【MySQL】总结中
什么是MySQL
MySQL是一个数据库软件,是一个"客户端-服务器"结构的软件。
客户端(Client):主动发起请求的一方。客户端给服务器发起的数据,称为请求(Request)
服务器(Server):被动接收请求的一方。服务器给客户端返回的·数据,称为响应(Response)
客户端和服务器通过网络进行通信的。
MySQL的服务器,使真正的本体,负责保存和管理数据,数据都是存储在硬盘上的。因为硬盘相对于内存而言,空间大,成本低,且数据持久保存。缺点是速度慢。
安装mysql
登录mysql
进入命令行窗口。若设置了环境变量。
直接输入登录语句 : mysql -uroot -p

接下来输入密码

若出现这样的错误,大概率是密码输入有问题,重新检查输入。
说明已经连接成功了。
一.对数据库的操作
--1.1创建数据库
create database MyDatabase;
--1.2判断数据库是否已经存在,若存在则不创建,不存在创建,语句更为严谨,可避免sql报错
create database if not exists MyDatabase;
--1.3创建数据库并手动指定字符集uft8 目的为了数据库可存储中文 uft8一个汉字3个字节,是变长编码
--一个汉字占几个字节是与 编码方式 有关的
create database MyDatabase charset utf8;
--2.查看所有创建的数据库
show databases;
--3.查看指定数据库的定义信息
show create database MyDatabase;
--4删除数据库 删除的是数据库及数据库中所有的的表和表里的所有数据
drop database MyDatabase; --危险操作
--5使用,选中指定的数据库 当操作基本表时,首先要写这个语句
use MyDatebase;二.对基本表的操作
常用的数据类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| bit[(M)] | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用Boolean对应bit,默认是1位,只能存0和1 |
| int | 4字节 | Integer | |
| long | 8字节 | Long | |
| double() | 8字节 | Double | |
| decimal(a,b) ,黑精准常用 | a/b最大值+2 | 精确数值常用,精度不会丢失 a指定长度,b指定小数位数 |
BigDecimal |
| varchar(size) | 0-65,535字节 | 可变长度字符串 | String |
| text | 0-65,535字节 | 长文本数据 | String |
| datetime | 8字节 | 范围从1000到9999年,不会进行时区的检索及转换 | java.util.Date java.sql.Timestamp |
| timestamp | 4字节 | 范围从1970到2038年,自动检索当前时区并进行转换(时间戳) | java.util.Date java.sql.Timestamp |
datetime的使用
insert into student values (1,'张三','2001-02-25 11:21:10'); 精确到秒
获取当前时间 now()函数
insert into student values (1,'张三','now()');
--创建表
create table 表名(列名 类型,列名 类型.....) ;
--查看当前数据库中的所有表
show tables;
--查看指定的表结构
desc 表名; --(describe 描述)
--删除基本表 表及表中的所有数据都会被删除
drop table 表名; --危险操作
--1.创建基本表例子
create table Student(
sno char(10) not null primary key, --[primary key] 为设置主键
name varchar(20) not null, -- [not null] 为属性列的值不能为空
sex int,
gender varchar(1), --or gender char(2)
--check(gender = '男' or gender = '女'),但是mysql会忽略掉这个关键词,不能用
--[check] 起限制,约束作用,例如性别男和女,分数0到100分
birthday datetime,
score decimal(3,1)) 小数点精确,用这个
--2.查看表的结构
desc 表名;
desc Student; --例子
--3.修改表名
alter table 表名 rename to 新的表名;
alter table Student rename to S; --例子
--4.添加一列
alter table 表名 add 列名 数据的类型; --(注意,此处所添加的列属性是默认可以为空值的null)
alter table Student add address varchar(50); --例子 添加住址
--5.添加多列
alter table 表名 add 列名 数据的类型,
列名 数据的类型,
列名 数据的类型;
--6.删除一列
alter table 表名 drop 列名;
alter table Student drop Dpet; --例子
--7.删除多列
alter table 表名 drop 列名,
列名,
列名,
列名;
----8.删除表
drop table 表名;
drop table Student; --例子
--9.判断表是否已经存在,若存在才删除,语句更为严谨,防止报错
drop table if exists 表名;
drop table if exists Student; --例子CRUD 增删改查
insert into Student() values();
delete from 表名 where 列名 = 值;
update 表名 set 列名 = 值 where 列名 = 值;
select * from Student where...;
insert into Student() values();
delete from 表名 where 列名 = 值;
update 表名 set 列名 = 值 where 列名 = 值;
select * from Student where...;1.添加 insert into
--例子
insert into Student(SNO,Name,Sex) values('2020041235','张璇',20), ('2020041236','田慧',21),('2020041237','田琪',20);
--1.规范书写
insert into 表名(列名1,列名2,...) values(值1,值2,,...);
--2.省略列名时,默认所有列都添加,下面两个句子表达意思相同
insert into 表名 values(值1,值2,,...,值n);--省略列名
insert into 表名(列名1,列名2,...,列名n) values(值1,值2,,...,值n);--此为写全了所有列名
--3.插入部分数据时
insert into 表名(列名2,列名3,,列明5) values(值2,值3,值5);
--4.插入多行数据时 两种写法 注意标点符号 明显第二种较为简单
insert into 表名()values();values();values();
insert into 表名()values(),(),(),();2. 删除 delete
--1.规范书写
--delete 作用仅是删除表中的数据,对表体,列属性名无任何影响
delete from 表名 where 列名 = 值;
delete from Student where SNO = '2020041599'; --删除一行或多行数据
--2.删除表中所有数据 只是删除了表里的所有记录 这里表体仍存在,是空表,表仍能查询到
delete from 表名 ; --如果不是想删除所有数据,切记加where,不然表中数据全删除完了,小编就吃过亏,慎用
--3.先删除表,再创建一张一样的表
truncate table 表名;
3.修改 update
--规范书写
update 表名 set 列名 = 值 where 列名 = 值;
--代码中第一个【列名 = 值】 为想要修改的所在列的值
--代码中第二个【列名 = 值】 的列名为具有标识的作用如主键,其值唯一。非主键也行,看具体修改的目的
--例子
update Student set Major = '软件工程' where SNO = '2020041158';
--即更改学号为2020041158的学生的专业名称。4.查询 select
--查询表中所有数据 (行列无限制,全部输出)
select * from 表名; --少用,不建议使用 若数据量太大,会卡死,数据库服务器会挂的
select * from Student; --例子
--查询表中某几列数据(行全部输出)
select 列名1,列名3 from 表名;
select SNO,Name,Major from Student; --例子
--查询特定列名的几行数据 (列全部输出)
select * from 表名 where 列名 = 值;
select * from Student where SNO = '2020041599';
--即查询学号为2020041599的学生的全部信息
--查询特定列名的几行数据 (行列都有限制)
select 列名2,列名4 from 表名 where 列名 = 值;5.查询字段为表达式
select chinese-10 from Student; --将每个同学的语文成绩都减去10
select chinese+math+english as total from Student; --计算每个同学的各科成绩总和
6.排序查询 order by
order by 用于排序,默认是按照升序排序。
注意: 如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
order by 列名 desc --[desc] 表示降序
order by 列名 asc --[asc] 表示升序
order by 列名1 asc 列名2 desc;
--查找所有学生的全部信息,按年龄降序排列
select * from S order by Age desc;7.条件查询 where
在第4视频
where可以使用表达式,但不能使用别名,因为与执行语句顺有关, where 先于 select
select chinese+math+english as total from Student where total > 300; --错误
不过上面解释算是理由,但也不完全对。
实现sql引擎的时候,是完全可以做到,把这里的别名,预先的定义好,然后再执行1,2,3,保证执行到where的时候,也可以访问到别名。不过sql没这样做。
select 条件查询的顺序:
1.先遍历表中的每个记录 from
2.把当前记录的值带入条件进行筛选。where
3.如果这个记录条件成立,就要进行保留,再进行列上的表达式的计算 select
4.如果还有 order by 会在所有语句都执行完后再进行排序
8.in 离散的,不连续的集合
-- 查询年龄40岁,35岁,44岁的信息
SELECT * FROM Student WHERE age = 40 OR age = 35 OR age = 44
SELECT * FROM Student WHERE age IN (40,35,44);--与上面等价
9.分页查询 limit
limit可以限制一次查询最多能查询出来多少个结果。
select * from Student limit 3 offset 3; offset偏移量 即“下标” 从0开始
s
select * from Student limit M offset N; M表示这次查询最多查询多少条记录,N表示查询的这N个记录是从第几个下标开始算。
| 运算符 | 说明 |
| > ,>=, <, <= | |
| = | 等于,null不安全,例如 null = null 得结果是 null 即这个不能查询空值 |
| <=> | 等于,null安全, 例如 null = null 的结果是 true 这个可以查询空值并展示 |
| !=,<> | 不等于 现在用 != |
| between a and b | 范围匹配左右都闭区间 |
| in() | 离散的,不连续的集合 |
| is null | |
| is not null | |
| like | 模糊匹配 |
null与任何数相运算,结果都为null。
MySQL不支持正则表达式
面临的数据量大(大数据),客户端的请求比较大(高并发),一台服务器搞不定就需要多台机器(分布式)
MySQL中的约束
- not null 指示某列不能存储null值
- unique 唯一键,保证的某列的整行必须有唯一的值,一个表中可以有多个唯一键唯一键。
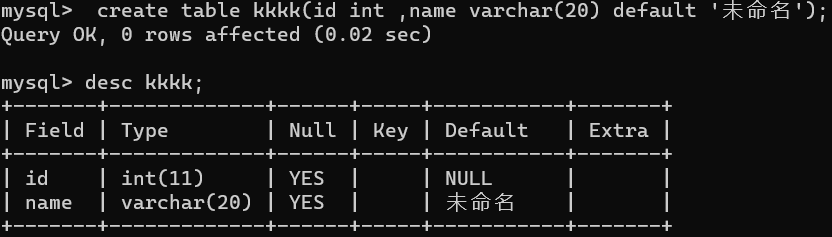
- default 规定没有给列赋值时的默认值 默认的默认值是 null 空
- primary key 主键,not 和 unique 的结合,一个表中只能有一个主键,一个主键可以由一个或多个列构成(但多个列的用的很少(联合主键)),被修饰的列具有唯一性
- foreign key 外键,能被外键修饰的列 ,前提是此列必须是另一个表中的主键或唯一键。一个表中可以有多个外键。
- check 对于MySQL5 忽略check子句
unique 一个表中可以有多个唯一键,可以为空null。
![]()
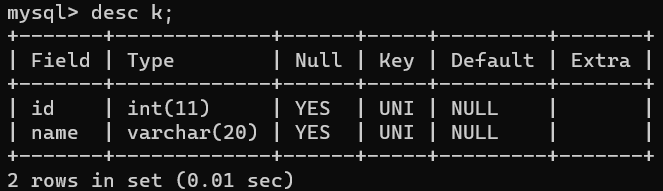
default 设置默认值
对主键或约束为 not null 的列不能用。

主要体现在插入值的时候
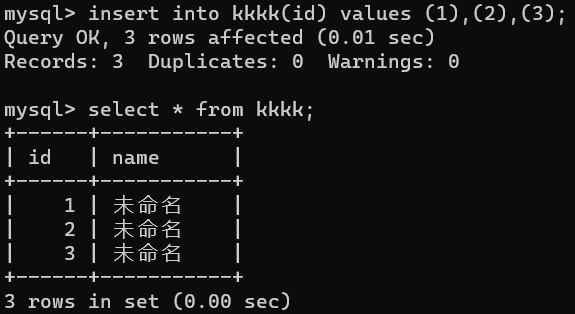
主键 一个表中只能有一个,不能为null。也可由多个列组合成一个联合主键,注意写法。

错误写法
![]()
联合主键 写法
![]()
外键 能被外键修饰的列 ,前提是此列必须是另一个表中的主键或唯一键。一个表中可以有多个外键。


一个表中多个外键的写法

自增主键:为了保证主键的唯一性。方式 插入的时候,主键位置写 null 。也可以自己手动设置,接下来自增的话会根据最新加入的大小为起始自增。
create table Student(id int primery key auto_increment); -- 创建
insert into Student(id) values(null); -- 插入
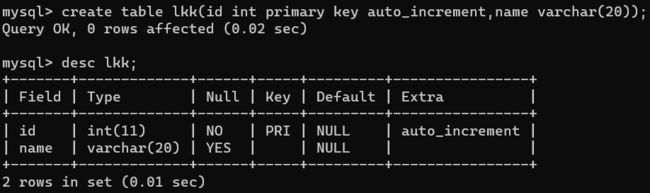
自动自增,主键位置填null。不加单引号。
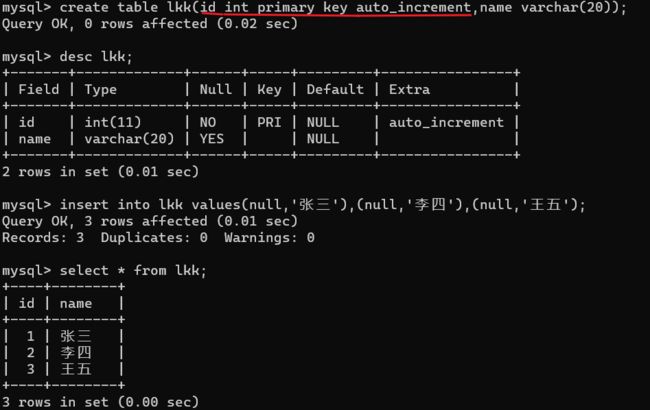
先手动增,在自动增,会发现自动增的那个数会根据当前在表中最大的数加1
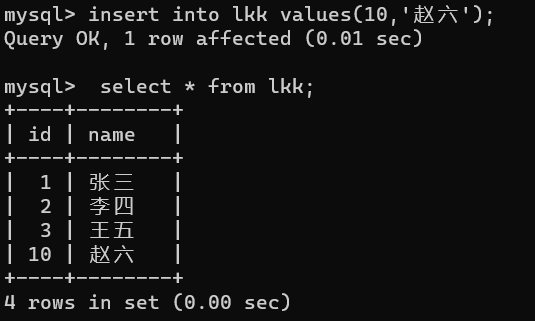
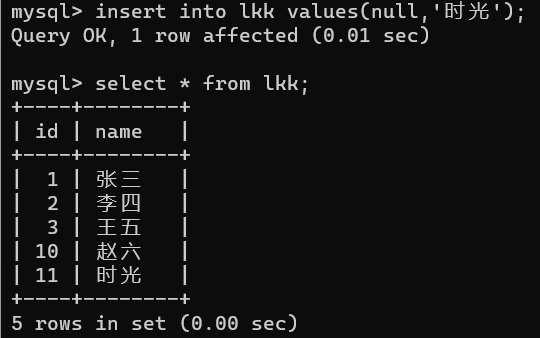
这时候,我想,我要是再先手动添加一个id为4的列,再让自增,结果是什么?
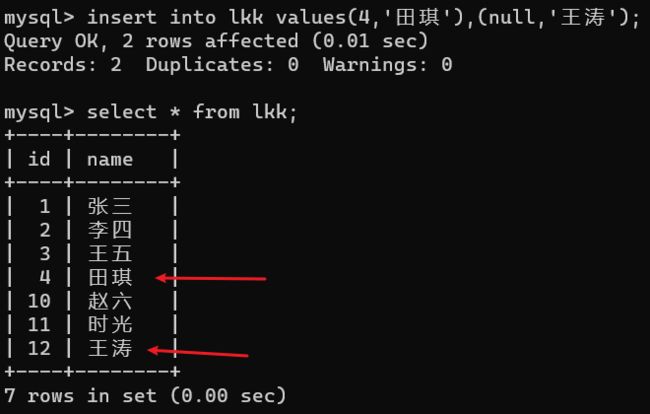
会发现不仅自增是根据当前表中自增主键最大的值+1,而且还会自动排序。
分布式系统生成唯一ID
公式:分布式唯一ID = 时间戳 + 机房编号/主机编号 + 随机因子
(+是指字符串拼接,而不是算术运算,拼出来是一个较长的字符串,随机因子有一定的概率生成相同的因子但是概率比较小,ms不行弄微秒,主机的编号设置的更细些,就可以保证ID唯一)
如果添加商品的速度比较慢,直接使用时间戳就够了。但是如果一个时间戳内,添加了多个商品。
添加的多个商品,是要落到不同主机上的,分布式系统生成唯一ID,就可以保证同一时间内,添加到不同主机上的商品编号。
外键 保证一个表中的数据匹配另一个表中的数据
外键的表就像子类,主键的表就像父类,外键的列中不能出现对应主键或唯一键中没有的值(包括删除和修改值),而主键或唯一键则不能删除或修改自身也在外键中出现的值,主键和主键所在的表都受到删除约束,不能删除。相互制约吧。
删除顺序:先删子表,再删父表。
create table A(id_A int primary key,name varchar(10));
create table B(id_B int,cno varchar(10),score decimal(3,1), foreign key(id_B) references A(id_A));
场景:如何表示一个商品还有没有货或商品的上下架。
给商品表新增一个单独的列,表示是否在线(不在线就相当于下架了)。
例如 商品表(id,name,price,.....,isOk)isOk这一列,若值为1,表示商品在线。值为0,表示商品下线。(逻辑删除)
表的设计
实体 每一个实体都是一个表
关系 表与表之间的关系,联系 如一对一(一个班只有一个班主任),一对多(一个班有多个学生),多对多(一个学生可以选多门课,一门课可以被多个学生选,此时就需要在创建一个新的关联表,新表中存放两个表的主键),没关系。
查询的进阶
查询搭配 插入 使用
insert into student1 select * from student2;
聚合函数 行和行之间的运算
将一列数据作为一个整体进行计算,通常和分组查询函数group by组合使用。
1.count() 计算列数
2.max() 计算列最大值
3.min() 计算列最小值
4.sum() 对列进行求和
5.avg() 对列计算平均数6.count(*) 查询当前共有多少行,null也计算
查看当前共有多少行 select count(*) from student;
分组查询
分组查询的时候,可以搭配条件,需要区分清楚,该条件是分组之前的条件,还是分组之后的条件。
(1)查询每个岗位(role)的平均工资。(分组之前)
select role,avg(salary) from goods group by role;
(2)查询每个岗位的平均薪资,但是排除平均薪资超过2W的结果。(分组之后)
select role,avg(salary) from goods group by role having avg(salary) > 2000;
(3)查询每个岗位的平均薪资,不算张三,并排除平均薪资超过2W的结果。
select role,avg(salary) from goods where name != '张三' group by role having avg(salary) > 2000;
联合查询/多表查询
笛卡尔积
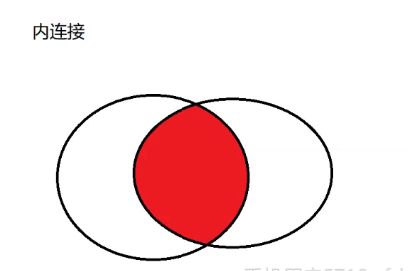
内连接 inner
两个表中共有的数据
select * from student inner join score on student.id = score.id;
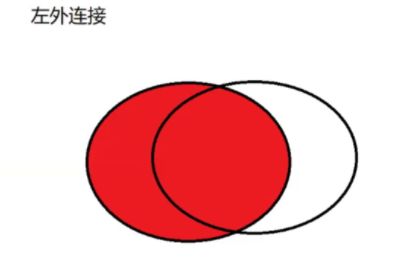
左外连接 left join
就是以左侧表为基准,保证左侧表的每个数据都会出现在最终结果里,如果在右侧表中不存在,对应的列就填为null。
select * from student left join score on student.id = score.id;
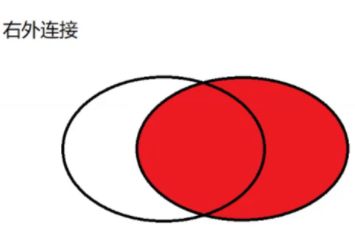
右外连接 right join
就是以右侧表为基准,保证右侧表的每个数据都会出现在最终结果里,如果在左侧表中不存在,对应的列就填为null。
select * from student right join score on student.id = score.id;
自连接
一张表自己和自己进行笛卡尔积连接。
注意写法,必须要先有别名
select score as s1 , score as s2 from student where s1.score = s2.score;
子查询
in 通常用这个
exists(节省内存空间,仅此而已)
普通子查询
相关子查询
合并查询 union
把多个表的查询结果合并在一起,前提是合并的多个表的列的个数和类型必须要一致,列名不做要求。
select * from student1 union select * from student2; -- 自动去重
select * from student1 union all select * from student2; -- 不会去重+all
MySQL索引和事务(面试中的重点)
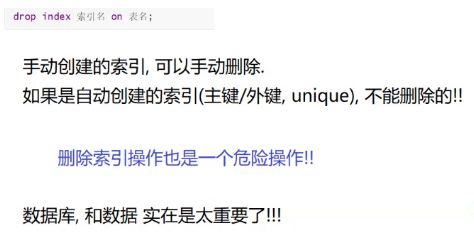
索引(index) 就像书的目录一样。属于针对 查询操作 的优化手段。一个表可以有多个索引。主键,唯一键unique,外键都是自动生成索引的,并且不能删除他们的索引。手动创建的索引,可以手动删除。
首先:

其次:

索引的操作:

show index from student;
create index idx_student_name on student(name); -- 注意写法 主键,唯一键unique,外键都是自动生成索引的,所以不用手动
drop index idx_student_name on student; -- 注意写法 主键,唯一键unique,外键的索引不能删除