Java 生产初学常用注解
目录
- 0. 基础语法
-
- 逻辑运算符
- 继承
- 抛出异常 throw
- 获取数据方式
- 泛型
- 1. 接收前端数据(controller)
- mybatis
-
- 1. QueryWrapper
- 获取和赋值
- 2. service 层
-
- 注解
- 3. Dao 层(与数据库交互)
-
- 3.1 mybatis-plus中BaseMapper
- 4. ELK框架
-
- es配置sql参数
- logstash
-
- 数据读取
-
- csv数据读取
- 导入数据库数据
- 查询日志
- idea的debug调试按钮使用
0. 基础语法
class:用于定义一个类。
public:用于声明公共的访问级别,表示对所有类可见。
private:用于声明私有的访问级别,表示只有在同一类中可见。
static:用于声明静态成员,可以在没有创建对象的情况下访问。使得非静态类更适合用于表示具有多个实例的对象,例如用户、订单等。
void:用于表示方法没有返回值。
final:用于声明最终的变量,表示不能再修改其值。
if/else:用于条件语句,根据条件执行不同的代码块。
for/while/do-while:用于循环语句,重复执行一段代码块。
try/catch/finally:用于异常处理,捕获并处理异常。
new:用于创建对象实例。
this:访问当前对象或类中的成员变量和方法,例如访问this.name、this.age等成员变量,或者调用this.method()等方法。
逻辑运算符
&& 且 || 或
! 的优先级别高(先执行!后执行&& ||)
继承
public class 子类 extends 父类{}
抛出异常 throw
这里不行这里报错,不终止全部程序。
throw: 指的是在方法之中人为抛出一个异常类对象,这个对象可以是自己实例化,或者是已经存在的。
throws: 指的是在方法的声明上使用,表示此方法在调用时必须处理异常。
try 和 catch 是用于处理异常的语句,它们构成了一种异常处理机制。在一个 try 语句中,程序执行一段代码,如果发生了异常,则会被捕获,并转到相应的 catch 语句中进行处理。
方法后边加上throws Exception的作用是抛出异常。其中Exception可以理解为所有异常,也可以抛出指定异常。如果方法后边不加throws Exception,方法出了异常就会向上传递抛出(如果方法有调用者,那就交给调用者处理,如果调用者继续一层层抛出,最终交给虚拟机,虚拟机处理,整个程序会中断! 如果在程序中捕获 还可以继续进行)
获取数据方式
get:从里面拿
post:往里面放
put:
delete:删除
post 不需要传入
新增 insert,修改update,
泛型
List指的是集合.<>是泛型,里面指定了这个集合中存放的是什么数据.
1、集合可以有List,vector等,其实map也是一个集合
2、这些集合有啥用呢,就好比你有一堆数据要存:
[name=‘张三’ , age=20, address=‘北京’]
[name=‘李四’ , age=15, address=‘湖南’]
[name=‘王五’ , age=18, address=‘甘肃’]等等,
这样一条一条的数据你就能够用集合来保存起来,放到一条集合中去
3、例如用list来保存,保存形式就如下:
list = {[name=‘张三’ , age=20, address=‘北京’], [name=‘李四’ , age=15, address=‘湖南’] , [name=‘王五’ , age=18, address=‘甘肃’]};
这样的形式了,然后取值的时候你就可以根据list.get(i)来分别取值了。
4、如果要取到每一条里面的属性,那么可以配合map或者存储的是实体类对象,来分别取值就对了,非常的简单且实用
List list = new ArrayList();
…
list.get(0).getName();
1. 接收前端数据(controller)
@GetMapping是Spring4.3提供的新注解,它是一个组合注解,等价于@RequestMapping(method = RequestMethod.Get ),用于简化开发,注意:@RequestMapping如果没有指定请求方式,将接收Get、Post、Head、Options等所有的请求方式.同理还有@PostMapping、@PutMapping、@DeleteMapping、@PatchMapping等
@Autowired注入(相当于python中的import库,多了一步操作)
RestController的作用相当于Controller加ResponseBody共同作用的结果,但采用RestController请求方式一般会采用Restful风格的形式。
Controller的作用:声明该类是Controller层的Bean,将该类声明进入Spring容器中进行管理
collection 包括 List(列表),Set(集合),Queue(队列)
collection coll
copyProperties(a,b)是把a复制给b
mybatis
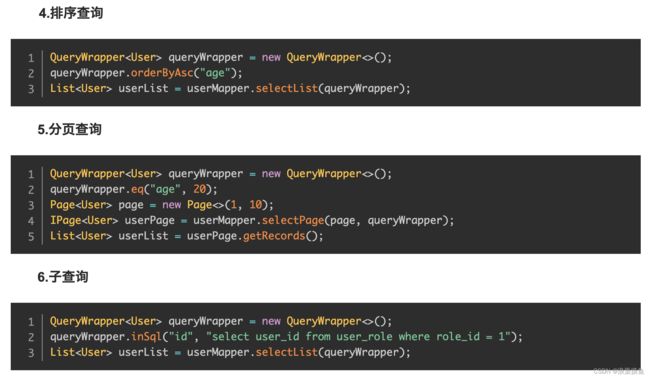
1. QueryWrapper
Mybatis-plus 提供的动态条件查询(条件构造器)
常见用法:
用来查询id等

获取和赋值
get 参数名 获取
set 参数名 赋值
2. service 层
注解
-
重写
@Override 告诉你说下面这个方法是从父类/接口 继承过来的,需要你重写一次,是伪代码,表示重写(当然不写也可以),不过写上有如下好处:
1>可以当注释用,方便阅读
2>编译器可以给你验证@Override下面的方法名是否是你父类中所有的,如果没有则报错 -
服务类
@ service 定义成服务类之后才能用import 加载进来。 -
工厂方法
工厂方法模式是一种设计模式,它的作用是将对象的创建和使用分离开来,从而使得程序更加灵活、可维护。在工厂方法模式中,我们通常会定义一个抽象的工厂类,该类中包含一个静态的方法,用于根据输入参数创建相应的对象。
3. Dao 层(与数据库交互)
定义新用数据的方法在这写
3.1 mybatis-plus中BaseMapper
集成增删改查的功能
4. ELK框架
参考文章
Elasticsearch:开源分布式搜索引擎,提供收集、分析、存储数据三大功能
- 特点:分布式、零配置、自动发现、索引自动分片、索引副本机制、restful风格接口、多数据源、自动搜索负载
Logstash:用来做日志的收集、分析、过滤日志的工具,支持大量的数据获取方式。
- 工作方式:c/s架构,client端安装在需要收集日志的主机上,server端负责将收集到的各个节点的日志进行过滤、修改等操作,再一并发往elasticsearch上去。
es配置sql参数
ES指令
cmd命令初始化:npm install
cmd命令启动:npm run dev
logstash
数据读取
csv数据读取
input {
file {
#要读取的数据文件的路径
path => "D:/elk/logstash-7.6.1/config/TSI_DOC_TITLE_CONTENT_VIEW.csv"
start_position => "beginning"
}
}
filter {
csv {
#分隔符
separator => ","
#数据对应的字段名,顺序要和字段值一致
columns => ["TID","TNAME","TPARENT","DID","CONTENT"]
}
mutate{
#忽略某些字段
remove_field => ["@version","message","host","path","@timestamp"]
#类型
convert => {
"TID" => "string"
"TENAME" => "string"
"TPARENT" => "string"
"DID" => "string"
"CONTENT" => "string"
}
}
}
output {
elasticsearch {
#要写入的es地址
hosts => "http://localhost:9200"
#索引
index => "title"
#类型,6.X版本后的固定用这个
document_type => "_doc"
#定义文档id用表数据的主键,会方便核对数据
document_id =>"%{TID}"
}
stdout {}
}
cmd进入bin目录执行:logstash -f data.conf
导入数据库数据
input {
jdbc {
jdbc_driver_library => "d:/elk/logstash-7.6.1/lib/ojdbc6-11.2.0.2.0.jar"
jdbc_driver_class => "Java::oracle.jdbc.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@192.168.212.22:7210:chestnut"
jdbc_user => "chestnut"
jdbc_password => "chestnut1111"
schedule => "* * * * *"
statement_filepath => "d:/elk/logstash-7.6.1/sql/gettitlecontent.sql"
jdbc_page_size => "100000"
use_column_value => "true"
tracking_column => "tid"
codec => plain { charset => "UTF-8"}
jdbc_paging_enabled => true
}
}
filter {
mutate{
#忽略某些字段
remove_field => ["@version","message","host","path","@timestamp"]
}
}
output {
elasticsearch {
#要写入的es地址
hosts => "http://localhost:9200"
#索引
index => "title"
#类型,6.X版本后的固定用这个
document_type => "_doc"
#定义文档id用表数据的主键,会方便核对数据
document_id => "%{tid}"
}
stdout {}
}
cd到bin目录运行:logstash -f getoracle.conf
查询日志
idea 后端可以在开始的地方,通过git插入代码
vscode 前端通过 git 指令拉代码 git clone https://github.com/Eugene-Hung/Test.git,直到显示succeed。
前端通过ES的指令启动,只有把代码作为开头才能npm install 不能作为一个模块打开
!! 可以通过前端的network来看后端端口
通过传参看各个变量的定义
idea的debug调试按钮使用
