坐标点地图匹配方法
1.概述
1.1.背景
随着公司业务发展,车定位轨迹数据越来越多,目前发现轨迹数据存在偏移问题,本文主要目的在于用图数据库和空间数据库来解决偏移问题,做到轨迹纠偏,将偏移的定位点放置到附近的道路上。
坐标点地图匹配方法
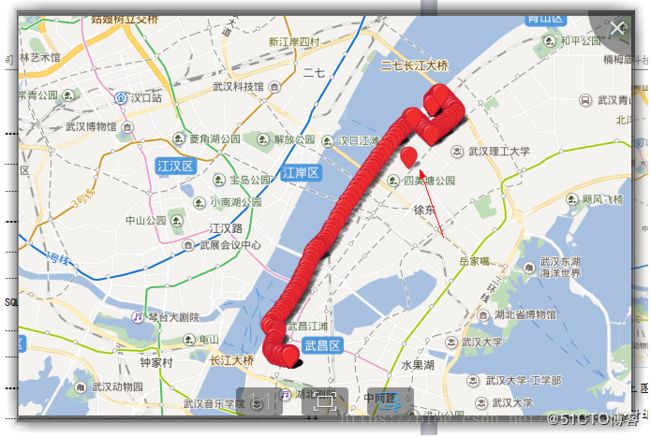
例如在上图中有个点不在轨迹上,也不在道路上,本文将通过计算的方法给它找到附近最近的道路上的点。
1.2.绑路方法
绑路的方法主要分为以下几个步骤:
1、获取路网数据保存至Neo4j数据库
2、将路网中的点数据保存到Postgresql数据库
3、输入一组经纬度点,分别找到每个点附近出现的在路上的点,在图数据库中查找这些点之间是否有连线关系,组成周围存在的路。
4、从周围存在的路中找到该点对于每个路线段的垂线在该路网线段的垂足,并计算垂足到该点的距离。
5、找出最近的距离的垂足作为该点绑路的点。
坐标点地图匹配方法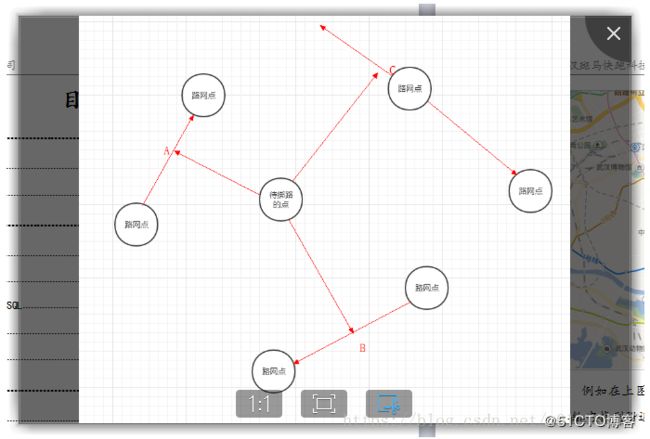
如上图中,就有三个备选点,分别对绑路的点对三个路网线段做垂线获得备选点,然后求垂足A、B、C与绑路的点的距离,选取A、B、C中到该点距离最短的作为结果输出。
2.数据清洗与保存
2.1.数据格式
获取的路网数据经过清洗格式如下图所示: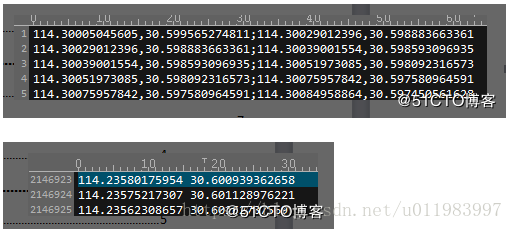
坐标点地图匹配方法
坐标点地图匹配方法
上图中第一幅表示连线关系第二幅为点坐标。
将连线关系和点的经纬度保存至图数据库中,将点的经纬度保存至空间数据库中。
空间数据库表格式:
CREATE TABLE “public”.”roadpoint” (
“id” serial NOT NULL,
“lat” float8 DEFAULT 0,
“lng” float8 DEFAULT 0,
“gisp” point
)
WITH (OIDS=FALSE)
;
ALTER TABLE “public”.”roadpoint” OWNER TO “bmkpdev”;
COMMENT ON COLUMN “public”.”roadpoint”.”lat” IS ‘纬度’;
COMMENT ON COLUMN “public”.”roadpoint”.”lng” IS ‘经度’;
CREATE INDEX “georoadpointgis_idx” ON “public”.”roadpoint” USING gist (“gisp”) WITH (fillfactor = 85);
其中gisp是空间数据类型,后建立空间索引georoadpointgis_idx,用于检索最近的路网当中的点。
图数据库中创建点的Cypher语句如下:
创建点
create (:point {lng:114.3086811059,lat:30.335394066259});
create (:point {lng:114.30853126854,lat:30.336053775889});
创建点的关系
match (a:point),(b:point)
where a.lng=114.3086811059 and a.lat=30.335394066259 and b.lng=114.30853126854 and b.lat=30.336053775889
create (a)-[r:to]->(b)
return r;
从Neo4j的web管理界面上可以查找到该点:坐标点地图匹配方法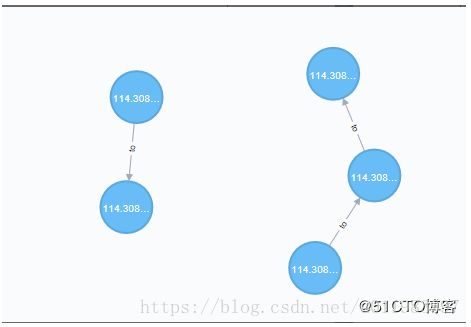
为了加快在图数据库中的查询速度 需要在图数据库中建立索引,索引语句如下:
create index on:node(lat)
create index on:node(lng)
2.2.Python连接Neo4j
获取图数据库中的点与点之间是否有连线关系,查询代码如下:
坐标点地图匹配方法
find_relationship = test_graph.match_one(start_node=find_code_1,end_node=find_code_3,bidirectional=False)
print find_relationship
2.3.Python连接Postgresql
示例代码如下:
import psycopg2# 数据库连接参数
conn = psycopg2.connect(database=”platoon”, user=”postgres”, password=”postgres”, host=”192.168.10.80”, port=”5432”)
cur = conn.cursor()
cur.execute(“CREATE TABLE test(id serial PRIMARY KEY, num integer,data varchar);”)# insert one item
cur.execute(“INSERT INTO test(num, data)VALUES(%s, %s)”, (1, ‘aaa’))
cur.execute(“INSERT INTO test(num, data)VALUES(%s, %s)”, (2, ‘bbb’))
cur.execute(“INSERT INTO test(num, data)VALUES(%s, %s)”, (3, ‘ccc’))
cur.execute(“SELECT * FROM test;”)
rows = cur.fetchall() # all rows in tableprint(rows)for i in rows:
print(i)
conn.commit()
cur.close()
conn.close()
2.4.垂足计算公式
假设图中O点为待绑定的点,AB为周围的路网点:
坐标点地图匹配方法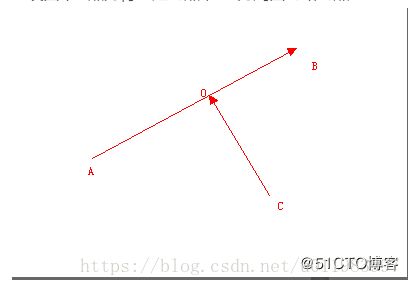
垂足坐标如下:
坐标点地图匹配方法
y坐标和x坐标对称。
筛选选数据库小数点后面两位不一样就抛弃
找出最近的十个点的SQL:
select *,geo_distance(gisp,point(114.404498,30.511795)) as distance from roadpoint where geo_distance(gisp,point(114.404498,30.511795)) < 0.62 ORDER BY distance limit 10
2.5.计算结果展示
未进行绑路的点的分布如图
坐标点地图匹配方法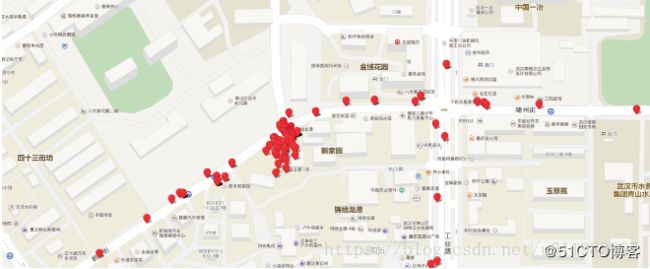
坐标点地图匹配方法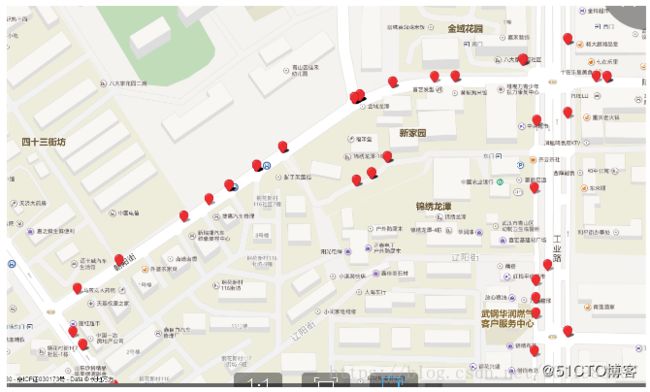
从上图看出效果比较理想,实现了定位点到道路点的转化
程序有几个可以优化的地方:
1、根据方向判断在哪条路上
2、计算点到直线的距离有更快的方法
3、选择子集有更快的方法
求(x0, y0)到经过(x1, y1); (x2, y2)直线的距离。
直线方程中
A = y2 - y1,
B = x1- x2,
C = x2 y1 - x1 y2;
点的直线的距离公式为:
double d = (fabs((y2 - y1) x0 +(x1 - x2) y0 + ((x2 y1) -(x1 y2)))) / (sqrt(pow(y2 - y1, 2) + pow(x1 - x2, 2)));
2.6.Neo4j快速导入数据的方法
数据格式如下:
坐标点地图匹配方法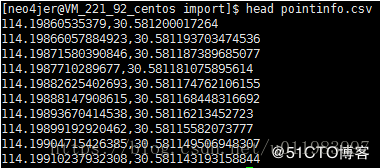
导入语句如下:
using periodic commit 1000 load csv from “file:///pointinfo.csv” as line create (:point {toFloat(lng:line[0]), lat:toFloat(line[1])})
3.性能提升方法
为了结局在空间数据库中快速匹配到附近的道路点,特采用geohash算法:
导入数据的roadpoint表结构如下:
坐标点地图匹配方法
建立空间索引的sql如下:
update roadpoint set gisp = point(lng,lat) where gisp is null;
增加新列geohashcode的sql如下:
ALTER table roadpoint add geohashcode varchar(20) DEFAULT NULL;
CREATE INDEX “geohash_index” ON “public”.”roadpoint” USING hash (“geohashcode”);
3.1.感性认识GeoHash
首先来点感性认识,http://openlocation.org/geohash/geohash-js/ 提供了在地图上显示geohash编码的功能。
1)GeoHash将二维的经纬度转换成字符串,比如下图展示了北京9个区域的GeoHash字符串,分别是WX4ER,WX4G2、WX4G3等等,每一个字符串代表了某一矩形区域。也就是说,这个矩形区域内所有的点(经纬度坐标)都共享相同的GeoHash字符串,这样既可以保护隐私(只表示大概区域位置而不是具体的点),又比较容易做缓存,比如左上角这个区域内的用户不断发送位置信息请求餐馆数据,由于这些用户的GeoHash字符串都是WX4ER,所以可以把WX4ER当作key,把该区域的餐馆信息当作value来进行缓存,而如果不使用GeoHash的话,由于区域内的用户传来的经纬度是各不相同的,很难做缓存。坐标点地图匹配方法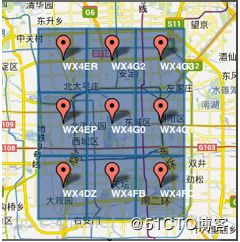
2)字符串越长,表示的范围越精确。如图所示,5位的编码能表示10平方千米范围的矩形区域,而6位编码能表示更精细的区域(约0.34平方千米)
坐标点地图匹配方法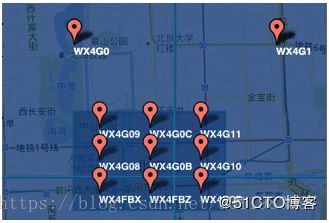
3)字符串相似的表示距离相近(特殊情况后文阐述),这样可以利用字符串的前缀匹配来查询附近的POI信息。如下两个图所示,一个在城区,一个在郊区,城区的GeoHash字符串之间比较相似,郊区的字符串之间也比较相似,而城区和郊区的GeoHash字符串相似程度要低些。
坐标点地图匹配方法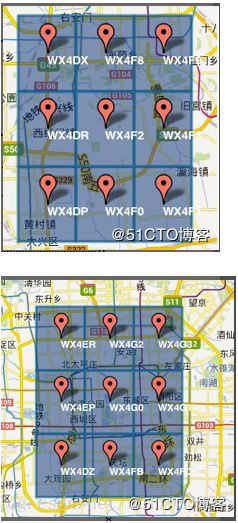
坐标点地图匹配方法
城区 郊区
通过上面的介绍我们知道了GeoHash就是一种将经纬度转换成字符串的方法,并且使得在大部分情况下,字符串前缀匹配越多的距离越近,回到我们的案例,根据所在位置查询来查询附近餐馆时,只需要将所在位置经纬度转换成GeoHash字符串,并与各个餐馆的GeoHash字符串进行前缀匹配,匹配越多的距离越近。
3.2.GeoHash算法的步骤
下面以北海公园为例介绍GeoHash算法的计算步骤
坐标点地图匹配方法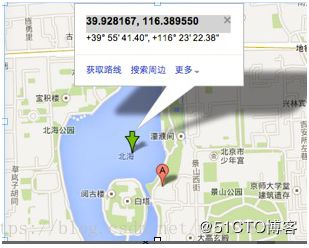
2.1. 根据经纬度计算GeoHash二进制编码
地球纬度区间是[-90,90], 北海公园的纬度是39.928167,可以通过下面算法对纬度39.928167进行逼近编码:
1)区间[-90,90]进行二分为[-90,0),[0,90],称为左右区间,可以确定39.928167属于右区间[0,90],给标记为1;
2)接着将区间[0,90]进行二分为 [0,45),[45,90],可以确定39.928167属于左区间 [0,45),给标记为0;
3)递归上述过程39.928167总是属于某个区间[a,b]。随着每次迭代区间[a,b]总在缩小,并越来越逼近39.928167;
4)如果给定的纬度x(39.928167)属于左区间,则记录0,如果属于右区间则记录1,这样随着算法的进行会产生一个序列1011100,序列的长度跟给定的区间划分次数有关。
根据纬度算编码
bit min mid max
1 -90.000 0.000 90.000
0 0.000 45.000 90.000
1 0.000 22.500 45.000
1 22.500 33.750 45.000
1 33.7500 39.375 45.000
0 39.375 42.188 45.000
0 39.375 40.7815 42.188
0 39.375 40.07825 40.7815
1 39.375 39.726625 40.07825
1 39.726625 39.9024375 40.07825
同理,地球经度区间是[-180,180],可以对经度116.389550进行编码。
根据经度算编码
bit min mid max
1 -180 0.000 180
1 0.000 90 180
0 90 135 180
1 90 112.5 135
0 112.5 123.75 135
0 112.5 118.125 123.75
1 112.5 115.3125 118.125
0 115.3125 116.71875 118.125
1 115.3125 116.015625 116.71875
1 116.015625 116.3671875 116.71875
2.2. 组码
通过上述计算,纬度产生的编码为10111 00011,经度产生的编码为11010 01011。偶数位放经度,奇数位放纬度,把2串编码组合生成新串:11100 11101 00100 01111。
最后使用用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,首先将11100 11101 00100 01111转成十进制,对应着28、29、4、15,十进制对应的编码就是wx4g。同理,将编码转换成经纬度的解码算法与之相反,具体不再赘述。坐标点地图匹配方法
3.3.GeoHash Base32编码长度与精度
下表摘自维基百科:http://en.wikipedia.org/wiki/Geohash
可以看出,当geohash base32编码长度为8时,精度在19米左右,而当编码长度为9时,精度在2米左右,编码长度需要根据数据情况进行选择。
坐标点地图匹配方法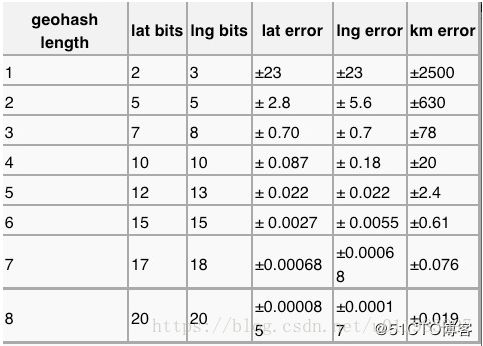
3.4.GeoHash算法
上文讲了GeoHash的计算步骤,仅仅说明是什么而没有说明为什么?为什么分别给经度和维度编码?为什么需要将经纬度两串编码交叉组合成一串编码?本节试图回答这一问题。
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线,当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
坐标点地图匹配方法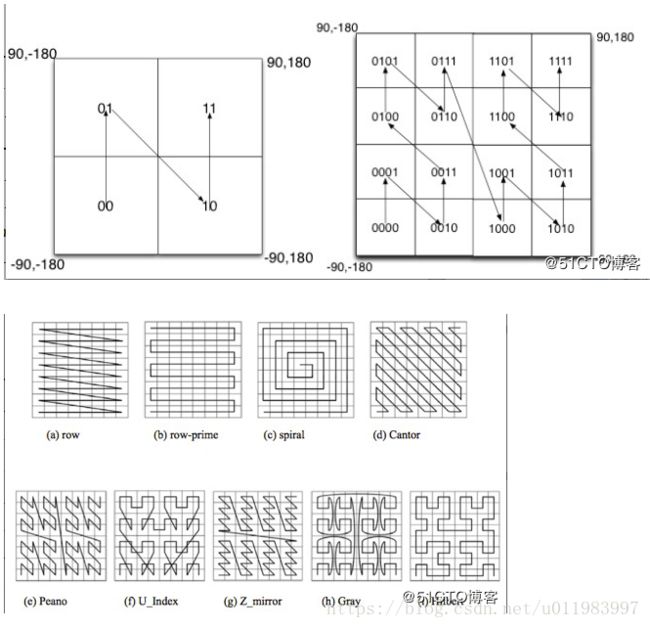
坐标点地图匹配方法
除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为什么GeoHash不选择Hilbert空间填充曲线呢?可能是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式。
3.5.使用注意点
1)由于GeoHash是将区域划分为一个个规则矩形,并对每个矩形进行编码,这样在查询附近POI信息时会导致以下问题,比如红色的点是我们的位置,绿色的两个点分别是附近的两个餐馆,但是在查询的时候会发现距离较远餐馆的GeoHash编码与我们一样(因为在同一个GeoHash区域块上),而较近餐馆的GeoHash编码与我们不一致。这个问题往往产生在边界处。
坐标点地图匹配方法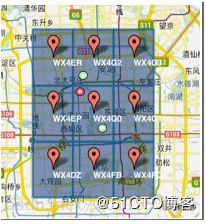
解决的思路很简单,我们查询时,除了使用定位点的GeoHash编码进行匹配外,还使用周围8个区域的GeoHash编码,这样可以避免这个问题。
2)我们已经知道现有的GeoHash算法使用的是Peano空间填充曲线,这种曲线会产生突变,造成了编码虽然相似但距离可能相差很大的问题,因此在查询附近餐馆时候,首先筛选GeoHash编码相似的POI点,然后进行实际距离计算。
4.服务发布
本程序采用flask框架部署上线:
Flask是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 。Flask使用 BSD 授权。
Flask也被称为 “microframework” ,因为它使用简单的核心,用 extension 增加其他功能。Flask没有默认使用的数据库、窗体验证工具。
访问url示例如下:
http://127.0.0.1:8881/latlonPoint?lng=114&lat=30
Python示例程序如下:
#!/usr/bin/env python
-- coding: utf-8 --
## 对flask框架模块调用
## 要注意Python Interpreter选取、virtualenv虚拟环境
## 详见Flask环境搭建、目的是隔离出一个独立环境
## 查询需要数据库支撑,MySQL
import os
import json
from flask import Flask
from flask import request
from flask import redirect
from flask import jsonify
from flask_cors import CORS
app = Flask(__name__)
CORS(app)
@app.route('/latlonPoint' , methods=['GET', 'POST'])
def index():
#接收POST参数
#接收参数类型为json格式
#字符串格式需要将 undecode转化为 UTF-8
#如果接收方式为post方法,则直接接收数据
if request.method == 'GET' :
#rev_data = json.loads(request.get_data())
#lng = float(rev_data.get('lng')) # 字符串:lng
#lat = float(rev_data.get('lat')) # 字符串:lat
lng = request.args.get('lng')
lat = request.args.get('lat')
datalist = {"lng" :lng,"lat" :lat }
return json.dumps(datalist)
else:
return '只接受post请求!
'
@app.route('/')
def user():
return'Please input your detail route!
'
if __name__ =='__main__':
#app.run(host = '0.0.0.0',port=8881,ssl_context='adhoc')
# app.run(host = '0.0.0.0',port=8881)
app.run(port=8881, debug=True,threaded=True)解决桥上桥下的问题
位置定位数据中,一直有个关键问题就是当定位数据处于立交桥的交汇处,如何判断,该定位点在桥上还是桥下。
此时需要输入前面的定位数据,通过以上的绑路算法 判断在哪一条路上 ,然后在图数据库中搜索与之相关联的路,作为备选,这一切的前提是图数据库中的数据点之间是能够关联上的。