领域驱动设计DDD(一)
领域驱动设计DDD(一)
- 一、何为领域驱动设计
- 二、模型驱动设计
-
- (一)分层架构
- (二)实体
- (三)值对象
- (四)服务
- (五)模块
- (六)聚合
- (七)工厂
- (八)资源库
- 三、面向深层理解的重构
-
- (一)如何凸显关键概念
-
- 1. 增加约束
- 2. 添加过程
- 3 .添加规约
- 四、保持模型的一致性
-
- (一)界定的上下文
- (二)持续集成
- (三)上下文映射
- (四)共享内核(Shared Kernel)
- (五)客户-供应商(Customer-Supplier)
- (六)顺从者
- (七)防崩溃层(Anticorruption Layer)
- (八)隔离通道(Separate Way)
- (九)开放主机服务(Open Host Service)
- (十)提炼
一、何为领域驱动设计
在进行项目开发之前,应当对整个项目 所处的领域有深刻的理解,比如你要做银行软件系统,如果对银行业领域不了解,这样开发出来的软件能好吗?所以开发人员 要和 银行领域内的专家进行沟通,从而初步构建出一个模型,用于软件开发。
但是开发人员 满脑子的继承多态,银行专业人员有属于他们的术语,两者如何沟通就成为一大问题,因此需要公共语言(通用语言)。如何选择公共语言呢?领域驱动设计的一个核心的原则是 使用一种 基于模型 的语言。因为模型是 软件满足领域的共同点,所以它很适合作为这种通用语言的 构造基础。
那么如何创建模型呢?我的理解是,就是通过我们日常的冗余对话,提取关键信息点,用图的形式 形象概括对话内容,图中表明类与类之间的对应关系,所以有人会说UML图 很适合用来构建模型,它形象表明了类与类之间的对应关系,但是一旦当类的数量多起来, UML图就变得非常庞大,根本看不进去,这时候有人会说,用文档的形式,把UML类图拆成一个个小的部分,这样每个部分就像聚光灯一样只专注于领域的一个部分,但如果文档也很冗余呢?
再加上,这个模型的构建,需要能够很好的转变为代码,如果这个模型的构建 不能够很好的服务于 最终项目的落地实现(也就是说,模型和代码之间也不再存在映射关系),那么开发人员在实际设计时,逼不得已要做出不同于模型的修改,以便能够解决实际问题,这样模型就没有什么用了。所以需要开发人员的加入,来构建模型,一旦开发人员加入模型构建,我们就需要明白,使用面向对象编程能够更好的实现模型。
综上,便是模型的设计需要考虑的因素。
二、模型驱动设计
对于模型驱动设计而言,推荐使用面向对象编程。下面介绍 模型驱动设计中 要使用的最重要的模式。这些模式的作用是 从领域驱动设计的角度 展现一些 对象建模和软件设计中 的关键元素。下图展现的是模式和模式间关系的总图。
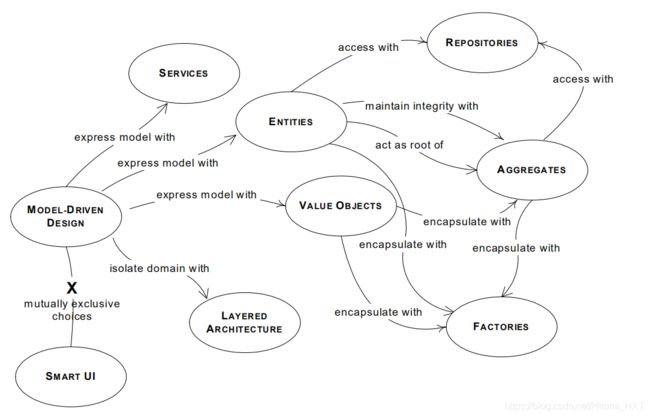
(一)分层架构
目的:解耦合
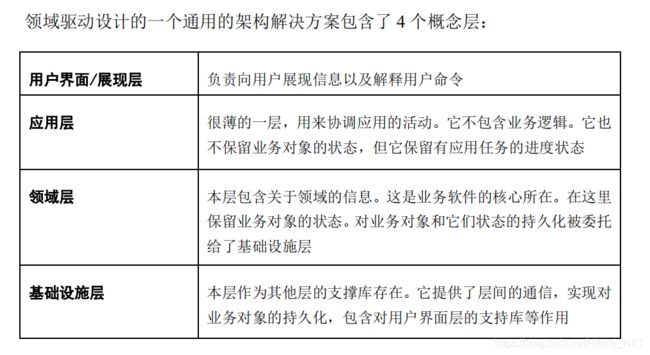
举个栗子:应用层、领域层和基础设施层之间的一个典型交互,看上去会是这样:用户想要预定一个飞行路线,请求一个位于应用层中的应用服务来做这件事情。应用层从基础设施层中取得相关的领域对象,然后调用它们的相关方法,例如检查与其他已经被预定的飞行线路的安全界限(security margins)。当领域对象执行完所有的检查并将它们的状态修改为“已决定”(decided)之后,应用服务将对象持久化到基础设施中。
(二)实体
如果我们要用软件程序实现一个“人”的概念,我们可能会创建一个 Person 类,这个类会带有一系列的属性,例如:名称,出生日期,出生地等。这些属性中有哪个可以作为 Person 的标识符吗?名字不可以作为标识符,因为可能有很多人拥有同一个名字。通常标识符或是对象的一个属性(或属性的组合),这里的标识符,有点像数据库的主键。更加重要的是,系统能够轻易区分开 两个拥有不同标识符的对象,或者将两个使用了 相同标识符的对象 看做是相同的,我们把拥有标识符的对象叫做实体。
(三)值对象
用来描述领域的特定方面、并且没有标识符的一个对象,叫做值对象。极力推荐将值对象实现为不可变的。
实现为不可变的,并且不具有标识符,值对象就能够被共享了。
实体和值对象的区别:有无标识符。值对象比实体低一个等级的感觉,但是值对象可以被共享。
值对象 可以包含 其他的值对象,它们甚至还可以包含 对实体对象的引用。尽管值对象 仅仅用来包含 一个领域对象的属性,但这并不意味着 它应该包含一长列所有的属性。属性可以被分组到不同的对象中。被选择用来构成一个值对象的属性 应该形成一个概念上的整体。一个客户会跟其姓名、街道、城市、州相关。最好用一个单独的对象 来包含这些地址信息,客户对象会包含一个对这个对象的引用。街道、城市、州应该归属于一个对象,因为它们在概念上属于一体的,而不应该作为客户对象分离的属性。
(四)服务
在我们开发通用语言时,领域中的关键概念被引入到语言中,语言中的名词很容易被映射成对象。语言中对应那些名词的动词成为了那些对象的行为。但是有些领域中的动作,它们是一些动词,看上去却不属于任何对象。它们代表了领域中的一个重要的行为,所以不能忽略它们或者简单地把它们合并到某个实体或者值对象中。给一个对象增加这样的行为会破坏这个对象,让它看上去拥有了本不该属于它的功能。但是,要使用一种面向对象语言,我们必须使用一个对象才行。我们不能只拥有一个单独的功能,它必须附属于某个对象。通常这种行为类的功能会跨越若干个对象,或许是不同的类。例如,为了从一个账户向另一个账户转钱,这个功能应该放到转出的账户还是在接
收的账户中?感觉放在这两个中的哪一个也不对劲。也就是说,有些行为方法不知道应该属于哪个对象,这个时候就可以把它放到服务里面,它的作用仅仅是为领域提供相应的功能。
成为服务要满足什么样的要求呢?
- 服务执行的操作代表了一个领域概念,这个领域概念无法自然地隶属于一个实体或者值对象。也就是说,这个行为方法属于哪一个对象都不太合适。
- 被执行的操作涉及到领域中的其他的对象。也就是说,这个服务本身就和很多类相关。
- 操作是无状态的。
很容易弄混 属于领域层的服务 和 属于基础设施层的服务,不论是应用服务 还是 领域服务,通常都是建立在 领域的实体对象 和 值对象 之上,以便提供与这些对象 直接相关的服务。决定一个服务 应该归属于哪一层是很困难的。如果所执行的操作 概念上属于应用层,那么服务 就应该放到这个层。如果操作是关于领域对象的,而且确实是与领域有关的、为领域的需要服务,那么它就应该属于领域层。
举个栗子:让我们考虑一个实际的 Web 报表应用的例子。报表使用存储在数据库中的数据,它们会基于模版来生成。最终的结果是一个在 Web 浏览器中可以显示给用户查看的HTML 页面。
用户界面层被包含在 Web 页面中,允许用户登录,选择想要查看的报表,单击一个按钮就来请求这个报表。应用层是很薄的一层,它位于用户界面层与领域层、基础设施层之间。在登录操作时,它会跟数据库基础设施进行交互;在需要创建报表时会和领域层进行交互。领域层中包含了领域的核心部分,与报表直接相关的对象。有两个这样的对象,Report 和 Template,它们是生成报表的基础。基础设施层将支持数据库访问和文件访问。
当用户选择创建一个报表时,他实际上从名称列表中选择了一个报表名称。这是一个字符串类型的 reportID。还会传递其他的参数,例如要在报表中显示的条目、报表中所包括数据的时间间隔等。但出于简化的考虑我们将只提到 reportID。这个名称会通过应用层被传递到领域层。由领域层负责根据所给的名称来创建并返回报表。因为报表会基于模版产生,我们需要创建一个服务,它的作用是根据一个reportID获得对应的模版,这个模版被保存在一个文件或者数据库中。保存操作不适于作为 Report 对象自身的一个操作。它也同样不属于 Template 对象。所以我们创建了一个独立的服务,这个服务的目的是基于一个报表的标识符来获取一个报表模版。这会是一个位于领域层的服务。它会通过使用文件方面的基础设施,从磁盘上获取模版。
(五)模块
对一个大型的复杂项目而言,模型趋向于越来越大。当模型发展到了某个规模时,就需要将其细分,再加上代码应当具有高层次的内聚性和低层次的耦合性,因此引入模块。推荐的做法是将高关联度的类分组到一个模块,以提供尽可能大的内聚性。模块与模块之间通过接口的方式进行通信。
内聚性分为:
- 通信性内聚:在模块中的部件操作相同的数据时,可以得到通信性内聚。把它们分到一组很有意义,因为它们之间存在很强的关联性。
- 功能性内聚:在模块中的部件协同工作以完成定义好的任务时,可以得到功能性内聚。功能性内聚被认为是最佳的内聚类型。
给定的模块名称会成为通用语言的组成部分。模块和它们的名称应该能够反映出对领域的深层理解。
设计人员会习惯地从一开始就创建模块,模块的角色被决定以后通常会保持不变,尽管模块的内部会发生很多变化。
模块的重构成本要比类的重构昂贵的多,但是如果发现了一个模块设计方面的错误,还是需要解决这个问题的。可以先改变模块,然后再寻求更进一步的解决途径。
(六)聚合
对象之间存在关联,当一个对象发生变化的时候,所涉及到的数据变化是连锁的,这时就很难保证一致性,在数据库里面,会使用事务来保证其一致性。聚合也是类似的作用,聚合是针对 数据变化可以考虑成一个单元 的一组关联的对象。聚合使用边界 将内部和外部的对象 划分开来。每个聚合都有一个根。这个根是一个实体,并且它是外部可以访问的唯一的对象。根对象可以持有 对 任意 聚合对象的引用,其他的对象可以 互相 持有彼此的引用,但一个外部对象 只能 持有对根对象的引用。如果边界内 还有其他的实体,那些实体的标识符是本地化的,只在聚合内有意义。

聚合是如何保持数据一致性和强化不变量的呢?
因为其他对象 只能持有 对根对象的引用,这意味着它们不能直接变更 聚合内的其他的对象。它们所能做的就是对根做变更,或者请求根来执行某些动作。根能够变更其他对象,但这是聚合内包含的操作,并且它是可控的。如果根从内存中被删除并移除,聚合内的其他所有的对象也将被删除,因为再不会有其他的对象持有对它们当中的任何一个的引用了。当针对根对象的变更 间接影响到聚合内 的其他对象,强化不变量变得很简单,因为根将做这件事情。如果外部对象能直接访问内部对象 并且变更它们时,强化不变量将变得困难的多。在这种情况下,强化不变量意味着将某些逻辑放到外部对象中去处理,这不是我们所期望的。
根对象可能会将 内部对象的临时引用 传递给外部对象,作为限制,当操作完成之后,外部对象 不能再持有这个引用。一种简单的实现方式是 向外部对象传递 值对象 的副本。在这些副本对象上 发生了什么不重要,因为它不会以任何方式影响到聚合的一致性。
如果一个聚合中的对象被保存到数据库中,可以通过查询来获得的应该只有根对象。其他的对象只能通过从根对象出发导航关联对象来获得。聚合内的对象 可以被允许持有 对其他聚合的根对象的引用。根实体拥有全局的标识符,并且有责任维护不变量。内部的实体拥有内部的标识符。
将 实体 和 值对象 聚集在聚合之中,并且定义各个聚合之间的边界。为每个聚合选择一个实体作为根,并且通过根 来控制所有边界内的对象的访问。允许外部对象 仅持有对根的引用。对内部成员的临时引用可以被传递出来,但是仅能用于 单个操作 之中。因为由根对象来进行访问控制,将无法盲目地对内部对象进行变更。这种安排使得强化聚合内对象的不变量变得可行,并且对聚合而言,它在任何状态变更中都是作为一个整体。
(七)工厂
用于处理对象的创建问题——让工厂帮忙创建
实体和聚合常常会很大很复杂,过于复杂以至于难以通过根实体的构造器来创建。实际上通过构造器努力构建一个复杂的聚合,并不是领域本身通常应该做的事情,在领域中,某些事物通常是由别的事物创建的(例如电器是在生产线上被创建的)。通过根实体的构造器来构建复杂的聚合,看上去就像是要用打印机构建打印机本身。
当一个客户对象(client object)想创建另一个对象时,它会调用它的构造器,可能还会传递某些参数。但是当对象构建 是一个很费力的过程时,创建这个对象 会涉及到大量的知识,例如对象的内部结构、所包含对象之间关系的 以及应用在这些对象上的规则。这意味着该对象的每个客户 将持有关于该对象构建的专用知识。这破坏了对于领域对象 和聚合的封装。如果客户属于应用层,领域层的一部分将被移到了外边,从而打乱整个设计。在真实生活中,这就像是给我们塑胶、橡胶、金属、硅,让我们来构建自己的打印机,这不是不可能完成的。也就是说,我们用参数去构建最终需要的对象。
创建一个对象 可以是它自身的主要操作,但是复杂的组装操作 不应该成为被创建对象的职责。因此,有必要引入一个新的概念,这个概念可以帮助封装复杂的 对象创建过程,它就是工厂(Factory)。
工厂被用来封装对象创建所必需的知识,它们对创建聚合特别有用。当聚合的根被创建后,所有聚合包含的对象将随之创建,保持创建过程的原子性非常重要。因此,为复杂对象和聚合创建实例的职责,应该转交给一个单独的对象。虽然这个对象本身在领域模型中没有职责,但它仍是领域设计的一部分。提供一个接口来封装所有复杂的组装过程,客户不需要引用正在初始化的对象所对应的具体类。将整个聚合 当作一个单元来创建。有很多的设计模式可以用来实现工厂模式,我们不会从设计的角度介绍,而是从领域建模的角度来介绍它。
工厂方法是一个对象方法,包含并隐藏了必要的创建其他对象的知识。这在客户试图创建一个 属于某聚合的对象时 是非常有用的。解决方案是给聚合的根添加一个方法,由这个方法来负责对象的创建,强化所有的不变量,返回对那个对象的一个引用或者一个副本。
举个栗子:在容器(container)中包含着具有某种特定类型的组件。当这样的一个组件被创建后能自动归属于一个容器是很有必要的。客户调用容器的 createComponent(Type t)方法,容器实例化一个新的组件。组件的具体类取决于它的类型(通过 createComponent 传入)。在创建之后,组件被增加到容器所包含的组件的集合中,将组件的一个副本返回给客户。

有时候创建一个对象的逻辑会更为复杂,或者创建一个对象还涉及到创建其他一系列对象时(例如,创建一个聚合)。可以使用一个单独的工厂对象来隐藏聚合的内部构造所需要的任务。让我们考虑一个程序模块的例子,在给定一组约束条件的情况下,计算一辆汽车从起点行驶到终点的路线。用户登录 Web 站点后运行应用程序,并指定一个要遵守的约束条件:最短的路线,最快的路线,或者最便宜的路线。可以在被创建的路线上标注用户信息,这些信息需要被保存下来,以便客户下次登录时能够检索到。

路线 ID 的生成器被用来为每一条路线创建一个唯一的标识符,这对一个实体而言是必要的。
当创建一个工厂时,我们被迫违反一个对象的封装原则,而这必须谨慎行事。每当对象中发生了某种变化时,会对构造规则或者某些不变量造成影响,我们需要确保工厂也被更新以支持新的条件。工厂和它们要创建的对象是紧密关联的。这可能是个弱点,但它也有长处。一个聚合包含了一系列密切相关的对象。根的构建与聚合内的其他对象的创建是相关的。会有一些逻辑一同放到聚合中,这些逻辑并不天然属于任何一个对象,因为它总是跟其他对象的构建有关。看起来比较合适的做法是,使用一个专用的工厂类来负责创建整个聚合,在这个工厂类中将包含应该为聚合强化的规则、约束和不变量。这个对象会保持简单,并将完成特定的目的,不会使复杂的构建逻辑混乱不堪。
实体工厂 和 值对象工厂是有差异的。值对象通常是不可变的对象,并且其所有必需的属性需要在创建时完成。当一个对象被创建之后,它必须是有效的,也是最终的,不会再发生变化。实体对象并非是不可变的。在被创建以后,它们可以通过设置某些属性发生变化,但是需要保持所有的不变量。另一个差异源于实体对象需要标识符,而值对象不需要。
有时工厂是不需要的,一个简单的构造器就足够了。在如下情况下应该使用构造器:
- 构造过程并不复杂。
- 一个对象的创建不涉及到其他对象的创建,可以将所有需要的属性传递给构造器。
- 客户对实现很感兴趣,可能希望选择使用策略(Strategy)模式。
- 类是特定的类型,不存在到层级,所以不用在一系列的具体实现中进行选择。
另一个观察角度是工厂需要从无到有创建一个新对象,或者它们需要对先前已经存在 但可能已经持久化到数据库中的 对象进行重建。将实体对象从它们所在的数据库中取回内存中,包含的是一个与创建一个新对象完全不同的过程。重建的新对象不需要一个新的标识,这个对象已经有一个标示符了,对不变量的违反也将区别对待。当从无到有创建一个新对象时,任何对不变量的违反都会产生一个异常。对于从数据库重建的对象,我们不能也这样处理。这个对象需要以某种方式加以修复,这样它们才能正常工作,否则就会有数据的丢失。
(八)资源库
用于处理对象的存储问题
为了从一个聚合中获得一个值对象,客户程序需要向聚合的根发送请求。要使用一个对象,则意味着这个对象已经被创建完毕了。如果个对象是聚合的根,那么它是一个实体,它会被保存为一个持久化的状态,可能是在数据库中,也可能是其他的持久化形式。
使用一个资源库,它的目的是封装所有获取对象引用所需的逻辑。领域对象不需处理基础设施,以得到领域中对其他对象的引用。只需要从资源库中获取它们。
资源库会保存对某些对象的引用。当一个对象被创建之后,它可以被保存到资源库中,可以从资源库中获取到以备后续使用。如果客户程序从资源库中请求一个对象,而资源库中不存在,就会从存储介质中获取它。不管怎样,资源库扮演了一个全局可访问对象的存储地点。
资源库可以包含一个策略。它可能基于特定的策略来访问某个或者另一个持久化存储介质。它可能 会对不同类型的对象 使用不同的存储位置。总之,实现了 领域模型本身 与需要保存对象 或它们的引用、访问底层持久化的基础设施 之间的耦合度。
需要注意的是,资源库的实现可能会非常像是基础设施,然而资源库的接口却是纯粹的领域模型。
工厂和资源库的区别:它们都是模型驱动设计中的模式,它们都能帮助我们管理领域对象的生命周期。
然而工厂关注的是对象的创建,而资源库关注的是已经存在的对象。
资源库可能会在本地缓存对象,但更常见的情况是需要从一个持久化存储中检索它们。
对象可以通过构造器创建,也可以通过一个工厂来构建。
出于这个理由,资源库也可以被看作是一个工厂,因为它会创建对象。然而它不是从无到有创建新的对象,而是重建已有的对象。我们不应该将资源库与工厂混合在一起。
工厂应该用来创建新的对象,而资源库应该用来发现已经创建的对象。
当一个新对象被添加到资源库时,它应该是先由工厂创建好的,然后它应该被传递给资源库,由资源库来保存它。

另外要注意的是工厂是“纯的领域”,而资源库会包含到 基础设施的连接,例如数据库。
三、面向深层理解的重构
(一)如何凸显关键概念
1. 增加约束
举个栗子:我们可以向一个书架添加书籍,但是我们永远不能添加超过它容量的部分。

这个约束可以被视为书架行为的一部分,见下面的 Java 代码
public class Bookshelf {
private int capacity = 20;
private Collection content;
public void add(Book book) {
if(content.size() + 1 <= capacity) {
content.add(book);
} else {
throw new IllegalOperationException(“The bookshelf has reached its limit.”);
}
}
}
我们可以重构这个代码,将约束提取为一个单独的方法。
public class Bookshelf {
private int capacity = 20;
private Collection content;
public void add(Book book) {
if(isSpaceAvailable()) {
content.add(book);
} else {
throw new IllegalOperationException(“The bookshelf has reached its limit.”);
}
}
private boolean isSpaceAvailable() {
return content.size() < capacity;
}
}
将约束置于一个单独的方法,将它显现出来,这样做有很多优点。它很容易阅读,并且每个人都会注意到 add()方法服从于这个约束。如果约束变得更为复杂,还有空间可以向该方法添加更多的逻辑
2. 添加过程
过程(process)通常在代码中被表达为 procedure。从我们开始使用面向对象语言后 我们就不再用 一种过程化的方法,所以我们需要为处理过程选择一个对象,然后给它添加行为。最好的实现过程的方式是 使用服务。如果还有其他的 实现过程的不同方式,我们可以将其算法 封装在一个策略对象中。并不是所有的过程 都必须要显现出来。那么什么时候显现出来呢?如果通用语言中 提到了某个过程,那就应该将它显现出来。
3 .添加规约
规约是用来测试一个对象是否满足特定条件的,或者他们是否已经准备好达成某种目的。它也可以被用来从集合中筛选出一个特定的对象,或者作为某个对象的创建条件。
规则应该被封装到其自身的一个对象中,这将成为客户的规约,并且被保留在领域层中。新的对象将包含一组布尔方法,这些方法用来测试一个客户对象是否有资格获得贷款。每一个方法承担了一个小的测试功能,通过组合所有的方法,可以给出某个原始问题的答案。如果业务规则没有被包含在一个规约对象中,对应的代码会散布到很多对象中,难以保证规则的一致性。
举个栗子:通常情况下,单个规约负责检查一个简单的规则是否得到了满足,若干个这样的规约组合在一起,表达一个复杂的规则,如下:
Customer customer =customerRepository.findCustomer(customerIdentiy);
…
Specification customerEligibleForRefund = new Specification(new CustomerPaidHisDebtsInThePast(),
new CustomerHasNoOutstandingBalances());
if(customerEligibleForRefund.isSatisfiedBy(customer) {
refundService.issueRefundTo(customer);
}
测试简单的规则很简单,只需阅读这段代码,这段代码的含义很明显,表示了一个客户是否有资格获得偿还资金。
四、保持模型的一致性
(一)界定的上下文
我们将一个大模块划分为小模块进行开发的时候,需要对每个小模块进行上下文的界定。目的在于大家各自在各自的模块里开发,不越界,而且最终开发的模块要能够很好的进行合并。
主要的思想是定义模型的范围,定出它的上下文的边界,然后尽最大可能保持模型的统一。在模型跨越整个企业项目时,要保持它的纯洁是很困难的;但是在它被限定到一个特定区域时,要保持它的纯洁就容易得多。明确定义模型所应用的上下文,根据以下因素来明确设置边界:
- 团队的组织结构
- 应用的特定部分中的惯例
- 物理表现(例如代码库、数据库 Schema)
保持模型在这些边界里严格一致,不要因外界因素而产生干扰或混淆。界定的上下文并不是模块。界定的上下文提供有模型在其中进化的逻辑框架。模块是被用来组织模型的元素,因此界定的上下文包含了模块。
当不同的团队不得不共同工作于一个模型时,我们必须小心不要踩到别人的脚(译者注:意思为各司其职,不越界)。要时刻意识到任何针对模型的变更都有可能破坏现有的功能。当使用多个模型时,每个人在自己的模型之上可以自由地工作。我们都知道自己模型的界限,都恪守在这些边界里。我们需要确保模型的纯洁、一致和统一。
举个栗子,我们要创建一个用来在互联网上卖东西的电子商务应用。
- 这个应用允许客户注册,然后我们收集他们的个人数据,包括信用卡号码。数据保存在一个关系型数据库里面。
- 客户被允许登录,通过浏览网站寻找商品,然后下单。不论在什么时候下单,应用都需要发布一个事件,因为必须有人邮寄请求的货物。
- 我们还想做一个用于创建报表的报表界面,这样我们就能够监视可售卖货物的状态、哪些是客户感兴趣购买的、哪些是不受欢迎的等等。
开始的时候,我们用一个模型涵盖整个电子商务的领域。这样做有很大的诱惑性,毕竟我们被要求创建一个大的应用。但是仔细考虑手头的任务之后,我们发现这个在线购物应用其实和报表关联度不大。它们有不同的关注点,操作不同的概念,甚至需要用到不同的技术。唯一共通的地方是客户和商品的数据都存储在数据库里,两个应用都会访问这些数据。推荐的做法是为每一个领域创建一个独立的模型,一个是电子商务的模型,一个是报表的模型。它们两个可以在互不关注的情况下自由进化,甚至可以变成独立的应用。也许报表应用会用到电子商务应用应该存储在数据库里的一些特定数据,但多数情况下它们彼此独立发展。 - 还需要有个消息发送系统将订单信息通知仓库工作人员,这样他们就可以邮寄被购买的商品。
邮寄人员也会用到一个应用,该应用可以提供给他们关于所购买的商品条目、数量、客户地址以及交付需求等详细信息。不需要使在线购物(e-shop)模型来涵盖两个活动领域。对在线购物而言,用异步消息的方式将包含购买信息的值对象发送给仓库,这样做要简单的多。这样就清楚地得到了两个可以独立开发的模型,我们只需要确保它们之间的接口工作良好就可以了。
(二)持续集成
一旦上下文被界定出来,就说明我们要进行分模块开发,此时就需要保证团队间的沟通,同时我们在开发过程中会出现新概念新代码的引入,此时就要保证新元素的引入可以和旧元素的和谐相处。因此,持续集成在我看来更像是一个思想,我们需要在短时间内合并代码,发现问题及时修改,不要滚雪球,同时测试也需要跟上进度,这样就不会开发的特别快,结果全是bug没有修改。
(三)上下文映射
上下文映射(Context Map)是描绘不同的界定上下文和它们之间关系的一份文档。它可以是一个图表(diagram),也可以是其他任何形式的文档,细节层次可以有所不同。目的是,要让每个在项目中工作的人都能够分享并理解它。
(四)共享内核(Shared Kernel)
共享内核(Shared Kernel)和客户-供应商(Customer-Supplier)是处理上下文之间的高级交互的模式。
工作于紧密关联的应用程序上团队如果缺乏协调,有时会进展得很快,但他们的工作成果有可能会很难整合。他们在转换层(translation layers)和改造(retrofitting)上花费的时间比一开始就做持续集成会更多,做了许多重复劳动,失去了公共的通用语言带来的好处。因此,需要指派两个团队同意共享的领域模型子集。
共享内核的目的是减少重复,但是仍保持两个独立的上下文。对于共享内核的开发需要多加小心。两个开发团队都有可能修改内核的代码,还必须对所做的修改做集成。如果团队用的是内核代码的副本,那么要尽可能早地合并代码,至少每周一次。还应该使用一个测试套件,这样每一个针对内核的修改都能快速地被测试。内核的任何改变都应该与另一个团队进行沟通,并且通知相关团队,使大家都能了解新增的功能。我感觉就是,共享内核就是代码交集的部分,大家一起编写。
(五)客户-供应商(Customer-Supplier)
有的时候两个子系统之间存在特殊的关系:一个子系统严重依赖另一个。两个子系统所在的上下文是不同的,并且一个系统的处理结果被作为另外一个的输入。它们没有共享的内核,因为有这样一个内核从概念上说是错误的,或者两个子系统要共享代码在技术上不可能实现。
该模型应用于两个团队之间,在两个团队之间建立一个清晰的客户/供应商关系。客户团队应该介绍它的需求,而供应商团队根据需求制定计划。
(六)顺从者
在两个团队对彼此的关系都有兴趣时,客户-供应商关系是可行的。客户非常依赖于供应商,然而供应商却不依赖客户。如果有管理手段保证合作的执行,供应商会给予客户需要的关注,并聆听客户的要求。如果管理手段没有清晰地界定在两个团队之间需要完成什么,或者管理很糟糕,或者缺乏管理,供应商慢慢地会更加关注它的模型和设计,对帮助客户不再感兴趣。此时客户团队非常孤立无援,最明显的做法是将它与供应商分离开,完全自力更生——这个就是隔离通道。
如果客户团队不得不使用供应商团队的模型,那么就需要顺从这个模型了。客户团队遵从供应商团队的模型,完全顺从它。这和共享内核很相似,但有一个重要的不同之处。客户团队不能对内核做更改。他们只能将它作为自己模型的一部分,可以在所提供的现有代码上完成构建。
(七)防崩溃层(Anticorruption Layer)
提出防崩溃层的原因:
- 我们需要同遗留应用进行交互,但是遗留应用的模型和我们用的模型不一样,又或者说他的模型乱七八糟,所以我们就需要在我们的模型和遗留模型之间建立一个集成层,作为两者沟通的桥梁。
- 客户端和外部系统交互,为了避免客户端受到外部系统的影响,就需要一个防崩溃层。从我们模型的观点来看,防崩溃层是模型天然的一部分,并不像一个外来的东西,防崩溃层用外部语言和外部模型交流。
我们应该如何来实现防崩溃层?
一个非常好的解决方案是将这个层看作来自客户端模型的一个 服务。
除了这一点,防崩溃层最有可能还需要一个 适配器(Adapter)。适配器可以使你将一个类的接口转换成客户端能够理解的另一个接口。
防崩溃层也许包含多个服务。每一个服务都有一个相应的 Facade,对每一个 Facade我们为之添加一个适配器。我们不应该为所有的服务使用一个适配器,因为这样会将很多功能混在一起,从而导致杂乱无章。
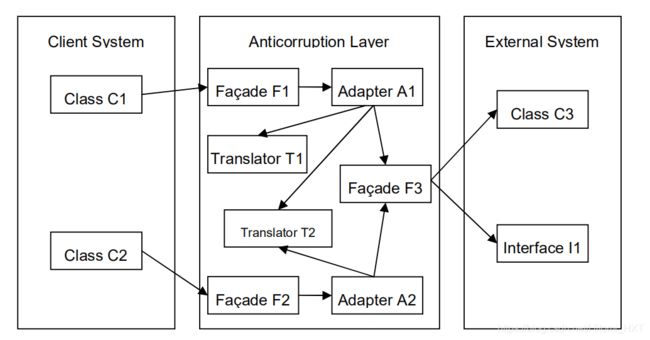
我们必须再添加一个组件。适配器将外部系统的行为包装起来。我们还需要对象和数据转换(object and data conversion),可以使用一个 转换器translator 来完成这个任务。它可以是一个非常简单的对象,有很少的功能,满足数据转换的基本需要。如果外部系统有一个复杂的接口,最好在适配器和接口之间再添加一个额外的 Facade。这会简化适配器的协议,将它和其他系统分离开来。
(八)隔离通道(Separate Way)
隔离通道(Separate Way)是在我们想让上下文高度独立和独立进化时要用到的模式。
隔离通道模式适合于以下情况:
一个企业应用可由几个较小的应用组成,而且从建模的角度来看 彼此之间 有很少 或者 没有公共之处。它有一组自己的需求:
- 从用户角度看这是一个应用
- 但是从建模和设计的观点来看,它可以由具有不同实现的独立模型来完成。
我们应该查看一下需求,思考一下它们是否 可以被划分成 两个 或者 多个 几乎没有相通之处的部分。如果可以这样做,那么我们就创建独立的界定上下文(Bounded Context),并独立建模。
这样做的好处是可以自由地选择用来实现模型的技术。
在采用隔离通道模式之前,我们需要确信我们将不会回到一个集成的系统。独立开发的模型是很难做集成的,它们的相通之处很少,不值得这样做。别用着隔离通道,结果把两个独立的模块又变成一个整体了。也就是说,我们的集成,是”小的集成。
(九)开放主机服务(Open Host Service)
当我们试图集成两个子系统时,通常要在它们之间创建一个转换层。这个层在客户端子系统和我们想要集成的外部子系统之间扮演了缓冲的角色。这个层可以是始终如一的,这要看关系的复杂度和外部子系统是如何设计的。
如果外部子系统不是被一个客户端子系统使用,而是被多个子系统使用的话,我们需要为所有的子系统 创建转换层。所有的这些层都会重复相同的转换任务,也会包含相似的代码。
当一个子系统要和其他很多子系统集成时,为每一个子系统定制一个转换器会使整个团队陷入困境。会有越来越多的代码需要维护,当做出变更时,有越来越多的事情需要担心。
这个问题的解决方案是,将外部子系统看作服务提供者。如果我们能为这个系统封装一组服务,那么所有的其他子系统将会访问这些服务,我们也就不需要任何转换层。
难点在于每一个子系统 也许需要以 一种特殊的方式 和 外部子系统交互,那么要创建一组 一致的服务 可能会比较麻烦。定义一个能以 一组服务的形式 访问你的子系统的 协议。将这个协议开放出来,使得所有需要和你 做集成的人 都能使用它。然后增强和扩展这个协议,使其能够处理新的集成需求,但某团队有特殊需求时除外。对于特殊的需求,使用一个一次性的转换器来增强协议,从而使得共享的协议保持简单和一致。
(十)提炼
即使在我们改进和创建很多抽象之后,一个大的领域还是会有一个大的模型。就是在做了很多次重构之后,模型依然会很大。对于这样的情况,就需要做一次提炼了。其思路是定义一个代表领域本质的核心域(Core Domain)。提炼过程的副产品将是包含了领域中其他部分的普通子域(Generic Subdomain)。
系统的核心域是什么,取决于我们如何看待系统。一个简单的路线系统会将路线和与它相关的概念看作核心域,而空中交通监控系统却将路线看作普通子域。一个应用的核心域有可能会变成另一个应用的普通子域。
我们应当将重心放在核心域的实现上,有下面几种方法可以实现普通子域:
- 购买现成的解决方案。
- 外包。
- 已有模型。
- 自己实现。