jdk1.7与jdk1.8的HashMap区别2-底层原理区别
jdk1.7与jdk1.8的HashMap区别1-基本结构与属性对比_ycsdn10的博客-CSDN博客
一、代码区别
1.代码数:JDK1.7与JDK1.8相差了一倍的代码
2.方法数:JDK1.7是40个,JDK1.8是51个(只算基本方法)
二、Hash差别
1.JDK1.7
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}进行了4次位运算,5次亦或运算
2.JDK1.8
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}进行了1次位运算,1次亦或运算
三、数据存储机制差别
由上一章知道,JDK1.7是数组+链表,JDK1.8是数组+链表+红黑树
1.JDK1.7存储机制
(1)数组特点
根据下标定位,一般情况下查询、修改快于链表。
(2)链表特点
连接元素通过指针,新增和删除只需变更指针连接即可,所以一般情况下增删快,查询因需要遍历链表,所以查询效率一般慢于数组。
(3)解决Hash冲突
采用链地址法来存储发生Hash冲突的元素。
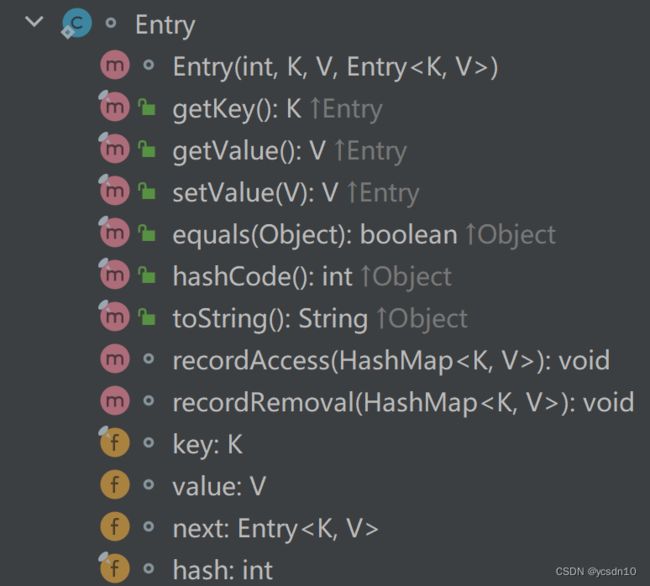
(4)节点
i.节点属性
static class Entry implements Map.Entry {
// 对应的key值
final K key;
// 对应value值
V value;
// 指针,指向下一个entry
Entry next;
// hash值
final int hash;
} ii.具体代码结构
iii.完整数据结构
1)假设以下链表当中的hash通过计算是同一个hash,那么为以下结构

2)数组和链表两部分

(5) 初始化
public HashMap() {}
public HashMap(int initialCapacity) {}
public HashMap(int initialCapacity, float loadFactor) {}
public HashMap(Map m) {}以上为4个初始化的几个方式。
i.HashMap()
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}负载因子为:默认DEFAULT_LOAD_FACTOR,为0.75f
扩容阈值为:默认初始化容量*负载因子=16*0.75 = 12
数组table:初始化为Entry[16]的数组
ii.HashMap(int initialCapacity)
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}从上面看出,容量参数进来之后,调用的是this,也就是iii的方法
iii.HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}1)当容量小于0时,直接抛出异常
2)当容量大于最大容量时候,容量赋值为最大容量2的30次
3)如果负载因子是小于等于0或者不是Float,那么就抛出异常
4)设置容量变化初始为1,如果初始值大于实际容量,那么变化值左移一位,即实际容量值=实际容量值*2,之后在比较,循环 4)步骤,直到初始化容量小于或者等于实际容量(这边可以看到,实际容量只能是2的倍数)
5)扩容阈值 = 实际容量*负载因子(因为实际容量是2的倍数,如果负载因子是默认值,那么扩容阈值=2的倍数*0.75,最小值为1.5)
6)数组容量为刚才计算得到的实际容量
iv.HashMap(Map m)
public HashMap(Map m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
putAllForCreate(m);
}
private void putAllForCreate(Map m) {
for (Map.Entry e : m.entrySet())
putForCreate(e.getKey(), e.getValue());
}
private void putForCreate(K key, V value) {
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
/**
* Look for preexisting entry for key. This will never happen for
* clone or deserialize. It will only happen for construction if the
* input Map is a sorted map whose ordering is inconsistent w/ equals.
*/
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
createEntry(hash, key, value, i);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
} 1)调用iii的方法进行初始化,容量=(int)(传进来的map的大小/默认负载因子(0.75)+1)和默认初始容量(16)取大的值;负载因子为默认负载因子
2)循环处理所有键值对
2.1)如果key为null,取0,否则进行取hash后(进行了4运算)的值,次位运算,5次亦或
2.2)进行hash值与长度-1进行与运算,得到Entry数组的下标,因为实际容量只能是2的倍数,所以在这个条件下,满足以下
h % length == h&(length-1)也就是取模运算, 但是因为与运算效率高,而%length是要转换成10进制,所以用h&(length-1)
2.3)for循环处理 在entry数组中查找hash码相同并且key相同的位置,放入当前的传入的value,并且结束此次设置值处理
2.4)2.3没有找对相同的hash与key的位置,会进行一个插入,会新建一个Entry对象,next指向原来的头节点,也就是头插法;头插法的好处就是效率更快(createEntry官方的注释是:与addEntry类似,只是在创建条目时使用此版本,作为Map构造或“伪构造”(克隆,反序列化)。这个版本不必担心调整表的大小。子类覆盖它以改变HashMap(Map)的clone和readObject行为。)
关于头插法是这样的,新的节点放置在hash相同的链表的头部
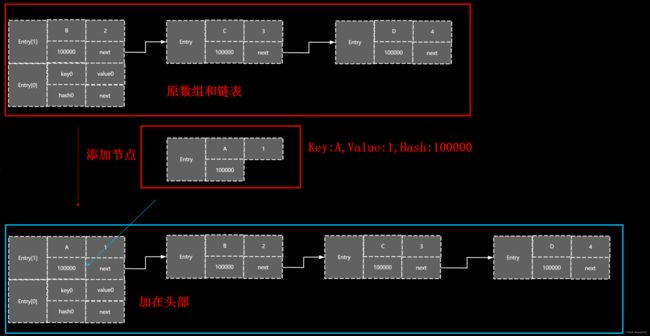
(6)添加元素
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
} 6.1)key为null的时候,数组下标为0的Entry,对应的值为传进来的Value,因为是null,所以hash为0,直接添加到数组下标为0的时候的链表头结点当中。并结束
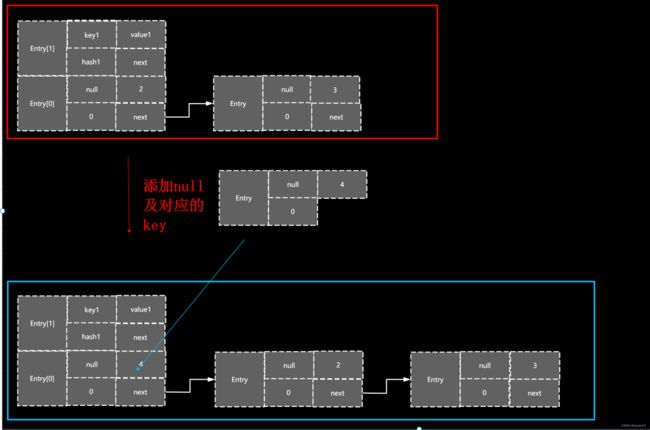
6.2)进行取hash后的值,4次位运算,5次亦或进行hash值与长度-1进行与运算,得到Entry数组的下标,因为实际容量只能是2的倍数,所以在这个条件下,满足以下
h % length == h&(length-1)也就是取模运算, 但是因为与运算效率高,而%length是要转换成10进制,所以用h&(length-1).(跟初始化的时候类似)
6.3)for循环处理 在entry数组中查找hash码相同并且key相同的位置,放入当前的传入的value,并且结束此次设置值处理
6.4)6.3没有找对相同的hash与key的位置,会进行一个插入,会新建一个Entry对象,next指向原来的头节点,也就是头插法;头插法的好处就是效率更快(跟初始化类似)
(7)移除元素
public V remove(Object key) {
Entry e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry prev = table[i];
Entry e = prev;
while (e != null) {
Entry next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
} 7.1)根据传入的Key,进行Hash处理,null则为0,不为null则计算hash
7.2)通过hash与数组长度,计算数组下标
7.3)获取对应下标的数组的Entry
7.4)如果Entry当前为Null,代表这个key在对应的数组并没有对应的value,所以直接返回
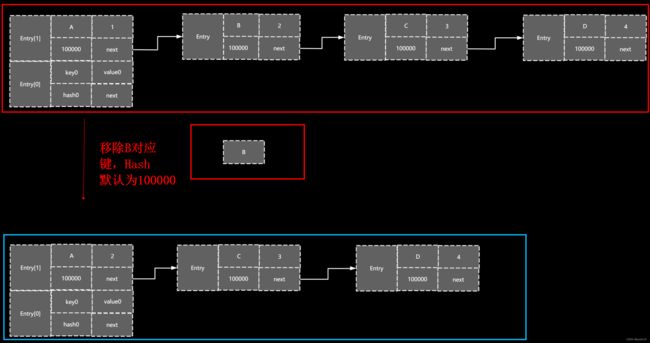
7.5)如果取得的Entry不为null,则要取到当前数组位置下的链表,并且循环判断如果key相等,hash相等,modCount(更改的次数)会增加,size减去1,然后对应的链表节点移除,当前位置指向下一个节点,前一个节点的下一个位置属性从原有的当前Key位置指向下一个节点
7.6)所有都没有找到,原样返回。
(8)扩容
public void putAll(Map m) {
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
/*
* Expand the map if the map if the number of mappings to be added
* is greater than or equal to threshold. This is conservative; the
* obvious condition is (m.size() + size) >= threshold, but this
* condition could result in a map with twice the appropriate capacity,
* if the keys to be added overlap with the keys already in this map.
* By using the conservative calculation, we subject ourself
* to at most one extra resize.
*/
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
for (Map.Entry e : m.entrySet())
put(e.getKey(), e.getValue());
} void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
} 8.1)不管数组容量左移一位,还是直接2*数组容量,都是扩大为原来的两倍长度
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
8.2)扩容时,先拿到原来的数组长度,如果老的数组长度已经跟设定的最大长度相等了,那么,扩容阈值就设置为最大值,并且结束扩容
8.3)容量正常情况下,建立新数组,然后进入实际的数据复制阶段
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry e = src[j];
if (e != null) {
src[j] = null;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
} 8.3.1)先获取原来的数组,并且得到新数组的大小(设置hash对应的位置不变)

8.3.2)循环下标处理数组,不为null的时候
8.3.2.1)原数组下标位置为null
8.3.2.2)获取对应位置链表的首个Entry,然后计算新数组下标位置
8.3.2.3)把原链表反序,加入到目前的数组位置
8.4)处理扩容阈值和新数组地址
2.JDK1.8存储机制
待补充
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}