Chapter 13: Network Programming | Python for Everybody 讲义笔记_En
文章目录
- Python for Everybody
-
- 课程简介
- Network Programming
-
- Networked programs
- Hypertext Transfer Protocol - HTTP
- The world’s simplest web browser
- Retrieving an image over HTTP
- Retrieving web pages with `urllib`
- Reading binary files using urllib
- Parsing HTML and scraping the web
- Parsing HTML using regular expressions
- Parsing HTML using BeautifulSoup
- Bonus section for Unix / Linux users
- Glossary
Python for Everybody
Exploring Data Using Python 3
Dr. Charles R. Severance
课程简介
Python for Everybody 零基础程序设计(Python 入门)
- This course aims to teach everyone the basics of programming computers using Python. 本课程旨在向所有人传授使用 Python 进行计算机编程的基础知识。
- We cover the basics of how one constructs a program from a series of simple instructions in Python. 我们介绍了如何通过 Python 中的一系列简单指令构建程序的基础知识。
- The course has no pre-requisites and avoids all but the simplest mathematics. Anyone with moderate computer experience should be able to master the materials in this course. 该课程没有任何先决条件,除了最简单的数学之外,避免了所有内容。任何具有中等计算机经验的人都应该能够掌握本课程中的材料。
- This course will cover Chapters 1-5 of the textbook “Python for Everybody”. Once a student completes this course, they will be ready to take more advanced programming courses. 本课程将涵盖《Python for Everyday》教科书的第 1-5 章。学生完成本课程后,他们将准备好学习更高级的编程课程。
- This course covers Python 3.

coursera
Python for Everybody 零基础程序设计(Python 入门)
Charles Russell Severance
Clinical Professor
个人主页
Twitter

University of Michigan
课程资源
coursera原版课程视频
coursera原版视频-中英文精校字幕-B站
Dr. Chuck官方翻录版视频-机器翻译字幕-B站
PY4E-课程配套练习
Dr. Chuck Online - 系列课程开源官网
Network Programming
We take a quick look at how data moves across the network using the HyperText Transport Protocol (HTTP) and how we write programs to read data across the network.
Networked programs
While many of the examples in this book have focused on reading files and looking for data in those files, there are many different sources of information when one considers the Internet.
In this chapter we will pretend to be a web browser and retrieve web pages using the Hypertext Transfer Protocol (HTTP). Then we will read through the web page data and parse it.
Hypertext Transfer Protocol - HTTP
The network protocol that powers the web is actually quite simple and there is built-in support in Python called socket which makes it very easy to make network connections and retrieve data over those sockets in a Python program.
A socket is much like a file, except that a single socket provides a two-way connection between two programs. You can both read from and write to the same socket. If you write something to a socket, it is sent to the application at the other end of the socket. If you read from the socket, you are given the data which the other application has sent.
But if you try to read a socket when the program on the other end of the socket has not sent any data, you just sit and wait. If the programs on both ends of the socket simply wait for some data without sending anything, they will wait for a very long time, so an important part of programs that communicate over the Internet is to have some sort of protocol.
A protocol is a set of precise rules that determine who is to go first, what they are to do, and then what the responses are to that message, and who sends next, and so on. In a sense the two applications at either end of the socket are doing a dance and making sure not to step on each other’s toes.
There are many documents that describe these network protocols. The Hypertext Transfer Protocol is described in the following document:
https://www.w3.org/Protocols/rfc2616/rfc2616.txt
This is a long and complex 176-page document with a lot of detail. If you find it interesting, feel free to read it all. But if you take a look around page 36 of RFC2616 you will find the syntax for the GET request. To request a document from a web server, we make a connection, e.g. to the www.pr4e.org server on port 80, and then send a line of the form
GET http://data.pr4e.org/romeo.txt HTTP/1.0
where the second parameter is the web page we are requesting, and then we also send a blank line. The web server will respond with some header information about the document and a blank line followed by the document content.
The world’s simplest web browser
Perhaps the easiest way to show how the HTTP protocol works is to write a very simple Python program that makes a connection to a web server and follows the rules of the HTTP protocol to request a document and display what the server sends back.
import socket
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect(('data.pr4e.org', 80))
cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\r\n\r\n'.encode()
mysock.send(cmd)
while True:
data = mysock.recv(512)
if len(data) < 1:
break
print(data.decode(),end='')
mysock.close()
# Code: http://www.py4e.com/code3/socket1.py
First the program makes a connection to port 80 on the server www.pr4e.com. Since our program is playing the role of the “web browser”, the HTTP protocol says we must send the GET command followed by a blank line. \r\n signifies an EOL (end of line), so \r\n\r\n signifies nothing between two EOL sequences. That is the equivalent of a blank line.
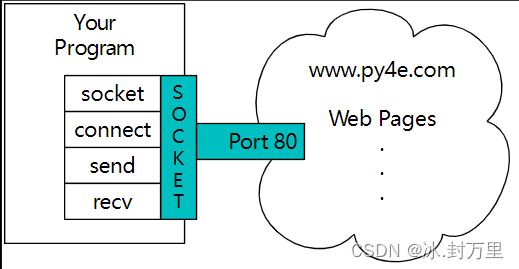
A Socket Connection
Once we send that blank line, we write a loop that receives data in 512-character chunks from the socket and prints the data out until there is no more data to read (i.e., the recv() returns an empty string).
The program produces the following output:
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 18:52:55 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Sat, 13 May 2017 11:22:22 GMT
ETag: "a7-54f6609245537"
Accept-Ranges: bytes
Content-Length: 167
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: text/plain
But soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with grief
The output starts with headers which the web server sends to describe the document. For example, the Content-Type header indicates that the document is a plain text document (text/plain).
After the server sends us the headers, it adds a blank line to indicate the end of the headers, and then sends the actual data of the file romeo.txt.
This example shows how to make a low-level network connection with sockets. Sockets can be used to communicate with a web server or with a mail server or many other kinds of servers. All that is needed is to find the document which describes the protocol and write the code to send and receive the data according to the protocol.
However, since the protocol that we use most commonly is the HTTP web protocol, Python has a special library specifically designed to support the HTTP protocol for the retrieval of documents and data over the web.
One of the requirements for using the HTTP protocol is the need to send and receive data as bytes objects, instead of strings. In the preceding example, the encode() and decode() methods convert strings into bytes objects and back again.
The next example uses b'' notation to specify that a variable should be stored as a bytes object. encode() and b'' are equivalent.
>>> b'Hello world'
b'Hello world'
>>> 'Hello world'.encode()
b'Hello world'
Retrieving an image over HTTP
In the above example, we retrieved a plain text file which had newlines in the file and we simply copied the data to the screen as the program ran. We can use a similar program to retrieve an image across using HTTP. Instead of copying the data to the screen as the program runs, we accumulate the data in a string, trim off the headers, and then save the image data to a file as follows:
import socket
import time
HOST = 'data.pr4e.org'
PORT = 80
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect((HOST, PORT))
mysock.sendall(b'GET http://data.pr4e.org/cover3.jpg HTTP/1.0\r\n\r\n')
count = 0
picture = b""
while True:
data = mysock.recv(5120)
if len(data) < 1: break
#time.sleep(0.25)
count = count + len(data)
print(len(data), count)
picture = picture + data
mysock.close()
# Look for the end of the header (2 CRLF)
pos = picture.find(b"\r\n\r\n")
print('Header length', pos)
print(picture[:pos].decode())
# Skip past the header and save the picture data
picture = picture[pos+4:]
fhand = open("stuff.jpg", "wb")
fhand.write(picture)
fhand.close()
# Code: http://www.py4e.com/code3/urljpeg.py
When the program runs, it produces the following output:
$ python urljpeg.py
5120 5120
5120 10240
4240 14480
5120 19600
...
5120 214000
3200 217200
5120 222320
5120 227440
3167 230607
Header length 393
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 18:54:09 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Mon, 15 May 2017 12:27:40 GMT
ETag: "38342-54f8f2e5b6277"
Accept-Ranges: bytes
Content-Length: 230210
Vary: Accept-Encoding
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: image/jpeg
You can see that for this url, the Content-Type header indicates that body of the document is an image (image/jpeg). Once the program completes, you can view the image data by opening the file stuff.jpg in an image viewer.
As the program runs, you can see that we don’t get 5120 characters each time we call the recv() method. We get as many characters as have been transferred across the network to us by the web server at the moment we call recv(). In this example, we either get as few as 3200 characters each time we request up to 5120 characters of data.
Your results may be different depending on your network speed. Also note that on the last call to recv() we get 3167 bytes, which is the end of the stream, and in the next call to recv() we get a zero-length string that tells us that the server has called close() on its end of the socket and there is no more data forthcoming.
We can slow down our successive recv() calls by uncommenting the call to time.sleep(). This way, we wait a quarter of a second after each call so that the server can “get ahead” of us and send more data to us before we call recv() again. With the delay, in place the program executes as follows:
$ python urljpeg.py
5120 5120
5120 10240
5120 15360
...
5120 225280
5120 230400
207 230607
Header length 393
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 21:42:08 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Mon, 15 May 2017 12:27:40 GMT
ETag: "38342-54f8f2e5b6277"
Accept-Ranges: bytes
Content-Length: 230210
Vary: Accept-Encoding
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: image/jpeg
Now other than the first and last calls to recv(), we now get 5120 characters each time we ask for new data.
There is a buffer between the server making send() requests and our application making recv() requests. When we run the program with the delay in place, at some point the server might fill up the buffer in the socket and be forced to pause until our program starts to empty the buffer. The pausing of either the sending application or the receiving application is called “flow control.”
Retrieving web pages with urllib
While we can manually send and receive data over HTTP using the socket library, there is a much simpler way to perform this common task in Python by using the urllib library.
Using urllib, you can treat a web page much like a file. You simply indicate which web page you would like to retrieve and urllib handles all of the HTTP protocol and header details.
The equivalent code to read the romeo.txt file from the web using urllib is as follows:
import urllib.request
fhand = urllib.request.urlopen('http://data.pr4e.org/romeo.txt')
for line in fhand:
print(line.decode().strip())
# Code: http://www.py4e.com/code3/urllib1.py
Once the web page has been opened with urllib.request.urlopen, we can treat it like a file and read through it using a for loop.
When the program runs, we only see the output of the contents of the file. The headers are still sent, but the urllib code consumes the headers and only returns the data to us.
But soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with grief
As an example, we can write a program to retrieve the data for romeo.txt and compute the frequency of each word in the file as follows:
import urllib.request, urllib.parse, urllib.error
fhand = urllib.request.urlopen('http://data.pr4e.org/romeo.txt')
counts = dict()
for line in fhand:
words = line.decode().split()
for word in words:
counts[word] = counts.get(word, 0) + 1
print(counts)
# Code: http://www.py4e.com/code3/urlwords.py
Again, once we have opened the web page, we can read it like a local file.
Reading binary files using urllib
Sometimes you want to retrieve a non-text (or binary) file such as an image or video file. The data in these files is generally not useful to print out, but you can easily make a copy of a URL to a local file on your hard disk using urllib.
The pattern is to open the URL and use read to download the entire contents of the document into a string variable (img) then write that information to a local file as follows:
import urllib.request, urllib.parse, urllib.error
img = urllib.request.urlopen('http://data.pr4e.org/cover3.jpg').read()
fhand = open('cover3.jpg', 'wb')
fhand.write(img)
fhand.close()
# Code: http://www.py4e.com/code3/curl1.py
This program reads all of the data in at once across the network and stores it in the variable img in the main memory of your computer, then opens the file cover.jpg and writes the data out to your disk. The wb argument for open() opens a binary file for writing only. This program will work if the size of the file is less than the size of the memory of your computer.
However if this is a large audio or video file, this program may crash or at least run extremely slowly when your computer runs out of memory. In order to avoid running out of memory, we retrieve the data in blocks (or buffers) and then write each block to your disk before retrieving the next block. This way the program can read any size file without using up all of the memory you have in your computer.
import urllib.request, urllib.parse, urllib.error
img = urllib.request.urlopen('http://data.pr4e.org/cover3.jpg')
fhand = open('cover3.jpg', 'wb')
size = 0
while True:
info = img.read(100000)
if len(info) < 1: break
size = size + len(info)
fhand.write(info)
print(size, 'characters copied.')
fhand.close()
# Code: http://www.py4e.com/code3/curl2.py
In this example, we read only 100,000 characters at a time and then write those characters to the cover3.jpg file before retrieving the next 100,000 characters of data from the web.
This program runs as follows:
python curl2.py
230210 characters copied.
Parsing HTML and scraping the web
One of the common uses of the urllib capability in Python is to scrape the web. Web scraping is when we write a program that pretends to be a web browser and retrieves pages, then examines the data in those pages looking for patterns.
As an example, a search engine such as Google will look at the source of one web page and extract the links to other pages and retrieve those pages, extracting links, and so on. Using this technique, Google spiders its way through nearly all of the pages on the web.
Google also uses the frequency of links from pages it finds to a particular page as one measure of how “important” a page is and how high the page should appear in its search results.
Parsing HTML using regular expressions
One simple way to parse HTML is to use regular expressions to repeatedly search for and extract substrings that match a particular pattern.
Here is a simple web page:
<h1>The First Page</h1>
<p>
If you like, you can switch to the
<a href="http://www.dr-chuck.com/page2.htm">
Second Page</a>.
</p>
We can construct a well-formed regular expression to match and extract the link values from the above text as follows:
href="http[s]?://.+?"
Our regular expression looks for strings that start with “href="http://” or “href="https://”, followed by one or more characters (.+?), followed by another double quote. The question mark behind the [s]? indicates to search for the string “http” followed by zero or one “s”.
The question mark added to the .+? indicates that the match is to be done in a “non-greedy” fashion instead of a “greedy” fashion. A non-greedy match tries to find the smallest possible matching string and a greedy match tries to find the largest possible matching string.
We add parentheses to our regular expression to indicate which part of our matched string we would like to extract, and produce the following program:
# Search for link values within URL input
import urllib.request, urllib.parse, urllib.error
import re
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urllib.request.urlopen(url, context=ctx).read()
links = re.findall(b'href="(http[s]?://.*?)"', html)
for link in links:
print(link.decode())
# Code: http://www.py4e.com/code3/urlregex.py
The ssl library allows this program to access web sites that strictly enforce HTTPS. The read method returns HTML source code as a bytes object instead of returning an HTTPResponse object. The findall regular expression method will give us a list of all of the strings that match our regular expression, returning only the link text between the double quotes.
When we run the program and input a URL, we get the following output:
Enter - https://docs.python.org
https://docs.python.org/3/index.html
https://www.python.org/
https://docs.python.org/3.8/
https://docs.python.org/3.7/
https://docs.python.org/3.5/
https://docs.python.org/2.7/
https://www.python.org/doc/versions/
https://www.python.org/dev/peps/
https://wiki.python.org/moin/BeginnersGuide
https://wiki.python.org/moin/PythonBooks
https://www.python.org/doc/av/
https://www.python.org/
https://www.python.org/psf/donations/
http://sphinx.pocoo.org/
Regular expressions work very nicely when your HTML is well formatted and predictable. But since there are a lot of “broken” HTML pages out there, a solution only using regular expressions might either miss some valid links or end up with bad data.
This can be solved by using a robust HTML parsing library.
Parsing HTML using BeautifulSoup
Even though HTML looks like XML1 and some pages are carefully constructed to be XML, most HTML is generally broken in ways that cause an XML parser to reject the entire page of HTML as improperly formed.
There are a number of Python libraries which can help you parse HTML and extract data from the pages. Each of the libraries has its strengths and weaknesses and you can pick one based on your needs.
As an example, we will simply parse some HTML input and extract links using the BeautifulSoup library. BeautifulSoup tolerates highly flawed HTML and still lets you easily extract the data you need. You can download and install the BeautifulSoup code from:
https://pypi.python.org/pypi/beautifulsoup4
Information on installing BeautifulSoup with the Python Package Index tool pip is available at:
https://packaging.python.org/tutorials/installing-packages/
We will use urllib to read the page and then use BeautifulSoup to extract the href attributes from the anchor (a) tags.
# To run this, download the BeautifulSoup zip file
# http://www.py4e.com/code3/bs4.zip
# and unzip it in the same directory as this file
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
# Retrieve all of the anchor tags
tags = soup('a')
for tag in tags:
print(tag.get('href', None))
# Code: http://www.py4e.com/code3/urllinks.py
The program prompts for a web address, then opens the web page, reads the data and passes the data to the BeautifulSoup parser, and then retrieves all of the anchor tags and prints out the href attribute for each tag.
When the program runs, it produces the following output:
Enter - https://docs.python.org
genindex.html
py-modindex.html
https://www.python.org/
#
whatsnew/3.6.html
whatsnew/index.html
tutorial/index.html
library/index.html
reference/index.html
using/index.html
howto/index.html
installing/index.html
distributing/index.html
extending/index.html
c-api/index.html
faq/index.html
py-modindex.html
genindex.html
glossary.html
search.html
contents.html
bugs.html
about.html
license.html
copyright.html
download.html
https://docs.python.org/3.8/
https://docs.python.org/3.7/
https://docs.python.org/3.5/
https://docs.python.org/2.7/
https://www.python.org/doc/versions/
https://www.python.org/dev/peps/
https://wiki.python.org/moin/BeginnersGuide
https://wiki.python.org/moin/PythonBooks
https://www.python.org/doc/av/
genindex.html
py-modindex.html
https://www.python.org/
#
copyright.html
https://www.python.org/psf/donations/
bugs.html
http://sphinx.pocoo.org/
This list is much longer because some HTML anchor tags are relative paths (e.g., tutorial/index.html) or in-page references (e.g., ‘#’) that do not include “http://” or “https://”, which was a requirement in our regular expression.
You can use also BeautifulSoup to pull out various parts of each tag:
# To run this, download the BeautifulSoup zip file
# http://www.py4e.com/code3/bs4.zip
# and unzip it in the same directory as this file
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, "html.parser")
# Retrieve all of the anchor tags
tags = soup('a')
for tag in tags:
# Look at the parts of a tag
print('TAG:', tag)
print('URL:', tag.get('href', None))
print('Contents:', tag.contents[0])
print('Attrs:', tag.attrs)
# Code: http://www.py4e.com/code3/urllink2.py
python urllink2.py
Enter - http://www.dr-chuck.com/page1.htm
TAG: <a href="http://www.dr-chuck.com/page2.htm">
Second Page</a>
URL: http://www.dr-chuck.com/page2.htm
Content: ['\nSecond Page']
Attrs: [('href', 'http://www.dr-chuck.com/page2.htm')]
html.parser is the HTML parser included in the standard Python 3 library. Information on other HTML parsers is available at:
http://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-a-parser
These examples only begin to show the power of BeautifulSoup when it comes to parsing HTML.
Bonus section for Unix / Linux users
If you have a Linux, Unix, or Macintosh computer, you probably have commands built in to your operating system that retrieves both plain text and binary files using the HTTP or File Transfer (FTP) protocols. One of these commands is curl:
$ curl -O http://www.py4e.com/cover.jpg
The command curl is short for “copy URL” and so the two examples listed earlier to retrieve binary files with urllib are cleverly named curl1.py and curl2.py on www.py4e.com/code3 as they implement similar functionality to the curl command. There is also a curl3.py sample program that does this task a little more effectively, in case you actually want to use this pattern in a program you are writing.
A second command that functions very similarly is wget:
$ wget http://www.py4e.com/cover.jpg
Both of these commands make retrieving webpages and remote files a simple task.
Glossary
BeautifulSoup
A Python library for parsing HTML documents and extracting data from HTML documents that compensates for most of the imperfections in the HTML that browsers generally ignore. You can download the BeautifulSoup code from www.crummy.com.
port
A number that generally indicates which application you are contacting when you make a socket connection to a server. As an example, web traffic usually uses port 80 while email traffic uses port 25.
scrape
When a program pretends to be a web browser and retrieves a web page, then looks at the web page content. Often programs are following the links in one page to find the next page so they can traverse a network of pages or a social network.
socket
A network connection between two applications where the applications can send and receive data in either direction.
spider
The act of a web search engine retrieving a page and then all the pages linked from a page and so on until they have nearly all of the pages on the Internet which they use to build their search index.
The XML format is described in the next chapter. ↩︎