python爬虫实战(1)--爬取新闻数据
想要每天看到新闻数据又不想占用太多时间去整理,萌生自己抓取新闻网站的想法。
1. 准备工作
使用python语言可以快速实现,调用BeautifulSoup包里面的方法
安装BeautifulSoup
pip install BeautifulSoup
完成以后引入项目
2. 开发
定义请求头,方便把请求包装成正常的用户请求,防止被拒绝
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
定义被抓取的url,并请求加上请求头
response = requests.get(url=url, headers=headers)
BeautifulSoup解析
soup = BeautifulSoup(response.text, "html.parser")
分析网站需要提取数据的标签--爬取新闻数据_第1张图片](http://img.e-com-net.com/image/info8/8f376b9510284141836b1799487c7601.jpg)
因为获取的对象是li标签的第一个,即
divs = soup.find(class_="js-item item")
这样默认就是第一个,如果需要获取全部,则需要find_all,遍历集合
防止获取到的新闻是当天的做一个日期判断
a = first_div.find(class_="title")
if a.getText().__contains__(datetime.date.today().strftime("%#m月%#d日")):
日期存在title里面所以为了判断单独取一下信息
然后要取到最新日期的新闻自己的url,并get请求这个url

b = a.get('href')
response = requests.get(url=b, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
打开新的网址后分析网站标签信息
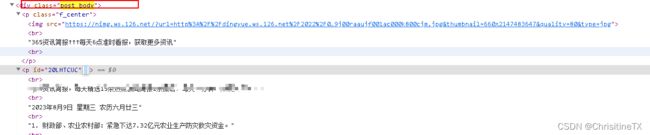
取这个标签,获取到p标签的值
body = soup.find(class_="post_body")
p = body.find_all('p')
获取到的是个数组,去掉第一个元素,从第二个开始即是我们需要的结果
p_id_tag = p[1].__str__()
输出的信息带有元素标记,使用正则处理一下
raw_text = re.findall(r']*>(.*?)', p_id_tag).__str__()
# 去掉 HTML 标签并换行显示
clean_text = raw_text.replace('
', '\n').replace('', '').replace('
', '').replace("']",
"").replace(
"['", "").replace(r"\u200b", "")
然后把抓取的信息写入txt
file = open("C:\\Users\\Administrator\\Desktop\\每日新闻" + '.txt',
'w', encoding='utf-8')
file.write(clean_text)
file.close()
最后使用定时任务每天定时抓取,这样就可以每天更新了
schedule.every().day.at("08:00").do(getNews)
while True:
schedule.run_pending()
time.sleep(1)
运行效果
