2023-7-16
目录
前端
桂电官网页面如何实现?
用到了什么布局方式?
http状态码有哪些,分别代表什么含义?
JavaScript的DOM事件分为哪三个阶段?
HTML5有哪些语义标签?
桂电官网导航条实现过程?
Ajax的好处?
CSS有哪些选择器?项目中具体用到了哪些选择器?
CSS伪类选择器有哪些?项目中用到了什么伪类选择器?
ES6有哪些新特性?
JavaScript如何提交表单?
JavaScript如何获取文本框的值?
JavaScript有哪些内置对象?
轮播图如何实现?
说一下盒子模型
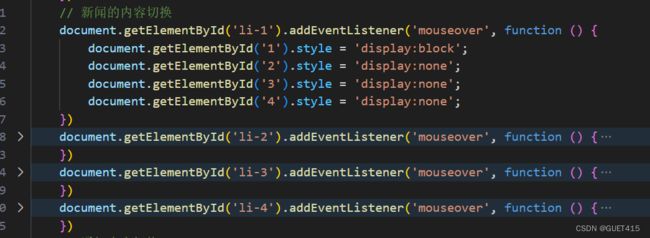
一条新闻是如何发布的?
什么是Ajax和JSON?
原生Ajax的交互流程有哪几步?
HTML如何模块化?
什么是同步、什么是异步?
谈谈对正则表达式的理解?有哪些具体的规则?
后端
详细说明MVC模式?
为什么要自己封装⼀个SpringMVC?
详细解释Model1和Model2
JDBC使用的步骤?
Servlet生命周期
Servlet如何返回JSON数据给前端?
过滤器有什么作用?项目中是否使用了过滤器?
什么是POJO、VO、DTO?
BaseDaoImpl是怎样实现的?
动态代理如何实现事务处理的?
BeanFactory实现过程?
为什么要统⼀封装返回结果ResponseData?
新闻图片上传到了哪里?图片能不能保存到数据库?
注解有什么作用?
做项目过程中,遇到了哪些问题?是如何解决的?
前端
桂电官网页面如何实现?
分为三个部分:开头部分、中间部分以及结尾部分
- 开头部分包含顶部、导航栏、轮播图
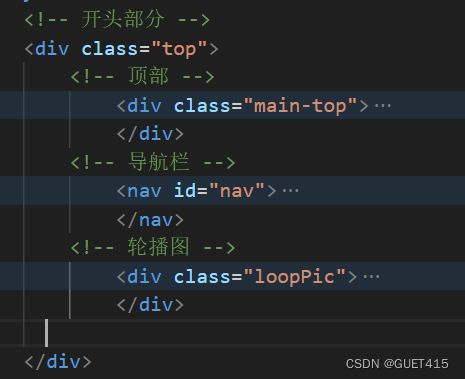
- 中间部分包含要闻、新闻、通知、学术、专题网站、正文末尾
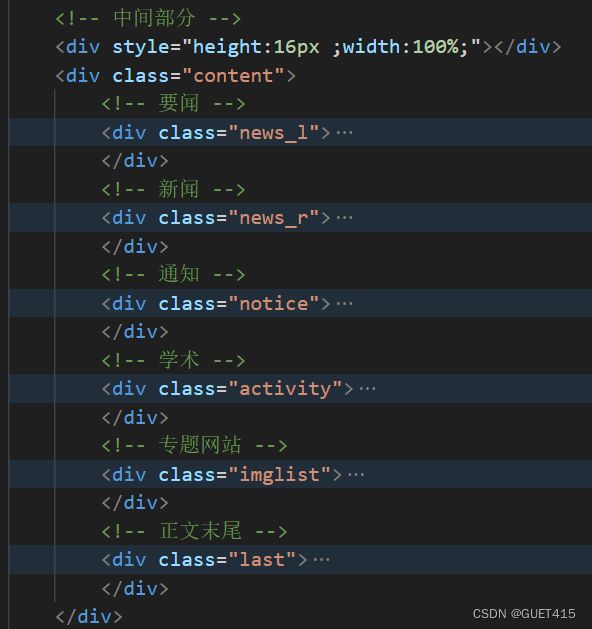
- 结尾部分

用到了什么布局方式?
使用了响应式布局方式。
响应式布局是一种根据设备屏幕尺寸和分辨率的变化,自动调整页面布局和元素大小的技术。通过使用CSS媒体查询和弹性布局等技术,可以使页面在不同设备上都能正确显示和操作。
http状态码有哪些,分别代表什么含义?
HTTP状态码表示Web服务器在处理客户端请求时返回的状态信息。 以下是常见的HTTP状态码及其含义:
1xx (信息性状态码):请求已被接受,需要继续处理。
- 100 Continue:继续发送请求的剩余部分。
- 101 Switching Protocols:切换协议,服务器将遵从客户的请求转换到另外一种协议。
2xx (成功状态码):请求已成功被服务器接收、理解、并接受。
- 200 OK:请求成功处理。
- 201 Created:请求被创建完成,同时新的资源被创建。
- 202 Accepted:请求被接受,但没有被处理完成。
- 204 No Content:请求成功处理,但没有返回任何内容。
3xx (重定向状态码):需要客户端执行进一步的操作才能完成请求。
- 301 Moved Permanently:所请求的资源已被永久移动到新位置。
- 302 Found:所请求的资源已被暂时移动到新位置。
- 303 See Other:所请求的资源可以在另一个 URI 下被找到,但客户端应该使用 GET 方法进行检索。
- 304 Not Modified:所请求的资源未被修改,服务器返回此状态码时,不会返回任何资源内容。
- 307 Temporary Redirect:所请求的资源可以在另一个 URI 下被找到。
4xx (客户端错误状态码):表示请求可能出错,妨碍了服务器的处理。
- 400 Bad Request:请求无效。
- 401 Unauthorized:请求要求用户身份验证。
- 403 Forbidden:服务器拒绝请求。
- 404 Not Found:服务器找不到请求的资源。
5xx (服务器错误状态码):表示服务器在处理请求时发生了错误。
- 500 Internal Server Error:服务器内部错误。
- 502 Bad Gateway:错误网关。
- 503 Service Unavailable:服务不可用。
- 504 Gateway Timeout:网关超时。
JavaScript的DOM事件分为哪三个阶段?
JavaScript的DOM事件分为以下三个阶段:
-
捕获阶段(Capture Phase):事件从最外层的父元素向下传播,直到触发事件的目标元素。在捕获阶段中,事件会依次经过每个祖先元素。
-
目标阶段(Target Phase):事件到达目标元素,即触发事件的元素。在目标阶段中,事件在目标元素上被触发。
-
冒泡阶段(Bubble Phase):事件从目标元素向上冒泡,传播到最外层的父元素。在冒泡阶段中,事件会依次经过每个祖先元素。
事件的传播顺序是先捕获阶段,然后是目标阶段,最后是冒泡阶段。可以通过addEventListener()方法的第三个参数来指定事件是在捕获阶段还是冒泡阶段触发,默认为冒泡阶段。
HTML5有哪些语义标签?
HTML5的语义标签包括:
- header:定义文档或节的头部
- nav:定义导航链接的部分
- aside:定义侧边栏或注释
- section:定义文档中的节或主题区域
- article:定义独立的内容块
- hgroup:定义标题中的组元素
- figure:定义单独的内容块及其标题
- figcaption:定义内容块的标题
- main:定义文档的主内容
- footer:定义文档或节的尾部
使用语义标签可以更好地描述页面结构和内容,让搜索引擎更好地理解和处理页面信息,提高网站的可访问性和SEO优化效果。
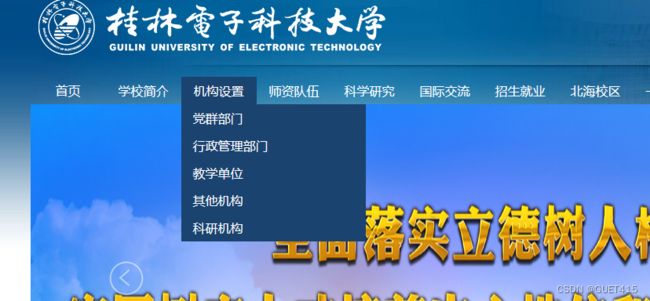
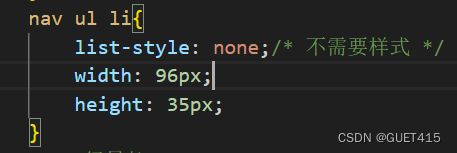
桂电官网导航条实现过程?
1.设计导航条的样式和布局:包括导航栏的颜色、字体、背景图片等;
2.创建HTML结构:使用标签创建一个无序列表,每个作为一个导航项。
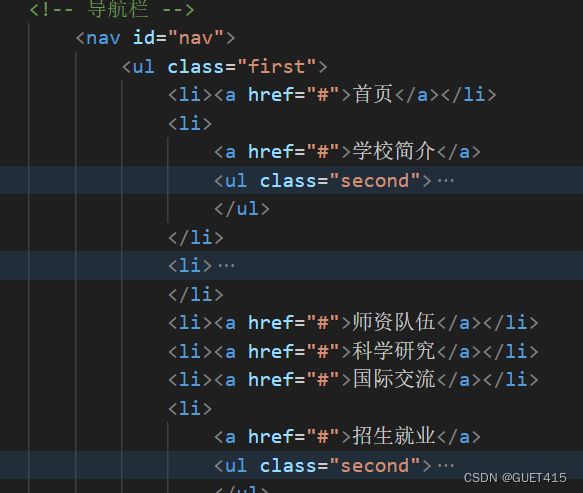
3.编写CSS代码:使用CSS定义导航条的样式,包括字体、颜色、背景、对齐方式等;
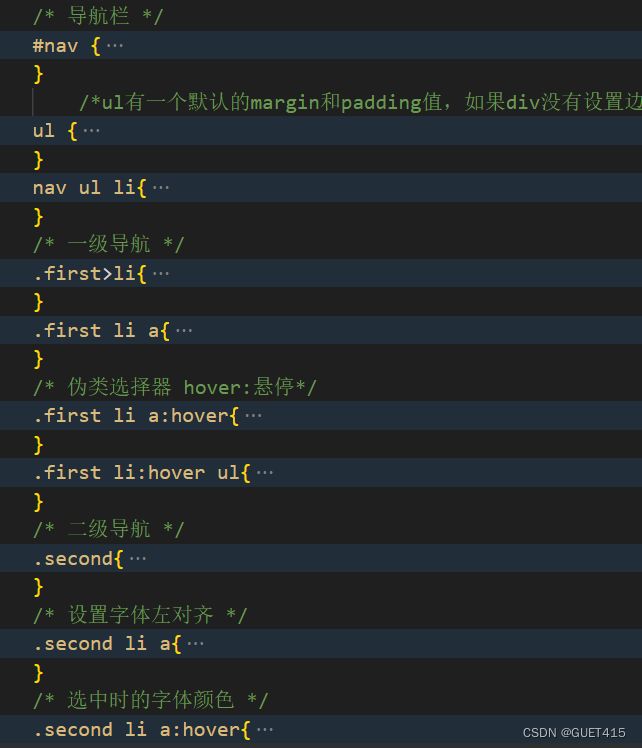
4.添加鼠标事件:使用JavaScript或jQuery添加鼠标事件,实现下拉菜单、在鼠标悬停时改变背景颜色等功能。
Ajax的好处?
-
异步加载:Ajax可以异步地向服务器发送请求和接收响应,而不用等待整个页面重新加载。这使得用户可以快速地获取所需信息,提高了用户体验。
-
减轻服务器负担:因为Ajax只更新需要改变的部分,所以减轻了服务器的负担,使得服务器可以更快地响应请求。
-
交互性:Ajax可以使用户与Web应用程序进行实时交互,如搜索建议、自动保存、即时验证等。
-
减少带宽需求:因为Ajax只更新需要改变的部分,而不是整个页面,所以减少了对带宽的需求,提高了Web应用程序的性能。
-
将前端和后端分离:因为Ajax可以使前端和后端的代码分离,使得开发团队可以分别开发和维护它们的代码,提高了开发效率。
CSS有哪些选择器?项目中具体用到了哪些选择器?
CSS有以下选择器:
- 元素选择器
- 类选择器

- ID选择器
- 后代选择器
- 子选择器
- 相邻兄弟选择器
- 通用选择器
- 属性选择器
- 伪类选择器

- 伪元素选择器
- 组合选择器
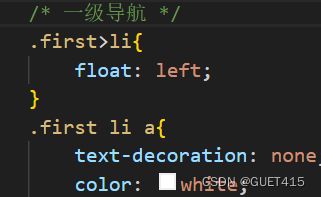
用到类选择器和伪类选择器
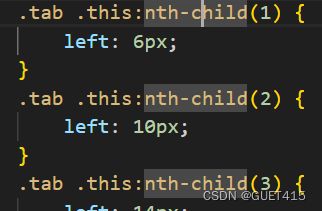
用于实现这个

CSS伪类选择器有哪些?项目中用到了什么伪类选择器?
CSS伪类选择器可以用来选择HTML元素的特殊状态或位置。常见的CSS伪类选择器有:
- :hover - 当鼠标悬停在元素上时应用样式

- :active - 当元素被激活(例如被点击)时应用样式
- :focus - 当元素获得焦点时应用样式
- :visited - 当链接已被访问时应用样式
- :link - 当链接未被访问时应用样式
- :first-child - 选择父元素的第一个子元素
- :last-child - 选择父元素的最后一个子元素
- :nth-child(n) - 选择父元素的第n个子元素
- :nth-of-type(n) - 选择父元素下特定类型的第n个子元素
- :not(selector) - 选择不符合指定选择器的元素
ES6有哪些新特性?
ES6是ECMAScript 6的简称,它是JavaScript的下一代标准,也称为ES2015。
它引入了一些新特性,包括:
-
let和const关键字:用于定义块级作用域的变量和常量。
-
箭头函数:更简洁的函数定义方式。
-
模板字符串:用反引号(`)定义字符串,可以包含变量和表达式。
-
解构赋值:可以从对象或数组中快速提取变量。
-
默认参数:在函数定义时设置形参的默认值。
-
展开运算符:可以将数组或对象展开成一个新的数组或对象。
-
Promise:用于异步编程的一种解决方案。
-
类和继承:引入了class、extends和super关键字来定义类和继承关系。
-
模块化:支持import和export关键字来导入和导出模块。
-
迭代器和生成器:引入了Symbol.iterator和function*关键字来支持迭代器和生成器的特性。
-
简化对象属性定义:支持在对象字面量中省略冒号和function关键字。
-
新的数据结构:引入了Set、Map、WeakSet和WeakMap等新的数据结构。
以上是ES6中的一些主要新特性。
JavaScript如何提交表单?
JavaScript可以使用以下方法提交表单:
- 使用form元素的submit()方法提交表单:
document.getElementById("myForm").submit();
- 使用XMLHttpRequest对象提交表单:
var xhr = new XMLHttpRequest();
xhr.open("POST", "http://example.com/submitform", true);
xhr.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
xhr.send("name=value&name2=value2");
- 使用jQuery库的ajax()方法提交表单:
$.ajax({
type: "POST",
url: "http://example.com/submitform",
data: $("#myForm").serialize(),
success: function(data) {
console.log(data);
}
});
注意:在提交表单时,需要确保表单元素的name属性和后台接收数据的参数名一致,且使用POST方法提交时需要设置Content-type头信息。
JavaScript如何获取文本框的值?
可以通过以下两种方法获取文本框的值:
- 通过ID获取文本框元素,然后使用
.value属性获取输入的值,例如:
- 通过表单元素的
name属性获取输入的值,例如:
在第二种方法中,document.forms[0]表示获取第一个表单元素,可以根据具体情况进行修改。document.forms[0]["myInput"].value表示获取表单元素中name属性为myInput的输入框的值。
JavaScript有哪些内置对象?
JavaScript的内置对象包括:
- 原始类型的包装对象:Boolean、Number、String、Symbol
- 全局对象:Object、Function、Array、Date、RegExp、Error、Map、Set、Math、JSON、Reflect、Promise
- 浏览器对象:Window、Document、Element、Event、XMLHttpRequest、History、Location、Navigator、Screen、Storage、WebSocket、Worker
- Node.js对象:Buffer、Process、Console、Global、Module、Timer等。
需要注意的是,一些内置对象可能只存在于特定的JavaScript执行环境中,比如浏览器对象只存在于浏览器环境中,而Node.js对象只存在于Node.js环境中。
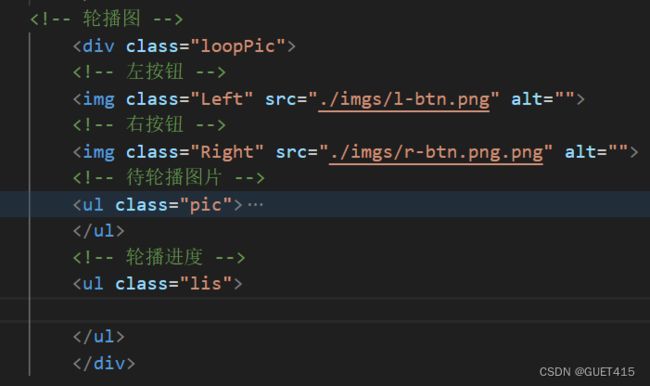
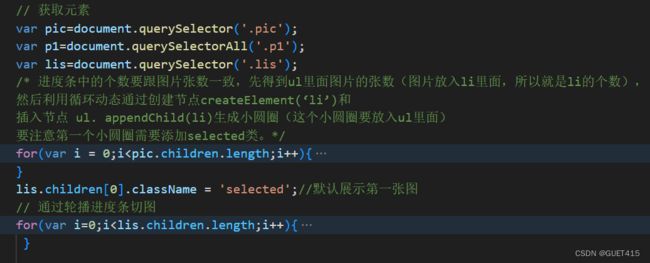
轮播图如何实现?
轮播图(Carousel)最常见的实现方式是通过 HTML、CSS 和 JavaScript 来实现。以下是一般实现的步骤:
- HTML 部分:
在 HTML 文件中添加包含图片的标签。每张图片都放在
- 中的
- CSS 部分:
- JavaScript 部分:
-
内容区域(Content):盒子的实际内容,例如文本、图片或其他嵌套元素。
-
内边距(Padding):内容区域与边框之间的空白区域。内边距可以用来设置元素内容与边框之间的间距。
-
边框(Border):包围内容和内边距的线条或样式。边框可以设置宽度、样式和颜色。
-
外边距(Margin):边框与相邻元素之间的空白区域。外边距可以用来设置元素与其他元素之间的间距。
-
width和height:设置元素的宽度和高度。 -
padding:设置内边距的大小。 -
border:设置边框的样式、宽度和颜色。 -
margin:设置外边距的大小。 -
后端编写接口:后端先编写好新闻的数据结构,包括新闻标题、内容、作者、发布时间等信息,并在服务器端编写好发布新闻接口。这个接口提供了发布新闻所需的数据格式和操作方法,前端可以通过这个接口将新闻数据传输到服务器端。
-
前端获取数据:前端为了向用户展示新闻,需要从后端获取数据。前端可以通过Ajax技术向服务器端发送HTTP请求,获取新闻数据。
-
前端展示数据:前端拿到数据之后,需要将数据渲染到页面上展示给用户。前端可以使用HTML、CSS等技术来美化展示效果。
-
用户发布新闻:如果用户想发布新闻,前端可以提供相应的界面和交互逻辑。用户输入新闻标题、内容等信息,前端将这些信息通过之前后端提供的发布新闻接口传输到服务器端。
-
服务器端处理数据:服务器端接收到前端传来的新闻数据后,会将数据存储在数据库中。有时候,后端还需要对数据进行验证和处理,以确保数据的安全、完整性和正确性。
-
前端展示新闻:当新闻发布成功后,前端再次通过Ajax请求获取最新的新闻列表,将新闻展示给用户。
-
创建 XMLHttpRequest 对象:使用 JavaScript 中的
new XMLHttpRequest()创建一个 XMLHttpRequest 对象。 -
设置回调函数:使用
onreadystatechange属性指定一个回调函数,该函数将在请求状态发生变化时被触发。 -
初始化请求:使用
open(method, url, async)方法初始化请求。其中,method表示请求的方法(如 "GET" 或 "POST"),url表示请求的 URL,async表示是否使用异步方式发送请求(通常为true)。 -
设置请求头(可选):使用
setRequestHeader(header, value)方法设置请求头,例如设置 Content-Type。 -
发送请求:使用
send(data)方法发送请求。对于 GET 请求,可以将参数附加到 URL 上;对于 POST 请求,可以将参数作为data参数传递。 -
监听请求状态变化:在回调函数中使用
readyState属性检查请求状态。当readyState的值为 4 时,表示请求已完成。 -
处理响应数据:在回调函数中使用
status属性检查响应状态码。如果status的值为 200,表示请求成功。可以使用responseText或responseXML属性获取服务器返回的数据。 -
清理和处理错误(可选):在回调函数中处理请求完成后的清理工作,并处理可能发生的错误。
-
字符匹配:正则表达式可以直接匹配普通字符,例如
abc可以匹配字符串中的 "abc"。 -
字符类:使用方括号表示字符类,例如
[abc]可以匹配字符串中的 "a"、"b" 或 "c"。 -
范围类:可以使用连字符
-来表示范围,例如[a-z]可以匹配任意小写字母。 -
预定义字符类:正则表达式提供了一些预定义的字符类,例如
\d可以匹配任意数字,\w可以匹配任意字母、数字或下划线。 -
量词:使用量词来指定匹配的次数,例如
a{3}可以匹配连续的三个 "a",a{2,4}可以匹配两到四个 "a"。 -
通配符:使用点
.来表示任意字符,例如a.b可以匹配 "aab"、"axb" 等。 -
转义字符:使用反斜杠
\来转义特殊字符,例如\.可以匹配点字符本身。 -
边界匹配:使用
^表示字符串的开头,$表示字符串的结尾,例如^abc$可以匹配整个字符串只有 "abc"。 -
分组和捕获:使用括号
()进行分组,并可以通过捕获组来提取匹配的内容。 -
反向引用:可以使用反向引用来引用之前的捕获组,例如
(abc)\1可以匹配 "abcabc"。 -
模型(Model):表示应用程序的数据和业务逻辑。模型负责与应用程序的数据库或其他数据源进行交互,以读取或存储数据。模型还可以包含一些特定的业务逻辑,例如数据验证和处理。
-
视图(View):表示应用程序的用户界面。视图负责显示数据和用户交互,例如用户界面、网页或移动应用程序。视图通常使用模板引擎来渲染数据。
-
控制器(Controller):表示应用程序的业务逻辑和用户输入处理。控制器负责从视图接收用户输入,然后选择适当的模型进行操作并将结果返回给视图。控制器还负责将视图与模型解耦,以便更容易地进行测试和维护。
-
加载数据库驱动程序:通过 Class.forName() 方法来加载指定的数据库驱动程序。
-
连接数据库:使用 DriverManager.getConnection() 方法获取数据库连接对象。
-
创建 Statement 对象:通过 Connection 对象创建 Statement 对象。
-
执行 SQL 语句:使用 Statement 对象往数据库发送 SQL 语句并接收数据库返回的结果。
-
处理结果集:对数据库返回的结果进行处理,可以使用 ResultSet 对象进行遍历,获取和操作数据。
-
关闭资源:释放相关对象和资源,如 ResultSet、Statement 和 Connection 对象。
-
加载和实例化阶段:容器根据web.xml配置文件中的Servlet配置信息加载并实例化Servlet。
-
初始化阶段:容器调用Servlet的init()方法,进行初始化操作,例如读取配置信息、建立数据库连接等。
-
请求处理阶段:容器接收到客户端请求后,调用Service()方法处理请求,并将响应返回给客户端。
-
销毁阶段:容器在关闭时调用Servlet的destroy()方法,进行资源释放和清理操作。
- 使用JSP(JavaServer Pages)页面:
使用 CSS 来定义每个图片容器的位置、大小、背景图片等样式属性。
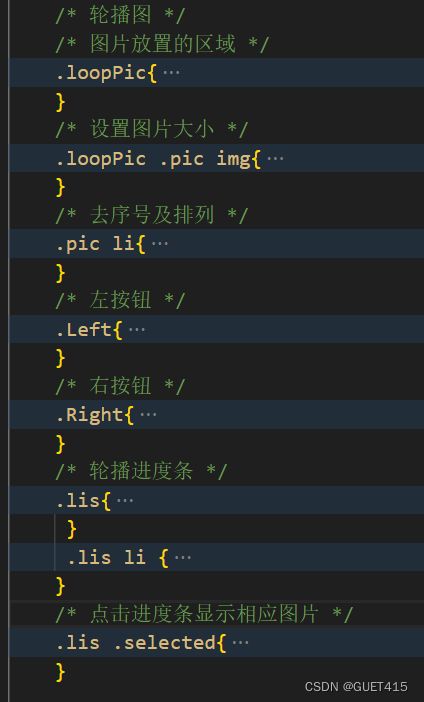
1.实现切图
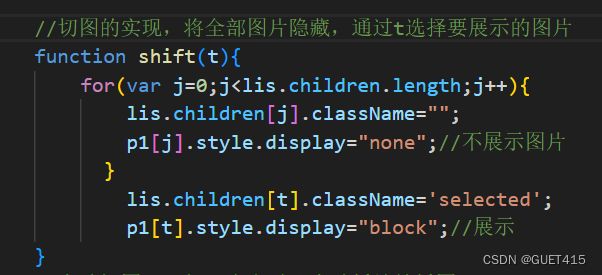
2. 左右切图
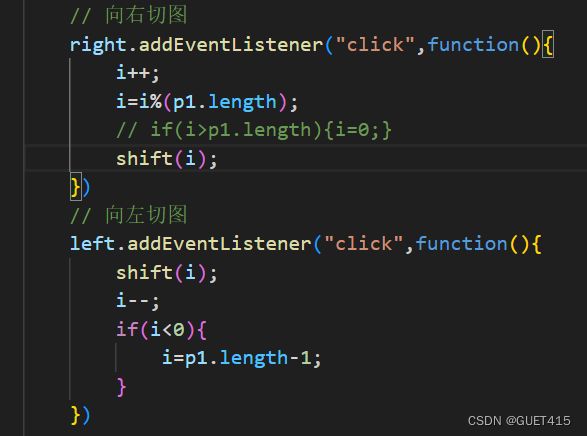
3.自动切图以及鼠标的事件
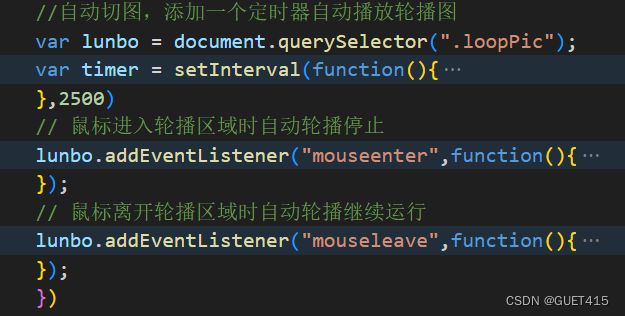
4.轮播进度条以及通过进度条切图

说一下盒子模型
盒子模型是指在网页布局中,每个元素都被视为一个矩形的盒子,包含内容、内边距、边框和外边距。这个盒子模型在CSS中被广泛使用,用于确定元素在页面中的尺寸、位置和样式。
盒子模型由以下几个部分组成:
在CSS中,可以使用盒子模型的属性来控制元素的尺寸和布局,例如:
默认情况下,元素的宽度和高度属性指的是内容区域的尺寸,而不包括内边距、边框和外边距。但是,可以使用 box-sizing 属性来改变盒子模型的行为,使其包括内边距和边框在内。
盒子模型在网页布局中起着重要的作用,通过调整盒子模型的属性,可以实现元素的尺寸、位置、间距和样式的控制,从而创建出各种不同的布局效果。
一条新闻是如何发布的?
一条新闻的发布是需要前后端配合完成的。以下是大致流程:
总之,新闻的发布需要前后端协同工作,前端负责展示数据,后端负责处理数据和提供接口,完成数据交互和存储。
什么是Ajax和JSON?
Ajax是指异步JavaScript和XML,它是一种用于创建动态Web应用的技术。通过Ajax,Web应用程序可以在不重新加载整个页面的情况下向服务器发出请求,并动态更新页面上的内容。Ajax使用一组Web技术,包括HTML、CSS、JavaScript、XML和HTTP,可以通过JavaScript中的XMLHttpRequest对象与服务器进行通信。
JSON是JavaScript对象表示法的缩写,它是一种轻量级的数据交换格式。JSON使用一组简单的语法规则,可以在不同的编程语言之间进行数据交换。JSON不仅比XML更加简洁和易于理解,而且也比XML更加高效。在Web应用程序开发中,JSON通常用于向客户端发送数据。
原生Ajax的交互流程有哪几步?
这些步骤描述了原生 Ajax 的基本交互流程。使用原生 Ajax 可以实现异步的数据交互,从而实现无需刷新整个页面的动态更新。然而,现代的 Web 开发中,通常使用更高级的工具和框架(如 jQuery、Axios 等)来简化 Ajax 的使用。
HTML如何模块化?
HTML可以使用各种不同的方法进行模块化。
一种方法是使用HTML5的语义化标记(例如header,nav,section,article,footer等元素),这些元素可以帮助在HTML中构建清晰的结构和模块化的内容。
另一种方法是使用HTML模板。HTML模板可以让开发者定义可重复使用的代码块,然后在不同的页面或不同的部分中引用它们。
还有一种方法是使用HTML的include功能,将HTML代码片段包含到其他HTML文件中。这种方法可以帮助开发者在多个页面中重复使用相同的HTML模块。
另外,一些Web框架和库,如AngularJS,React和Vue.js等,通过提供组件系统来帮助开发者在HTML中实现模块化。这些组件可以帮助开发者将复杂的页面结构拆分为更小的、可重用的部分。
什么是同步、什么是异步?
同步和异步是计算机编程中常用的概念,用于描述不同的程序执行方式。
同步指程序的执行顺序按照代码的先后顺序依次执行,每个操作都需要等待上一个操作完成后才能继续执行下一个操作,直到程序完成。
异步则指程序的执行顺序不按照代码先后顺序,而是将任务挂起并交给其他线程或进程执行,程序不必等待当前操作完成就可以继续执行下一个操作。
举个简单的例子,如果你要从服务器获取数据,同步的方式就是发送请求后,程序会一直等待服务器响应数据,直到收到数据才能继续执行下一步操作;异步的方式则是发送请求后,程序不会阻塞等待服务器响应,而是可以继续执行下一步操作,等到服务器响应后再去处理响应数据。
在实际编程中,同步方式适合简单的、无需等待时间过长的操作,而异步方式适合需要等待时间较长的操作或需要同时进行多个操作的情况。
谈谈对正则表达式的理解?有哪些具体的规则?
正则表达式是一种用于匹配、查找和操作文本的强大工具。它是由一系列字符和特殊字符组成的模式,用于描述和匹配字符串的规则。
以下是一些常见的正则表达式规则:
后端
详细说明MVC模式?
MVC是一种软件架构模式,它将应用程序分解成三个核心部分:模型、视图和控制器。这种模式旨在实现应用程序的分离关注点(Separation of Concerns)。MVC模式的三个核心部分分别有不同的职责:
MVC模式的主要优点是它可以实现分离关注点,即将不同的职责分开处理。这使得开发人员可以更容易地进行单元测试和代码重用,并且更容易进行应用程序的扩展和维护。
为什么要自己封装⼀个SpringMVC?
封装一个SpringMVC框架可以帮助我们更好地理解SpringMVC的工作原理和核心功能,同时也可以加深我们对Web技术和MVC架构的理解。在实际项目中,我们可以根据业务需求自定义一些特定的功能或扩展点,这时候自己封装的SpringMVC框架就可以更好地适应我们的需要。此外,封装自己的框架也可以提高我们的编程能力和设计能力,让我们更加熟练地掌握Java语言和Web开发技术。
详细解释Model1和Model2
Model1 和 Model2 都是机器学习中常用的模型类型,下面分别进行详细解释:
Model1 是传统的经典统计学习模型,如线性回归、逻辑回归、朴素贝叶斯、决策树等,它们通常基于统计学原理,通过构建数学模型来描述数据之间的关系。Model1 通常假设样本数据服从一个确定的数据分布,然后尝试最大化或最小化某种目标函数来建立一个预测模型。Model1 模型适用于数据比较规律和清晰的情况,通过调整模型参数可以优化预测结果的准确性和泛化能力。
Model2 是深度学习中常用的模型类型,如卷积神经网络 (CNN)、循环神经网络 (RNN)、长短时记忆网络 (LSTM) 等。Model2 不同于 Model1,它是基于神经网络的构架进行训练和预测。在神经网络中,数据被转换为多个层次的特征,每层特征都是由之前层次提取的特征组合而成。Model2 通常需要大量的数据和计算资源来进行训练,可以有效地处理大量非结构化数据,例如文本、图像和音频等。Model2 模型在深度学习领域取得了重大突破,广泛应用于图像识别、语音识别、自然语言处理等领域。
JDBC使用的步骤?
JDBC使用的一般步骤如下:
注意:为了保证数据库的安全性,需要使用 PreparedStatement 对象代替 Statement 对象来执行 SQL 语句,以防止 SQL 注入攻击。同时,在使用 JDBC 进行数据库操作时一定要注意资源的正确关闭,及时释放相关对象和资源。
Servlet生命周期
Servlet生命周期指从Servlet实例的创建到销毁的整个过程。Servlet容器在接收到请求时创建Servlet实例,然后处理请求并响应客户端后销毁Servlet实例。Servlet生命周期可分为以下阶段:
在以上阶段中,Servlet的destroy()方法执行后,Servlet实例将被销毁,并释放相关资源。如果容器重新收到请求,则需要重新加载和实例化Servlet,并重新执行整个生命周期过程。
Servlet如何返回JSON数据给前端?
Servlet可以使用Java提供的JSON库将Java对象转换为JSON格式的字符串,然后将其作为响应体返回给前端。以下是一些常见的方式:
在Servlet中设置响应内容的类型为“application/json”,并在响应体中输出JSON格式的字符串即可。例如:
response.setContentType("application/json");
response.setCharacterEncoding("UTF-8");
String json = "{\"name\":\"张三\",\"age\":20}"; // 假设要返回的JSON数据
response.getWriter().write(json);
在客户端页面中使用ajax调用该Servlet,然后处理从服务器返回的JSON数据。
- 使用第三方库,如Jackson或Gson:
这些库可以将Java对象转换成JSON格式的字符串,并将JSON作为响应体返回给前端。例如:
response.setContentType("application/json");
response.setCharacterEncoding("UTF-8");
ObjectMapper mapper = new ObjectMapper(); // 创建ObjectMapper对象
User user = new User("张三", 20); // 假设要返回的Java对象
String json = mapper.writeValueAsString(user); // 将Java对象转换为JSON格式的字符串
response.getWriter().write(json);
注意,需要在项目中添加依赖项以引入所选的JSON库。
过滤器有什么作用?项目中是否使用了过滤器?
过滤器可以根据特定的条件从数据流中过滤出符合条件的数据,同时将不符合条件的数据滤除掉。过滤器可以对各种类型的数据进行过滤,如文本、数字、图像、声音、视频等。过滤器可以用于多种应用场景,如数据清洗、数据抽样、数据筛选、安全过滤、广告过滤、垃圾邮件过滤等。
什么是POJO、VO、DTO?
POJO是Plain Old Java Object的缩写,指的是简单的Java对象,它是一种普通的Java对象,没有实现任何框架或接口,也没有继承任何类,仅仅只是一个存储数据的实体。
VO是Value Object的缩写,也叫做值对象,通常用于表示业务领域中的某个具体的概念,比如用户、订单等。VO一般只包含属性和getter/setter方法,不包含任何业务逻辑代码。
DTO是Data Transfer Object的缩写,用于在不同层之间传输数据,通常用于将数据库中的数据转换为业务逻辑层(Service层)需要的数据格式,或者将业务逻辑层处理的数据转换为网络传输的数据格式。DTO一般包含多个属性,getter/setter方法和一些数据转换的方法。
BaseDaoImpl是怎样实现的?
BaseDaoImpl是一个基础的数据访问对象(DAO)类的实现,主要用于提供数据库操作的基础方法,包括增删改查等操作。
它的实现主要包括以下几个方面:
-
继承通用的DAO接口,如JDBC的JdbcTemplate或Hibernate的HibernateTemplate等,以便于使用相关的数据库操作方法。
-
提供基本的增删改查方法,如save、delete、update、get等。
-
提供分页查询的方法,以便于对大量数据进行分页查询。
-
处理异常,如数据库连接异常、SQL语句异常等。
-
提供事务支持,以保证操作的原子性和数据的一致性。
基于以上实现,BaseDaoImpl可以作为各种具体DAO类的基类,以便于快速实现对应的数据操作。同时,它也可以根据具体的业务需求进行扩展和定制。
动态代理如何实现事务处理的?
动态代理可以通过在方法调用前后添加事务处理的逻辑,来实现事务处理。在方法调用前,开启事务,然后在方法调用后根据方法执行结果来决定是否提交事务或者回滚事务。
具体实现可以使用AOP的思想,通过拦截方法的调用,在方法执行前后添加事务处理的逻辑。在Java中,可以使用Spring框架提供的事务管理器来实现动态代理的事务处理。
例如,使用Spring框架的@Transactional注解声明一个方法为事务方法,Spring在动态代理时会将该方法包装为一个事务代理方法,然后在代理方法中添加事务处理逻辑。当该方法被调用时,代理方法会自动处理事务,保证方法执行的原子性和一致性。
示例代码如下:
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
@Transactional
@Override
public void updateUser(User user) {
userDao.updateUser(user);
}
}
在上述示例中,@Transactional注解声明了updateUser方法为事务方法,Spring会自动为该方法生成事务代理方法,并在代理方法中添加事务处理的逻辑。如果更新用户信息失败,代理方法会自动回滚事务,保证数据的一致性。
BeanFactory实现过程?
BeanFactory是一个接口,用于管理Spring中的bean。BeanFactory接口提供了一些方法,如getBean()、containsBean()等,用于在容器中获取bean。
BeanFactory的实现过程分为以下几步:
-
创建bean定义:BeanFactory中的bean都是基于BeanDefinition定义的。BeanDefinition定义了bean的属性和配置信息,如bean的名字、类名、作用域、构造函数参数、依赖注入等。
-
加载bean定义:BeanFactory创建bean的过程是基于配置文件中的bean定义信息。BeanFactory从配置文件中读取bean定义信息,然后解析bean定义信息,并将其转换为BeanDefinition对象。
-
注册bean定义:将上一步中解析好的BeanDefinition对象注册到BeanFactory中。
-
初始化bean:BeanFactory从容器中获取bean定义后,就可以创建bean实例了。在创建bean实例之前,需要解决依赖注入问题。BeanFactory使用依赖注入的方式将bean所依赖的其他bean注入到当前bean实例中。
-
返回bean实例:BeanFactory创建完bean实例后,返回给调用者使用。
总之,BeanFactory在创建bean时,先解析bean定义信息,然后创建bean实例并解决bean之间的依赖关系。最后,将创建好的bean实例返回到调用者。
为什么要统⼀封装返回结果ResponseData?
统一封装返回结果(ResponseData)的好处有以下几点:
-
代码可维护性:通过统一封装,不同的接口返回的数据格式就会统一,这样有助于维护代码。如果某种数据结构变更了,只需修改封装代码即可。
-
规范性:封装返回结果可以规定一套数据结构,如状态码、错误信息、返回数据等,统一格式,使得前端和后端开发者能够更好地理解和应用。
-
提高效率:通过封装返回结果,能够减少前后端之间数据格式不一致或者前端多次反复请求接口的情况,提高了数据传输效率。
-
安全性:通过封装,可以将接口返回结果中的敏感信息统一加密,避免敏感数据被不当的人员获取到。
新闻图片上传到了哪里?图片能不能保存到数据库?
新闻图片通常会上传到服务器的文件夹中,图片的路径会保存在数据库中,以方便在需要时调用。如果您需要保存图片到数据库中,可以将图片转换成二进制流数据,然后将其存储在数据库的二进制字段中。不过需要注意的是,将图片存储到数据库中可能会影响数据库的性能,因为图片通常会占据较大的存储空间。这种情况下,建议将图片存储在独立的文件服务器上,然后在数据库中保存图片的路径或者标识符。
注解有什么作用?
注解是Java中的一种元数据,用于描述代码的特性、限制和用途等信息,可以附加在类、方法、变量等程序元素上。它的主要作用包括:
-
提供元数据:注解可以传递元数据信息,程序可以通过注解来获取类、方法、变量等的特性、限制和用途等信息。
-
编译时检查:注解可以在编译时对代码进行检查,提高程序的健壮性和安全性,例如Java中的@Deprecated注解可以标记已过时的方法或类,编译器会在编译时给出警告。
-
更好的代码可读性:注解可以提高代码的可读性和可维护性,使代码更加简洁,易于理解。
-
代码生成:注解可以用于生成代码,例如Java中的@Generated注解可以标记代码是由工具自动生成的,便于代码维护和追踪。
总体而言,注解是Java语言中一项重要的语言特性,可以通过提供元数据、检查代码、提高代码可读性和生成代码等方式提高程序的质量和效率。
做项目过程中,遇到了哪些问题?是如何解决的?
- 布局混乱
通过各种选择器解决
- 轮播图实现
通过网上搜索资料解决
- 点击列表实现内容切换