LayoutLM: Pre-training of Text and Layout for Document Image Understanding
LayoutLM:文本和布局的预训练,用于理解文档图像
Yiheng Xu ∗ [email protected] Harbin Institute of Technology Minghao Li ∗ [email protected] Beihang University Lei Cui [email protected] Microsoft Research Asia Shaohan Huang [email protected] Microsoft Research Asia Furu Wei [email protected] Microsoft Research Asia Ming Zhou [email protected] Microsoft Research Asia
摘要
近年来,各种NLP任务都成功地验证了预训练技术。尽管NLP应用程序广泛使用预训练模型,但它们几乎只关注文本级操作,而忽略了对文档图像理解至关重要的布局和样式信息。在本文中,我们提出了LayoutLM来联合模型扫描文档图像中文本和布局信息之间的交互,这有利于大量真实文档图像理解任务,例如从扫描文档中提取信息。此外,我们还利用图像特征将单词的视觉信息合并到LayoutLM中。
据我们所知,这是首次在文档级预训练的单一框架中联合学习文本和布局。它在几个下游任务中取得了最新的成果,包括表单理解(从70.72到79.27)、收据理解(从94.02到95.24)和文档图像分类(从93.07到94.42)。代码和经过预训练的LayoutLM模型可在https://aka.ms/layoutlm.
CCS概念
•信息系统→ 商业智能;•计算方法学→ 信息提取;转移学习;•应用计算→ 文档分析。
关键词布局LM;预先训练的模型;文档图像理解ACM参考格式:Yiheng Xu、Minghao Li、Lei Cui、Shaohan Huang、Furu Wei和Ming Zhou。LayoutLM:文档图像理解的文本和布局预训练。《第26届ACM SIGKDD知识发现和数据挖掘会议记录》(KDD’20),2020年8月23日至27日,美国加利福尼亚州虚拟活动。ACM,美国纽约州纽约市,9页。https://doi.org/10.1145/3394486.3403172。
1引言
文档AI或文档智能1是一个相对较新的研究主题,涉及自动读取、理解和分析业务文档的技术。业务文档是提供公司内部和外部交易相关详细信息的文件,如图1所示。它们可能是数字生成的,以电子文件的形式出现,也可能是书面或打印在纸上的扫描形式。业务文档的一些常见示例包括采购订单、财务报告、业务电子邮件、销售协议、供应商合同、信函、发票、收据、简历等。业务文档对公司的效率和生产力至关重要。业务文档的确切格式可能会有所不同,但信息通常以自然语言呈现,并且可以以各种方式组织,包括纯文本、多列布局和各种表格/表格/图形。由于布局和格式的多样性、扫描文档图像的质量差以及模板结构的复杂性,理解业务文档是一项非常具有挑战性的任务。
如今,许多公司通过人工工作从业务文档中提取数据,这既耗时又昂贵,同时需要人工定制或配置。
每种类型文档的规则和工作流通常需要硬编码,并随着特定格式的更改或处理多种格式时进行更新。为了解决这些问题,文档AI模型和算法设计用于自动分类、提取和结构化业务文档中的信息,从而加速自动化文档处理工作流。
当代的文档人工智能方法通常是基于计算机视觉或自然语言处理角度的深层神经网络,或两者的组合。早期的尝试通常集中于检测和分析文档的某些部分,例如表格区域。[7] 我们首先提出了一种基于卷积神经网络(CNN)的PDF文档表检测方法。之后,[21、24、29]还利用更先进更快的R-CNN模型[19]或Mask R-CNN模型[9],进一步提高文档布局分析的准确性。此外,[28]提出了一种端到端、多模态、完全卷积的网络,用于从文档图像中提取语义结构,利用预先训练的NLP模型中的文本嵌入。
最近,[15]引入了一种基于图卷积网络(GCN)的模型,将文本和视觉信息结合起来,用于从业务文档中提取信息。虽然这些模型在使用深度神经网络的文档人工智能领域取得了重大进展,但大多数方法都面临两个局限:(1)它们依赖于少数人类标记的训练样本,而没有充分探索使用大规模未标记训练样本的可能性。(2) 他们通常利用预先训练的CV模型或NLP模型,但不考虑对文本和布局信息进行联合训练。因此,研究文本和布局的自我监督预训练如何在文档AI领域有所帮助是很重要的。
为此,我们提出了LayoutLM,这是一种简单而有效的文本和版面预训练方法,用于文档图像理解任务。受BERT模型[4]的启发,输入文本信息主要由文本嵌入和位置嵌入表示,LayoutLM进一步添加了两种类型的输入嵌入:(1)二维位置嵌入,表示token在文档中的相对位置;(2) 在文档中嵌入扫描的token图像的图像。LayoutLM的体系结构如图2所示。我们添加了这两个输入嵌入,因为二维位置嵌入可以捕获文档中tokens之间的关系,同时图像嵌入可以捕获一些外观特征,如字体方向、类型和颜色。此外,我们采用多任务学习目标进行布局LM,包括蒙面视觉语言模型(MVLM)丢失和多标签文档分类(MDC)丢失,这进一步加强了文本和布局的联合预训练。在这项工作中,我们的重点是基于扫描文档图像的文档预训练,而数字生成文档的挑战性较小,因为它们可以被视为不需要OCR的特例,因此不在本文的范围之内。具体而言,LayoutLM是在IIT-CDIP测试集合1.0 2[14]上预先训练的,其中包含600多万个扫描文档和1100万个扫描文档图像。扫描的文档有多种类别,包括信函、备忘录、电子邮件、文件夹、表单、手写、发票、广告、预算、新闻文章、演示文稿、科学出版物、问卷、简历、科学报告、规范等,非常适合大规模的自我监督预训练。我们选择三个基准数据集作为下游任务来评估预先训练好的LayoutLM模型的性能。第一个是FUNSD数据集3【10】,用于空间布局分析和形状理解。
第二个是SROIE数据集4,用于提取扫描收据信息。第三个是用于文档图像分类的RVL-CDIP数据集5[8],它由16类40万灰度图像组成。实验表明,经过预训练的LayoutLM模型在这些基准数据集上的性能明显优于几个SOTA预训练模型,显示了在文档图像理解任务中对文本和布局信息进行预训练的巨大优势。
本文的贡献总结如下:•首次在单个框架中对扫描文档图像的文本和布局信息进行预训练。还利用图像功能来实现最新的效果。
•LayoutLM使用蒙面视觉语言模型和多标签文档分类作为训练目标,这在文档图像理解任务中明显优于几个SOTA预训练模型。
•代码和预先训练的模型可在https://aka.ms/layoutlm更多下游任务。

图1:具有不同布局和格式的业务文档的扫描图像
2布局LM
在本节中,我们将简要回顾BERT模型,并介绍如何在LayoutLM框架中联合扩展模型文本和布局信息。
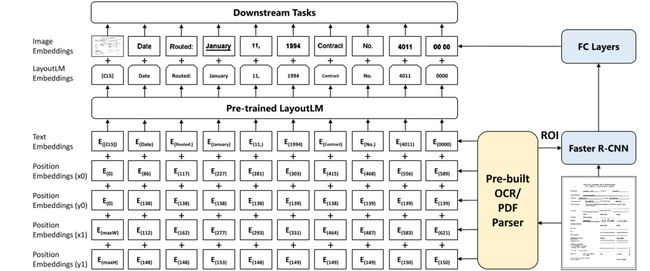
图2:LayoutLM的一个示例,其中二维布局和图像嵌入集成到原始的BERT体系结构中。更快的R-CNN的LayoutLM嵌入和图像嵌入一起用于下游任务。
2.1 BERT模型
BERT模型是一种基于注意力的双向语言建模方法。经验证,BERT模型显示了大规模训练数据下自监督任务的有效知识转移。BERT的体系结构基本上是一个多层双向Transformer编码器。它接受一系列tokens并堆叠多个层以生成最终表示。
具体地说,给定一组使用WordPiece处理的tokens,通过对相应的单词嵌入、位置嵌入和段嵌入求和来计算输入嵌入。
然后,这些输入嵌入通过多层双向Transformer传递,该Transformer可以生成具有自适应注意力机制的情境化表示。
BERT框架中有两个步骤:预训练和微调。在预训练期间,模型使用两个目标来学习语言表示:蒙面语言建模(MLM)和下一句预测(NSP),其中MLM随机屏蔽一些输入tokens,目标是恢复这些蒙面tokens,NSP是以一对句子为输入的二元分类任务,并对它们是否是两个连续的句子进行分类。在微调中,使用特定于任务的数据集以端到端的方式更新所有参数。BERT模型已成功应用于一系列自然语言处理任务中。
2.2布局LM模型
虽然类BERT模型在一些具有挑战性的NLP任务中已成为最先进的技术,但它们通常仅将文本信息用于任何类型的输入。当涉及到视觉丰富的文档时,有更多的信息可以编码到预先训练的模型中。因此,我们建议利用来自文档布局的视觉丰富信息,并将其与输入文本对齐。基本上,有两种类型的功能可以显著改善视觉丰富文档中的语言表示,它们是:文档布局信息。很明显,单词在文档中的相对位置对语义表示有很大的影响。以表单理解为例,给定表单中的一个键(例如,“Passport ID:”),其对应值更可能位于其右侧或下方,而不是左侧或上方。
因此,我们可以将这些相对位置信息嵌入为二维位置表示。基于Transformer内部的自我注意机制,将二维位置特征嵌入到语言表示中,可以更好地将布局信息与语义表示对齐。
视觉信息。与文本信息相比,视觉信息是文档表示的另一个重要特征。通常,文档包含一些视觉信号,以显示文档段的重要性和优先级。
视觉信息可以用图像特征来表示,并在文档表示中得到有效利用。对于文档级视觉特征,整个图像可以表示文档的布局,这是文档图像分类的一个基本特征。对于单词级视觉特征,粗体、下划线和斜体等样式也是序列标记任务的重要提示。因此,我们认为,将图像特征与传统的文本表示相结合,可以为文档带来更丰富的语义表示。
2.3模型架构
为了利用现有的预训练模型并适应文档图像理解任务,我们使用BERT体系结构作为主干,并添加了两个新的输入嵌入:二维位置嵌入和图像嵌入。
二维位置嵌入。与在序列中建模单词位置的位置嵌入不同,二维位置嵌入旨在模型文档中的相对空间位置。为了表示扫描文档图像中元素的空间位置,我们将文档页面视为具有左上角原点的坐标系。在此设置中,边界框可以通过![]() 精确定义,其中
精确定义,其中![]() 对应于边界框中左上角的位置,
对应于边界框中左上角的位置,![]() 表示右下角的位置。我们添加了四个位置嵌入层和两个嵌入表,其中表示相同维度的嵌入层共享相同的嵌入表。这意味着我们在嵌入表x中查找x 0和x 1的位置嵌入,并在表y中查找y 0和y 1。
表示右下角的位置。我们添加了四个位置嵌入层和两个嵌入表,其中表示相同维度的嵌入层共享相同的嵌入表。这意味着我们在嵌入表x中查找x 0和x 1的位置嵌入,并在表y中查找y 0和y 1。
图像嵌入。为了利用文档的图像特征并将图像特征与文本对齐,我们添加了一个图像嵌入层来表示语言表示中的图像特征。更详细地说,通过OCR结果中每个单词的边界框,我们将图像分割成几个部分,它们与单词有一对一的对应关系。我们使用这些来自更快的R-CNN(19)模型的图像片段生成图像区域特征,作为token图像嵌入。对于[CLS]token,我们还使用更快的R-CNN模型,使用整个扫描文档图像作为感兴趣区域(ROI)生成嵌入,以利于需要[CLS]token表示的下游任务。
2.4预训练布局
任务#1:屏蔽视觉语言模型。受蒙面语言模型的启发,我们提出了蒙面视觉语言模型(MVLM),以二维位置嵌入和文本嵌入为线索来学习语言表征。在预训练期间,我们随机mask一些输入的tokens,但保留相应的二维位置嵌入,然后对模型进行训练的以预测给定上下文的屏蔽tokens。通过这种方式,LayoutLM模型不仅理解了语言环境,而且还利用了相应的二维位置信息,从而弥合了视觉和语言模式之间的差距。
任务#2:多标签文档分类。对于文档图像理解,许多任务要求模型生成高质量的文档级表示。由于IIT-CDIP测试集合包含每个文档图像的多个标记,因此我们还在预训练阶段使用多标签文档分类(MDC)丢失。给定一组扫描的文档,我们使用文档标签来监督预训练过程,以便模型能够对来自不同领域的知识进行聚类,并生成更好的文档级表示。由于MDC丢失需要每个文档图像的标签,而这些图像可能不存在于较大的数据集中,因此在预训练期间是可选的,将来可能不会用于预训练较大的模型。我们将在第3节中比较MVLM和MVLM+MDC的性能。
2.5微调布局LM
预先训练的LayoutLM模型在三个文档图像理解任务上进行了微调,包括表单理解任务、收据理解任务以及文档图像分类任务。对于表单和收据理解任务,LayoutLM预测每个token的{B,I,E,S,O}标记,并使用顺序标签检测数据集中的每种类型的实体。对于文档图像分类任务,LayoutLM使用[CLS]token的表示来预测类标签。
3 实验
3.1预训练数据集
预训练模型的性能在很大程度上取决于数据集的规模和质量。因此,我们需要一个大规模的扫描文档图像数据集来预训练LayoutLM模型。
我们的模型经过IIT-CDIP测试集1.0的预先训练,其中包含600多万个文档,以及1100多万个扫描文档图像。此外,每个文档都有相应的文本和元数据存储在XML文件中。文本是通过对文档图像应用OCR生成的内容。元数据描述文档的属性,例如唯一标识和文档标签。虽然元数据包含错误和不一致的标记,但这个大规模数据集中的扫描文档图像非常适合对我们的模型进行预训练。
3.2微调数据集
FUNSD数据集。我们在FUNSD数据集上评估了我们在有噪声的扫描文档中进行表单理解的方法。该数据集包括199个真实、完整注释、扫描的表单,其中包含9707个语义实体和31485个单词。这些表单被组织为相互关联的语义实体列表。每个语义实体包括唯一标识符、标签(即问题、答案、标题或其他)、丰富框、与其他实体的链接列表和单词列表。数据集分为149个训练样本和50个测试样本。我们采用单词级F1分数作为评价指标。
SROIE数据集。我们还评估了SROIE数据集上的模型,以提取收据信息(任务3)。该数据集包含626份训练收据和347份测试收据。每个收据都组织为带有边框的文本行列表。每张收据都标有四种类型的实体,即{公司、日期、地址、总数}。评估指标是F1分数中实体识别结果的精确匹配。
RVL-CDIP数据集。RVL-CDIP数据集由16类400000幅灰度图像组成,每类25000幅图像。有320000张训练图像、40000张验证图像和40000张测试图像。图像已调整大小,因此其最大尺寸不超过1000像素。这16门课包括{信件、表格、电子邮件、手写、广告、科学报告、科学出版物、说明书、文件夹、新闻文章、预算、发票、演示、问卷、简历、备忘录}。评估指标是总体分类精度。
3.3文件预处理
为了利用每个文档的布局信息,我们需要获得每个token的位置。然而,预训练数据集(IIT-CDIP测试集合)只包含纯文本,而缺少相应的边界框。在这种情况下,我们重新处理扫描的文档图像以获得必要的布局信息。
与IIT-CDIP测试集合中的原始预处理一样,我们也通过将OCR应用于文档图像来处理数据集。区别在于,我们同时获得了识别出的单词及其在文档图像中的相应位置。多亏了开源OCR引擎Tesseract 6,我们可以轻松获得识别和二维位置。我们以hOCR格式存储OCR结果,hOCR格式是一种标准规范格式,它使用层次表示法明确定义了单个文档图像的OCR结果。
3.4模型预训练
我们用预先训练好的BERT基模型初始化LayoutLM模型的权重。具体来说,我们的基础模型具有相同的架构:一个12层的Transformer,768个隐藏尺寸,以及12个注意力头,其中包含约113M的参数。因此,我们使用BERT基模型初始化模型中除二维位置嵌入层之外的所有模块。对于大型设置,我们的模型有一个24层Transformer,具有1024个隐藏尺寸和16个注意力头,由预先训练的BERT大型模型初始化,包含大约343M的参数。在【4】之后,我们选择15%的输入tokens进行预测。我们在80%的时间里用[MASK]token替换这些被屏蔽的tokens,在10%的时间里用随机token替换,在10%的时间里用不变的token替换。然后,模型用交叉熵损失预测相应的token。
此外,我们还添加了具有四种嵌入表示(x 0,y 0,x 1,y 1)的二维位置嵌入层,其中(x 0,y 0)对应于边界框中左上角的位置,(x 1,y 1)表示右下角的位置。考虑到文档布局可能因页面大小而异,我们将实际坐标缩放为“虚拟”坐标:将实际坐标缩放为0到1000之间的值。此外,我们还使用ResNet-101模型作为更快的R-CNN模型的骨干网络,该模型是在视觉基因组数据集上预先训练的[12]。
我们在8个NVIDIA Tesla V100 32GB GPU上训练我们的模型,总批量为80。Adam优化器用于5e-5的初始学习率和线性衰减学习率计划。基本模型需要80小时才能在1100万个文档上完成一个历元,而大型模型需要近170小时才能完成一个历元。
3.5特定于任务的微调我们在三个文档图像理解任务上评估LayoutLM模型:表单理解、收据理解和文档图像分类。我们遵循典型的微调策略,在特定于任务的数据集上以端到端的方式更新所有参数。
形成理解。此任务需要提取表单的文本内容并对其进行结构化。它旨在从扫描的表单图像中提取键值对。更详细地说,该任务包括两个子任务:语义标记和语义链接。语义标记是将单词聚合为语义实体并为其指定预定义标签的任务。语义链接的任务是预测语义实体之间的关系。在这项工作中,我们关注语义标记任务,而语义链接超出了范围。为了微调此任务的布局LM,我们将语义标记视为序列标记问题。我们将最终表示传递到线性层,然后是softmax层,以预测每个token的标签。模型经过100个时代的训练的,批量大小为16,学习率为5e-5。
收据理解。此任务需要根据扫描的收据图像填充几个预定义的语义槽。
例如,给定一组收据,我们需要填写特定的位置(例如,公司、地址、日期和总数)。与表单理解任务不同,表单理解任务需要标记所有匹配的实体和键值对,语义槽的数量是用预定义的键固定的。因此,模型只需使用序列标记方法预测相应的值。
文档图像分类。给定一个视觉丰富的文档,此任务旨在预测每个文档图像的对应类别。与现有的基于图像的方法不同,我们的模型不仅包括图像表示,还包括使用LayoutLM中的多模式架构的文本和布局信息。
因此,我们的模型可以更有效地结合文本、布局和图像信息。为了在此任务中微调我们的模型,我们将LayoutLM模型的输出与整个图像嵌入连接起来,然后是用于类别预测的softmax层。我们对模型进行了30个时代的微调,批量大小为40,学习率为2e-5。
3.6结果
形成理解。我们在FUNSD数据集上评估表单理解任务。实验结果如表1所示。
我们将LayoutLM模型与两个SOTA预训练NLP模型进行了比较:BERT和RoBERTa【16】。BERT基本模型达到0.603,而大型模型在F1达到0.656。与BERT相比,RoBERTa在这个数据集上的表现要好得多,因为它是使用具有更多时代的更大数据进行训练的的。由于时间限制,我们为LayoutLM提供了4种设置,即500K文档页面6个时代,1M文档页面6个时代,2M文档页面6个时代,以及11M文档页面2个时代。据观察,LayoutLM模型的性能大大优于现有SOTA训练前基线。在基础架构下,具有11M训练数据的LayoutLM模型在F1中达到0.7866,远远高于参数大小相似的BERT和RoBERTa。此外,我们还在预训练步骤中添加了MDC损失,这确实为FUNSD数据集带来了实质性的改进。最后,当同时使用文本、布局和图像信息时,LayoutLM模型达到了0.7927的最佳性能。
此外,我们还使用FUNSD数据集上的不同数据和时代评估了LayoutLM模型,如表2所示。
对于不同的数据设置,我们可以看到,随着在预训练步骤中对更多的历元进行训练的,总体精确度会单调增加。此外,随着向LayoutLM模型中输入更多数据,准确性也得到了提高。由于FUNSD数据集仅包含149幅用于微调的图像,因此结果证实,文本和布局的预训练对于理解扫描文档是有效的,尤其是在资源设置较低的情况下。
此外,我们还比较了LayoutLM模型的不同初始化方法,包括from scratch、BERT和RoBERTa。
表3中的结果表明,使用RoBERTa BASE初始化的LayoutLM BASE模型在F1中的表现优于BERT BASE 2.1个百分点。
对于大型设置,使用RoBERTa LARGE初始化的LayoutLM大型模型比BERT大型模型进一步提高了1.3个点。我们将在未来以RoBERTa作为初始化对象对更多模型进行预训练,尤其是对于大型设置。
收据理解。我们使用SROIE数据集评估收据理解任务。结果如表4所示。由于我们只测试SROIE中关键信息提取任务的性能,我们希望消除错误OCR结果的影响。因此,我们使用地面真实OCR对训练数据进行预处理,并使用基线模型(BERT和RoBERTa)以及LayoutLM模型进行一组实验。
结果表明,使用11M文档图像训练的LayoutLM大型模型F1得分为0.9524,明显优于竞争排行榜第一名。
这一结果还验证了预先训练的LayoutLM不仅在域内数据集(FUNSD)上表现良好,而且在域外数据集(如SROIE)上也优于一些强基线。
文档图像分类。最后,我们使用RVL-CDIP数据集评估文档图像分类任务。文档图像不同于其他自然图像,因为文档图像中的大多数内容都是各种样式和布局的文本。传统上,具有预训练的基于图像的分类模型的性能要比基于文本的模型好得多,如表5所示。我们可以看到,BERT或RoBERTa的表现都不如基于图像的方法,这说明文本信息不足以完成这项任务,它仍然需要布局和图像特征。我们通过使用LayoutLM模型来解决这个问题。结果表明,即使没有图像特征,LayoutLM仍然优于基于图像的方法中的单个模型。在集成了图像嵌入后,LayoutLM的准确率达到94.42%,明显优于几种SOTA基线的文档图像分类。
据观察,我们的模型在“电子邮件”类别中表现最好,而在“形式”类别中表现最差。我们将进一步研究如何利用预训练的layoutlm和图像模型,以及如何在layoutlm模型的预训练步骤中包含图像信息。
表2:FUNSD数据集上不同数据和年代的LayoutLM基础(文本+布局,MVLM)精度
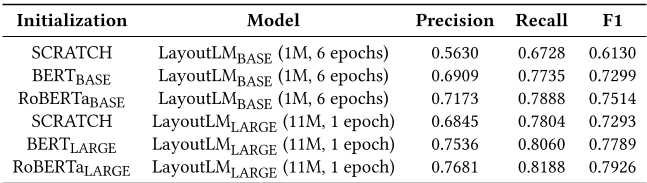
表3:BASE和LARGE的不同初始化方法(文本+布局,MVLM)
4相关工作
文档分析与识别(DAR)的研究始于20世纪90年代初。主流方法可分为三类:基于规则的方法、传统的机器学习方法和深度学习方法。
4.1基于规则的方法
基于规则的方法【6、13、18、23】包含两种类型的分析方法:自下而上和自上而下。自下而上的方法[5、13、23]通常将黑色像素的连通分量检测为文档图像中的基本计算单元,文档分割过程是通过不同的启发式算法将其组合成更高层次的结构,并根据不同的结构特征对其进行标记。Docstrum算法[18]是最早成功的基于连通成分分析的自底向上算法之一。它将极轴结构上的连接组件分组,以导出最终分段。[23]使用不同组件之间的特殊距离度量来构建物理页面结构。他们通过使用启发式和路径压缩算法进一步降低了时间复杂度。
自顶向下的方法通常递归地将页面拆分为列、块、文本行和tokens。【6】提出用所有像素中的黑色像素替换基本单元,并采用递归的X-Y切割算法对文档进行分解,建立X-Y树,使复杂文档更容易分解。尽管这些方法在某些文档上表现良好,但它们需要大量的人力来找出更好的规则,有时无法推广到其他来源的文档。因此,在DAR研究中利用机器学习方法是不可避免的。
4.2机器学习方法
随着传统机器学习的发展,统计机器学习方法在过去十年中已成为文档分割任务的主流。[22]将文档的布局信息视为解析问题,并基于基于文法的损失函数全局搜索最优解析树。他们利用机器学习方法来选择特征,并在解析过程中对所有参数进行训练。
与此同时,人工神经网络[17]已广泛应用于文档分析和识别。大多数工作都致力于识别孤立的手写和印刷字符,取得了广泛认可的成功结果。除了人工神经网络(ANN)模型外,SVM和GMM【27】也被用于文档布局分析任务。对于机器学习方法,设计手工制作的特征通常很耗时,而且很难获得高度摘要的语义上下文。此外,这些方法通常依赖于视觉线索,但忽略了文本信息。
4.3深度学习方法
近年来,深度学习方法已成为许多机器学习问题的主流和事实标准。从理论上讲,它们可以通过多层神经网络的叠加来拟合任意函数,并且在许多研究领域都被证明是有效的。【28】将文档语义结构提取任务视为逐像素分类问题。他们提出了一种考虑视觉和文本信息的多模态神经网络,而这项工作的局限性在于,他们只使用该网络来帮助启发式算法对候选边界框进行分类,而不是使用端到端的方法。【26】针对移动和云服务,提出一个轻量级的文档布局分析模型。模型使用图像的一维信息进行推理,并将其与使用二维信息的模型进行比较,在实验中达到了相当的精度。[11] 利用预测分割mask和边界框的完全卷积编码器-解码器网络,模型的性能明显优于基于连续文本或文档图像的方法。【24】将上下文信息纳入更快的R-CNN模型,该模型涉及文章内容固有的本地化性质,以提高区域检测性能。
现有的DAR深度学习方法通常面临两个局限:(1)模型通常依赖有限的标记数据,而大量未标记数据未使用。(2) 当前的深度学习模型通常利用预先训练的CV模型或NLP模型,但不考虑文本和版面的联合预先训练。LayoutLM解决了这两个限制,并与以前的基线相比实现了更好的性能。

表4:SROIE数据集上的模型准确性(精度、召回率、F1)
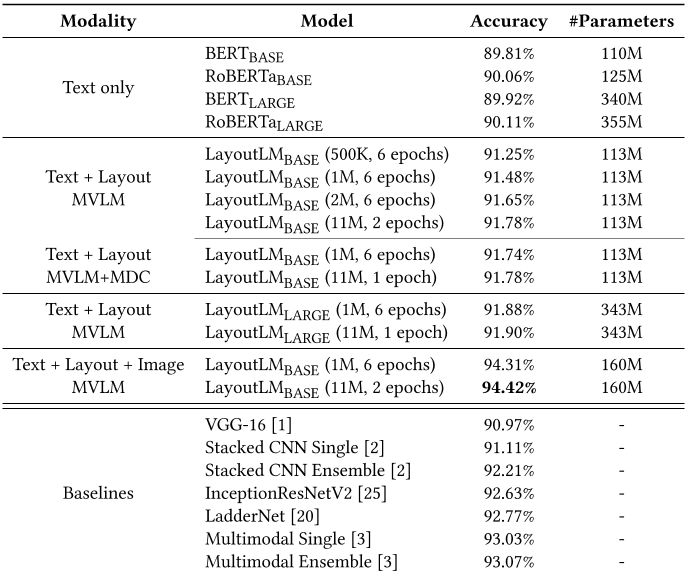
表5:RVL-CDIP数据集的分类精度
5结论和未来工作
我们介绍了LayoutLM,这是一种简单而有效的预训练技术,在单个框架中使用文本和布局信息。LayoutLM以Transformer架构为主干,利用多模式输入,包括token嵌入、布局嵌入和图像嵌入。同时,基于大规模未标记扫描文档图像,模型可以很容易地以自我监督的方式进行训练的。我们评估了LayoutLM模型的三个任务:表单理解、收据理解和扫描文档图像分类。实验表明,LayoutLM在这些任务中的表现明显优于几个SOTA预训练模型。
为了将来的研究,我们将研究具有更多数据和更多计算资源的预训练模型。此外,我们还将使用带有文本和布局的大型体系结构对LayoutLM进行训练,并在预训练步骤中嵌入图像。此外,我们还将探索新的网络架构和其他自我监督的训练目标,以进一步释放LayoutLM的威力。
参考文献
[1] Muhammad Zeshan Afzal, Andreas Kölsch, Sheraz Ahmed, and Marcus Liwicki. 2017. Cutting the Error by Half: Investigation of Very Deep CNN and Advanced Training Strategies for Document Image Classification. 2017 14th IAPR international Conference on Document Analysis and Recognition (ICDAR) 01 (2017), 883–888.
[2] Arindam Das, Saikat Roy, and Ujjwal Bhattacharya. 2018. Document Image Classification with Intra-Domain Transfer Learning and Stacked Generalization of Deep Convolutional Neural Networks. 2018 24th International Conference on Pattern Recognition (ICPR) (2018), 3180–3185.
[3] Tyler Dauphinee, Nikunj Patel, and Mohammad Mehdi Rashidi. 2019. Modular Multimodal Architecture for Document Classification. ArXiv abs/1912.04376 (2019).
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) . Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. https://doi.org/10.18653/v1/N19-1423
[5] Jaekyu Ha, Robert M Haralick, and Ihsin T Phillips. 1995. Document page decomposition by the bounding-box project. In Proceedings of 3rd International Conference on Document Analysis and Recognition , Vol. 2. IEEE, 1119–1122.
[6] Jaekyu Ha, Robert M Haralick, and Ihsin T Phillips. 1995. Recursive XY cut using bounding boxes of connected components. In Proceedings of 3rd International Conference on Document Analysis and Recognition , Vol. 2. IEEE, 952–955.
[7] Leipeng Hao, Liangcai Gao, Xiaohan Yi, and Zhi Tang. 2016. A Table Detection Method for PDF Documents Based on Convolutional Neural Networks. 2016 12th IAPR Workshop on Document Analysis Systems (DAS) (2016), 287–292.
[8] Adam W. Harley, Alex Ufkes, and Konstantinos G. Derpanis. 2015. Evaluation of deep convolutional nets for document image classification and retrieval. 2015 13th International Conference on Document Analysis and Recognition (ICDAR) (2015), 991–995.
[9] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross B. Girshick. 2017. Mask R-CNN. CoRR abs/1703.06870 (2017). arXiv:1703.06870 http://arxiv.org/abs/1703. 06870
[10] Guillaume Jaume, Hazim Kemal Ekenel, and Jean-Philippe Thiran. 2019. FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents. 2019 international Conference on Document Analysis and Recognition Workshops (ICDARW) 2 (2019), 1–6.
[11] Anoop R Katti, Christian Reisswig, Cordula Guder, Sebastian Brarda, Steffen Bickel, Johannes Höhne, and Jean Baptiste Faddoul. 2018. Chargrid: Towards Understanding 2D Documents. In Proceedings of the 2018 Conference on empirical Methods in Natural Language Processing . Association for Computational Linguistics, Brussels, Belgium, 4459–4469. https://doi.org/10.18653/v1/D18-1476
[12] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, Michael Bernstein, and Li Fei-Fei. 2016. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. https://arxiv.org/abs/1602.07332
[13] Frank Lebourgeois, Z Bublinski, and H Emptoz. 1992. A fast and efficient method for extracting text paragraphs and graphics from unconstrained documents. In Proceedings., 11th IAPR International Conference on Pattern Recognition. Vol. II. Conference B: Pattern Recognition Methodology and Systems . IEEE, 272–276.
[14] D. Lewis, G. Agam, S. Argamon, O. Frieder, D. Grossman, and J. Heard. 2006. Building a Test Collection for Complex Document Information Processing. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (Seattle, Washington, USA) (SIGIR ’06) . ACM, New York, NY, USA, 665–666. https://doi.org/10.1145/1148170.1148307
[15] Xiaojing Liu, Feiyu Gao, Qiong Zhang, and Huasha Zhao. 2019. Graph convolution for Multimodal Information Extraction from Visually Rich Documents. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (industry Papers) . Association for Computational Linguistics, Minneapolis, Minnesota, 32–39. https://doi.org/10.18653/v1/N19-2005
[16] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke S. Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv abs/1907.11692 (2019).
[17] S. Marinai, M. Gori, and G. Soda. 2005. Artificial neural networks for document analysis and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 27, 1 (Jan 2005), 23–35. https://doi.org/10.1109/TPAMI.2005.4
[18] L. O’Gorman. 1993. The document spectrum for page layout analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence 15, 11 (Nov 1993), 1162– 1173. https://doi.org/10.1109/34.244677
[19] Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun. 2015. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (2015), 1137–1149.
[20] Ritesh Sarkhel and Arnab Nandi. 2019. Deterministic Routing between layout Abstractions for Multi-Scale Classification of Visually Rich Documents. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial intelligence, IJCAI-19 . International Joint Conferences on Artificial Intelligence Organization, 3360–3366. https://doi.org/10.24963/ijcai.2019/466
[21] Sebastian Schreiber, Stefan Agne, Ivo Wolf, Andreas Dengel, and Sheraz Ahmed. 2017. DeepDeSRT: Deep Learning for Detection and Structure Recognition of Tables in Document Images. 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) 01 (2017), 1162–1167.
[22] Michael Shilman, Percy Liang, and Paul Viola. 2005. Learning nongenerative grammatical models for document analysis. In Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1 , Vol. 2. IEEE, 962–969.
[23] Anikó Simon, J-C Pret, and A Peter Johnson. 1997. A fast algorithm for bottom-up document layout analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence 19, 3 (1997), 273–277.
[24] Carlos Soto and Shinjae Yoo. 2019. Visual Detection with Context for Document Layout Analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) . Association for Computational Linguistics, Hong Kong, China, 3462–3468. https://doi.org/10.18653/v1/D19-1348 [25] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alex Alemi. 2016. Inception-v4, Inception-ResNet and the Impact of Residual Connections on learning. In AAAI .
[26] Matheus Palhares Viana and Dário Augusto Borges Oliveira. 2017. Fast cnnbased Document Layout Analysis. 2017 IEEE International Conference on Computer Vision Workshops (ICCVW) (2017), 1173–1180.
[27] H. Wei, M. Baechler, F. Slimane, and R. Ingold. 2013. Evaluation of SVM, MLP and GMM Classifiers for Layout Analysis of Historical Documents. In 2013 12th International Conference on Document Analysis and Recognition . 1220–1224. https: //doi.org/10.1109/ICDAR.2013.247
[28] Xiaowei Yang, Ersin Yumer, Paul Asente, Mike Kraley, Daniel Kifer, and C. Lee Giles. 2017. Learning to Extract Semantic Structure from Documents Using Multimodal Fully Convolutional Neural Networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017), 4342–4351.
[29] Xu Zhong, Jianbin Tang, and Antonio Jimeno-Yepes. 2019. PubLayNet: largest dataset ever for document layout analysis. ArXiv abs/1908.07836 (2019).