MYSQL触发器,存储过程与函数
MYSQL触发器,存储过程与函数
1.触发器
在我们要进行数据库应用的时候,常常会需要创建一些辅助的东西来帮助我们实现多表之间数据联动的处理。例如我们修改了学生表的记录,添加进去一个学生。那么在相应的人数统计的表中就需要增加1个人数。如果每次写入SQL语句的时候都需要人为的处理这种依赖关系,显然费时费力。此时触发器则起到了作用。
触发器(trigger)是一个特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,
比如当对一个表进行操作( insert,delete, update)时就会激活它执行。
1.1 触发器的创建
语法结构:
CREATE TRIGGER 触发器名称 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN
触发器程序体;
END
# 说明:
<触发器名称> 最多64个字符,它和MySQL中其他对象的命名方式一样
{ BEFORE | AFTER } 触发器时机
{ INSERT | UPDATE | DELETE } 触发的事件
ON <表名称> 标识建立触发器的表名,即在哪张表上建立触发器
FOR EACH ROW 触发器的执行间隔:
FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次
<触发器程序体> 要触发的SQL语句:可用顺序,判断,循环等语句实现一般程序需要的逻辑功能
注:符号问题很重要,注意begin和end之间的语句是需要写分号的。
关于符号转换标识:在实际开发中我们写的函数,触发器等语句是多语句的整体,需要告诉系统我们的语句是一个整体。故需要标志这个整体的位置,具体解释如下
DELIMITER $$ -- 定义结束符为$$
{整体内容...}
END$$ -- 确认语句结束
DELIMITER ; -- 将语句定义回$$
1.2 实例演示
示例1:创建学生表,内部新插入数据后将人数表内信息自增
-- 1.创建数据表
CREATE TABLE student(
id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY NOT NULL,
s_name VARCHAR(20)
);
INSERT INTO student(s_name) VALUES ('张三');
CREATE TABLE student_total(total INT);
INSERT INTO student_total (total) VALUES (1);
-- 2.1 定义触发器
DELIMITER $$
CREATE TRIGGER student_insert_trigger AFTER INSERT
ON student FOR EACH ROW
BEGIN
UPDATE student_total SET total=total+1;
END$$
DELIMITER ;
-- 2.2调用触发器,查看效果
INSERT INTO student (s_name) VALUES ('batman');
SELECT * FROM student_total;
-- 3.1 查看当前表触发器
SHOW TRIGGERS;
-- 3.2 通过系统表查看所有触发器
SELECT * FROM information_schema.TRIGGERS;
-- 4.删除触发器
DROP TRIGGER student_insert_trigger;
示例2:创建更新和删除触发器并测试
-- 1.创建表
CREATE TABLE tab2(
id INT PRIMARY KEY AUTO_INCREMENT,
t_name VARCHAR(20),
salary DOUBLE(10,2)
);
CREATE TABLE tab1(
id INT PRIMARY KEY AUTO_INCREMENT,
t_name VARCHAR(20),
sex ENUM('m','f'),
age INT
);
-- 2.定义触发器
DELIMITER $$
CREATE TRIGGER tab1_delete_trigger AFTER DELETE
ON tab1 FOR EACH ROW
BEGIN
DELETE FROM tab2 WHERE tab2.`t_name`=old.t_name;
END$$
DELIMITER ;
-- 3.测试触发器
DELETE FROM tab1 WHERE id=1;
SELECT * FROM tab2;
-- 4.定义更新触发器
DELIMITER $$
CREATE TRIGGER tab1_after_update AFTER UPDATE
ON tab1 FOR EACH ROW
BEGIN
UPDATE tab2 SET t_name=new.t_name WHERE t_name=old.t_name;
END$$
DELIMITER ;
-- 5.更新触发器测试
UPDATE tab1 SET t_name='batman' WHERE t_name='文章';
SELECT * FROM tab2;
2.存储过程
2.1 什么是存储过程?函数呢?
存储过程和函数是事先经过编译并存储在数据库中的一段sql语句集合,调用存储过程函数可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程和函数的区别:
- 函数必须有返回值,而存储过程可以没有。
- 存储过程的参数可以是IN、OUT、INOUT类型,函数的参数只能是IN
2.2 存储过程的优点
- 存储过程只在创建时进行编译;而SQL语句每执行一次就编译一次,所以使用存储过程可以提高数据库执行速度
- 简化复杂操作,结合事务一起封装
- 复用性好
- 安全性高,可指定存储过程的使用权
注意:在并发量低的情况下,很少使用存储过程,并发量高的情况下,为了提高效率,用存储过程比较多。
2.3 存储过程的创建与应用
创建存储过程的语法:
create procedure sp_name(参数列表)
[特性...]过程体
存储过程的参数形式:[IN | OUT | INOUT]参数名 类型
IN 输入参数
OUT 输出参数
INOUT 输入输出参数
#调用
call 存储过程名(实参列表)
示例1:无参存储过程
-- 1.定义无参存储过程
DELIMITER $$
CREATE PROCEDURE p1()
BEGIN
SELECT COUNT(*) FROM mysql.`user`;
END$$
DELIMITER ;
-- 2.调用存储过程
CALL p1();
-- 3.定义调用具有循环作用的存储过程
-- 3.1 创建测试表
CREATE TABLE t1(
id INT,
t_name VARCHAR(50)
);
-- 3.2 定义存储过程
DELIMITER $$
CREATE PROCEDURE p2()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE(i < 2000) DO
INSERT INTO t1 VALUES (i,MD5(i));
SET i=i+1;
END WHILE;
END$$
DELIMITER ;
-- 3.3 调用存储过程并测试
CALL p2();
SELECT * FROM t1;
示例2:有输入参数的存储过程
-- 创建测试表
CREATE TABLE t1(
id INT,
t_name VARCHAR(50)
);
-- 1.创建存储过程
DELIMITER $$
CREATE PROCEDURE p3(IN a INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE(i示例3:定义带有输出参数的存储过程
-- 1.定义输出型存储过程
DELIMITER $$
CREATE PROCEDURE p4(OUT out1 INT)
BEGIN
SELECT COUNT(*) INTO out1 FROM t1;
END$$
DELIMITER ;
-- 2.执行输出
CALL p4(@output);
SELECT @output;
示例4:输入输出同时有的存储过程
这里我们需要先修改student表的数据,之前创建过的。

-- I/O存储过程
-- 1.创建存储过程
DELIMITER $$
CREATE PROCEDURE p5(IN in1 VARCHAR(50),OUT out1 INT)
BEGIN
SELECT COUNT(*) INTO out1 FROM student WHERE s_name=in1;
END$$
DELIMITER ;
2.测试
CALL p5('张三',@out);
SELECT @out;

示例5:inout参数的使用
可进可出的参数,属实优点迷
-- 1.创建
DELIMITER $$
CREATE PROCEDURE p6(INOUT test INT)
BEGIN
IF(test IS NULL)THEN
SELECT 100 INTO test;
ELSE
SET test=test+1;
END IF;
END$$
DELIMITER ;
-- 2.测试
SELECT @ceshi;
CALL p6(@ceshi);
SELECT @ceshi;
CALL p6(@ceshi);
SELECT @ceshi;
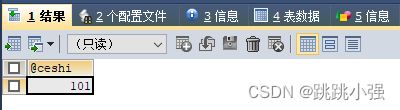
总结:作为inout参数来说,其作用就是把变量输入到存储过程处理完后将变量返回来。类似于C语言里的地址传参进行数据处理;
3.存储函数
3.1 函数创建环境
有的用户在使用MYSQL时会出现1418报错,这是因为我们启用了binlog造成的数据不一致问题,有两种解决方案,可以参考以下博文:
MYSQL 错误1418
方法1:第一种是在创建子程序(存储过程、函数、触发器)时,声明为DETERMINISTIC或NO SQL与READS SQL DATA中的一个, 例如:
CREATE DEFINER = CURRENT_USER PROCEDURE `NewProc`()
DETERMINISTIC
BEGIN
#Routine body goes here...
END;;
方法2:第二种是信任子程序的创建者,禁止创建、修改子程序时对SUPER权限的要求,设置log_bin_trust_routine_creators全局系统变量为1。下面三个任意一个均可以解决问题。
(1)在客户端上执行 SET GLOBAL log_bin_trust_function_creators = 1。
(2)MySQL启动时,加上--log-bin-trust-function-creators选项,参数设置为1。
(3)在MySQL配置文件my.ini或my.cnf中的[mysqld]段上加log-bin-trust-function-creators=1。
3.2 函数的创建
CREATE FUNCTION func_name ([param_name type[,...]])
RETURNS type
[characteristic ...]
BEGIN
routine_body
END;
参数说明:
(1)func_name :存储函数的名称。
(2)param_name type:可选项,指定存储函数的参数。type参数用于指定存储函数的参数类型,该类型
可以是MySQL数据库中所有支持的类型。
(3)RETURNS type:指定返回值的类型。
(4)characteristic:可选项,指定存储函数的特性。
(5)routine_body:SQL代码内容。
3.3 函数的应用举例
示例1:无参有返回值
-- 定义函数统计student表中的员工个数
-- 1.定义函数
DELIMITER $$
CREATE FUNCTION f1()
RETURNS INT
BEGIN
DECLARE c INT DEFAULT 0;
SELECT COUNT(1) INTO c FROM student;
RETURN c;
END$$
DELIMITER ;
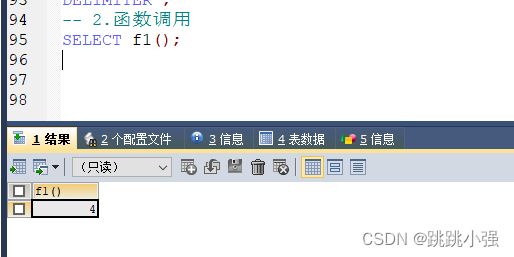
-- 2.函数调用
SELECT f1();
示例2:带参数
-- 定义有参数的函数
-- 1.环境修改
ALTER TABLE student ADD COLUMN salary DOUBLE;
UPDATE student SET salary=20 WHERE s_name='batman';
-- 2.函数创建
DELIMITER $$
CREATE FUNCTION f2(in_ VARCHAR(20))
RETURNS INT
BEGIN
DECLARE sa INT;
SELECT salary INTO sa FROM student WHERE s_name=in_;
RETURN sa;
END$$
DELIMITER ;
-- 3.函数调用
SELECT f2('batman');
示例3:带参数和返回值
-- 1.函数求均值
DELIMITER $$
CREATE FUNCTION f3(n VARCHAR(20))
RETURNS DOUBLE
BEGIN
DECLARE s_avg DOUBLE;
SELECT AVG(salary) INTO s_avg FROM student WHERE s_name=n;
RETURN s_avg;
END$$
DELIMITER ;
-- 2.执行函数
SELECT * FROM student;
SELECT f3('张三');
-- 3.删除函数
DROP FUNCTION f3;