【腾讯云 Finops Crane 集训营】Finops Crane-英雄之剑
形势所迫
随着云原生技术的不断发展,越来越多的企业选择将应用程序部署在云上或自建的 Kubernetes 集群上。然而,许多研究表明,大多数用户的集群资源利用率并不高,存在严重的浪费现象。为了解决这个问题,本次集训营的实验通过实例快速搭建一个 Kubernetes+Crane 环境,并介绍如何利用 Crane 优化你的集群和应用程序。通过本次实验,可学习到如何最大化地利用你的集群资源,提高应用程序的性能和可靠性,从而为你的企业带来更高的价值和竞争力。无论是初学者还是有经验的 Kubernetes 用户,本次实验中学习的技术知识和实践经验,能帮助我们更好地应对云原生时代的挑战,只要应用得当,它就像英雄手中的宝剑,无往不利,真正做到了当下流行的“控本增效”四字策略。
酝酿已久
Kubernetes是用于自动部署、扩展和管理“容器化应用程序”的开源系统。该系统由Google设计并捐赠给Cloud Native Computing Foundation来使用。 它旨在提供“跨主机集群的自动部署、扩展以及运行应用程序容器的平台”。 它支持一系列容器工具,包括Docker等。
FinOps Crane
首先逐个拆解,FinOps,Financial Operations,即是一种新兴的管理方法,旨在帮助IT企业更好地管理云计算成本。它强调将云计算成本视为业务成本,而不是IT成本,并通过实时监控和分析云计算成本,帮助企业更好地了解其云计算成本结构和趋势,并制定相应的成本优化策略。FinOps的实践需要财务、运营和技术团队之间的密切合作,通过协同工作,企业可以更好地管理云计算成本,提高业务效率和竞争力。
而Crane 是一个基于 FinOps 的云资源分析与成本优化平台。它的愿景是在保证客户应用运行质量的前提下实现极致的降本。它本身也是一种云成本管理工具。与 Kubernetes /其他工具集成之后就是一种容器编排的开源工具。
宝剑出世
Crane整体功能:
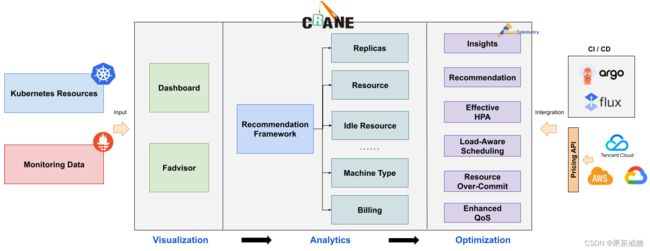
Crane与K8s相辅相成,它们的关系就好像一文一武的组合,能发挥出1+1>2的效果。
k8s虽然功能强大,但是其缺点也非常的明显,那就是部署和维护成本高;资源消耗高,影响性能;
过于复杂导致各种各样的错误和故障。而Crane的加入,就像是围棋界的神之一手,弥补了其缺点,并简化了管理的工作,使得技术或业务人员能更好的上手,将更多的精力从维护中解放出来,去做更有意义的事。
成本可视化和优化评估
可视化的仪表板,我们可以直观地了解多个云平台上的成本和使用情况。通过多维度的成本洞察,优化评估。通过 Cloud Provider 支持多云计费。
推荐框架
提供了一个可扩展的推荐框架以支持多种云资源的分析,内置了多种推荐器:资源推荐,副本推荐,HPA 推荐,闲置资源推荐。
多云管理
Crane 可以管理多个云平台的账户和资源,再也不用因为在多个云厂商都有部署而徒增不必要烦恼。它为我们提供一站式的云成本管理解决方案。一个平台实现所有的云服务的管理,主打的就是一个人性化。
基于预测的水平弹性器
EffectiveHorizontalPodAutoscaler 支持了预测驱动的弹性。它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,观测,周期),让弹性更加高效,并保障了服务的质量。
负载感知的调度器
动态调度器根据实际的节点利用率构建了一个简单但高效的模型,并过滤掉那些负载高的节点来平衡集群。
拓扑感知的调度器
Crane Scheduler与Crane Agent配合工作,支持更为精细化的资源拓扑感知调度和多种绑核策略,可解决复杂场景下“吵闹的邻居问题",使得资源得到更合理高效的利用。
基于 QOS 的混部
Crane 可以自动识别并优化云环境中的资源和服务,以降低成本并提高效率。它可以根据实际使用情况自动调整计算资源的规模,如果有的服务的资源占比需求较大,它就会自动去调整资源增加,从而确保我们服务器达到最佳性能和最低成本的一个奇妙的平衡和奇点,实现最优的效率。
极致剑身,浑然一体
整体架构如下:
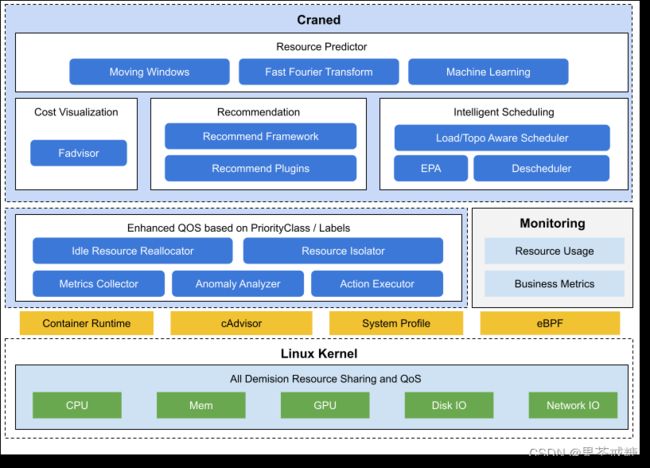
Craned
Craned 是 Crane 的最核心组件,它管理了 CRDs 的生命周期以及API。Craned 通过 Deployment 方式部署且由两个容器组成:
- Craned: 运行了 Operators 用来管理 CRDs,向 Dashboard 提供了 WebApi,Predictors 提供了 TimeSeries API
- Dashboard: 基于 TDesign’s Starter 脚手架研发的前端项目,提供了易于上手的产品功能
Fadvisor
Fadvisor 提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。Fadvisor 通过 Cloud Provider 支持了多云计费的 API。
Metric Adapter
Metric Adapter 实现了一个 Custom Metric Apiserver. Metric Adapter 读取 CRDs 信息并提供基于 Custom/External Metric API 的 HPA Metric 的数据。
Crane Agent
Crane Agent 通过 DaemonSet 部署在集群的节点上。
初露锋芒
实验步骤
实验准备步骤 (课前准备)
安装 kubectl
请参考官方文档依据你的本地环境系统参考对应的文档安装
kubectl参考文档
安装 Helm
请参考官方文档依据你的本地环境系统参考对应的文档安装
Helm参考文档
安装 kind
请参考官方文档依据你的本地环境系统参考对应的文档安装
kind参考文档
安装 Docker
请参考官方文档依据你的本地环境系统参考对应的文档安装
docker参考文档
本地安装 Crane
安装本地的 Kind 集群和 Crane 组件
以下命令将安装 Crane 以及其依赖 (Prometheus/Grafana).
curl -sf https://raw.githubusercontent.com/gocrane/crane/main/hack/local-env-setup.sh | sh -
如果上面安装命令报网络错误,可以用本地的安装包执行安装,在命令行中执行以下安装命令:
# 必须在 installation 的上级目录例如:我们预设好的 training 跟目录中执行
# Mac/Linux
bash installation/local-env-setup.sh
# Windows
./installation/local-env-setup.sh
确保所有 Pod 都正常运行:
$ export KUBECONFIG=${HOME}/.kube/config_crane
$ kubectl get pod -n crane-system
NAME READY STATUS RESTARTS AGE
craned-6dcc5c569f-vnfsf 2/2 Running 0 4m41s
fadvisor-5b685f4cd6-xpxzq 1/1 Running 0 4m37s
grafana-64656f6d54-6l24j 1/1 Running 0 4m46s
metric-adapter-967c6d57f-swhfv 1/1 Running 0 4m41s
prometheus-kube-state-metrics-7f9d78cffc-p8l7c 1/1 Running 0 4m46s
prometheus-server-fb944f4b7-4qqlv 2/2 Running 0 4m46s
提示:Pod 的启动需要一定的时间,等几分钟后输入命令查看后集群状态是否都 Running
访问 Crane Dashboard
kubectl -n crane-system port-forward service/craned 9090:9090
# 后续的终端操作请在新窗口操作,每一个新窗口操作前请把配置环境变量加上(不然会出现8080端口被拒绝的提示)
export KUBECONFIG=${HOME}/.kube/config_crane
访问 Crane Dashboard
添加本地集群:
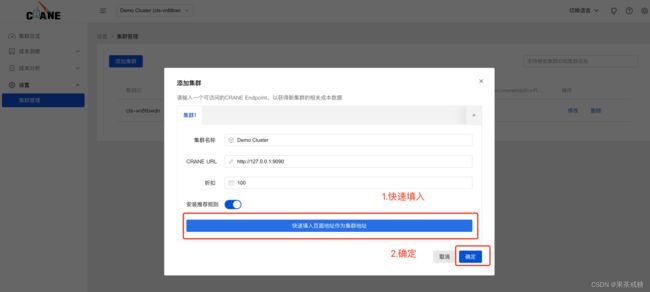
使用智能弹性 EffectiveHPA
Kubernetes HPA 支持了丰富的弹性扩展能力,Kubernetes 平台开发者部署服务实现自定义 Metric 的服务,Kubernetes 用户配置多项内置的资源指标或者自定义 Metric 指标实现自定义水平弹性。
EffectiveHorizontalPodAutoscaler(简称 EHPA)是 Crane 提供的弹性伸缩产品,它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,观测,周期),让弹性更加高效,并保障了服务的质量。
- 提前扩容,保证服务质量:通过算法预测未来的流量洪峰提前扩容,避免扩容不及时导致的雪崩和- 服务稳定性故障。
- 减少无效缩容:通过预测未来可减少不必要的缩容,稳定工作负载的资源使用率,消除突刺误判。
- 支持 Cron 配置:支持 Cron-based 弹性配置,应对大促等异常流量洪峰。
- 兼容社区:使用社区 HPA 作为弹性控制的执行层,能力完全兼容社区。
安装Metrics Server
用以下命令安装 Metrics Server:
kubectl apply -f installation/components.yaml
kubectl get pod -n kube-system
创建测试应用
用以下命令启动一个 Deployment 用 hpa-example 镜像运行一个容器, 然后将其暴露为一个 服务(Service):
kubectl apply -f installation/php-apache.yaml
kubectl apply -f installation/nginx-deployment.yaml
创建 EffectiveHPA
kubectl apply -f installation/effective-hpa.yaml
运行以下命令查看 EffectiveHPA 的当前状态:
kubectl get ehpa
输出类似于:
NAME STRATEGY MINPODS MAXPODS SPECIFICPODS REPLICAS AGE
php-apache Auto 1 10 0 3m39s
增加负载
# 在单独的终端中运行它
# 如果你是新创建请配置环境变量
export KUBECONFIG=${HOME}/.kube/config_crane
# 以便负载生成继续,你可以继续执行其余步骤
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
现在执行:
# 准备好后按 Ctrl+C 结束观察
# 如果你是新创建请配置环境变量
export KUBECONFIG=${HOME}/.kube/config_crane
kubectl get hpa ehpa-php-apache --watch
随着请求增多,CPU利用率会不断提升,可以看到 EffectiveHPA 会自动扩容实例。
说明:预测数据需要两天以上的监控数据才能出现。
集群总览
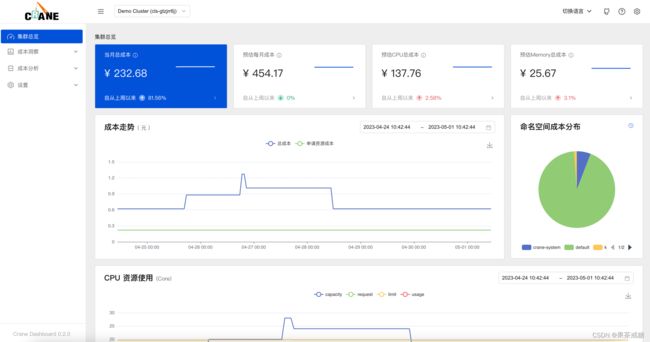
成本洞察->集群总览
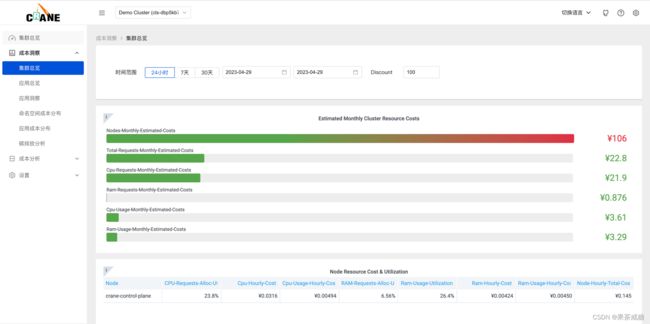
成本洞察->集群总览
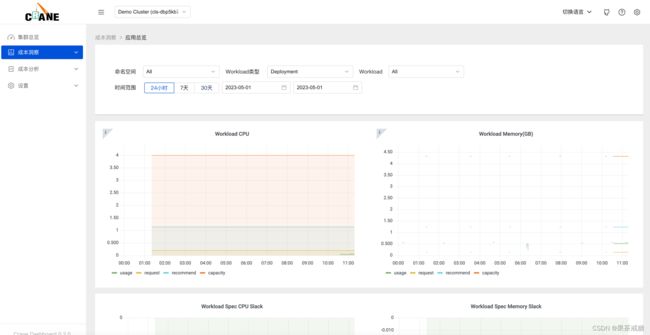
更多的成本分析图表可以通过登陆 Grafana 的页面或者分析源码研究。
登陆 Grafana 的方式可以通过以下命令建立一个 port-mapping:
# 如果你是新创建请配置环境变量
export KUBECONFIG=${HOME}/.kube/config_crane
kubectl -n crane-system port-forward service/grafana 8082:8082
访问本地 Grafana(账号密码:admin/admin): http://127.0.0.1:8082/grafana/login
日趋锋利
在 dashboard 中开箱后就可以看到相关的成本数据,是因为在添加集群的时候我们安装了推荐的规则。
推荐框架会自动分析集群的各种资源的运行情况并给出优化建议。Crane 的推荐模块会定期检测发现集群资源配置的问题,并给出优化建议。智能推荐提供了多种 Recommender 来实现面向不同资源的优化推荐。
在页面可以看到我们安装的两个推荐规则。成本分析>推荐规则
这些推荐规则实际上在将 K8s 集群接入Dashboard时安装上的 RecommendationRule CRD 对象:
$ kubectl get RecommendationRule
NAME RUNINTERVAL AGE
idlenodes-rule 24h 16m
workloads-rule 24h 16m
workloads-rule 这个推荐规则的资源对象如下所示:
apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
metadata:
name: workloads-rule
labels:
analysis.crane.io/recommendation-rule-preinstall: "true"
spec:
resourceSelectors:
- kind: Deployment
apiVersion: apps/v1
- kind: StatefulSet
apiVersion: apps/v1
namespaceSelector:
any: true
runInterval: 24h
recommenders:
- name: Replicas
- name: Resource
RecommendationRule 是一个集群维度的对象,该推荐规则会对所有命名空间中的 Deployments 和 StatefulSets 做资源推荐和副本数推荐。相关规范属性如下所示:
- 每隔 24 小时运行一次分析推荐,runInterval 格式为时间间隔,比如: 1h,1m,设置为空表示只运行一次。
- 待分析的资源通过配置 resourceSelectors 数组设置,每个 resourceSelector 通过 kind、apiVersion、name 选择 K8s 中的资源,当不指定 name 时表示在 namespaceSelector 基础上的所有资源。
- namespaceSelector 定义了待分析资源的命名空间,any: true 表示选择所有命名空间。
- recommenders 定义了待分析的资源需要通过哪些 Recommender 进行分析。目前支持两种 Recommender:
1.资源推荐(Resource): 通过 VPA 算法分析应用的真实用量推荐更合适的资源配置
2.副本数推荐(Replicas): 通过 HPA 算法分析应用的真实用量推荐更合适的副本数量
资源推荐
Kubernetes 用户在创建应用资源时常常是基于经验值来设置 request 和 limit,通过资源推荐的算法分析应用的真实用量推荐更合适的资源配置,你可以参考并采纳它提升集群的资源利用率。该推荐算法模型采用了 VPA 的滑动窗口(Moving Window)算法进行推荐:
- 通过监控数据,获取 Workload 过去一周(可配置)的 CPU 和内存的历史用量。
- 算法考虑数据的时效性,较新的数据采样点会拥有更高的权重。
- CPU 推荐值基于用户设置的目标百分位值计算,内存推荐值基于历史数据的最大值。
副本数推荐
Kubernetes 用户在创建应用资源时常常是基于经验值来设置副本数。通过副本数推荐的算法分析应用的真实用量推荐更合适的副本配置,同样可以参考并采纳它提升集群的资源利用率。其实现的基本算法是基于工作负载历史 CPU 负载,找到过去七天内每小时负载最低的 CPU 用量,计算按 50%(可配置)利用率和工作负载 CPU Request 应配置的副本数。
推荐配置
当我们部署 crane 的时候会在同一个命名空间中创建一个名为 recommendation-configuration 的 ConfigMap 对象,包含一个 yaml 格式的 RecommendationConfiguration,该配置订阅了 recommender 的配置,如下所示:
$ kubectl get cm recommendation-configuration -n crane-system -oyaml
apiVersion: v1
data:
config.yaml: |-
apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationConfiguration
recommenders:
- name: Replicas # 副本数推荐
acceptedResources:
- kind: Deployment
apiVersion: apps/v1
- kind: StatefulSet
apiVersion: apps/v1
- name: Resource # 资源推荐
acceptedResources:
- kind: Deployment
apiVersion: apps/v1
- kind: StatefulSet
apiVersion: apps/v1
kind: ConfigMap
metadata:
name: recommendation-configuration
namespace: crane-system
需要注意的是资源类型和 recommenders 需要可以匹配,比如 Resource 推荐默认只支持 Deployments 和 StatefulSets。
同样的也可以再查看一次闲置节点推荐规则的资源对象,如下所示:
$ kubectl get recommendationrule idlenodes-rule -oyaml
apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
metadata:
labels:
analysis.crane.io/recommendation-rule-preinstall: "true"
name: idlenodes-rule
spec:
namespaceSelector:
any: true
recommenders:
- name: IdleNode
resourceSelectors:
- apiVersion: v1
kind: Node
runInterval: 24h
创建 RecommendationRule 配置后,RecommendationRule 控制器会根据配置定期运行推荐任务,给出优化建议生成 Recommendation 对象,然后我们可以根据优化建议 Recommendation 调整资源配置。
比如我们这里集群中已经生成了多个优化建议 Recommendation 对象。
kubectl get recommendations -A
NAME TYPE TARGETKIND TARGETNAMESPACE TARGETNAME STRATEGY PERIODSECONDS ADOPTIONTYPE AGE
workloads-rule-resource-8whzs Resource StatefulSet default nacos Once StatusAndAnnotation 34m
workloads-rule-resource-hx4cp Resource StatefulSet default redis-replicas Once StatusAndAnnotation 34m
可以随便查看任意一个优化建议对象。
$ kubectl get recommend workloads-rule-resource-g7nwp -n crane-system -oyaml
apiVersion: analysis.crane.io/v1alpha1
kind: Recommendation
metadata:
name: workloads-rule-resource-g7nwp
namespace: crane-system
spec:
adoptionType: StatusAndAnnotation
completionStrategy:
completionStrategyType: Once
targetRef:
apiVersion: apps/v1
kind: Deployment
name: fadvisor
namespace: crane-system
type: Resource
status:
action: Patch
conditions:
- lastTransitionTime: "2022-10-20T07:43:49Z"
message: Recommendation is ready
reason: RecommendationReady
status: "True"
type: Ready
currentInfo: '{"spec":{"template":{"spec":{"containers":[{"name":"fadvisor","resources":{"requests":{"cpu":"0","memory":"0"}}}]}}}}'
lastUpdateTime: "2022-10-20T07:43:49Z"
recommendedInfo: '{"spec":{"template":{"spec":{"containers":[{"name":"fadvisor","resources":{"requests":{"cpu":"114m","memory":"120586239"}}}]}}}}'
recommendedValue: |
resourceRequest:
containers:
- containerName: fadvisor
target:
cpu: 114m
memory: "120586239"
targetRef: {}
资源推荐-在 dashboard 的页面也能查看到优化建议列表
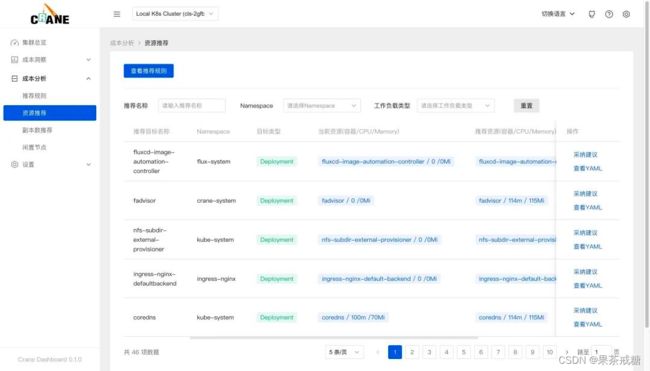
查看监控 -通过查看详细的监控数据
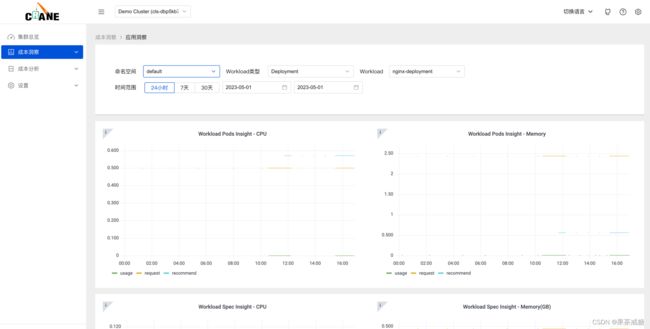
在页面中可以看到当前资源(容器/CPU/Memory)与推荐的资源数据,点击采纳建议即可获取优化的执行命令。
执行命令即可完成优化,其实就是修改资源对象的 resources 资源数据。
patchData=`kubectl get recommend workloads-rule-resource-g7nwp -n crane-system -o jsonpath='{.status.recommendedInfo}'`;kubectl patch Deployment fadvisor -n crane-system --patch "${patchData}"
对于闲置节点推荐,由于节点的下线在不同平台上的步骤不同,用户可以根据自身需求进行节点的下线或者缩容。
应用在监控系统(比如 Prometheus)中的历史数据越久,推荐结果就越准确,建议生产上超过两周时间。对新建应用的预测往往不准。
将本地的集群清理删除:
kind delete cluster --name=crane
在本文中,我们探讨了关于云原生背景下Crane的应用,并分享了从0到1的入门级操作。期望这次动手实验能帮助大家更好地理解和应用这些前沿技术和工具,不断探索和学习以提高自己的技术水平。如果将Crane作为一把宝剑,那我们就是行侠仗义的英雄。都说宝剑配英雄,唯有我们变得越来越强,Crane的强大才会更好的诠释。