动力节点2023最新-MybatisPlus教程(五)拓展篇
5 【拓展篇】
5.1 逻辑删除
前面我们完成了基本的增删改查操作,但是对于删除操作来说,我们思考一个问题,在实际开发中我们真的会将数据完成从数据库中删除掉么?
当然是不会的,这里我们举个例子:
在电商网站中,我们会上架很多商品,这些商品下架以后,我们如果将这些商品从数据库中删除,那么在年底统计商品数据信息的时候,这个商品要统计的,所以这个商品信息我们是不能删除的。

如果商城中的商品下架了,这时候我们将商品从数据库删掉
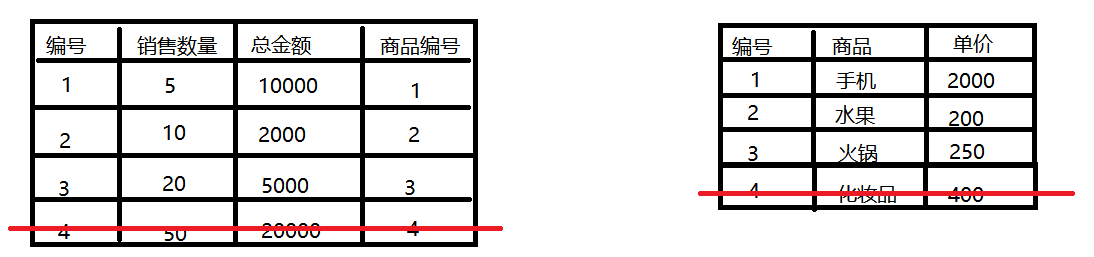
那到了年终总结的时候,我们要总结一下这一年的销售额,发现少了20000,这肯定不合理。所以我们是不能将数据真实删除的。
这里我们就采取逻辑删除的方案,逻辑删除的操作就是增加一个字段表示这个数据的状态,如果一条数据需要删除,我们通过改变这条数据的状态来实现,这样既可以表示这条数据是删除的状态,又保留了数据以便以后统计,我们来实现一下这个效果。
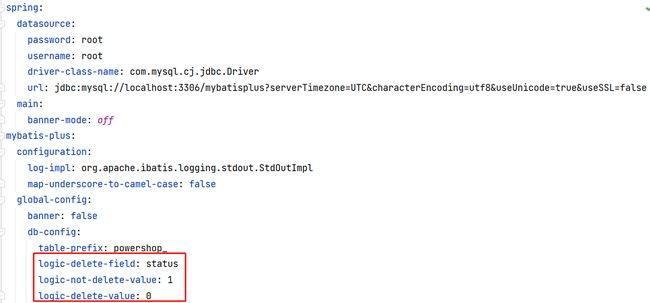
【1】先在表中增加一列字段,表示是否删除的状态,这里我们使用的字段类型为int类型,通过1表示该条数据可用,0表示该条数据不可用

【2】实体类添加一个字段为Integer,用于对应表中的字段
@Data
@AllArgsConstructor
@NoArgsConstructorpublic class User extends Model {
private Long id;
private String name;
private Integer age;
private String email;
@TableLogic(value = "1",delval = "0")
private Integer status;
}
【3】测试逻辑删除效果
@Testvoid logicDelete(){
userMapper.deleteById(7L);
}
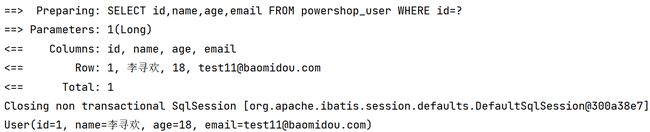
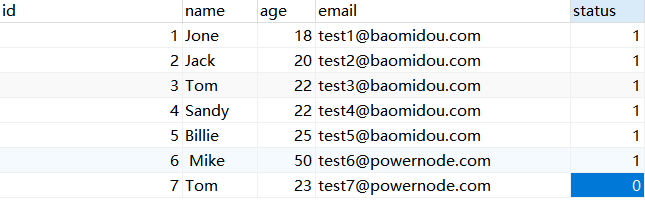
查看拼接的SQL语句,我们发现在执行删除操作的时候,语句变成了修改,是将这条数据的状态由1变为的0,表示这条数据为删除状态

我们还可以通过全局配置来实现逻辑删除的效果
5.2 通用枚举
首先我们先来回顾一下枚举,什么是枚举呢?
当我们想要表示一组信息,这组信息只能从一些固定的值中进行选择,不能随意写,在这种场景下,枚举就非常的合适。
例如我们想要表示性别,性别只有两个值,要么是男性,要么是女性,那我们就可以使用枚举来描述性别。
【1】我们先在表中添加一个字段,表示性别,这里我们一般使用int来描述,因为int类型可以通过0和1这两个值来表示两个不同的性别
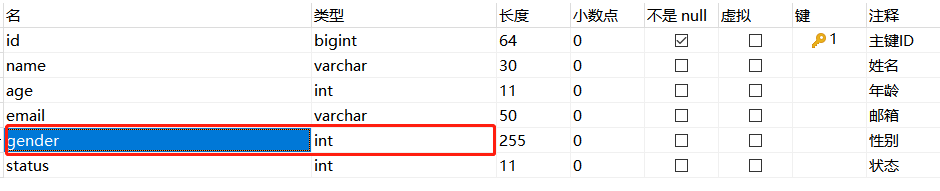
【2】编写枚举类
public enum GenderEnum {
_MAN_(0,"男"),
_WOMAN_(1,"女");
private Integer gender;
private String genderName;
GenderEnum(Integer gender, String genderName) {
this.gender = gender;
this.genderName = genderName;
}
}
【3】实体类添加相关字段
@Data
@AllArgsConstructor
@NoArgsConstructorpublic class User extends Model {
private Long id;
private String name;
private Integer age;
private String email;
private GenderEnum gender;
private Integer status;
}
【4】添加数据
@Testvoid enumTest(){
User user = new User();
user.setName("liu");
user.setAge(29);
user.setEmail("[email protected]");
user.setGenderEnum(GenderEnum._MAN_);
user.setStatus(1);
userMapper.insert(user);
}
此时我们查看控制台,会发现添加失败了

原因是我们无法将一个枚举类型作为int数字插入到数据库中。不过我们对于枚举类型都给了对应的int的值,所以这里我们只需要进行一个配置,就可以将枚举类型作为数字插入到数据库中,为属性gender,添加上@EnumValue注解
public enum GenderEnum {
_MAN_(0,"男"),
_WOMAN_(1,"女");
@EnumValue
private Integer gender;
private String genderName;
GenderEnum(Integer gender, String genderName) {
this.gender = gender;
this.genderName = genderName;
}
}
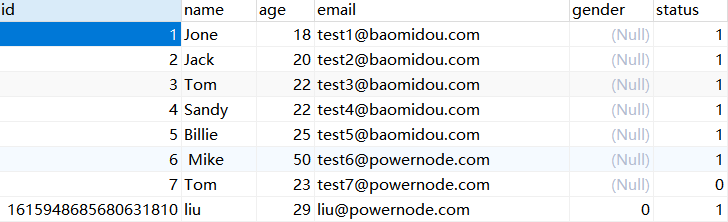
此时我们再次执行添加操作,发现可以成功添加数据,而枚举类型的值也作为数据被插入到数据库中
![]()
5.3 字段类型处理器
在某些场景下,我们在实体类中是使用Map集合作为属性接收前端传递过来的数据的,但是这些数据存储在数据库时,我们使用的是json格式的数据进行存储,json本质是一个字符串,就是varchar类型。那怎么做到实体类的Map类型和数据库的varchar类型的互相转换,这里就需要使用到字段类型处理器来完成。
【1】我们先在实体类中添加一个字段,Map类型
@Data
@AllArgsConstructor
@NoArgsConstructorpublic class User extends Model {
private Long id;
private String name;
private Integer age;
private String email;
private GenderEnum gender;
private Integer status;
private Map contact;**//联系方式**}
【2】在数据库中我们添加一个字段,为varchar类型

【3】为实体类添加上对应的注解,实现使用字段类型处理器进行不同类型数据转换
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName(autoResultMap = true)**//查询时将json字符串封装为Map集合**public class User extends Model {
private Long id;
private String name;
private Integer age;
private String email;
private GenderEnum gender;
private Integer status;
@TableField(typeHandler = FastjsonTypeHandler.class)**//指定字段类型处理器
**private Map contact;**//联系方式**}
【4】字段类型处理器依赖Fastjson这个Json处理器,所以我们需要引入对应的依赖
com.alibaba
fastjson
1.2.76
【5】测试添加操作
@Testvoid typeHandler(){
User user = new User();
user.setName("zhang");
user.setAge(28);
user.setEmail("[email protected]");
user.setGender(GenderEnum._MAN_);
user.setStatus(1);
HashMap contact = new HashMap<>();
contact.put("phone","010-1234567");
contact.put("tel","13388889999");
user.setContact(contact);
userMapper.insert(user);
}
执行的SQL语句如下
==> Preparing: INSERT INTO powershop_user ( id, name, age, email, gender, status, contact ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
==> Parameters: 1617915941843202049(Long), zhang(String), 28(Integer), [email protected](String), 0(Integer), 1(Integer), {"phone":"010-1234567","tel":"13388889999"}(String)
<== Updates: 1
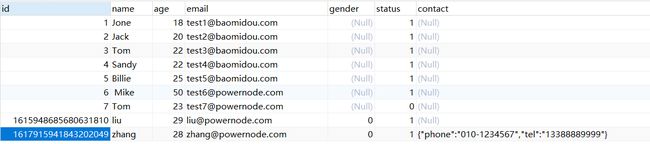
通过观察SQL语句,我们发现当插入一个Map类型的字段的时候,该字段会转换为String类型
查看数据库中的信息,发现添加成功
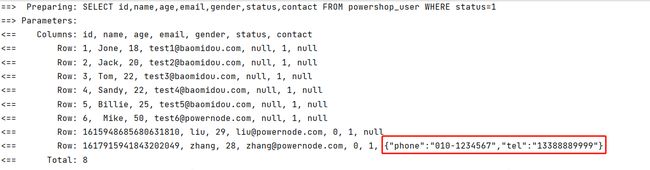
【6】测试查询操作,通过结果发现,从数据库中查询出来的数据,已经被转到Map集合
@Testvoid typeHandlerSelect(){
List users = userMapper.selectList(null);
System._out_.println(users);
}
5.4 自动填充功能
在项目中有一些属性,如果我们不希望每次都填充的话,我们可以设置为自动填充,比如常见的时间,创建时间和更新时间可以设置为自动填充。
【1】在数据库的表中添加两个字段

注意只有设置了下划线和小驼峰映射,这种mysql的写法才能和实体类完成映射

【2】在实体类中,添加对应字段,并为需要自动填充的属性指定填充时机
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName(autoResultMap = true)public class User extends Model {
@TableId
private Long id;
private String name;
private Integer age;
private String email;
private Integer status;
private GenderEnum gender;
@TableField(typeHandler = FastjsonTypeHandler.class)
private Map
** **@TableField(fill = FieldFill.INSERT)
private Date createTime;
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
}
【3】编写自动填充处理器,指定填充策略
@Componentpublic class MyMetaHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
setFieldValByName("createTime",new Date(),metaObject);
setFieldValByName("updateTime",new Date(),metaObject);
}
@Override
public void updateFill(MetaObject metaObject) {
setFieldValByName("updateTime",new Date(),metaObject);
}
}
【4】这里在插入前先设置一下mysql时区

通过查看发现,目前时区时间正常
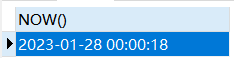
【5】再将配置文件的时区修改为serverTimezone=Asia/Shanghai

【6】测试插入操作
@Testvoid testFill(){
User user = new User();
user.setName("wang");
user.setAge(35);
user.setEmail("[email protected]");
user.setGender(GenderEnum._MAN_);
user.setStatus(1);
HashMap contact = new HashMap<>();
contact.put("phone","010-1234567");
contact.put("tel","13388889999");
userMapper.insert(user);
}
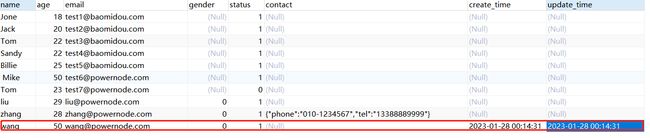
【7】测试更新操作
@Testvoid testFill2(){
User user = new User();
user.setId(6L);
user.setName("wang");
user.setAge(35);
user.setEmail("[email protected]");
user.setGender(GenderEnum._MAN_);
user.setStatus(1);
HashMap contact = new HashMap<>();
contact.put("phone","010-1234567");
contact.put("tel","13388889999");
userMapper.updateById(user);
}

5.5 防全表更新与删除插件
在实际开发中,全表更新和删除是非常危险的操作,在MybatisPlus中,提供了插件和防止这种危险操作的发生
先演示一下全表更新的场景
@Testpublic void testUpdateAll(){
User user = new User();
user.setGender(GenderEnum._MAN_);
userService.saveOrUpdate(user,null);
}

这是很危险的
如何解决呢?
注入MybatisPlusInterceptor类,并配置BlockAttackInnerInterceptor拦截器
@Configurationpublic class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType._MYSQL_));
interceptor.addInnerInterceptor(new BlockAttackInnerInterceptor());
return interceptor;
}
}
测试全表更新,会出现抛出异常,防止了全表更新
@SpringBootTestpublic class QueryTest {
@Autowired
private UserService userService;
@Testvoid allUpdate(){
User user = new User();
user.setId(999L);
user.setName("wang");
user.setEmail("[email protected]");
userService.saveOrUpdate(user,null);
}
}
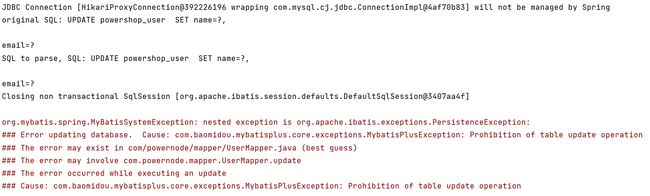
5.6 MybatisX快速开发插件
5.6.1 安装
MybatisX是一款IDEA提供的插件,目的是为了我们简化Mybatis以及MybatisPlus框架而生。
我们来看一下,如何在IDEA中安装插件
【1】首先选择File -> Settings
【2】选择Plugins
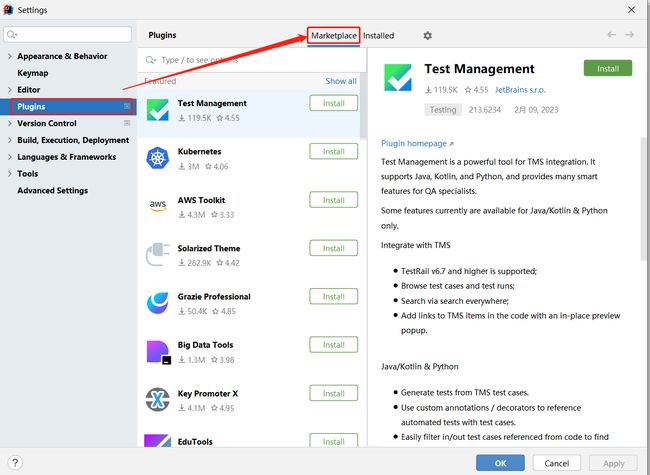
【3】搜索MybatisX,点击安装
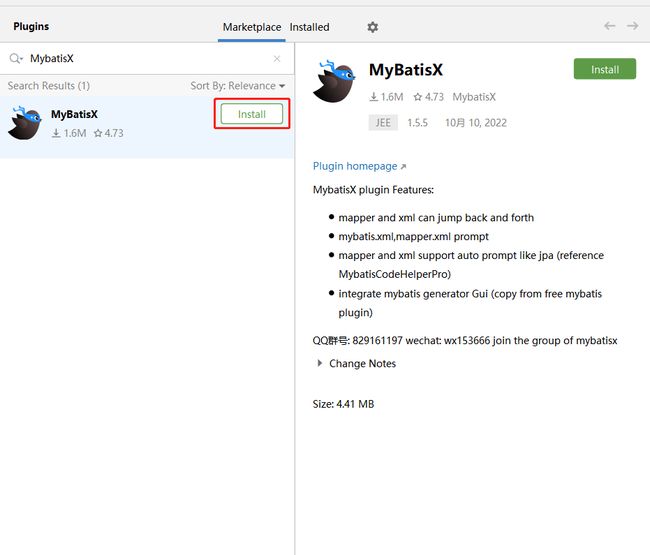
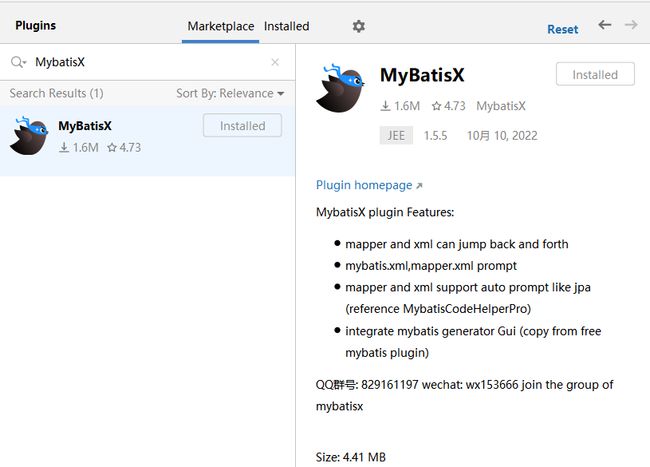
【4】这种效果就是安装完毕了
【5】在已安装的目录下,我们可以看到有了这个IDEA插件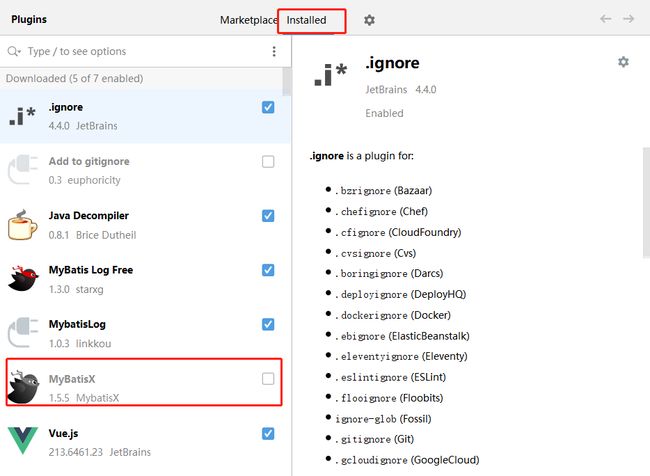
【6】此时我们勾选他,表示启用

【7】重启IDEA,让该插件生效,至此MybatisX插件就安装完毕了
5.6.2 功能
插件安装好以后,我们来看一下插件的功能
1、Mapper接口和映射文件的跳转功能
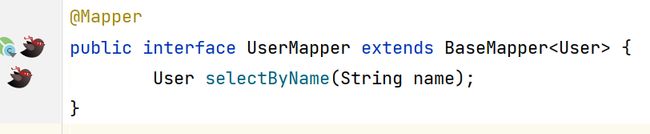
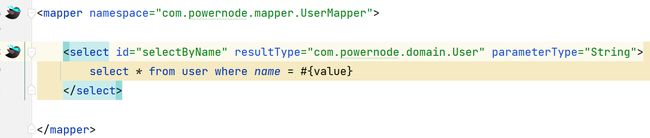
2、逆向工程
逆向工程就是通过数据库表结构,逆向产生Java工程的结构
包括以下几点:
(1)实体类
(2)Mapper接口
(3)Mapper映射文件
(4)Service接口
(5)Service实现类
在这里我们创建一个模块,用于测试逆向工程功能
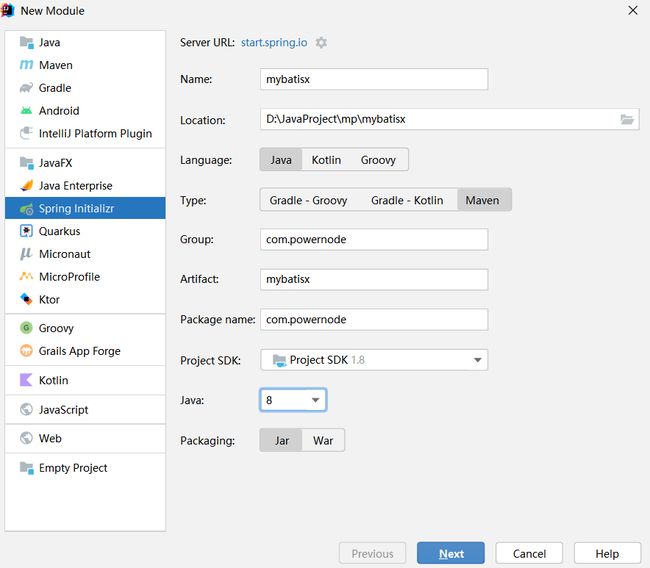
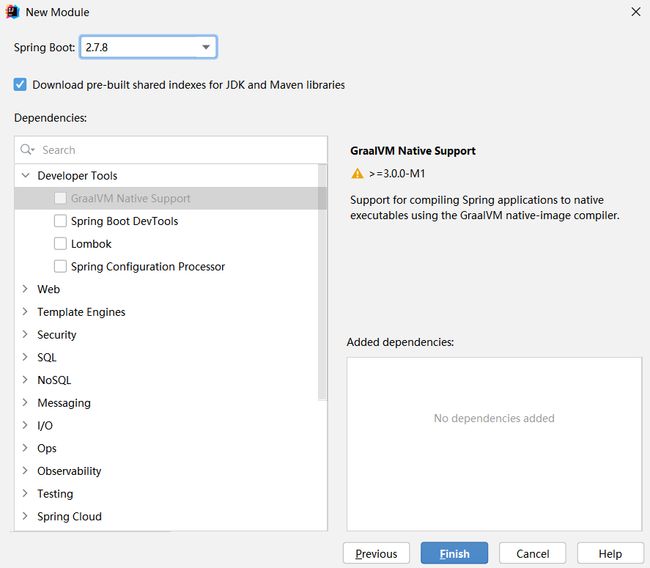
引入依赖,和编写对应的配置文件信息
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-test
test
mysql
mysql-connector-java
8.0.31
com.alibaba
druid
1.2.8
com.baomidou
mybatis-plus-boot-starter
3.5.3
org.projectlombok
lombok
org.springframework.boot
spring-boot-starter-web
spring:
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/mybatisplus?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
【1】首先使用IDEA连接mysql
【2】填写连接信息,测试连接通过

【3】找到表右键,选择插件的逆向工程选项

【4】编写逆向工程配置信息
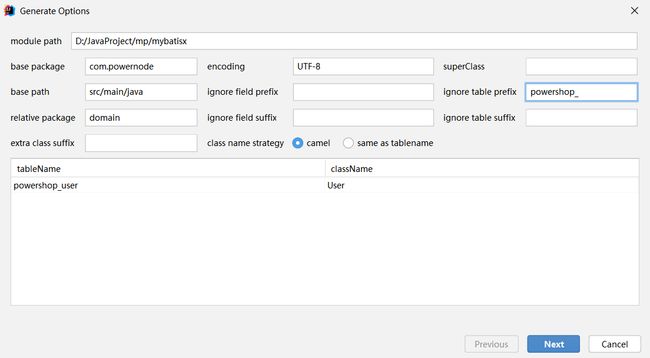
【5】编写生成信息
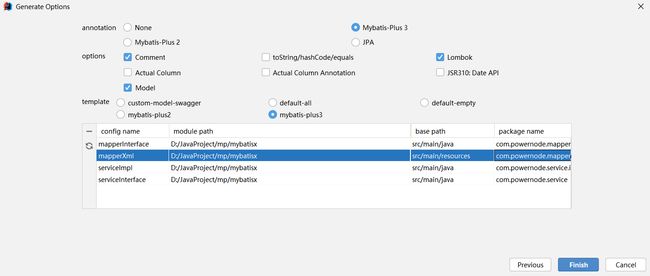
【6】观察生成结构,发现下面这些内容都已产生
(1)实体类
(2)Mapper接口
(3)Mapper映射文件
(4)Service接口
(5)Service映射文件
【7】接下来我们在Mapper接口上添加@Mapper注解
@Mapperpublic interface UserMapper extends BaseMapper {
}
【8】测试代码环境

- 常见需求代码生成
虽然Mapper接口中提供了一些常见方法,我们可以直接使用这些常见的方法来完成sql操作,但是对于实际场景中各种复杂的操作需求来说,依然是不够用的,所以MybatisX提供了更多的方法,以及可以根据这些方法直接生成对应的sql语句,这样使得开发变得更加的简单。
可以根据名称联想常见的操作
@Mapperpublic interface UserMapper extends BaseMapper {
**//添加操作
**int insertSelective(User user);
**//删除操作
**int deleteByNameAndAge(@Param("name") String name, @Param("age") Integer age);
**//修改操作
**int updateNameByAge(@Param("name") String name, @Param("age") Integer age);
**//查询操作
**List selectAllByAgeBetween(@Param("beginAge") Integer beginAge, @Param("endAge") Integer endAge);
}
在映射配置文件中,会生成对应的sql,并不需要我们编写
insert into powershop_user
id,
name,
age,
email,
values
#{id,jdbcType=BIGINT},
#{name,jdbcType=VARCHAR},
#{age,jdbcType=INTEGER},
#{email,jdbcType=VARCHAR},
delete
from powershop_user
where name = #{name,jdbcType=VARCHAR}
AND age = #{age,jdbcType=NUMERIC}
update powershop_user
set name = #{name,jdbcType=VARCHAR}
where age = #{age,jdbcType=NUMERIC}
5.7 乐观锁
首先我们先要了解开发中的一个常见场景,叫做并发请求。并发请求就是在同一时刻有多个请求同时请求服务器资源,如果是获取信息,没什么问题,但是如果是对于信息做修改操作呢,那就会出现问题。
这里举一个具体的例子,比如目前商品的库存只剩余1件了,这个时候有多个用户都想要购买这件商品,都发起了购买商品的请求,那么能让这多个用户都购买到么,肯定是不行的,因为多个用户都买到了这件商品,那么就会出现超卖问题,库存不够是没法发货的。所以在开发中就要解决这种超卖的问题
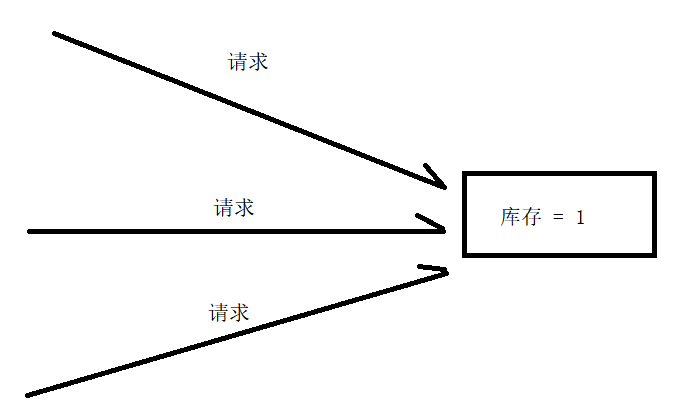
抛开超卖这一种场景,诸如此类并发访问的场景非常多,这类场景的核心问题就是,一个
请求在执行的过程中,其他请求不能改变数据,如果是一次完整的请求,在该请求的过程中其他请求没有对于这个数据产生修改操作,那么这个请求是能够正常修改数据的。如果该请求在改变数据的过程中,已经有其他请求改变了数据,那该请求就不去改变这条数据了。
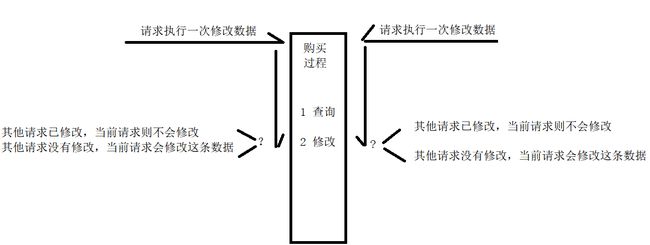
想要解决这类问题,最常见的就是加锁的思想,锁可以用验证在请求的执行过程中,是否有数据发生改变。
常见的数据库锁类型有两种,悲观锁和乐观锁。
一次完成的修改操作是,先查询数据,然后修改数据。
悲观锁:悲观锁是在查询的时候就锁定数据,在这次请求未完成之前,不会释放锁。等到这次请求完毕以后,再释放锁,释放了锁以后,其他请求才可以对于这条数据完成读写
这样做的操作能够保证读取到的信息就是当前的信息,保证了信息的正确性,但是并发效率很低,在实际开发中使用悲观锁的场景很少,因为在并发时我们是要保证效率的。
乐观锁:乐观锁是通过表字段完成设计的,他的核心思想是,在读取的时候不加锁,其他请求依然可以读取到这个数据,在修改的时候判断一个数据是否有被修改过,如果有被修改过,那本次请求的修改操作失效。
具体的通过sql是这样实现的
Update 表 set 字段 = 新值,version = version + 1 where version = 1
这样做的操作是不会对于数据读取产生影响,并发的效率较高。但是可能目前看到的数据并不是真实信息数据,是被修改之前的,但是在很多场景下是可以容忍的,并不是产生很大影响,例如很多时候我们看到的是有库存,或者都加入到购物车了,但是点进去以后库存没有了。
接下来我们来看一下乐观锁的使用
【1】在数据库表中添加一个字段version,表示版本,默认值是1

生成后的效果
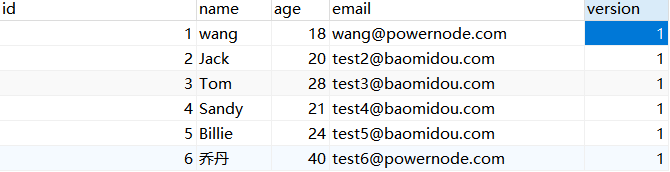
【2】找到实体类,添加对应的属性,并使用@Version标注为这是一个乐观锁字段信息
@Data
@NoArgsConstructor
@AllArgsConstructorpublic class User {
private Long id;
private String name;
private Integer age;
private String email;
@Version
private Integer version;
}
【3】因为要对每条修改语句完成语句的增强,这里我们通过拦截器的配置,让每条修改的sql语句在执行的时候,都加上版本控制的功能
@Configurationpublic class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
}
【4】测试效果,这里我们模拟先查询,再修改
@Testvoid updateTest(){
User user = userMapper.selectById(6L);
user.setName("li");
userMapper.updateById(user);
}
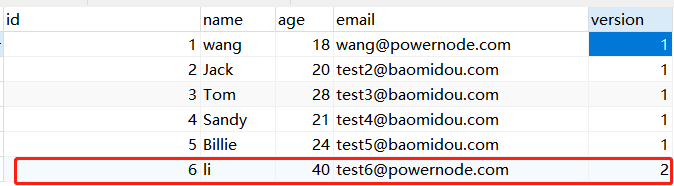
我们通过查看拼接好的SQL语句发现,查询时将User的数据查询出来,是包含version版本信息的

当我们完成修改时,他会将版本号 + 1

此时查看数据发现,更改姓名后,version已经为2了
接下来我们模拟一下,当出现多个修改请求的时候,是否能够做到乐观锁的效果。
乐观锁的效果是,一个请求在修改的过程中,是允许另一个请求查询的,但是修改时会通过版本号是否改变来决定是否修改,如果版本号变了,证明已经有请求修改过数据了,那这次修改不生效,如果版本号没有发生变化,那就完成修改。
@Testvoid updateTest2(){
**//模拟操作1的查询操作
**User user1 = userMapper.selectById(6L);
**//模拟操作2的查询操作
**User user2 = userMapper.selectById(6L);
**//模拟操作2的修改操作
**user2.setName("lisi");
userMapper.updateById(user2);
**//模拟操作1的修改操作
**user1.setName("zhangsan");
userMapper.updateById(user1);
}
我们来看下这段代码的执行过程,这段代码其实是两次操作,只不过操作1在执行的过程中,有操作2完成了对于数据的修改,这时操作1就无法再次进行修改了
操作1的查询:此时版本为2

操作2的查询:此时版本为2

操作2的修改:此时检查版本,版本没有变化,所以完成修改,并将版本改为3

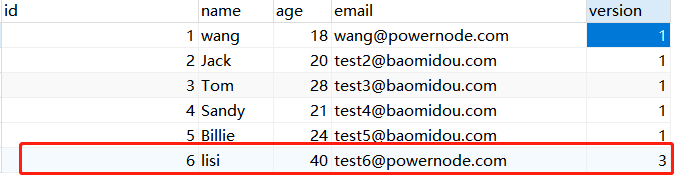
操作1的修改:此时检查版本,版本已经有最初获取的版本信息发生了变化,所以杜绝修改

5.8 代码生成器
代码生成器和逆向工程的区别在于,代码生成器可以生成更多的结构,更多的内容,允许我们能够配置生成的选项更多。在这里我们演示一下代码生成器的用法。
【1】参考官网,使用代码生成器需要引入两个依赖
****
com.baomidou
mybatis-plus-generator
3.5.3
****
org.freemarker
freemarker
2.3.31
【2】编写代码生成器代码
@SpringBootTestclass GeneratorApplicationTests {
public static void main(String[] args) {
FastAutoGenerator._create_("jdbc:mysql://localhost:3306/mybatisplus?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false", "root", "root")
.globalConfig(builder -> {
builder.author("powernode") **// 设置作者
//.enableSwagger() // 开启 swagger 模式
**.fileOverride() **// 覆盖已生成文件
**.outputDir("D://"); **// 指定输出目录
**})
.packageConfig(builder -> {
builder.parent("com.powernode") **// 设置父包名
**.moduleName("mybatisplus") **// 设置父包模块名
**.pathInfo(Collections._singletonMap_(OutputFile._xml_, "D://")); **// 设置mapperXml生成路径
**})
.strategyConfig(builder -> {
builder.addInclude("powershop_user") **// 设置需要生成的表名
**.addTablePrefix("powershop"); **// 设置过滤表前缀
**})
.templateEngine(new FreemarkerTemplateEngine()) **// 使用Freemarker引擎模板,默认的是Velocity引擎模板
**.execute();
}
}
【3】执行,查看生成效果
5.9 执行SQL分析打印
在我们日常开发工作当中,避免不了查看当前程序所执行的SQL语句,以及了解它的执行时间,方便分析是否出现了慢SQL问题。我们可以使用MybatisPlus提供的SQL分析打印的功能,来获取SQL语句执行的时间。
【1】由于该功能依赖于p6spy组件,所以需要在pom.xml中先引入该组件
p6spy
p6spy
3.9.1
【2】在application.yml中进行配置
将驱动和url修改
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:mysql
【3】在resources下,创建 spy.properties配置文件
3.2.1以上使用
modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory
自定义日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志输出到控制台
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
使用日志系统记录 sql
#appender=com.p6spy.engine.spy.appender.Slf4JLogger
设置 p6spy driver 代理
deregisterdrivers=true
取消JDBC URL前缀
useprefix=true
配置记录 Log 例外,可去掉的结果集error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,commit,resultset
日期格式
dateformat=yyyy-MM-dd HH:mm:ss
实际驱动可多个
#driverlist=org.h2.Driver
是否开启慢SQL记录
outagedetection=true
慢SQL记录标准 2 秒
outagedetectioninterval=2
【4】测试
执行查询所有的操作,可以看到sql语句的执行时间

5.10 多数据源
在学习多数据源之前,我们先来了解一下分库分表
当一个项目的数据库的数据十分庞大时,在完成SQL操作的时候,需要检索的数据就会更多,我们会遇到性能问题,会出现SQL执行效率低的问题。
针对这个问题,我们的解决方案是,将一个数据库中的数据,拆分到多个数据库中,从而减少单个数据库的数据量,从分摊访问请求的压力和减少单个数据库数据量这两个方面,都提升了效率。
我们来演示一下,在MybatisPlus中,如何演示数据源切换的效果
【1】先创建一个新的模块,将之前模块中的内容复制过来
结构如下
【2】引入依赖
com.baomidou
dynamic-datasource-spring-boot-starter
3.1.0
【3】创建新的数据库,提供多数据源环境
数据库
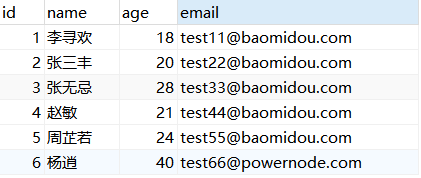
表数据
【4】编写配置文件,指定多数据源信息
spring:
datasource:
dynamic:
primary: master
strict: false
datasource:
master:
username: root
password: root
url: jdbc:mysql://localhost:3306/mybatisplus?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
slave_1:
username: root
password: root
url: jdbc:mysql://localhost:3306/mybatisplus2?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
【5】创建多个Service,分别使用@DS注解描述不同的数据源信息
@Service
@DS("master")public class UserServiceImpl extends ServiceImpl implements UserService {
}
@Service
@DS("slave_1")public class UserServiceImpl2 extends ServiceImpl implements UserService{
}
【6】测试service多数据源环境执行结果
@SpringBootTestclass Mp03ApplicationTests {
@Autowired
private UserServiceImpl userServiceImpl;
@Autowired
private UserServiceImpl2 userServiceImpl2;
@Test
public void select(){
User user = userServiceImpl.getById(1L);
System._out_.println(user);
}
@Test
public void select2(){
User user = userServiceImpl2.getById(1L);
System._out_.println(user);
}
}
【7】观察测试结果,发现结果可以从两个数据源中获取