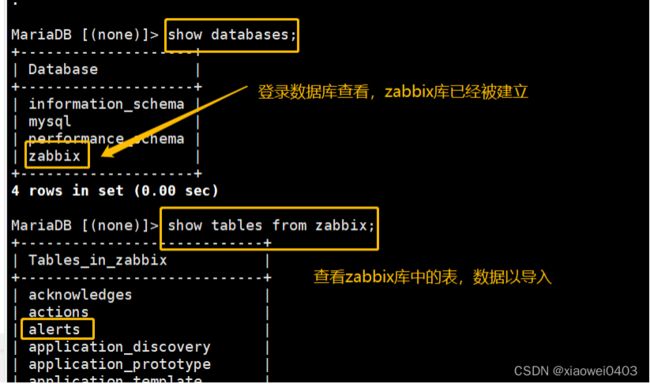
7.查询已安装的zabbix-server-mysql的文件列表,找到sql.gz文件位置
rpm -ql zabbix-server-mysql
zcat /usr/share/doc/zabbix-server-mysql-5.0.36/create.sql.gz | mysql -uroot -pabc123 zabbix

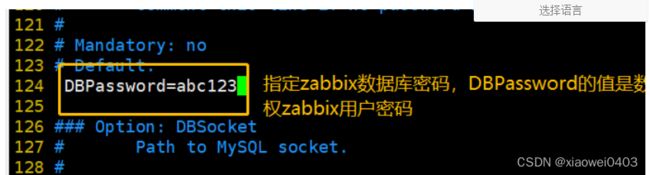
8、修改 zabbix-server 配置文件/etc/zabbix/zabbix_server.conf,修改数据库的密码。
vim /etc/zabbix/zabbix_server.conf
设置密码为zabbix
9.修改zabbix的php配置文件,/etc/opt/rh/rh-php72/php-fpm.d/zabbix.conf
vim /etc/opt/rh/rh-php72/php-fpm.d/zabbix.conf

10.启动zabbix相关服务
systemctl restart zabbix-server zabbix-agent httpd rh-php72-php-fpm
systemctl enable zabbix-server zabbix-agent httpd rh-php72-php-fpm
netstat -natp | grep zabbix

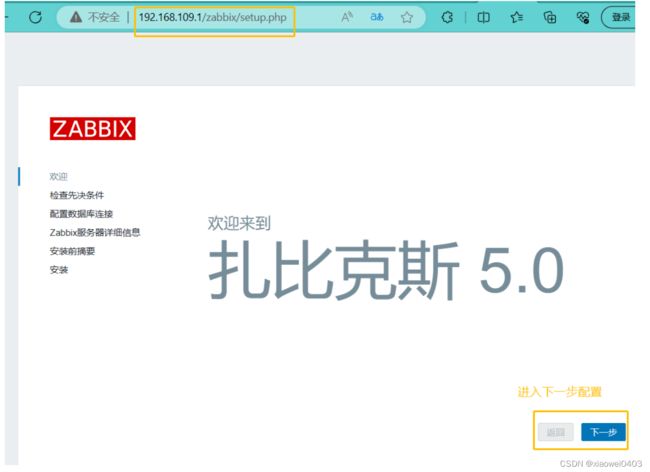
11.浏览器访问http://192.168.109.1/zabbix
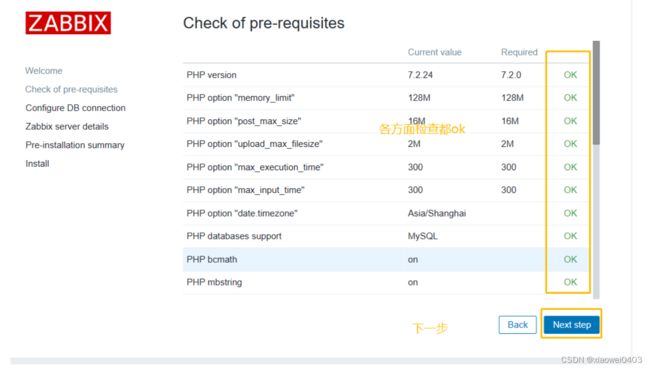
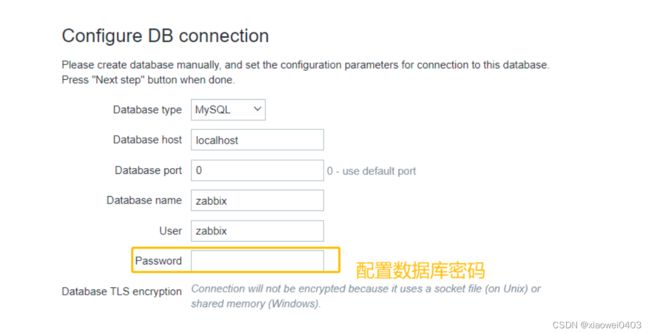


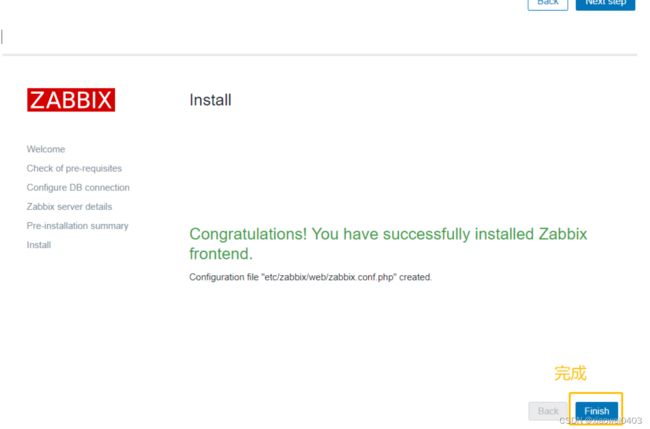
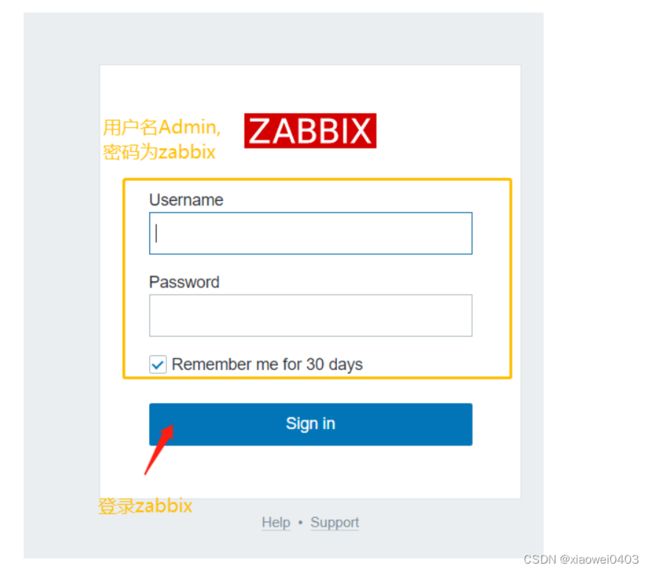


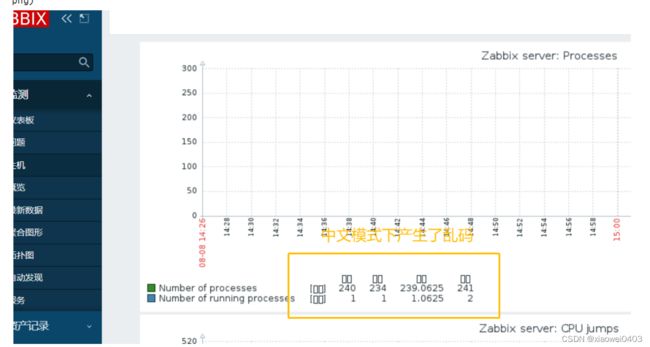
12、解决zabbix-server Web页面中乱码问题
yum install -y wqy-microhei-fonts
cp -f /usr/share/fonts/wqy-microhei/wqy-microhei.ttc /usr/share/fonts/dejavu/DejaVuSans.ttf


部署zabbix客户端(端口号10050)
zabbix 5.0版本采用golang 语言开发的新版本客户端agent2 。
zabbix 服务端 zabbix_server 默认使用 10051 端口,客户端 zabbix_agent2 默认使用 10050 端口
1.关闭防火墙、修改主机名
systemctl disable --now firewalld
setenforce 0
hostnamectl set-hostname zbx-agent01
bash

2.服务端和客户端都配置时间同步
yum install -y ntpdate
ntpdate -u ntp.aliyun.com

3.客户端配置时区,与服务器保持一致
mv /etc/localtime{,.bak}
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
date

4.设置zabbix的下载源,安装zabbix-agent2
rpm -ivh https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/zabbix-release-5.0-1.el7.noarch.rpm
sed -i 's#http://repo.zabbix.com#https://mirrors.aliyun.com/zabbix#' /etc/yum.repos.d/zabbix.repo

yum install -y zabbix-agent2

5.修改agent2配置文件,/etc/zabbix/zabbix_agent2.conf
vim /etc/zabbix/zabbix_agent2.conf

6.启动zabbix-agent2
systemctl start zabbix-agent2
systemctl enable zabbix-agent2
netstat -natp | grep zabbix

7.在服务端验证zabbix-agent2的连通性
yum install -y zabbix-get

zabbix_get -s '192.168.109.3' -p 10050 -k 'agent.ping'
zabbix_get -s '192.168.109.3' -p 10050 -k 'system.hostname'

2.3将客户端加入服务端的监控主机中

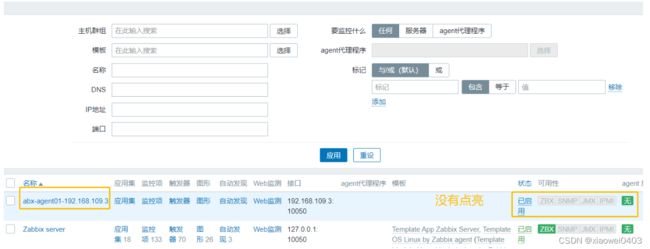
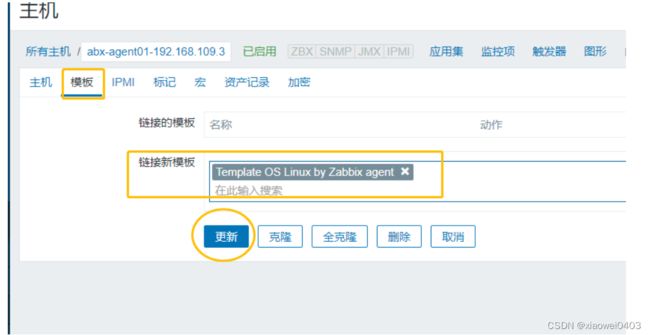



总结:
zookeeper 分布式服务框架,存储业务服务节点元数据信息,并且负责通知在zookeeper上注册的服务节点状态给客户端=文件系统+通知机制
1个leader n个follower 节点数量要是 >= 3的奇数台
第一次选举,通过比较myid,myid最大获取选票,当选票过半数确定leaderd的节点,之后再加入节点无论多大都作为follower加入到这个集群
非第一次选举 当我们源leader
出现故障时,其他节点选举新的leader,先比较epoch(任期),在比较事务id,服务器id,最大胜出
kafka
是一个消息队列(MQ),大数据实时处理 解耦 数据缓冲 流量削峰 异步处理
发布/订阅模式 主要是观察者模式 一对多 消费完之后不会清楚数据
的
部署kafka 首先需要部署 zookeeper集群,在zookeeper集群基础上再安装kafka应用(中间件),节点(服务器数量>=3奇数台)
生产者推送数据到kafka集群需要通过zookeeper确定kafka的位置,消费者消费的数据在哪里,也要根据存储在zookeeper上offset来确定偏移量记录上的一条消费的数据位置,以便在故障恢复的时候可以接着下一跳数据继续消费
几个kafka服务器几个broker,生成推送的数据到topic(主题)当中,topic可以被分区多个partition,一个partition可以有多个replication,replication可以是一个leader和多个follower,leader负责数据的读写,follower负责备份复制,消费者面向topic进行数据消费