Linux文件编辑常用命令
目录
一、grep命令——在文本中找出指定字符串
二、awk命令
awk基本格式
正则表达式模式(用斜线(//)包含起来)
关系表达式模式(通常用于匹配特定字段或变量的内容)
范围模式
特殊表达式模式
内置变量
三、Sed命令——非交互式编辑器
地址类型(元字符集)
命令(可以使用分隔符组合使用多个命令,按顺序执行)
替换标志
报错信息和退出信息
Sed使用实例
四、cut命令——数据截取
举例:
辨别空格和制表符
五、tr命令——字符转换:替换,删除
六、sort命令——排序
七、uniq命令——去除重复行
八、tee命令——双向输出
将文件复制多份
将错误信息也输出到文件
九、paste命令——合并文件
一、grep命令——在文本中找出指定字符串

排除文件内的空行:grep -v '^$' 文件名,同理,如果想排除注释行只需把‘$’换成‘#’即可。
二、awk命令
awk基本格式
awk [选项] ‘脚本命令’ 文件名
常用选项: -F:指定分隔符,默认以空格或tab为分隔符;
-f:从脚本文件中读取awk命令;
-v:赋值一个用户定义的变量,如-v shyn=shenyanan;
正则表达式模式(用斜线(//)包含起来)
1. 显示111文件中包含“0.1”的每条记录:
awk ‘/0.1/ {print $0} ’ 1112. 显示111文件中包含“0.1”的每条记录的第一和第二字段:
awk ‘/0.1/ {print $1,$2}’ 1113. 显示111文件中以数字开头的每条记录的第一列字段
awk ‘/^0-9/ {print $1}’ 111每条记录中的字段由$后跟字段号(以1开头)引用:整个记录可以用$0引用;第一个字段用$1表示;第二个字段用$2表示;依此类推,最后一个字段也可以用特殊变量$NF引用。
关系表达式模式(通常用于匹配特定字段或变量的内容)
常用的关系运算符有: ~:包含 !~:不包含
>:大于 <:小于
>=:大于等于 <=:小于等于
==:等于 !=:不等于
1. 显示111文件中第二字段中包含“aa”字符的每条记录(反之可以使用!~
awk ‘$2 ~ /aa/ {print $0}’ 1112. 显示111文件中第4字段“大于等于30”的记录
awk ‘$4 >= 30 {print $0}’ 111范围模式
范围模式由逗号分隔的两组字符组成,从与第一个字符串匹配的记录开始,直到与第二个字符串的记录匹配为止的所有记录。
1. 显示111文件从“bin”到“test”在内的记录
awk ‘/bin/,/test/ {print $}’ 1112. 显示111文件第四字段等于31到第四字段等于34内的记录
awk ‘$4 == 31 , $4 == 34 {print $0}’ 111特殊表达式模式

内置变量

三、Sed命令——非交互式编辑器
linux命令总结sed命令详解 - 琴酒网络 - 博客园 (cnblogs.com) https://www.cnblogs.com/ginvip/p/6376049.html
https://www.cnblogs.com/ginvip/p/6376049.html
sed 选项 ‘地址类型与命令/查找字符串/替换字符串/标志’ 文件或目录
选项:-e:该选项会将其后跟的脚本命令添加到已有的命令中。
-f:该选项会将其后文件中的脚本命令添加到已有的命令中。
-i:直接修改文件内容不,在屏幕上输出,可以指定后缀名生成备份文件,如-i.bak。
-n:安静模式,屏蔽默认输出(全部文本),只有经过sed特殊处理的那一行才会被列出来。
地址类型(元字符集)
如果没有指定地址,sed会处理输入的所有的行。
first~step:first 指起始匹配行, step 指步长,例如: sed -n 2~5p 含义:从第二行开始匹配,隔 5 行匹配一次,即 2,7,12.......。 
命令(可以使用分隔符组合使用多个命令,按顺序执行)
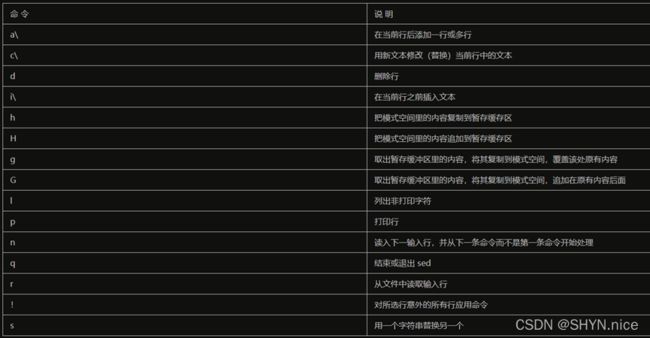
替换标志
sed -i “s/旧数据/新数据/g” 文件或目录
g:进行全局替换,而不是仅替换第一次出现的位置
p:打印行
w:指定输出文件名,将替换后的结果写到文件。
x:互换模板块中的文本和缓冲区中的文本
y:把一个字符翻译为另外的字符(但是不用于正则表达式)

报错信息和退出信息
遇到语法错误时, sed 会向标准错误输出发送一条相当简单的报错信息。但是,如果 sed判断不出错在何处,它会“断章取义”,给出令人迷惑的报错信息。如果没有语法错误, sed将会返回给 shell 一个退出状态,状态为 0 代表成功,为非 0 整数代表失败。
Sed使用实例
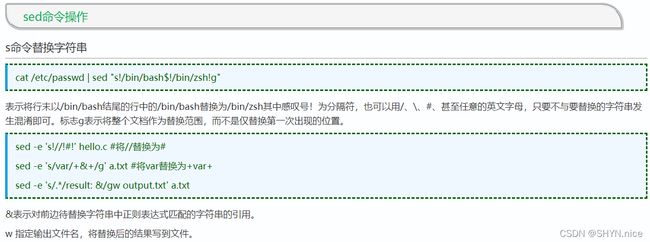

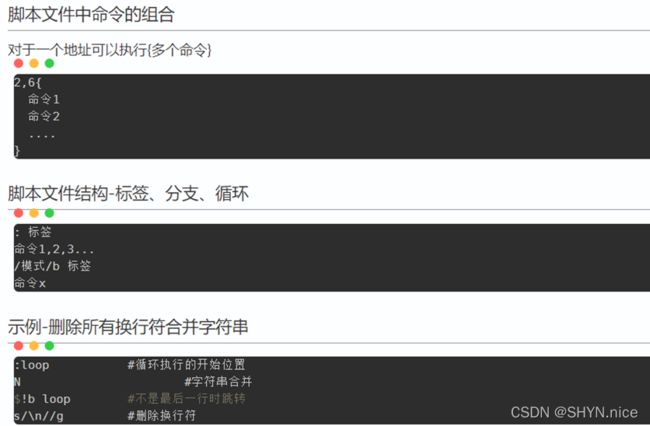
四、cut命令——数据截取
cut命令用于显示行中指定部分,以每一行为一个处理对象。
-b:以字节为单位进行分隔,并且支持“3-5”这样的写法,多个定位数字之间可以以逗号分隔。“-b -3”表示从开头到第三个字节;“-b 3-”表示从第三字节到结尾。
-c:以字符为单位进行分隔。
-d:自定义分隔符,默认为制表符(Tab)
-f:指定显示区域,与-d一起使用。如“cut -d : -f 1”以冒号为分隔符提取第一列内容。它也支持多个定位数字。
-n:取消分隔多字节字符。仅和-b选项一起使用。三个字节组成一个汉字,-n选项用于告诉cut命令不要将多个字节符拆开,而是合并在一起显示。
举例:
[root@TL-16-39-84 tmp]# cat 1.txt
李老头 123
张老头 321
邓老头 231
[root@TL-16-39-84 tmp]# cut -b 3 1.txt
[root@TL-16-39-84 tmp]# cut -c 3 1.txt //-c会以字符为单位来提取内容,而-b只会傻傻的以字节(8位二进制位)来计算
头
头
头
[root@TL-16-39-84 tmp]# cut -nb 3 1.txt
头
头
头
[root@TL-16-39-84 tmp]# cut -bn 3 1.txt
cut: invalid byte, character or field list
Try 'cut --help' for more information.
[root@TL-16-39-84 tmp]# cut -d ' ' -f 1 1.txt //-d指定分隔符为空格,-f指定显示域
李老头
张老头
邓老头
辨别空格和制表符
当要检索的文件内容较多,较难分辨是制表符(Tab)还是空格时,可以使用此方法辨别:
#下面文件内容中有较长空白,空白处是Tab还是空格单看是看不出来的。
[root@TL-16-39-84 tmp]# cat 2.txt
The harder
The more fortunate !
#使用sed命令,如果是tab会显示为\t符号,若是空格则保持不变。
[root@TL-16-39-84 tmp]# sed -n l 2.txt //-n后面为字母L的小写
The harder$
The more \tfortunate\t!$cut只允许指定一个间隔符,不能设置多个空格,所以不善于处理“多空格”情况。也可以使用tr命令“tr -s ' '”去重连续空格后,再使用cut命令过滤。
五、tr命令——字符转换:替换,删除
tr可以看做是sed的简化变体,可以用来替换字符,删除字符,也可以用它来去重。
tr [选项] ... [第一字符集] [第二字符集]
-d:删除字符集1中的所有输入字符。
-s:删除所有重复出现字符序列,只保留第一个;即重复出现的字符串压缩为一个字符串。
六、sort命令——排序
sort命令用于将文本文件内容加以排序,个针对文件内容,以行尾单位来排序。
-u:去除重复行。
-r:按降序排列,默认为升序排列。
-o:将排序后的内容输入到指定文件,类似于重定向>。
-n:以数字排列,默认是按字符串排序。
-t:指定分隔符。
-k:指定查看第几列。
七、uniq命令——去除重复行
uniq命令用于检查及删除文本文件中重复出现的行列,一般与sort命令结合使用。
-c:去重并在输出行前面加上每行重复出现的次数。
-i:忽略大小写。
-d:只显示重复行。
-u:只显示不重复的行。
八、tee命令——双向输出
tee工具从标准输入读取并写入标准输出和文件,即:双向覆盖重定向<屏幕输出|文本输出>。可以重复展示输入内容;可将文件同时复制多份。
-a:追歼重定向,而非覆盖。
将文件复制多份
#将文件复制多份
[root@TL-16-39-84 tmp]# cat 1.txt |tee 3.txt 4.txt
李老头 123
张老头 321
邓老头 231
[root@TL-16-39-84 tmp]# ll
total 45700
-rw-r----- 1 root root 42 Dec 3 14:36 1.txt
-rw-r----- 1 root root 42 Dec 3 16:11 3.txt
-rw-r----- 1 root root 42 Dec 3 16:11 4.txt
将错误信息也输出到文件
tee命令默认只把标准输入的普通信息输出到文件,错误信息丢弃,通过如下方式可以将错误信息也同步输入到文件。
[root@TL-16-39-84 tmp]# ls 111 |tee 3.txt
ls: cannot access 111: No such file or directory
[root@TL-16-39-84 tmp]# cat 3.txt
[root@TL-16-39-84 tmp]#
[root@TL-16-39-84 tmp]# ls 111
ls: cannot access 111: No such file or directory
[root@TL-16-39-84 tmp]# ls 111 2>&1 |tee 3.txt
ls: cannot access 111: No such file or directory
[root@TL-16-39-84 tmp]# cat 3.txt
ls: cannot access 111: No such file or directory九、paste命令——合并文件
paste命令会把多个文件以列对列的方式输出到屏幕,不会改动源文件。
paste [选项] 文件一 文件二 ....
-d:指定分隔符,默认以Tab分隔,只支持一个字符;若指定字符串只调用第一个字符。
-s:将每个文件中的所有内容按照一行输出,行与行以Tab分隔。
[root@TL-16-39-84 tmp]# cat 1.txt
111
2222
3[root@TL-16-39-84 tmp]# cat 2.txt
111
2222
3[root@TL-16-39-84 tmp]# paste 1.txt 2.txt
111 111
2222 2222
3 3
[root@TL-16-39-84 tmp]# paste -d : 1.txt 2.txt
111:111
2222:2222
3:3
[root@TL-16-39-84 tmp]# paste -d all 1.txt 2.txt
111a111
2222a2222
3a3