02_快速体验 Hudi、编译 Hudi、安装HDFS、安装Spark 3.x、模拟数据、插入数据、查询数据、.hoodie文件、数据文件、Hudi 数据存储概述、Metadata 元数据等
本文来自"黑马程序员"hudi课程
2.第二章 快速体验 Hudi
2.1 编译 Hudi
2.1.1 第一步、Maven 安装
2.1.2 第二步、下载源码包
2.1.3 第三步、添加Maven镜像
2.1.4 第四步、执行编译命令
2.1.5 第五步、Hudi CLI测试
2.2 环境准备
2.2.1 安装HDFS
2.2.2 安装Spark 3.x
2.3 spark-shell 使用
2.3.1 启动spark-shell
2.3.2 模拟数据
2.3.3 插入数据
2.3.4 查询数据
2.3.5 表数据结构
2.3.5.1 .hoodie文件
2.3.5.2 数据文件
2.3.6 Hudi 数据存储概述
2.3.6.1 Metadata 元数据
2.3.6.2 Index 索引
2.3.6.3 Data 数据
2.4 IDEA 编程开发
2.4.1 准备环境
2.4.2 代码结构
2.4.3 插入数据Insert
2.4.4 查询数据Query
2.4.5 更新数据Update
2.4.6 增量查询Incremental query
2.4.7 删除数据Delete
2. 第二章 快速体验 Hudi
依据官方提供Spark DataSource数据源,对Hudi表数据进行CRUD操作,快速上手体验Hudi数据湖框架,分别在spark-shell命令行和IDEA中API使用。
2.1 编译 Hudi
Apache Hudi数据湖框架开发时添加MAVEN依赖即可,使用命令管理Hudi表数据,需要下载Hudi 源码包编译,操作步骤如下。
2.1.1 第一步、Maven 安装
在CentOS 7.7 版本64位操作上下载和安装Maven,直接将Maven软件包解压,然后配置系统环境变量即可。Maven版本为:3.5.4,仓库目录名称:m2,如下图所示:

配置Maven环境变量以后,执行:mvn -version

2.1.2 第二步、下载源码包
到Apache 软件归档目录下载Hudi 0.8源码包:http://archive.apache.org/dist/hudi/0.9.0/
wget https://archive.apache.org/dist/hudi/0.9.0/hudi-0.9.0.src.tgz
此外,也可以从Github上下载Hudi源码:
https://github.com/apache/hudi
其中说明如何编译Hudi源码:
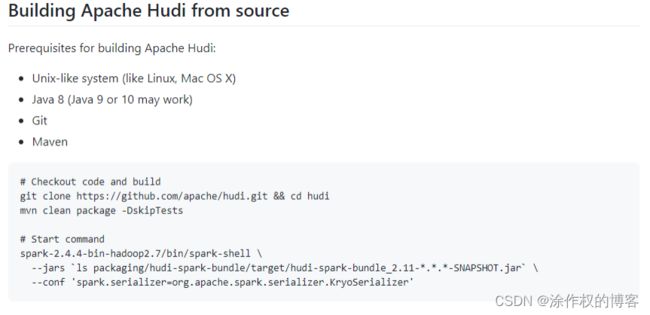
2.1.3 第三步、添加Maven镜像
由于Hudi编译时,需要下载相关依赖包,需要添加Maven镜像仓库路径,以便下载JAR包。
编辑$MAVEN_HOME/conf/settings.xml文件,添加如下镜像:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring插件仓库</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror>
<id>repo2</id>
<name>Mirror from Maven Repo2</name>
<url>https://repo.spring.io/plugins-release/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>UK</id>
<name>UK Central</name>
<url>http://uk.maven.org/maven2</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>jboss-public-repository-group</id>
<name>JBoss Public Repository Group</name>
<url>http://repository.jboss.org/nexus/content/groups/public</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>CN</id>
<name>OSChina Central</name>
<url>http://maven.oschina.net/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>google-maven-central</id>
<name>GCS Maven Central mirror Asia Pacific</name>
<url>https://maven-central-asia.storage-download.googleapis.com/maven2/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>confluent</id>
<name>confluent maven</name>
<url>http://packages.confluent.io/maven/</url>
<mirrorOf>confluent</mirrorOf>
</mirror>
2.1.4 第四步、执行编译命令
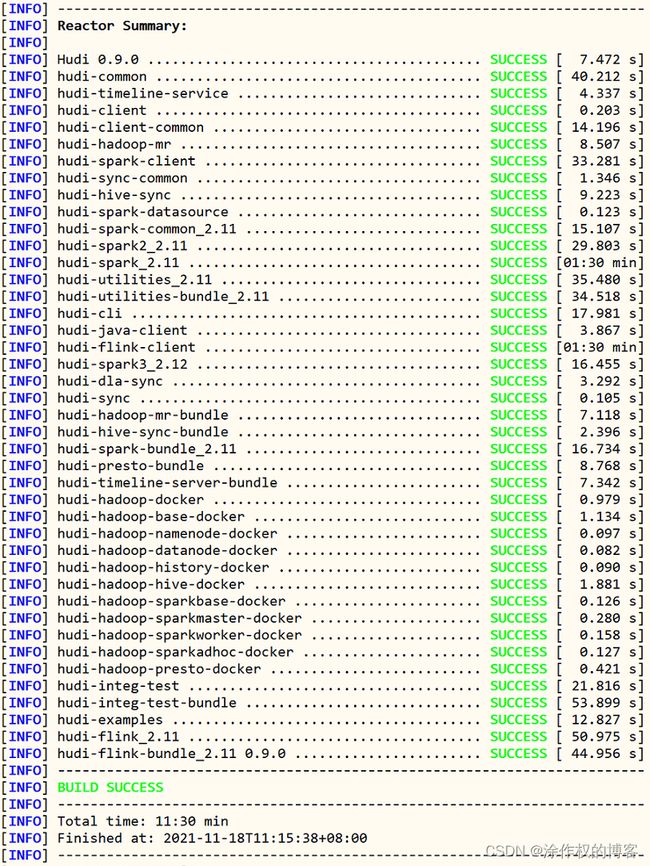
上传下载Hudi源码至CentOS系统目录:/root,解压tar包,进入软件包,执行编译命令:
[root@node1 hudi-0.9.0]# mvn clean install -DskipTests -DskipITs -Dscala-2.12 -Dspark3

编译成功以后,截图如下所示:
2.1.5 第五步、Hudi CLI测试
编译完成以后,进入**$HUDI_HOME/hudi-cli目录,运行hudi-cli**脚本,如果可以运行,说明编译成功,截图如下所示:

2.2 环境准备
Apache Hudi数据湖框架,提供数据管理功能,底层将数据存储到HDFS分布式可靠文件系统之上,默认支持Spark操作数据(保存数据和读取数据),同时支持Flink操作数据,以及与Hive等框架集成,首先搭建伪分布式大数据环境,方便后续Hudi使用。
2.2.1 安装HDFS
首先安装部署HDFS分布式文件系统伪分布式集群,方便后续数据保存。
step1、解压软件包
在node1.itcast.cn机器上解压配置HDFS
[root@node1 ~]# cd /export/software/
[root@node1 software]# rz
[root@node1 software]# tar -zxf hadoop-2.7.3.tar.gz -C /export/server/
解压完成以后,创建hadoop软连接,方便后续软件版本升级和管理。
[root@node1 ~]# cd /export/server/
[root@node1 server]# ln -s hadoop-2.7.3 hadoop
[root@node1 server]# ll
lrwxrwxrwx 1 root root 12 Feb 23 21:35 hadoop -> hadoop-2.7.3
drwxr-xr-x 9 root root 149 Nov 4 17:57 hadoop-2.7.3
step2、配置环境变量
在Hadoop中,bin和sbin目录下的脚本、etc/hadoop下的配置文件,有很多配置项都会使用到HADOOP_*这些环境变量。如果仅仅是配置了HADOOP_HOME,这些脚本会从HADOOP_HOME下通过追加相应的目录结构来确定COMMON、HDFS和YARN的类库路径。
HADOOP_HOME:Hadoop软件的安装路径;
HADOOP_CONF_DIR:Hadoop的配置文件路径;
HADOOP_COMMON_HOME:Hadoop公共类库的路径;
HADOOP_HDFS_HOME:Hadoop HDFS的类库路径;
HADOOP_YARN_HOME:Hadoop YARN的类库路径;
HADOOP_MAPRED_HOME:Hadoop MapReduce的类库路径;
编辑【/etc/profile】文件,命令如下:
vim /etc/profile
添加如下内容:
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行如下命令生效:
source /etc/profile
备注:三台机器都要配置环境变量,便使之生效,方便后续直接使用命令。
step3、hadoop-env.sh
在Hadoop环境变量脚本配置JDK和HADOOP安装目录,命令和内容如下。
执行命令:
[root@node1 ~]# vim /export/server/hadoop/etc/hadoop/hadoop-env.sh
修改内容如下:
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
step4、core-site.xml
配置Hadoop Common模块公共属性,编辑core-site.xml文件,命令和内容如下。
执行命令:
[root@node1 ~]# vim /export/server/hadoop/etc/hadoop/core-site.xml
增加配置内容:
fs.defaultFS</name>
hdfs://node1.itcast.cn:8020</value>
</property>
hadoop.tmp.dir</name>
/export/server/hadoop/datas/tmp</value>
</property>
hadoop.http.staticuser.user</name>
root</value>
</property>
创建临时数据目录,命令如下:
[root@node1 ~]# mkdir -p /export/server/hadoop/datas/tmp
step5、hdfs-site.xml
配置HDFS分布式文件系统相关属性,具体命令和内容如下所示:
执行命令:
[root@node1 ~]# vim /export/server/hadoop/etc/hadoop/hdfs-site.xml
增加配置内容:
dfs.namenode.name.dir</name>
/export/server/hadoop/datas/dfs/nn</value>
</property>
dfs.datanode.data.dir</name>
/export/server/hadoop/datas/dfs/dn</value>
</property>
dfs.replication</name>
1</value>
</property>
dfs.permissions.enabled</name>
false</value>
</property>
dfs.datanode.data.dir.perm</name>
750</value>
</property>
创建数据目录,命令如下:
[root@node1 ~]# mkdir -p /export/server/hadoop/datas/dfs/nn
[root@node1 ~]# mkdir -p /export/server/hadoop/datas/dfs/dn
step6、workers
配置HDFS集群中从节点DataNode所运行机器,,具体命令和内容如下所示:
执行命令:
[root@node1 ~]# vim /export/server/hadoop/etc/hadoop/workers
增加配置内容:
node1.itcast.cn
step7、格式化HDFS
第一次启动HDFS文件之前,先格式HDFS文件系统,命令如下:
[root@node1 ~]# hdfs namenode -format
step8、启动HDFS集群
在node1.itcast.cn上启动HDFS集群服务:NameNode和DataNodes,命令如下:
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
查看HDFS WEB UI,地址为:http://node1.itcast.cn:50070/

2.2.2 安装Spark 3.x
将编译完成spark安装包【spark-3.0.0-bin-hadoop2.7.tgz】解压至【/export/server】目录:
## 解压软件包
tar -zxf /export/software/spark-3.0.0-bin-hadoop2.7.tgz -C /export/server/
## 创建软连接,方便后期升级
ln -s /export/server/spark-3.0.0-bin-hadoop2.7 /export/server/spark
其中各个目录含义如下:

- 第一步、安装Scala-2.12.10
## 解压Scala
tar -zxf /export/softwares/scala-2.12.10.tgz -C /export/server/
## 创建软连接
ln -s /export/server/scala-2.12.10 /export/server/scala
## 设置环境变量
vim /etc/profile
### 内容如下:
# SCALA_HOME
export SCALA_HOME=/export/server/scala
export PATH=$PATH:$SCALA_HOME/bin
- 第二步、修改配置名称
## 进入配置目录
cd /export/server/spark/conf
## 修改配置文件名称
mv spark-env.sh.template spark-env.sh
- 第三步、修改配置文件,$SPARK_HOME/conf/spark-env.sh,增加如下内容:
## 设置JAVA和SCALA安装目录
JAVA_HOME=/export/server/jdk
SCALA_HOME=/export/server/scala
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
截图如下:

本地模式启动spark-shell:
## 进入Spark安装目录
cd /export/server/spark
## 启动spark-shell
bin/spark-shell --master local[2]
运行成功以后,有如下提示信息:

将$【SPARK_HOME/README.md】文件上传到HDFS目录【/datas】,使用SparkContext读取文件,命令如下:
## 上传HDFS文件
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /export/server/spark/README.md /datas
## 读取文件
val datasRDD = sc.textFile("/datas/README.md")
## 条目数
datasRDD.count
## 获取第一条数据
datasRDD.first
相关截图如下:

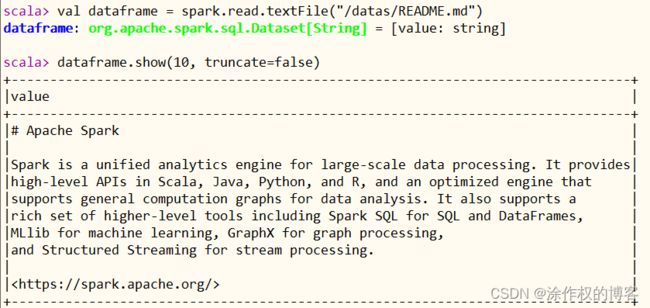
使用SparkSession对象spark,加载读取文本数据,封装至DataFrame中,截图如下:
2.3 spark-shell 使用
首先使用spark-shell命令行,以本地模式(LocalMode:–master local[2])方式运行,模拟产生Trip乘车交易数据,将其保存至Hudi表,并且从Hudi表加载数据查询分析,其中Hudi表数据最后存储在HDFS分布式文件系统上。
启动伪分布式HDFS文件系统命令如下:
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
2.3.1 启动spark-shell
在spark-shell命令行,对Hudi表数据进行操作,需要运行spark-shell命令时,添加相关依赖包,官方命令(针对Spark3及Hudi 0.9)如下:
spark-shell \
--master local[2] \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1 \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
上述命令需要联网,基于ivy下载相关jar包到本地,然后加载到CLASSPATH中。其中包含3个jar包:

此外,可以将上述三个jar包下载下来,上传到虚拟机,命令如下:
[root@node1 ~]# cd /root
[root@node1 ~]# mkdir -p hudi-jars
# 上传JAR包
[root@node1 ~]# rz

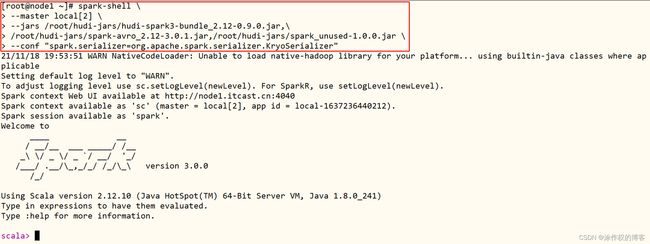
启动spark-shell时,通过–jars指定,具体操作命令如下所示:
spark-shell \
--master local[2] \
--jars /root/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar,\
/root/hudi-jars/spark-avro_2.12-3.0.1.jar,/root/hudi-jars/spark_unused-1.0.0.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
截图如下所示:
接下来执行相关代码,保存数据至Hudi表及从Hudi表加载数据。
官方文档:https://hudi.apache.org/docs/spark_quick-start-guide.html
2.3.2 模拟数据
首先导入Spark及Hudi相关包和定义变量(表的名称和数据存储路径),代码如下:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://node1.itcast.cn:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
其中构建DataGenerator对象,用于模拟生成Trip乘车数据,代码如下:
val inserts = convertToStringList(dataGen.generateInserts(10))
上述代码模拟产生10条Trip乘车数据,为JSON格式,如下所示:

接下来,将模拟数据List转换为DataFrame数据集,代码如下:
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
查看转换后DataFrame数据集的Schema信息,如下所示:
df.printSchema()

选择相关字段,查看模拟样本数据,具体如下:
df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10, truncate=false)

2.3.3 插入数据
将上述模拟产生Trip数据,保存到Hudi表中,由于Hudi诞生时基于Spark框架,所以SparkSQL支持Hudi数据源,直接通过format指定数据源Source,设置相关属性保存数据即可,命令如下:
df.write
.mode(Overwrite)
.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(RECORDKEY_FIELD_OPT_KEY, "uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
.option(TABLE_NAME, tableName)
.save(basePath)
采用Scala交互式命令行中paste模式粘贴代码,截图如下:

其中相关参数说明如下:
-
参数:getQuickstartWriteConfigs,设置写入/更新数据至Hudi时,Shuffle时分区数目
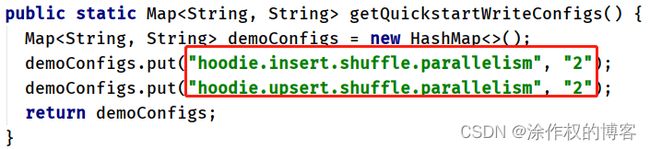
-
参数:PRECOMBINE_FIELD_OPT_KEY,数据合并时,依据主键字段

-
参数:RECORDKEY_FIELD_OPT_KEY,每条记录的唯一id,支持多个字段

-
参数:PARTITIONPATH_FIELD_OPT_KEY,用于存放数据的分区字段

数据保存成功以后,查看HDFS文件系统目录:/datas/hudi-warehouse/hudi_trips_cow,结构如下:
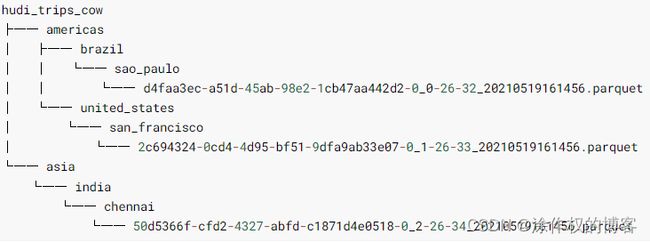
可以发现Hudi表数据存储在HDFS上,以PARQUET列式方式存储的。
2.3.4 查询数据
从Hudi表中读取数据,同样采用SparkSQL外部数据源加载数据方式,指定format数据源和相关参数options,命令如下:
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
其中指定Hudi表数据存储路径即可,采用正则Regex匹配方式,由于保存Hudi表属于分区表,并且为三级分区(相当于Hive中表指定三个分区字段),使用表达式://// 加载所有数据。

打印获取Hudi表数据的Schema信息,如下所示:
tripsSnapshotDF.printSchema()
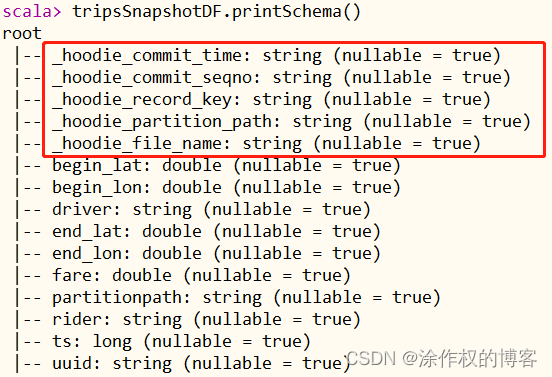
比原先保存到Hudi表中数据多5个字段,这些字段属于Hudi管理数据时使用的相关字段。
将获取Hudi表数据DataFrame注册为临时视图,采用SQL方式依据业务查询分析数据。
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
查询业务一:乘车费用 大于 20 信息数据
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
执行查询分析结果如下:

**查询业务二:**选取字段查询数据
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
执行查询分析结果如下:

至此,完成将数据保存Hudi表,及从Hudi进行加载数据分析操作。
2.3.5 表数据结构
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用HDFS进行存储。以HDFS存储来看,一个Hudi表的存储文件分为两类。

- .hoodie 文件:由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
- amricas和asia相关的路径是实际的数据文件,按分区存储,分区的路径key是可以指定的。
2.3.5.1 .hoodie文件
Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline。Timeline中某一次的操作,叫做Instant。Instant包含以下信息:
- Instant Action,记录本次操作是一次数据提交(COMMITS),还是文件合并(COMPACTION),或者是文件清理(CLEANS);
- Instant Time,本次操作发生的时间;
- State,操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是已完成(COMPLETED);
.hoodie文件夹中存放对应操作的状态记录:

2.3.5.2 数据文件
Hudi真实的数据文件使用Parquet文件格式存储,截图如下所示:
![]()
其中包含一个metadata元数据文件和数据文件parquet列式存储。
Hudi为了实现数据的CRUD,需要能够唯一标识一条记录。Hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键。
2.3.6 Hudi 数据存储概述
Hudi数据集的组织目录结构与Hive表示非常相似,一份数据集对应这一个根目录。数据集被打散为多个分区,分区字段以文件夹形式存在,该文件夹包含该分区的所有文件。

- 在根目录下,每个分区都有唯一的分区路径,每个分区数据存储在多个文件中。
- 每个文件都有惟一的fileId和生成文件的commit所标识。如果发生更新操作时,多个文件共享相同的fileId,但会有不同的commit。
- 每条记录由记录的key值进行标识并映射到一个fileId。
一条记录的key与fileId之间的映射一旦在第一个版本写入该文件时就是永久确定的。换言之,一个fileId标识的是一组文件,每个文件包含一组特定的记录,不同文件之间的相同记录通过版本号区分。
2.3.6.1 Metadata 元数据
以时间轴(timeline)的形式将数据集上的各项操作元数据维护起来,以支持数据集的瞬态视图,这部分元数据存储于根目录下的元数据目录。一共有三种类型的元数据:
- Commits:一个单独的commit包含对数据集之上一批数据的一次原子写入操作的相关信息。我们用单调递增的时间戳来标识commits,标定的是一次写入操作的开始。
- Cleans:用于清除数据集中不再被查询所用到的旧版本文件的后台活动。
- Compactions:用于协调Hudi内部的数据结构差异的后台活动。例如,将更新操作由基于行存的日志文件归集到列存数据上。
2.3.6.2 Index 索引
Hudi维护着一个索引,以支持在记录key存在情况下,将新记录的key快速映射到对应的fileId。索引的实现是插件式的。
- Bloom filter:存储于数据文件页脚。默认选项,不依赖外部系统实现。数据和索引始终保持一致。
- Apache HBase :可高效查找一小批key。在索引标记期间,此选项可能快几秒钟。
2.3.6.3 Data 数据
Hudi以两种不同的存储格式存储所有摄取的数据。这块的设计也是插件式的,用户可选择满足下列条件的任意数据格式:
- 读优化的列存格式(ROFormat),缺省值为Apache Parquet;
- 写优化的行存格式(WOFormat),缺省值为Apache Avro;
2.4 IDEA 编程开发
Apache Hudi最初是由Uber开发的,旨在以高效率实现低延迟的数据库访问。Hudi 提供了Hudi 表的概念,这些表支持CRUD操作。接下来,基于Spark框架使用Hudi API 进行读写操作。

2.4.1 准备环境
创建Maven Project工程,添加Hudi及Spark相关依赖jar包,POM文件内容如下所示:
<repositories>
<repository>
<id>aliyunid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
<repository>
<id>jbossid>
<url>http://repository.jboss.com/nexus/content/groups/publicurl>
repository>
repositories>
<properties>
<scala.version>2.12.10scala.version>
<scala.binary.version>2.12scala.binary.version>
<spark.version>3.0.0spark.version>
<hadoop.version>2.7.3hadoop.version>
<hudi.version>0.9.0hudi.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-spark3-bundle_2.12artifactId>
<version>${hudi.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-avro_2.12artifactId>
<version>${spark.version}version>
dependency>
dependencies>
<build>
<outputDirectory>target/classesoutputDirectory>
<testOutputDirectory>target/test-classestestOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resourcesdirectory>
resource>
resources>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
创建相关Maven Project工程目录结构,如下图所示:

其中将HDFS Client配置文件放入工程Project的resources目录下,方便将Hudi表数据存储HDFS上。
2.4.2 代码结构
基于Spark DataSource数据源,模拟产生Trip乘车交易数据,保存到Hudi表(COW类型: Copy on Write),再从Hudi表加载数据分析查询,具体任务需求如下:
任务一:模拟数据,插入Hudi表,采用COW模式
任务二:快照方式查询(Snapshot Query)数据,采用DSL方式
任务三:更新(Update)数据
任务四:增量查询(Incremental Query)数据,采用SQL方式
任务五:删除(Delete)数据
在工程中创建包【cn.itcast.hudi.spark】,并创建对象:HudiSparkDemo,编写MAIN方法,定义任务需求及功能代码结构:
def main(args: Array[String]): Unit = {
// 创建SparkSession实例对象,设置属性
val spark: SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
}
val tableName: String = "tbl_trips_cow"
val tablePath: String = "/hudi-warehouse/tbl_trips_cow"
// 构建数据生成器,为例模拟产生插入和更新数据
import org.apache.hudi.QuickstartUtils._
// 任务一:模拟数据,插入Hudi表,采用COW模式
//insertData(spark, tableName, tablePath)
// 任务二:快照方式查询(Snapshot Query)数据,采用DSL方式
//queryData(spark, tablePath)
//queryDataByTime(spark, tablePath)
//Thread.sleep(10000)
// 任务三:更新(Update)数据
//val dataGen: DataGenerator = new DataGenerator()
//insertData(spark, tableName, tablePath, dataGen)
//updateData(spark, tableName, tablePath, dataGen)
// 任务四:增量查询(Incremental Query)数据,采用SQL方式
//incrementalQueryData(spark, tablePath)
//任务五:删除(Delete)数据
deleteData(spark, tableName, tablePath)
// 应用结束,关闭资源
spark.stop()
}
接下来,按照任务说明,一个个完成任务代码编写。
2.4.3 插入数据Insert
使用官方QuickstartUtils提供模拟产生Trip数据类,模拟100条交易Trip乘车数据,将其转换为DataFrame数据集,保存至Hudi表中,代码基本与spark-shell命令行一致,如下所示:
/**
* 官方案例:模拟产生数据,插入Hudi表,表的类型COW
*/
def insertData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
// TODO: a. 模拟乘车数据
import org.apache.hudi.QuickstartUtils._
val dataGen: DataGenerator = new DataGenerator()
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read
.json(spark.sparkContext.parallelize(inserts.asScala, 2).toDS())
//insertDF.printSchema()
//insertDF.show(10, truncate = false)
// TODO: b. 插入数据至Hudi表
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
.mode(SaveMode.Append)
.format("hudi") // 指定数据源为Hudi
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性设置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
执行代码,查看HDFS文件系统路径下是否保存相关数据。
2.4.4 查询数据Query
采用Snapshot快照方式从Hudi表查询数据,编写DSL代码,按照业务分析数据,代码如下:
/**
* 官方案例:采用Snapshot Query快照方式查询表的数据
*/
def queryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
//tripsDF.printSchema()
//tripsDF.show(10, truncate = false)
// 查询费用大于20,小于50的乘车数据
tripsDF
.filter($"fare" >= 20 && $"fare" <= 50)
.select($"driver", $"rider", $"fare", $"begin_lat", $"begin_lon", $"partitionpath", $"_hoodie_commit_time")
.orderBy($"fare".desc, $"_hoodie_commit_time".desc)
.show(20, truncate = false)
}
执行上述代码,显示结果如下;
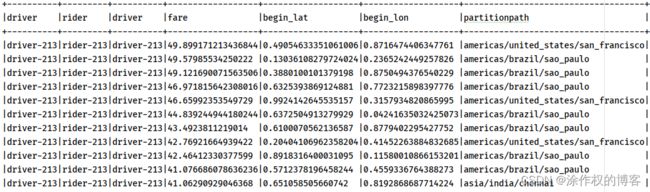
查询Hudi表数据,可以依据时间进行过滤查询,设置属性:“as.of.instant”,值的格式:“20210728141108"或"2021-07-28 14: 11: 08”,代码演示如下:
/**
* 官方案例:采用时间过滤查询数据
*/
def queryDataByTime(spark: SparkSession, path: String): Unit = {
import org.apache.spark.sql.functions._
// 方式一:指定字符串,格式 yyyyMMddHHmmss
val df1 = spark.read
.format("hudi")
.option("as.of.instant", "20211119095057")
.load(path)
.sort(col("_hoodie_commit_time").desc)
df1.show(numRows = 5, truncate = false)
// 方式二:指定字符串,格式yyyy-MM-dd HH:mm:ss
val df2 = spark.read
.format("hudi")
.option("as.of.instant", "20211119095057")
.load(path)
.sort(col("_hoodie_commit_time").desc)
df2.show(numRows = 5, truncate = false)
}
2.4.5 更新数据Update
Hudi数据湖框架最大优势就是支持对数据的Upser操作(插入或更新),接下来更新Update数据。由于官方提供工具类DataGenerator模拟生成更新update数据时,必须要与模拟生成插入insert数据使用同一个DataGenerator对象,所以重新编写insertData插入数据方法。
/**
* 官方案例:模拟产生数据,插入Hudi表,表的类型COW
*/
def insertData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator): Unit = {
import spark.implicits._
// TODO: a. 模拟乘车数据
import org.apache.hudi.QuickstartUtils._
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read
.json(spark.sparkContext.parallelize(inserts.asScala, 2).toDS())
//insertDF.printSchema()
//insertDF.show(10, truncate = false)
// TODO: b. 插入数据至Hudi表
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
.mode(SaveMode.Overwrite)
.format("hudi") // 指定数据源为Hudi
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性设置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
更新数据方法:updateData,先生成更新数据,再保存至Hudi表,代码如下:
/**
* 官方案例:更新Hudi数据,运行程序时,必须要求与插入数据使用同一个DataGenerator对象,更新数据Key是存在的
*/
def updateData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator): Unit = {
import spark.implicits._
// TODO: a、模拟产生更新数据
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConverters._
val updates = convertToStringList(dataGen.generateUpdates(100))
val updateDF = spark.read.json(spark.sparkContext.parallelize(updates.asScala, 2).toDS())
// TODO: b、更新数据至Hudi表
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
updateDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
2.4.6 增量查询Incremental query
当Hudi中表的类型为:COW时,支持2种方式查询:Snapshot Queries、Incremental Queries,默认情况下查询属于:Snapshot Queries快照查询,通过参数:hoodie.datasource.query.type 可以进行设置。

如果是incremental增量查询,需要指定时间戳,当Hudi表中数据满足:instant_time > beginTime时,数据将会被加载读取。此外,也可以设置某个时间范围:endTime > instant_time > begionTime,获取相应的数据,官方源码说明如下:

接下来,首先从Hudi表加载所有数据,获取其中字段值:_hoodie_commit_time,从中选取一个值,作为增量查询:beginTime开始时间;再次设置属性参数,从Hudi表增量查询数据,具体代码如下所示:
/**
* 官方案例:采用Incremental Query增量方式查询表的数据
*/
def incrementalQueryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
// TODO: a. 加载Hudi表数据,获取commitTime时间,作为增量查询时间阈值
import org.apache.hudi.DataSourceReadOptions._
spark.read
.format("hudi")
.load(path)
.createOrReplaceTempView("view_temp_hudi_trips")
val commits: Array[String] = spark
.sql(
"""
|select
| distinct(_hoodie_commit_time) as commitTime
|from
| view_temp_hudi_trips
|order by
| commitTime DESC
|""".stripMargin
)
.map(row => row.getString(0))
.take(50)
val beginTime = commits(commits.length - 1) // commit time we are interested in
println(s"beginTime = ${beginTime}")
// TODO: b. 设置Hudi数据CommitTime时间阈值,进行增量查询数据
val tripsIncrementalDF = spark.read
.format("hudi")
// 设置查询数据模式为:incremental,增量读取
.option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL)
// 设置增量读取数据时开始时间
.option(BEGIN_INSTANTTIME.key(), beginTime)
.load(path)
// TODO: c. 将增量查询数据注册为临时视图,查询费用fare大于20的数据信息
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark
.sql(
"""
|select
| `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts
|from
| hudi_trips_incremental
|where
| fare > 20.0
|""".stripMargin
)
.show(10, truncate = false)
}
上述代码,采用将DataFrame注册为临时视图,编写SQL语句,增量查询数据,运行结果如下:

2.4.7 删除数据Delete
使用DataGenerator数据生成器,基于已有数据构建要删除的数据,最终保存到Hudi表中,当时需要设置属性参数:hoodie.datasource.write.operation 值为:delete。
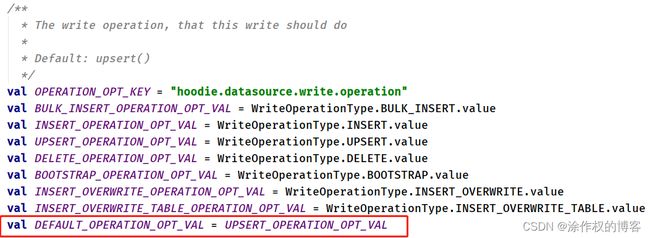
编写方法:deleteData,先从Hudi表获取2条数据,然后构建出数据格式,最后保存到Hudi表,具体代码如下所示:
/**
* 官方案例:删除Hudi表数据,依据主键UUID进行删除,如果是分区表,指定分区路径
*/
def deleteData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
// TODO: a. 加载Hudi表数据,获取条目数
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Count = ${tripsDF.count()}")
// TODO: b. 模拟要删除的数据
val dataframe: DataFrame = tripsDF.select($"uuid", $"partitionpath").limit(2)
import org.apache.hudi.QuickstartUtils._
val dataGen: DataGenerator = new DataGenerator()
val deletes = dataGen.generateDeletes(dataframe.collectAsList())
import scala.collection.JavaConverters._
val deleteDF = spark.read.json(spark.sparkContext.parallelize(deletes.asScala, 2))
// TODO: c. 保存数据至Hudi表,设置操作类型为:DELETE
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
deleteDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// 设置数据操作类型为delete,默认值为upsert
.option(OPERATION.key(), "delete")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
// TODO: d. 再次加载Hudi表数据,统计条目数,查看是否减少2条
val hudiDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Delete After Count = ${hudiDF.count()}")
}