python之requests
简介
requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,使用方法比urllib更加方便。
安装
pip快速安装:pip install requests
使用说明
请求方式
使用前,需要导入requests库:import requests
| 方法 | 调用方法 |
|---|---|
| get | requests.get(url, params=None, **kwargs) |
| post | requests.post(url, data=None, json=None, **kwargs) |
| put | requests.put(url, data=None, **kwargs) |
| delete | requests.delete(url, **kwargs) |
| options | requests.options(url, **kwargs) |
| head | requests.head(url, **kwargs) |
使用最多的方式是get和post,本章主要讲解这2个方式。
get方法
requests.get(url, params=None, **kwargs)中,除了必传的请求地址url外,还有1个默认参数params,这个参数会对url进行处理。一般get方式请求,参数是通过url?key1=value1&key2=value2....进行拼接的(即参数字段和值是=连接,参数之间连接符是&,接口路径通过?来连接参数内容),如果url已经带有参数,则可以不用params参数,如果url没有带参数,则requests.get()会将params的内容按照拼接逻辑拼接到url后。
示例:
请求方式:GET
接口路径:http://httpbin.org/get
参数:name=gemey&age=22
响应报文:返回请求数据(上传的参数数据、请求头、url)和服务器地址
带了params参数和不带的实现方式如下:
# -*- coding: utf-8 -*-
import requests
# url未携带参数数据
r1 = requests.get("http://httpbin.org/get?name=gemey&age=22")
print("----------url未携带参数数据----------")
print(r1.text)
# url携带参数数据
r2 = requests.get("http://httpbin.org/get", params={"name": "gemev", "age": 22})
print("\n----------url携带参数数据----------")
print(r2.text)
# url携带参数数据中有列表
r3 = requests.get("http://httpbin.org/get", params={"name": "gemev", "age": [22, 45]})
print("\n----------url携带参数数据中有列表----------")
print(r3.text)
执行结果为:
----------url未携带参数数据----------
{
"args": {
"age": "22",
"name": "gemey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353a902-4a61a3c00ac22a2e68043720"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?name=gemey&age=22"
}
----------url携带参数数据----------
{
"args": {
"age": "22",
"name": "gemev"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353a903-3c89e1b00e5b6cd47ecdcc53"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?name=gemev&age=22"
}
----------url携带参数数据中有列表----------
{
"args": {
"age": [
"22",
"45"
],
"name": "gemev"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353a903-0dff9b3716a2a1c12b3aa474"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?name=gemev&age=22&age=45"
}
post方法
如果想上传的数据较大,或者上传的数据对服务器方的数据库、文件等内容有修改,一般使用Post请求,post请求上传数据的方式有:表单、Json、文件等。
以下的post示例中,所使用的接口信息如下:
请求方式:POST
接口路径:http://httpbin.org/post
参数:可按照请求逻辑设置
响应报文:返回请求数据(上传的参数数据、请求头、url)和服务器地址
表单
post请求上传表单数据时,是通过data参数上传的,入参的数据是字典对象(dict)
# -*- coding: utf-8 -*-
import requests
url = 'http://httpbin.org/post'
data = {
'name': 'jack',
'age': 23
}
r = requests.post(url, data=data)
print(r.text)
执行结果为:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "23",
"name": "jack"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "16",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353af30-249b0cae334e1f374f91b017"
},
"json": null,
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
从执行结果来看,form参数请求中,Content-Type会被默认设置为application/x-www-form-urlencoded
Json
json也是post请求经常用到的数据上传格式,如果上传的数据是json格式,需要将python字典对象通过json参数传入,示例如下:
# -*- coding: utf-8 -*-
import requests
url = 'http://httpbin.org/post'
data = {
'name': 'jack',
'age': 23
}
r = requests.post(url, json=data)
print(r.text)
执行结果如下:
{
"args": {},
"data": "{\"name\": \"jack\", \"age\": 23}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "27",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353b019-7732f91c2a9fda225b85c4a8"
},
"json": {
"age": 23,
"name": "jack"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
从执行结果来看,form参数请求中,Content-Type会被默认设置为application/json
上传文件
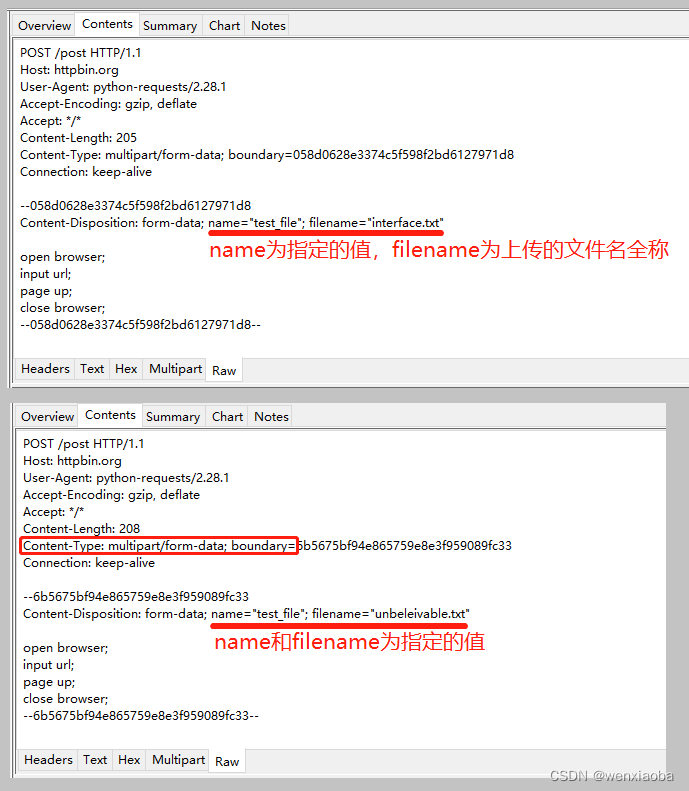
一般上传文件的请求,其请求头中的Content-Type字段值类似于"Content-Type": "multipart/form-data; boundary=xxx",,且其请求报文中,有name、filename字段,服务器端一般会检查name、filename、Content-Type这3个字段中某个或多个的字段值
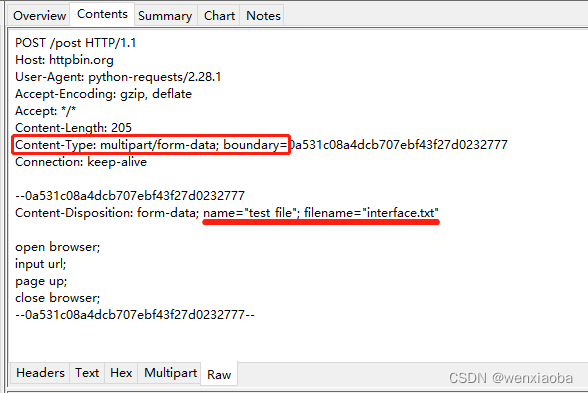
request()函数中有个files参数,用来处理文件上传,files参数需要指定name和filename(Content-Type会被默认指定值),格式为:
{"name": ("filename", open("待上传文件完整路径", "rb"))}:指定了name和filename的值{"name": open("待上传文件完整路径", "rb")}:指定了name的值,filename的值默认为上传文件的文件名和后缀
示例:
# -*- coding: utf-8 -*-
import requests
url = 'http://httpbin.org/post'
r1 = requests.post(url,files={"test_file": open("D:\\test_code\\allure_demo\\interface.txt", "rb")})
print("----------filename默认为上传文件的文件名+后缀----------")
print(r1.text)
r2 = requests.post(url, files={"test_file": ("unbeleivable.txt", open("D:\\test_code\\allure_demo\\interface.txt", "rb"))})
print("----------指定filename----------")
print(r2.text)
打印响应报文的结果基本一致,Content-Type字段值均类似于"Content-Type": "multipart/form-data; boundary=xxx",
执行结果如下:
----------filename默认为上传文件的文件名+后缀----------
{
"args": {},
"data": "",
"files": {
"test_file": "open browser;\r\ninput url;\r\npage up;\r\nclose browser;"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "205",
"Content-Type": "multipart/form-data; boundary=058d0628e3374c5f598f2bd6127971d8",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353e473-6cc609d66d687c517ce92282"
},
"json": null,
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
----------指定filename----------
{
"args": {},
"data": "",
"files": {
"test_file": "open browser;\r\ninput url;\r\npage up;\r\nclose browser;"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "208",
"Content-Type": "multipart/form-data; boundary=6b5675bf94e865759e8e3f959089fc33",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353e474-0ee3811b7a4305332066840f"
},
"json": null,
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
对请求数据进行抓包,可以看到name和filename字段值:
其他数据类型
Post请求不止上传文件、发送form、json数据,还支持html、xml等数据,这些数据一般通过data参数传入,但是需要在请求头的Content-Type字段申明数据类型。
以下以xml数据示例:
# -*- coding: utf-8 -*-
import requests
xml_data = """
RUNOOB
https://www.runoob.com
runoob-logo.png
coding study website
"""
url = 'http://httpbin.org/post'
# 指定请求头的Content-Type字段值为对应的数据类型
headers = {"Content-Type": "application/xml"}
# 需要传入url、data、headers参数
r1 = requests.post(url, data=xml_data, headers=headers)
print(r1.text)
执行结果如下:
{
"args": {},
"data": "\n\n RUNOOB \n https://www.runoob.com \n runoob-logo.png \n coding study website \n \n",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "179",
"Content-Type": "application/xml",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353e801-32d1699104c479d37decbad3"
},
"json": null,
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
响应对象和请求对象
requests.get()或post()请求后,得到一个Response对象,Response对象有很多属性和方法,常用如下:
| 属性/方法 | 说明 |
|---|---|
| content | 二进制形式的响应报文内容 |
| encoding | 解码text属性值的编码方式(即响应报文编码格式) |
| text | 响应的内容(字符串形式),unicode 类型数据 |
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie(客户端的不包含) |
| headers | 返回响应头,字典格式 |
| json() | 响应内容的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| request | 请求此响应的请求对象 |
| status_code | 响应状态码 |
| url | 响应的 URL |
其他属性或方法可以参考:Python requests 模块
示例:
# -*- coding: utf-8 -*-
import requests
cookies = {"c1": "cookie_1", "c2": "cookie_value2"}
resp = requests.get("http://httpbin.org/get?age=18&name=温小八", cookies=cookies)
print("----------content属性----------")
print(f"content所属类为:{type(resp.content)}")
print(f"content值:{resp.content}")
print("\n----------encoding属性----------")
print(f"encoding属性的值为:{resp.encoding},类型为:{type(resp.encoding)}")
print("\n----------text属性----------")
print(f"text所属类为:{type(resp.text)}")
print(f"text值:{resp.text}")
print("\n----------content属性转为字符串形式----------")
print(resp.content.decode(resp.encoding))
print("\n----------cookies属性----------")
print(f"cookies所属类为:{type(resp.cookies)}")
print(f"cookies值:{resp.cookies}")
for key, value in resp.cookies.items():
print(f"{key}: {value}")
print("\n----------headers属性----------")
print(f"headers所属类与字典类似:{type(resp.headers)}")
print(f"headers值:{resp.headers}")
print(f"header中Content-Type的值为:{resp.headers['Content-Type']}")
print("\n----------json()方法----------")
print(f"json()所属类为:{type(resp.json())}")
print(f"json()值:{resp.json()}")
print("\n----------request属性----------")
print(f"request所属类为:{type(resp.request)}")
print(f"request值:{resp.request}")
print("\n----------status_code属性----------")
print(f"status_code所属类为:{type(resp.status_code)}")
print(f"status_code值:{resp.status_code}")
print("\n----------url属性----------")
print(f"url所属类为:{type(resp.url)}")
print(f"url值:{resp.url}")
执行结果为:
----------content属性----------
content所属类为:
content值:b'{\n "args": {\n "age": "18", \n "name": "\\u6e29\\u5c0f\\u516b"\n }, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Cookie": "c1=cookie_1; c2=cookie_value2", \n "Host": "httpbin.org", \n "User-Agent": "python-requests/2.28.1", \n "X-Amzn-Trace-Id": "Root=1-6353fae2-47f16c2600b424c15447d0be"\n }, \n "origin": "113.117.59.233", \n "url": "http://httpbin.org/get?age=18&name=\\u6e29\\u5c0f\\u516b"\n}\n'
----------encoding属性----------
encoding属性的值为:utf-8,类型为:
----------text属性----------
text所属类为:
text值:{
"args": {
"age": "18",
"name": "\u6e29\u5c0f\u516b"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Cookie": "c1=cookie_1; c2=cookie_value2",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353fae2-47f16c2600b424c15447d0be"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?age=18&name=\u6e29\u5c0f\u516b"
}
----------content属性转为字符串形式----------
{
"args": {
"age": "18",
"name": "\u6e29\u5c0f\u516b"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Cookie": "c1=cookie_1; c2=cookie_value2",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353fae2-47f16c2600b424c15447d0be"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?age=18&name=\u6e29\u5c0f\u516b"
}
----------cookies属性----------
cookies所属类为:
cookies值:
----------headers属性----------
headers所属类与字典类似:
headers值:{'Date': 'Sat, 22 Oct 2022 14:14:58 GMT', 'Content-Type': 'application/json', 'Content-Length': '440', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
header中Content-Type的值为:application/json
----------json()方法----------
json()所属类为:
json()值:{'args': {'age': '18', 'name': '温小八'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Cookie': 'c1=cookie_1; c2=cookie_value2', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.28.1', 'X-Amzn-Trace-Id': 'Root=1-6353fae2-47f16c2600b424c15447d0be'}, 'origin': '113.117.59.233', 'url': 'http://httpbin.org/get?age=18&name=温小八'}
----------request属性----------
request所属类为:
request值:
----------status_code属性----------
status_code所属类为:
status_code值:200
----------url属性----------
url所属类为:
url值:http://httpbin.org/get?age=18&name=%E6%B8%A9%E5%B0%8F%E5%85%AB
response对象的request属性是个request对象,该对象也有几个属性可以了解下:
| 属性 | 说明 |
|---|---|
| url | 请求的 URL |
| headers | 请求头,字典格式 |
| path_url | 接口路径和参数内容(字符串形式),即接口域名后的内容 |
| body | 请求报文内容(二进制bytes,即字节形式) |
| method | 请求方式 |
示例:
# -*- coding: utf-8 -*-
import requests
cookies = {"c1": "cookie_1", "c2": "cookie_value2"}
data = {"gender": "女", "mobile": "188******68"}
resp = requests.post("http://httpbin.org/post?age=18&name=温小八", json=data, cookies=cookies)
req = resp.request
print("----------url属性----------")
print(f"url所属类为:{type(req.url)}")
print(f"url值:{req.url}")
print("\n----------headers属性----------")
print(f"headers所属类为:{type(req.headers)}")
print(f"headers值:{req.headers}")
print("\n----------path_url属性----------")
print(f"path_url所属类为:{type(req.path_url)}")
print(f"path_url值:{req.path_url}")
print("\n----------body属性----------")
print(f"body所属类为:{type(req.body)}")
print(f"body值:{req.body}")
print(f"转成字符串:{req.body.decode(resp.encoding)}")
print("\n----------method属性----------")
print(f"method所属类为:{type(req.method)}")
print(f"method值:{req.method}")
执行结果为:
----------url属性----------
url所属类为:
url值:http://httpbin.org/post?age=18&name=%E6%B8%A9%E5%B0%8F%E5%85%AB
----------headers属性----------
headers所属类为:
headers值:{'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'c1=cookie_1; c2=cookie_value2', 'Content-Length': '45', 'Content-Type': 'application/json'}
----------path_url属性----------
path_url所属类为:
path_url值:/post?age=18&name=%E6%B8%A9%E5%B0%8F%E5%85%AB
----------body属性----------
body所属类为:
body值:b'{"gender": "\\u5973", "mobile": "188******68"}'
转成字符串:{"gender": "\u5973", "mobile": "188******68"}
----------method属性----------
method所属类为:
method值:POST
传递Cookie
很多接口请求需要附带cookies,服务端校验成功后才会返回正常的响应数据。
requests提供2种传递Cookie的方式:
- 通过请求头信息传递:headers参数被传入字典,字典中包含
Cookie键值对(为了让服务端正常识别,cookie的值格式尽量为:key1=value1; key2=value2; xxx; keyn=valuen,) - 通过关键字参数cookies传递:cookies参数被传入字典,字典数据中的每个键值代表了一个cookie,键表示cookie的变量名称,值为对应的cookie值。
示例:
# -*- coding: utf-8 -*-
import requests
headers = {
"Cookie": "key1=value1;key2=value2"
}
r1 = requests.get("http://httpbin.org/get?age=18&name=温小八", headers=headers)
print(f"请求头header携带cookies的方式,请求头数据为:{r1.request.headers}")
cookies = {"c1": "cookie_1", "c2": "cookie_value2"}
r2 = requests.get("http://httpbin.org/get?age=18&name=温小八", cookies=cookies)
print(f"\ncookies参数传递的方式,请求头数据为:{r1.request.headers}")
print(r2.request.headers)
执行结果如下:
请求头header携带cookies的方式,请求头数据为:{'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'key1=value1;key2=value2'}
cookies参数传递的方式,请求头数据为:{'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'key1=value1;key2=value2'}
{'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'c1=cookie_1; c2=cookie_value2'}
超时设置
request()方法有超时处理机制,根据我们传入的参数timeout(单位秒,float类型)判断是否请求超时,若响应超时,则程序报错(ConnectTimeout)。
简单使用示例:
# -*- coding: utf-8 -*-
import requests
r1 = requests.get("http://httpbin.org/get?age=18&name=温小八", timeout=2.5)
print(f"请求在2.5秒内应答了,请求状态码为:{r1.status_code},请求响应时间为:{r1.elapsed.microseconds}微秒(相当于{r1.elapsed.microseconds/1000000}秒)")
执行结果为:
请求在2.5秒内应答了,请求状态码为:200,请求响应时间为:539199微秒(相当于0.539199秒)
timeout 参数如果传入的是一个数值,则timeout只对连接过程(应答,即从基础套接字上接收到任何字节的数据)的时间生效,如果相对响应体的下载时间也进行设置,则timeout传入一个元组,元组包含2个数值,第一个是针对连接过程,第2个针对响应体下载时间生效。如:r = requests.get("http://httpbin.org/get", timeout=(3.05, 27))
代理设置
调试时我们可能需要抓包来查看接口数据,或者需要通过代理去降低请求频率(比如服务端有对单位时间的同一IP的请求数量做处理等),这个时候,我们就需要将请求发送到代理,让代理发送给服务端,然后代理再将服务端响应数据返回给我们,设置代理的示例如下:
# -*- coding: utf-8 -*-
import requests
proxies = {"http": "http://127.0.0.1:8888",
"https": "http://127.0.0.1:8888"}
r1 = requests.get("http://httpbin.org/get?age=18&name=温小八", proxies=proxies)
print(f"http请求:{r1.text}")
# https请求通过代理,https默认去验证证书,设置成不验证:verify=False,后面在具体了解证书逻辑
r2 = requests.get("https://httpbin.org/get?age=19&name=温小九", proxies=proxies, verify=False)
print(f"https请求:{r2.text}")
执行结果如下:
http请求:{
"args": {
"age": "18",
"name": "\u6e29\u5c0f\u516b"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6354ae18-388d4ea440ff092f2c2b1fe6"
},
"origin": "113.117.125.63",
"url": "http://httpbin.org/get?age=18&name=\u6e29\u5c0f\u516b"
}
C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host '127.0.0.1'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
https请求:{
"args": {
"age": "19",
"name": "\u6e29\u5c0f\u4e5d"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6354ae1a-5d82379b695464b763a08146"
},
"origin": "113.117.125.63",
"url": "https://httpbin.org/get?age=19&name=\u6e29\u5c0f\u4e5d"
}
如果本地有证书的话,则将参数verify设置成证书的路径,如:requests.get('https://github.com', verify='/path/to/certfile')
认证
我们在访问接口时,很多需要去验证用户信息,验证方式有多种,requests封装了多种方式,requests.auth下支持Basic Authentication、Digest Authentication
接口来源:httpbin.org
# -*- coding: utf-8 -*-
import requests
from requests.auth import HTTPBasicAuth, HTTPDigestAuth
from requests_oauthlib import OAuth1
url = "http://httpbin.org/basic-auth/wenxiaoba/123458"
# auth未指定认证方式时,默认是HTTPBasicAuth认证
r_default = requests.get(url, auth=("wenxiaoba", "123458"))
print("-------------auth未指定认证方式-------------")
print(f"请求的请求头:{r_default.request.headers}")
print(f"响应数据:{r_default.text}")
# auth指定HTTPBasicAuth认证
r_basic = requests.get(url, auth=HTTPBasicAuth("wenxiaoba", "123458"))
print("-------------auth指定HTTPBasicAuth认证-------------")
print(f"请求的请求头:{r_basic.request.headers}")
print(f"响应数据:{r_basic.text}")
# auth指定HTTPDigesAuth认证
url = 'https://httpbin.org/digest-auth/auth/wenxiaoba/123458'
r_digest = requests.get(url, auth=HTTPDigestAuth('wenxiaoba', '123458'))
print("-------------auth指定HTTPDigesAuth认证-------------")
print(f"请求的请求头:{r_digest.request.headers}")
print(f"响应数据:{r_digest.text}")
执行结果如下:
-------------auth未指定认证方式-------------
请求的请求头:{'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Authorization': 'Basic d2VueGlhb2JhOjEyMzQ1OA=='}
响应数据:{
"authenticated": true,
"user": "wenxiaoba"
}
-------------auth指定HTTPBasicAuth认证-------------
请求的请求头:{'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Authorization': 'Basic d2VueGlhb2JhOjEyMzQ1OA=='}
响应数据:{
"authenticated": true,
"user": "wenxiaoba"
}
-------------auth指定HTTPDigesAuth认证-------------
请求的请求头:{'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'stale_after=never; fake=fake_value', 'Authorization': 'Digest username="wenxiaoba", realm="[email protected]", nonce="54d3f7882d08650c86d6780fe08ef184", uri="/digest-auth/auth/wenxiaoba/123458", response="21501b89292c1b23c8fdf1e424425b56", opaque="c8628f7877ee460311c777ec646c4562", algorithm="MD5", qop="auth", nc=00000001, cnonce="1bfef844c27762d6"'}
响应数据:{
"authenticated": true,
"user": "wenxiaoba"
}
其他的认证方式可以安装对应的库,比如OAuth 1 Authentication的认证,可以安装requests_oauthlib库,该库支持requests的auth参数传递。语法如下:
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1('YOUR_APP_KEY', 'YOUR_APP_SECRET',
'USER_OAUTH_TOKEN', 'USER_OAUTH_TOKEN_SECRET')
requests.get(url, auth=auth)
会话
会话会自动处理cookies信息、缓存数据而不用在请求时自己处理。
# -*- coding: utf-8 -*-
import requests
session = requests.session()
session.get("http://httpbin.org/cookies/set/number/python_request")
r = session.get("http://httpbin.org/cookies")
print(r.text)
cookie和session区别
1、cookie数据存放在客户的浏览器上,session数据放在服务器上
2、cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。(Session对象没有对存储的数据量的限制,其中可以保存更为复杂的数据类型)
Session其实是利用Cookie进行信息处理的,当用户首先进行了请求后,服务端就在用户浏览器上创建了一个Cookie,当这个Session结束时,其实就是意味着这个Cookie就过期了。