【Shell】基础语法(三)
文章目录
- 一、Shell基础语法
-
- 1. 位置参数和特殊变量
- 2. 输入输出
- 3. 管道
- 4. 文件重定向
- 5. 函数
- 6. 脚本调试方法
- 二、Shell高级和正则表达式
-
- 1. sort命令
- 2. uniq命令
- 3. wc命令
- 4. grep命令
- 5. find命令
- 6. xargs
- 7. sed命令
- 8. crontab
一、Shell基础语法
1. 位置参数和特殊变量
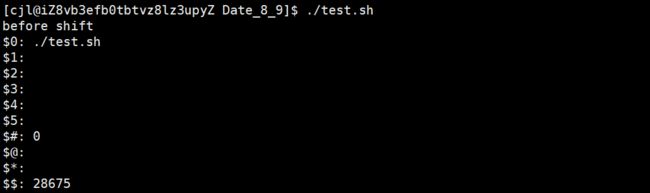
$0 相当于C语言main函数的argv[0]
$1、$2... 这些称为位置参数(Positional Parameter),相当于C语言main函数的argv[1]、argv[2]...
$# 相当于C语言main函数的argc - 1,注意这里的#后面不表示注释
$@ 表示参数列表"$1" "$2" ...,例如可以用在for循环中的in后面。
$* 表示参数列表"$1" "$2" ...,同上
$? 上一条命令的Exit Status
$$ 当前进程号
位置参数默认就支持10个 ,当然$@还是支持n个,可以配合shift来进行参数左移,来操作不定参数
#!/bin/bash
echo "before shift"
echo '$0:' $0
echo '$1:' $1
echo '$2:' $2
echo '$3:' $3
echo '$4:' $4
echo '$5:' $5
echo '$#:' $#
echo '$@:' $@
echo '$*:' $*
echo '$$:' $$
2. 输入输出
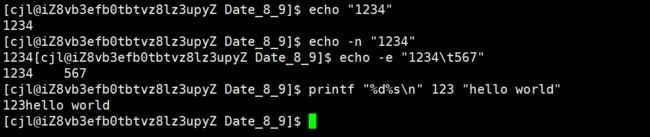
echo -n 表示不换行
echo -e 解析转义字符
echo -e "123\t234"
printf "%d\t%s\n" 123 "hello"
跟C的printf一样
3. 管道
使用 | 将多个命令拼接在一起。原理:就是将前一个命令的标准输出作为后一个命令的标准输入来重定向 ,标准错误输出是不会重定向。实际上是将前面进程的标准输出重定向到后边进程的标准输入。
#include ![]()
tee命令:tee命令把结果输出到标准输出,另一个副本输出到相应文件。


4. 文件重定向
cmd > file 把标准输出重定向到新文件中
cmd >> file 追加
cmd > file 2>&1 标准出错也重定向到1所指向的file里
2>&1
文件描述符2 也重定向到文件描述符1的位置
标准错误输出也重定向到标准输出的位置
cmd >> file 2>&1
cmd < file
将file的内容重定向到cmd命令的标准输入
cmd < file1 > file2 输入输出都定向到文件里
cmd < &fd 把文件描述符fd作为标准输入
cmd > &fd 把文件描述符fd作为标准输出
cmd < &- 关闭标准输入
#include 


5. 函数
function 函数名() #小括号里边也不需要填参数列表
{
local var=value #局部变量
return 1 #return 只能返回整数,不能返回其他类型 ,返回值是作为退出状态来使用
}
function关键字可以省略 ,小括号也可以省略 ,但是两个必须要保留一个,不然解析器不知道你要定义的是一个函数。- 调用函数的方法,就跟普通命令一样:
函数名 arg1 arg2 ... - 函数的执行状态看return语句,如果没有return语句,就以函数里边最后一条执行的指令的返回状态作为整个函数的退出状态。
testfunc()
{
echo "Testfunc"
return 1
}
testfunc
echo $?

Shell函数没有参数列表并不表示不能传参数,事实上,函数就像是迷你脚本,调用函数时可以传任意个参数,在函数内同样是用$0、$1、$2等变量来提取参数,函数中的位置参数相当于函数的局部变量,改变这些变量并不会影响函数外面的$0、$1、$2等变量。函数中可以用return命令返回,如果return后面跟一个数字则表示函数的Exit Status。
递归遍历当前目录下的所有文件:
#!/bin/bash
function visit
{
local dir="$1"
for f in `ls $1`
do
if [ -f "$dir/$f" ]
then
echo "$dir/$f is a file"
elif [ -d "$dir/$f" ]
then
echo "$dir/$f is a dir"
visit "$dir/$f"
else
echo "$dir/$f is not recognized"
fi
done
}
visit .

6. 脚本调试方法
-
bash
-ntest.sh 遍历一下脚本,检查语法错误,如果没有语法错误,则什么都不会显示。

-
bash
-vtest.sh 一边执行脚本一边将解析到的脚本输出来

-
bash
-xtest.sh 执行脚本的同时打印每一句命令,把变量的值都打印出来 (常用)

二、Shell高级和正则表达式
1. sort命令
命令从标准输入中读取数据然后按照字符串内容进行排序
-f 忽略字符大小写
-n 比较数值大小
-t 指定分割符,默认是空格或者tab
-k 指定分割后进行比较字段
-u 重复的行只显示一次
-r 反向排序
-R 打乱顺序
同样的两行洗不乱
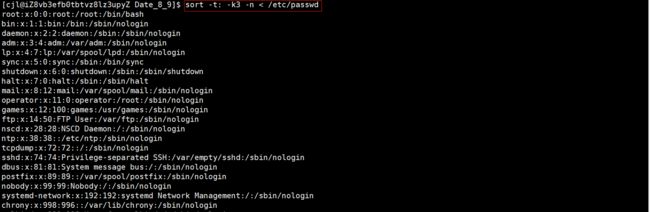
将 /etc/passwd 根据用户id来排序:sort -t: -k3 -n < /etc/passwd
2. uniq命令
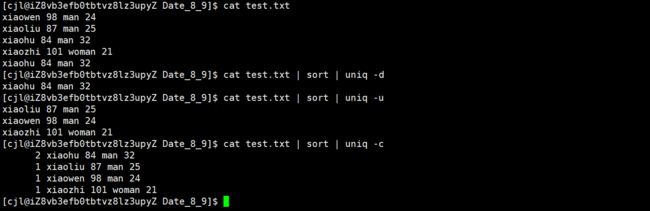
去除重复的行,前提是重复的行连续
-c 显示每行重复的次数
-d 仅显示重复过的行
-u 仅显示不曾重复的行
sort < test.txt | uniq
3. wc命令
word count
-l 统计行数
-c 统计字节数
-w 统计单词数

4. grep命令
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。Linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。

global regular expression print
-c 只输出匹配行的计数
-i 不区分大小写
-H 文件名显示
-r 递归遍历目录
-n 显示行号
-s 不显示不存在或无匹配文本的错误信息
-v 显示不包含匹配文本的所有行,这个参数经常用于过滤不想显 示的行
-E 使用扩展的正则表达
-P 使用perl的正则表达式
-F 匹配固定的字符串,而非正则表达式
egrep = grep -E
fgrep = grep -F
rgrep = grep -r
grep 默认使用的是基础的正则

5. find命令
find命令的一般形式为 find pathname -options [-print -exec -ok ...]
option 选项如下:
-name 按照文件名查找文件。
find . -name "1.txt"
-perm 按照文件权限来查找文件。
find . -perm 660
-user 按照文件属主来查找文件。
-group 按照文件所属的组来查找文件。
-mtime -n +n 按照文件的更改时间来查找文件,-n表示文件更改时间距现在n天以内,+n表示文件更改时间距现在
n天以前。find命令还有-atime和-ctime 选项,但它们都和-m time选项。
-atime 访问时间
-ctime 创建时间
-nogroup 查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser 查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2 查找更改时间比文件file1新但比文件file2旧的文件。
-type 查找某一类型的文件,诸如:
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
s - socket文件
-exec
find . -name "*.txt" -exec gzip {} \;
查找当前目录下的txt文件并且打包成为gzip
每找到一个文件,就会执行exec后面的命令
gzip ./a/2.txt
gzip ./a/6.txt
最后是一个\; 反斜杠不能省,作为当前exec后面命令的结束符
-ok
跟-exec用法一样,但是每找到一个文件要执行后面的命令前会给用户确认




6. xargs
将标准输入的参数整齐的拼凑到同一行中,单独使用该命令没有任何作用,需要配合其他命令来使用。
在使用find命令的-exec选项处理匹配到的文件时, find命令将所有匹配到的文件一起传递给exec执行。但有些系统对能够传递给exec的命令长度有限制,这样在find命令运行几分钟之后,就会出现 溢出错误。错误信息通常是“参数列太长”或“参数列溢出”。这就是xargs命令的用处所在,特别是与find命令一起使用。
find命令把匹配到的文件传递给xargs命令,而xargs命令每次只获取一部分文件而不是全部,不像-exec选项那样。这样它可以先处理最先获取的一部分文件,然后是下一批,并如此继续下去。


7. sed命令
sed意为流编辑器(Stream Editor),在Shell脚本和Makefile中作为过滤器使用非常普遍,也就是把前一个程序的输出引入sed的输入,经过一系列编辑命令转换为另一种格式输出。sed和vi都源于早期UNIX的ed工具,所以很多sed命令和vi的末行命令是相同的。
文本1 -> sed + 脚本 -> 文本2
ed 编辑器 -> sed -> vim
sed option 'script' file1 file2 ... sed 参数 ‘脚本(/pattern/action)’ 待处理文件
sed option -f scriptfile file1 file2 ... sed 参数 –f ‘脚本文件’ 待处理文件
p, print 打印
a, append 追加
i, insert 插入
d, delete 删除
s, substitution 替换
// file.txt
qwertyuiop
asdfghjkl
zxcvbnm
1234567890
9876543210




8. crontab
Linux crontab 是用来定期执行程序的命令。当安装完成操作系统之后,默认便会启动此任务调度命令。crond 命令每分钟会定期检查是否有要执行的工作,如果有要执行的工作便会自动执行该工作。
linux 系统定时器
需求,每天什么时候去做什么事情
/etc/crontab
# m h dom mon dow user command
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
crontab.sh
#!/bin/bash
# 获取当前路径
curPath=$(cd `dirname $0`;pwd)
date >> "$curPath/date.txt"
