K8S - Pod 的概念和简介
1. POD的基本概念
-
Pod 是K8s 系统中可以创建(部署)和管理的最小单元。
-
Pod 里面可以包含多个容器(多实例),是一组容器的集合。
也就是讲K8S 不会直接管理容器
-
1个POD中的容器共享网络命名空间(共享ip)
-
POD 是短暂的(可以被创建 迁移)
来自google的解析, POD的存在是为了覆盖container的细节
2. POD 存在的意义
- 创建容器使用docker, 1个docker 对应1个container, 一个container对应1个进程, 一个container运行1个程序, 是1个单进程的设计。
- Pod 是1个多进程的设计, 可以运行多个应用程序。 1 个POD可以有多个容器, 1个容器运行1个应用程序
- Pod 存在为了亲密性应用,
** 两个应用之间进行交互 (直接调用)
** 网络之间调用 (API), 如果不在同1个POD, 通常应用之间只能用ip调用, 如果在同1个POD, 可以用过127.0.0.1 和 socket直接调用
** 两个应用需要频繁调用(例如普通App 和 数据库)
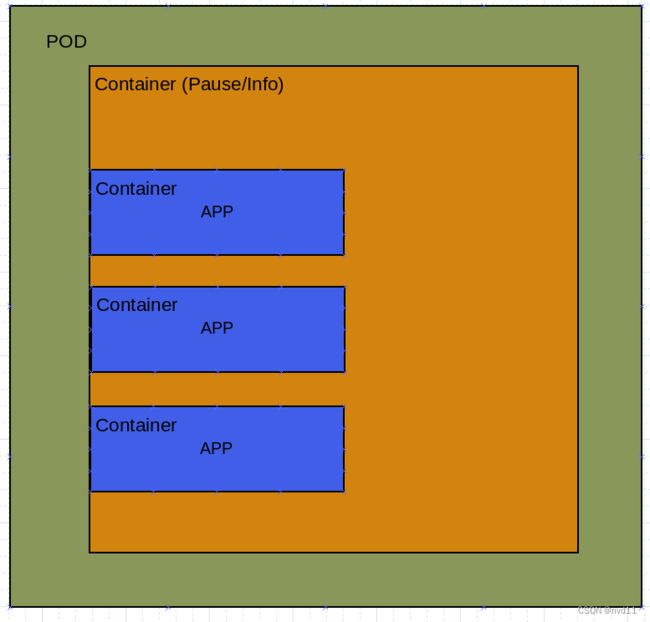
上图的Pause 表示POD里面必须存在的根容器
3 POD 的实现机制
通常POD的实现基于两种机制
分别是
- 共享网络
- 共享存储
3.1 共享网络机制
我们知道, 在docker中各个容器之间是相互隔离的。
在K8S 中, 容器也可以用namespace 和 group进行隔离。
但是如果两个容器在同1个POD 或namespace 中, 它们是可以做到网络共享的。(在同1个Namespace中是网络共享的大前提)
下面介绍的是在POD中网络共享机制的实现:
3.1.1 POD中多个容器的网络共享
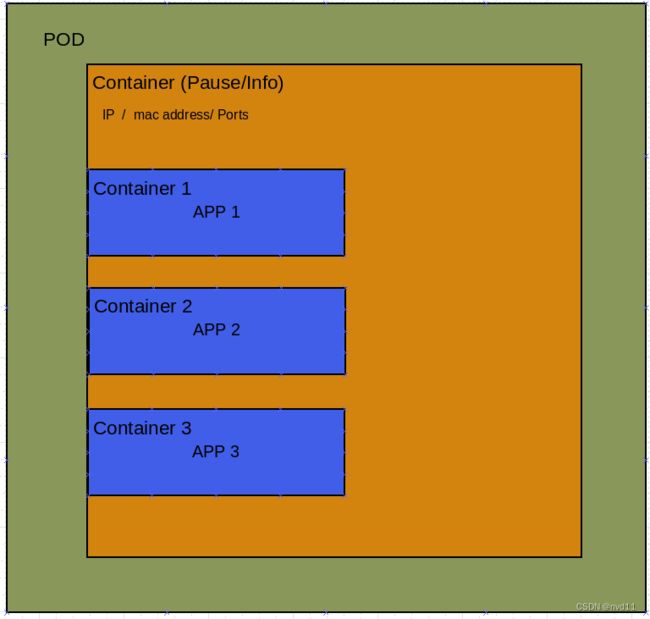
如下图, 在POD的初始化中, 会首先建立1个根容器, 这个根容器通常被称为 Pause, 也可以叫做info容器。
在这个根容器中, 会被分配1个ip地址, mac地址和 ports端口。
然后POD会继续根据用户要求创造若干个业务容器, 每个业务容器都会作为子容器加入到根容器中, 那么这些子容器就可以共享根容器的网络(ip mac port等)资源。
yaml 例子:
下面的yaml, 在同1个POD testPod1 中创建了两个容器, write-cont 和 read-cont, 至于根容器会被默认创建, 不用写在yaml中。
这两个容器都被加入到根容器的网络资源使用者列表中, 所以 这两个容器是可以共享网络的。
apiVersion: v1
kind: Pod
metadata:
name: testPod1
spec:
containers:
- name: write-cont
image: centos
command: ["bash", "-c", "for i in {1..100}; do echo $i >> /data/hello; sleep 1; done"]
volumeMounts:
- name: data
mountPath: /data
- name: read-cont
image: centos
command: ["bash","-c", "tail -f /data/hello"]
volumeMounts:
- name: data
mountPath: /data
volumns:
- name: data
emptyDir: {}
3.2 共享存储机制
Pod的容器在运行中 , 通常会不断产生数据, 为了持续使用, 必须对数据进行持久化。
-
共享存储: 跟docker机制类似, K8S 引入数据卷概念, 使用数据卷进行持久化存储
参考上面的yaml例子, 1个 write 容器会对1个公共的卷 data写数据, 而另1个容器 read可以从数据卷去读取数据。 因为他们都把数据卷挂在到容器中. -
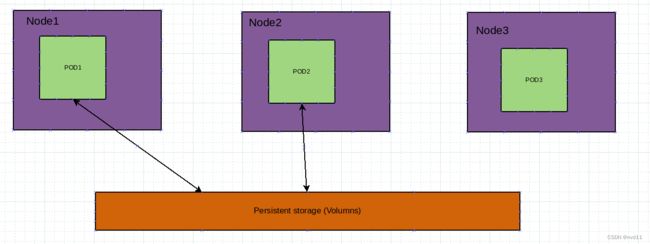
共享存储不只在POD的容器level, 实际上可以在Node之间, 让多个Node里面的POD 共享数据
4 POD 的镜像拉取
4.1 镜像拉取策略
我们看下面的yaml例子
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
container:
- name: nginx
image: nginx: 1.14
imagePullPolicy: Always # 镜像拉取策略
上面的 imagePullPolicy 就是 镜像拉取策略
有3个选项
- IfNotPresent: 默认值, 镜像在宿主机不存在才拉取
- Alway: 每次创建Pod时都会拉取
- Never: Pod 永不会主动拉取镜像
5 POD 的资源需求 和 资源限制
我们看1个例子
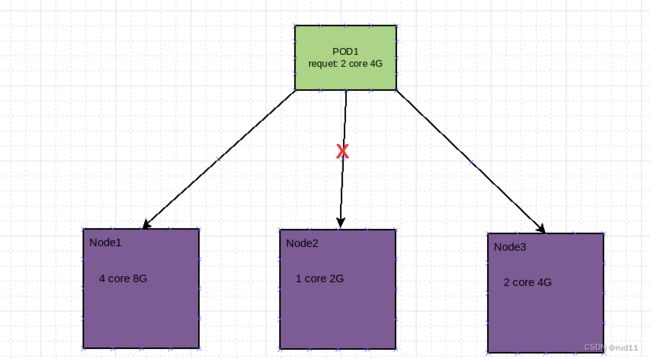
假如我们要构建运行1个POD1, 在k8s 集群中, 系统会把这个POD 分配到其中1个 k8s node上运行。
如果当前k8s 有如下面3个节点
其中node1 的规格是4 core 8G
node2 的规格是1 core 2G
node3 的规格是2 core 4G
而我们会觉得我们所建立的POD1正常运行至少需要2 core 4G, 如果被分配到POD2 运行则很有可能出问题
这时我们可以设置POD1 的最少资源需求 为 2 core 4G.
则k8s 就不会把这个POD 放到node2 去执行了。
至于把POD1 放到node3 可行吗?, 则要看node3有没有其他POD在运行, 空闲资源怎么样。
所以引申出另1个东西: 资源限制
当POD1 在node1运行时, 如果我们不想它占用过多的node资源, 则可以作出限制。
资源限制在yaml的关键字是
spec.containers[x].resources.requests.cpu # 最低需求cpu数 1 代表 1 core, 1000m 代表 1 core, 500m 和 0.5 都代表 0.5 core
spec.containers[x].resources.requests.memory # 最低需要内存 单位是Mi, 1 Mi = 1 MB
spec.containers[x].resources.limits.cpu # 最高能用到的cpu 数
spec.containers[x].resources.limits.memory # 能用到的最大内存限制
1个 yaml例子:
apiVersion: v1
kind: Pod
metadata:
name: Pod1
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources: # 资源需求
requests:
memory: "120Mi"
cpu: "500m"
limits: # 资源限制
memory: "500Mi"
cpu: "1000m"
6 POD 的重启机制
当POD里面的容器非正常退出, POD会对容器作一些处理,这就是POD对容器的重启机制
如下面的yaml例子:
apiVersion: v1
kind: Pod
metadata:
name: Pod1
spec:
containers:
- name: busybox
image: busybox:1.28.4
args:
- /bin/sh
- -c
- sleep 36000
restartPolicy: Never # 重启机制
restartPolicy 的选项有3种:
- Always: 当容器终止退出时, 总是会重启容器, 这个是默认策略
- OnFailture: 当容器异常退出 (退出码非0)时才会重启
- Never: 容器退出时不会重启, 多用于执行批量任务(批处理)
7 POD 的健康检查
如果我们想查看 POD的运行状态, 可以用下面的命令
gateman@k8smaster:~$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-scjht 1/1 Running 0 7d
但是这个Running status 并不能保证这个pod是健康的, 它并不能检查pod里面是否有oom or 程序已经崩溃的问题.
通常靠谱的方法是调用POD里面程序的health checking 接口
例如:
gateman@k8smaster:~$ curl -I 127.0.0.1:31407
HTTP/1.1 200 OK
Server: nginx/1.21.5
Date: Sun, 27 Nov 2022 11:59:18 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Dec 2021 15:28:38 GMT
Connection: keep-alive
ETag: "61cb2d26-267"
Accept-Ranges: bytes
但是K8S 允许我们在POD 的yaml文件中自定义 health checking 的规则
其中
1. livenessProbe (存活检查)
这个规则 如果health checking不通过, 则K8s 会kill掉 POD, 然后根据Pod 的restartPolily(上面的章节6) 的规则来操作
2. readnessProbe (就绪检查)
这个规则下, 如果health checking 不通过, K8s 会直接将这个pod 从service endpoint 中移除。
而上面两个Probe 支持一下三种检查方法:
1. httpGet
发送http 请求, 返回200 - 399 认为成功
2. exec
执行shell 命令,如果返回的退出码是0, 则认为成功
3. tcpSocket
发起TCP socket 连接, 如果连接建立, 则认为成功
例子:
apiVersion: 1
kind: Pod
metadata:
labels:
test: liveness
name: test-pod-liveness
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- c
- mkdir -p /tmp/healthy;
- sleep 30;
- rm -rf /tmp/healthy
livenessProbe:
exec:
command:
- ls /tmp/healthy
initialDelaySeconds: 5
perodSeconds: 5
上面的例子中, health checking的探针 在POD创建后5秒后就不断尝试隔5秒去检查 /tmp/healthy 文件夹, 当这个文件夹被删除后, 则会认为检查失败
8 POD 的调度策略
上面提到了, 我们用 kubectl get pods 命令可以查看pod的运行状态。
但是如果想知道pod 是在哪个node去运行的,必须加多1个参数
gateman@k8smaster:~$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-6799fc88d8-scjht 1/1 Running 0 7d7h 10.244.1.5 k8snode0 <none> <none>
gateman@k8smaster:~$
可以看出, nigix 这个pod 跑在 k8snode0上。
但是我们创建pod其实并不需要指定pod在哪个node上跑到的, 而是k8s会根据规则去自动分配。 这个规则就是所谓的POD 调度策略
8.1 POD 从建立到被分配(调度)到某个node的流程
8.1.1 用户发起POD create 指令 到API server处理
这一步在master node内完成, 毕竟api server是存在master node的
gateman@k8smaster:~$ docker ps | grep -i api
e2dc342dd4f8 bd16c7ea581a "kube-apiserver --ad…" 5 days ago Up 5 days k8s_kube-apiserver_kube-apiserver-k8smaster_kube-system_e12ac92bf1f55f7391d09a0523658312_2
906ba92f4bdf registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 5 days ago Up 5 days k8s_POD_kube-apiserver-k8smaster_kube-system_e12ac92bf1f55f7391d09a0523658312_2
当API server接收到用户create POD指令后, 会把对应的POD创建信息写入 ectd
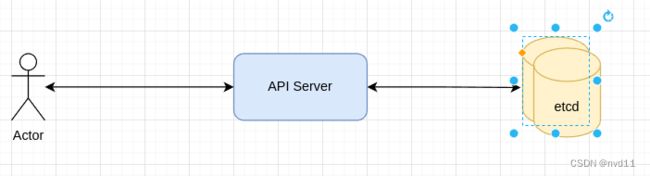
其实到第一步, 指令会马上返回给用户, 用户一般需要等待一会才去查询POD状态, 所以后面的动作是异步的
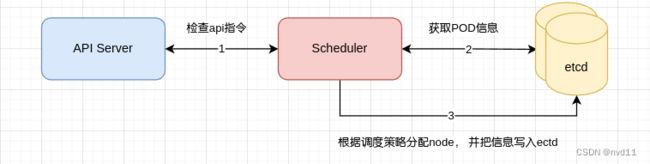
8.1.2 schedule 根据调度策略 分配 POD 到某个node
这一步也在master node内完成
所谓Schedlue 就是会定时与API server沟通, 一旦发现有新的pod create指令, 则会从ectd 获得pod信息, 然后根据调度策略去分配node, 然后将结果写入ectd
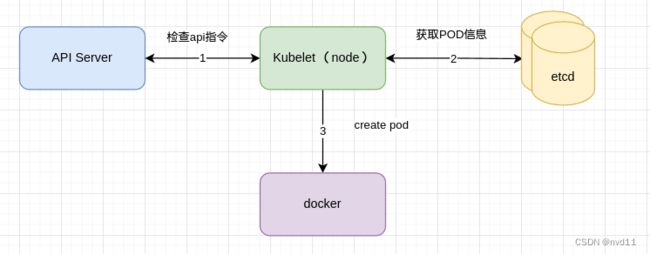
8.1.3 Node 的 kubelet 会根据pod信息在自己的docker容器内创建pod 的容器(s)
这一步当然在node内完成啦。
8.2 影响POD调度的一些因素
8.1 资源限制
这个很容易理解, 如本文的第5 章
resources: # 资源需求
requests:
memory: "120Mi"
cpu: "500m"
如果1个POD 需要120M 内存, 而某个node 剩余内存不足120M, 则这个node不会被选择
8.2 节点选择器标签
在Pod 的yaml 定义文件中, 我们还可以用标签选择器去选择被部署的node
例子:
apiVersion: v1
kind: Pod
metadata:
name: pod-env-test
spec:
nodeSeletor:
env_role: dev
contianers:
- name: ngnix
images: ngnix: 1.15
上面的nodeSelector 中的env_role 就是所谓的标签选择器, 看名字也知道这个选择器跟不同的运行环境有关
原理如图:
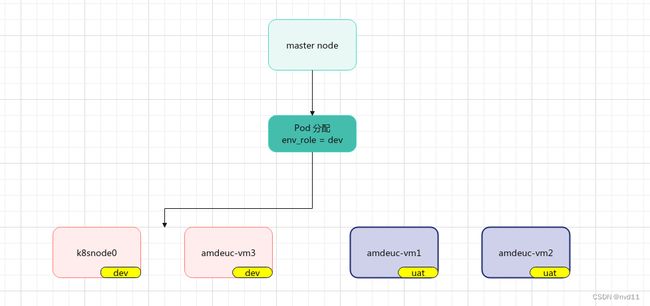
我们可以为每个node分别打上env_role 标签, 去定义这个node是输入 开发 or 测试 or 生产环境.
当我们的某个pod的yaml文件中制定了 标签, 则master 只会把这个pod 部署去对应的nodes, 这个优先级是最高的。
如何为某个node 打标签:
gateman@k8smaster:~$ kubectl label node k8snode0 env_role=dev
node/k8snode0 labeled
如何查看node的labels
gateman@k8smaster:~$ kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
admeuc-vm1 Ready <none> 7d22h v1.22.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=uat,kubernetes.io/arch=amd64,kubernetes.io/hostname=admeuc-vm1,kubernetes.io/os=linux
amdeuc-vm2 Ready <none> 55m v1.22.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=uat,kubernetes.io/arch=amd64,kubernetes.io/hostname=amdeuc-vm2,kubernetes.io/os=linux
amdeuc-vm3 Ready <none> 55m v1.22.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=dev,kubernetes.io/arch=amd64,kubernetes.io/hostname=amdeuc-vm3,kubernetes.io/os=linux
k8smaster Ready control-plane,master 43d v1.22.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8smaster,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
k8snode0 Ready <none> 43d v1.22.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=dev,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8snode0,kubernetes.io/os=linux
8.3 节点亲和性 nodeAffinity
用法基本上与8.2 标签选择器一样, 但功能更加强大
包括
8.3.1 硬亲和性,requireDuringSchedulingIgnoreDuringExecution
Node必须要满足亲和性的条件才会被选择, 如果没有任何node满足, 则POD的部署会一直等待
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-test
spec:
affinity:
requireDuringSchedulingIgnoreDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: env_role
operator: In
values:
- dev
- test
containers:
- name: ngnix:
image: ngnix: 1.15
8.3.2 软亲和性,preferredDuringSchedulingIgnoreDuringExecution
就是require和prefer的区别
Node调度会尝试满足亲和性的条件, 但不保证一定满足。
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-test
spec:
affinity:
preferredDuringSchedulingIgnoreDuringExecution:
- weight: 1 # 权重
preference:
- matchExpressions:
- key: env_role
operator: In
values:
- dev
- test
containers:
- name: ngnix:
image: ngnix: 1.15
Opertor - 常用的操作符
In
NotIn # 所谓的反亲和性
Exists
Gt
Lt
DoesNotExists # 所谓的反亲和性
8.4 污点和污点容忍 Taint
其实上面8.1 到 8.3 影响pod调度的属性都是在pod定义本身的。
但是污点 Taint是跟POD定义无关的, 它是Node的属性… 用于作一些特别分配处理
8.4.1 场景
a. 专用节点
例如某些node的有外网网络, 会部署一些专用应用
b. 配置特点硬件节点
例如某写node具有ssd硬盘, 会部署大量IO的应用
c. 基于Taint驱逐
用于排除某些node
8.4.2 查看node 的 污点信息
kubectl describe node xxxxx | grep -i taint
gateman@k8smaster:~$ kubectl describe node | grep -i taint
Taints: <none>
Taints: <none>
Taints: <none>
Taints: node-role.kubernetes.io/master:NoSchedule
Taints: <none>
只有master node 有1个污点, 表示 master node 有NoSchedule的污点
8.4.3 3个污点的值
** NoSchedule 表示一定不会被调度
** PreferNoSchedule 尽量不会被调度
** NoExecute: 不会被调度, 并且还会驱逐Node的已有pods 这个 吊
8.4.4 为Node打上污点
kubectl taint node [nodename] key=value #污点的3个值
例如:
Kubectl taint node k8snode0 env_role=dev:NoSchedule
这样就代表, 如果POd选择了dev env_role 标签, pod也不会调度到这个k8snode0上, 会选择另个存在 dev标签的节点。
8.4.4 为Node删除污点
kubectl taint node [nodename] key:[污点值] -
8.4.5 污点容忍
例子:
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
一旦在pod 配置文件中 写上上面的污点容忍信息
则代表即使打上对应污点的node也可能会被调度到…