尚硅谷大数据项目《在线教育之采集系统》笔记005
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili
目录
P057
P058
P059
P060
P061
P062
P063
P064
P065
P066
P067
P068
P069
P070
P071
P072
P073
P057
#!/bin/bash
MAXWELL_HOME=/opt/module/maxwell/maxwell-1.29.2
status_maxwell() {
result=`ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l`
return $result
}
start_maxwell() {
status_maxwell
if [[ $? -lt 1 ]]; then
echo "启动Maxwell!"
$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemon
else
echo "Maxwell正在运行!"
fi
}
stop_maxwell() {
status_maxwell
if [[ $? -gt 0 ]]; then
echo "停止Maxwell!"
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
else
echo "Maxwell未在运行!"
fi
}
case $1 in
start )
start_maxwell
;;
stop )
stop_maxwell
;;
restart )
stop_maxwell
start_maxwell
;;
esac
P058
[atguigu@node001 maxwell-1.29.2]$ bin/maxwell-bootstrap --database edu --table base_province --config /opt/module/maxwell/maxwell-1.29.2/config.properties
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
[atguigu@node001 maxwell-1.29.2]$ [atguigu@node002 ~]$ kafka-console-consumer.sh --bootstrap-server node001:9092 --topic maxwellP059
P060

P061
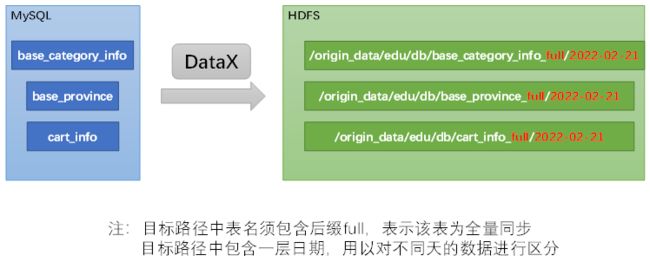
方便起见,此处提供了DataX配置文件批量生成脚本,脚本内容及使用方式如下。
# coding=utf-8
import json
import getopt
import os
import sys
import MySQLdb
#MySQL相关配置,需根据实际情况作出修改
mysql_host = "hadoop102"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "000000"
#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "hadoop102"
hdfs_nn_port = "8020"
#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/opt/module/datax/job/import"
def get_connection():
return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)
def get_mysql_meta(database, table):
connection = get_connection()
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_mysql_columns(database, table):
return map(lambda x: x[0], get_mysql_meta(database, table))
def get_hive_columns(database, table):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table)
return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)
def generate_json(source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": mysql_user,
"password": mysql_passwd,
"column": get_mysql_columns(source_database, source_table),
"splitPk": "",
"connection": [{
"table": [source_table],
"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,
"fileType": "text",
"path": "${targetdir}",
"fileName": source_table,
"column": get_hive_columns(source_database, source_table),
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:
json.dump(job, f)
def main(args):
source_database = ""
source_table = ""
options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])
for opt_name, opt_value in options:
if opt_name in ('-d', '--sourcedb'):
source_database = opt_value
if opt_name in ('-t', '--sourcetbl'):
source_table = opt_value
generate_json(source_database, source_table)
if __name__ == '__main__':
main(sys.argv[1:])P062
源“ySQL 8.0 Community Server”的GPG密钥已安装,但是不适用于此软件包。请检查源的公钥URL是否配置正确。_mysql 5.7 community server" 的 gpg 密钥已安装,但是不适用于此软件包_轶拾柒.的博客-CSDN博客
[atguigu@node001 ~]$ cd bin
[atguigu@node001 bin]$ python gen_import_config.py -d edu -t base_province
[atguigu@node001 bin]$ cd /opt/module/datax/job/import
[atguigu@node001 import]$ ls
database.table.json edu.base_province.json
[atguigu@node001 import]$ [atguigu@node001 import]$ cd /opt/module/datax/
[atguigu@node001 datax]$ bin/datax.py -p"-Dtargetdir=/base_province/2022-02-22" job/import/edu.base_province.json
2023-08-11 11:43:14.962 [job-0] ERROR RetryUtil - Exception when calling callable, 即将尝试执行第1次重试.本次重试计划等待[1000]ms,实际等待[1003]ms, 异常Msg:[DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的username/password错误,鉴权失败。请和DBA确认该数据库的连接信息是否正确。]
2023-08-11 11:43:14.970 [job-0] WARN DBUtil - test connection of [jdbc:mysql://node001:3306/edu] failed, for Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server..2023-08-11 11:43:14.962 [job-0] ERROR RetryUtil - Exception when calling callable, 即将尝试执行第1次重试.本次重试计划等待[1000]ms,实际等待[1003]ms, 异常Msg:[DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的username/password错误,鉴权失败。请和DBA确认该数据库的连接信息是否正确。]
2023-08-11 11:43:14.970 [job-0] WARN DBUtil - test connection of [jdbc:mysql://node001:3306/edu] failed, for Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server..解决方法:https://www.cnblogs.com/aluna/p/17115485.html

P063
#!/bin/bash
python ~/bin/gen_import_config.py -d edu -t base_category_info
python ~/bin/gen_import_config.py -d edu -t base_source
python ~/bin/gen_import_config.py -d edu -t base_province
python ~/bin/gen_import_config.py -d edu -t base_subject_info
python ~/bin/gen_import_config.py -d edu -t cart_info
python ~/bin/gen_import_config.py -d edu -t chapter_info
python ~/bin/gen_import_config.py -d edu -t course_info
python ~/bin/gen_import_config.py -d edu -t knowledge_point
python ~/bin/gen_import_config.py -d edu -t test_paper
python ~/bin/gen_import_config.py -d edu -t test_paper_question
python ~/bin/gen_import_config.py -d edu -t test_point_question
python ~/bin/gen_import_config.py -d edu -t test_question_info
python ~/bin/gen_import_config.py -d edu -t user_chapter_process
python ~/bin/gen_import_config.py -d edu -t test_question_option
python ~/bin/gen_import_config.py -d edu -t video_info
P064
[atguigu@node001 bin]$ date -d "-1 day" +%F # 获取系统时间
2023-08-10
[atguigu@node001 bin]$ [atguigu@hadoop102 bin]$ vim ~/bin/mysql_to_hdfs_full.sh
-----------------------------------------------------------------
#!/bin/bash
DATAX_HOME=/opt/module/datax
DATAX_DATA=/opt/module/datax/job
#清理脏数据
handle_targetdir() {
hadoop fs -rm -r $1 >/dev/null 2>&1
hadoop fs -mkdir -p $1
}
#数据同步
import_data() {
local datax_config=$1
local target_dir=$2
handle_targetdir "$target_dir"
echo "正在处理$1"
python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config >/tmp/datax_run.log 2>&1
if [ $? -ne 0 ]
then
echo "处理失败, 日志如下:"
cat /tmp/datax_run.log
fi
rm /tmp/datax_run.log
}
#接收表名变量
tab=$1
# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;then
do_date=$2
else
do_date=$(date -d "-1 day" +%F)
fi
case ${tab} in
base_category_info | base_province | base_source | base_subject_info | cart_info | chapter_info | course_info | knowledge_point | test_paper | test_paper_question | test_point_question | test_question_info | test_question_option | user_chapter_process | video_info)
import_data $DATAX_DATA/import/edu2077.${tab}.json /origin_data/edu/db/${tab}_full/$do_date
;;
"all")
for tmp in base_category_info base_province base_source base_subject_info cart_info chapter_info course_info knowledge_point test_paper test_paper_question test_point_question test_question_info test_question_option user_chapter_process video_info
do
import_data $DATAX_DATA/import/edu2077.${tmp}.json /origin_data/edu/db/${tmp}_full/$do_date
done
;;
esac[atguigu@node001 bin]$ jpsall
================ node001 ================
3441 DataNode
4882 Jps
4706 Maxwell
3862 NodeManager
4214 QuorumPeerMain
4632 Kafka
3275 NameNode
4079 JobHistoryServer
================ node002 ================
2064 DataNode
2290 ResourceManager
3315 Jps
3172 Kafka
2781 QuorumPeerMain
2413 NodeManager
================ node003 ================
2162 SecondaryNameNode
3003 Jps
2317 NodeManager
2861 Kafka
2062 DataNode
2479 QuorumPeerMain
[atguigu@node001 bin]$ mysql_to_hdfs_full.sh all 2022-02-22
正在处理/opt/module/datax/job/import/edu.base_category_info.json...
正在处理/opt/module/datax/job/import/edu.base_province.json...
正在处理/opt/module/datax/job/import/edu.base_source.json...
正在处理/opt/module/datax/job/import/edu.base_subject_info.json...
正在处理/opt/module/datax/job/import/edu.cart_info.json...
正在处理/opt/module/datax/job/import/edu.chapter_info.json...
正在处理/opt/module/datax/job/import/edu.course_info.json...
正在处理/opt/module/datax/job/import/edu.knowledge_point.json...
正在处理/opt/module/datax/job/import/edu.test_paper.json...
正在处理/opt/module/datax/job/import/edu.test_paper_question.json...
正在处理/opt/module/datax/job/import/edu.test_point_question.json...
正在处理/opt/module/datax/job/import/edu.test_question_info.json...
正在处理/opt/module/datax/job/import/edu.test_question_option.json...
正在处理/opt/module/datax/job/import/edu.user_chapter_process.json...
正在处理/opt/module/datax/job/import/edu.video_info.json...
[atguigu@node001 bin]$ 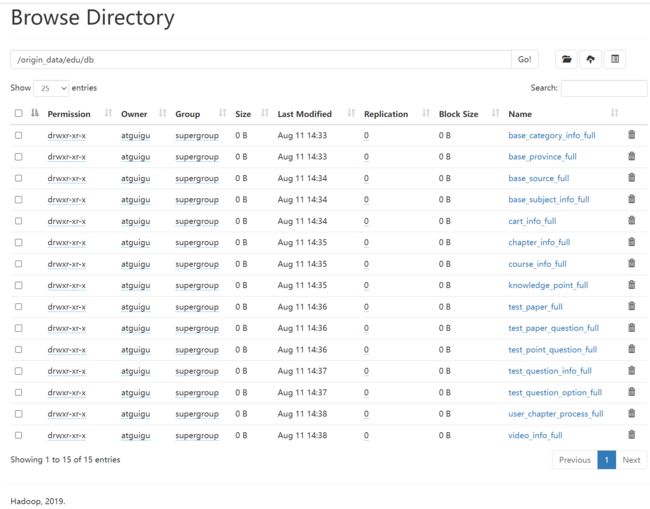
P065
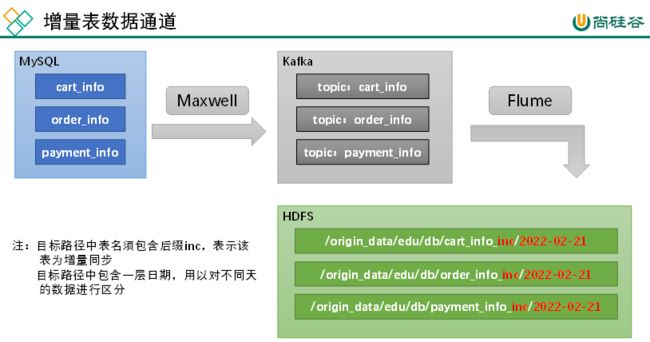
2.4 增量表数据同步
2.4.1 数据通道
P066

[atguigu@node001 bin]$ jpsall
================ node001 ================
3441 DataNode
7491 Maxwell
3862 NodeManager
4214 QuorumPeerMain
7559 Jps
4632 Kafka
3275 NameNode
4079 JobHistoryServer
================ node002 ================
2064 DataNode
2290 ResourceManager
3172 Kafka
4252 Jps
3917 ConsoleConsumer
2781 QuorumPeerMain
2413 NodeManager
================ node003 ================
2162 SecondaryNameNode
3318 Jps
2317 NodeManager
2861 Kafka
2062 DataNode
2479 QuorumPeerMain
[atguigu@node001 bin]$ mock.sh
[atguigu@node001 bin]$ [atguigu@node002 ~]$ kafka-console-consumer.sh --bootstrap-server node001:9092 --topic topic_dbP067
/opt/module/flume/flume-1.9.0/job/kafka_to_hdfs_db.conf
## 1、定义组件
a1.sources = r1
a1.channels = c1
a1.sinks = k1
## 2、配置sources
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = node001:9092,node002:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = topic_db
a1.sources.r1.batchSize = 1000
a1.sources.r1.batchDurationMillis = 1000
a1.sources.r1.useFlumeEventFormat = false
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptors.TimestampAndTableNameInterceptor$Builder
## 3、配置channels
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/flume-1.9.0/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/flume-1.9.0/data/behavior2
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## 4、配置sinks
a1.sinks.k1.type = hdfs
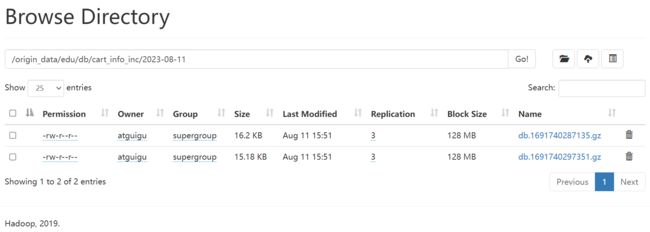
a1.sinks.k1.hdfs.path = /origin_data/edu/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 5、组装拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1P068
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimestampAndTableNameInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 拦截器任务
* 1.将body当中的ts放到header当中的timestamp
* 2.将body当中的table放到header当中的tableName
*/
@Override
public Event intercept(Event event) {
// 1、获取header 和body当中的数据
Map headers = event.getHeaders();
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
// 2、解析body当中的ts和table
JSONObject jsonObject = JSONObject.parseObject(log);
String table = jsonObject.getString("table");
// Maxwell输出的数据中的ts字段时间戳单位为秒,Flume HDFSSink要求单位为毫秒
String ts = jsonObject.getString("ts");
// 将body当中的ts放到header当中的timestamp
// 将body当中的table放到header当中的tableName
headers.put("tableName", table);
headers.put("timestamp", ts + "000");
return event;
}
@Override
public List intercept(List list) {
for (Event event : list) {
intercept(event);
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampAndTableNameInterceptor();
}
@Override
public void configure(Context context) {
}
}
} P069
[atguigu@node003 ~]$ cd /opt/module/flume/flume-1.9.0/
[atguigu@node003 flume-1.9.0]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_db.conf [atguigu@node002 ~]$ kafka-console-consumer.sh --bootstrap-server node001:9092 --topic topic_db[atguigu@node001 bin]$ jpsall
================ node001 ================
3441 DataNode
7491 Maxwell
3862 NodeManager
4214 QuorumPeerMain
4632 Kafka
8682 Jps
3275 NameNode
4079 JobHistoryServer
================ node002 ================
2064 DataNode
5026 Jps
2290 ResourceManager
3172 Kafka
2781 QuorumPeerMain
2413 NodeManager
================ node003 ================
2162 SecondaryNameNode
4115 Application
4234 Jps
2317 NodeManager
2861 Kafka
2062 DataNode
2479 QuorumPeerMain
[atguigu@node001 bin]$ mock.sh
P070


P071
#!/bin/bash
case $1 in
"start")
echo " --------启动 node003 业务数据flume-------"
ssh node003 "nohup /opt/module/flume/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume/flume-1.9.0/conf -f /opt/module/flume/flume-1.9.0/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 node003 业务数据flume-------"
ssh node003 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esacP072
[atguigu@node001 bin]$ mysql_to_kafka_inc_init.sh all
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
connecting to jdbc:mysql://node001:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
[atguigu@node001 bin]$