C语言学习笔记
C基础
1. 概述
1.1开发环境
- C程序生成过程
编辑器————>源代码文件
编译器————>二进制文件
链接器————>(加上库二进制文件)可执行程序
- 集成开发环境
VS2010安装
新建项目
先新建解决方案再建项目
- 已安装的模板-其他项目类型-Visual Stdio 解决方案
- 解决方案资源管理器-添加新建项目
解决方案和项目一起新建
编译链接
- 生成或生成解决方案
- 运行或调试可执行程序
- mingw
下载地址
$ gcc test1.c test2.c -o main.out
$ ./main.out
2. 数据类型
2.1 基本数据类型
1. 整形 精度为1
-
整形 int 四字节长度(windows操作系统,64位机)
有符号整型 int
表示范围 (-2)^(31)到 2^31 - 1无符号整型 unsigned int
表示范围 0到2^32 -1 -
短整型 short 二字节长度
有符号短整型 short
表示范围 (-2)^(15)到 2^15 - 1和无符号短整型 unsigned short
表示范围 0到 2^16 - 1 -
长整型 long **四字节长度 **(long占据的字节数还和编译器的数据模型相关)VC++ 以后版本还有long long 类型
有符号长整型 long
表示范围 (-2)^(31)到 2^31 - 1
无符号长整形 unsigned long
表示范围 (-2)^(31)到 2^31 - 1
2. 浮点型
浮点数都是有符号的
- 单精度 flaot 四个字节
- 双精度 double 八个字节
使用sizeof运算符可以得到类型所占字节数
%E 为以指数形式输出单、双精度实数
#include <stdio.h>
#include <float.h>
int main()
{
printf("float 存储最大字节数 : %lu \n", sizeof(float));
printf("float 最小值: %E\n", FLT_MIN );
printf("float 最大值: %E\n", FLT_MAX );
printf("精度值: %d\n", FLT_DIG );
return 0;
}
linux显示以下结果:
float 存储最大字节数 : 4
float 最小值: 1.175494E-38
float 最大值: 3.402823E+38
精度值: 6
3. 字符型 一个字节
使用‘’单引号表示
- 有符号字符 char
- 表示范围 -128 到127
- 有符号字符型 unsigned char
- 表示范围 0到255
4. 类型转换
-
隐式转换
表达式中出现不同类型间的混合运算,较低类型将自动向较高类型转换。
整型类型级别从低到高依次为:
signed char->unsigned char->short->unsigned short->int->unsigned int->long->unsigned long
浮点型级别从低到高依次为:
float->double
-
强制类型转换
int a,b; a=4; b=3; double dd; dd=a/b; // dd的结果将是1。 dd=(double)(a/b); // dd的结果是1.000000。 dd=(double)a/b; // dd的结果是1.333333 //运算过程是: (1)先运算a/b,得到的结果是整数的1; (2)把整数的1转换成double,是1.000000。 dd=(double)a/b,dd的结果是1.333333,这个也不好理解,它的运算过程是: (1)先执行(double)a,把a转换为double,即4.000000; (2)把4.00000除以3,得到1.333333,符合自动类型转换的规则。
2.2 枚举类型
使用enum关键字
例如:
#include枚举值默认从 0 开始,往后逐个加 1(递增),
如果只给第一个名字指定值1,这样枚举就1开始递增。
-
枚举数组:
enum DAY days[5]= {MON,TUE,WED,THU,FRI } -
枚举指针:
enum DAY * p_day;p_day=days;
2.3 void类型
void 类型指定没有可用的值。
| 序号 | 类型描述 |
|---|---|
| 1 | 函数返回为空 C 中有各种函数都不返回值,或者您可以说它们返回空。不返回值的函数的返回类型为空。例如 void exit (int status); |
| 2 | 函数参数为空 C 中有各种函数不接受任何参数。不带参数的函数可以接受一个 void。例如 int rand(void); |
| 3 | 指针指向 void 类型为 void * 的指针代表对象的地址,而不是类型。例如,内存分配函数 void *malloc( size_t size ); 返回指向 void 的指针,可以转换为任何数据类型。 |
2.4 派生类型
包括:指针类型、数组类型、结构体类型、共用体类型和函数类型。
2.5 typedef 类型定义符
给类型重命名
typedef struct student student将结构体student代替 struct student
#include typedef vs #define
- typedef 仅限于为类型定义符号名称,#define 不仅可以为类型定义别名,也能为数值定义别名,比如您可以定义 1 为 ONE。
- typedef 是由编译器执行解释的,#define 语句是由预编译器进行处理的。
3. 变量和常量(区分大小写)
3.1 变量
变量的的定义和声明
除非有extern关键字,否则都是变量的定义
变量作用域:
- 变量声明在各语句之前
- 局部变量作用域在其语句块
- 嵌套语句的同名变量:就近原则
3.2 常量
类型
- 整数
- 浮点
- 字符
- 字符串
定义(大写)
- 使用 #define 预处理器。
- 使用 const 关键字。
区别在于:
- const带类型
- define在编译的预处理阶段起作用,const在编译运行时起作用
- define只是简单的字符串替换,没有类型检查,不能调试,但是可以防止头文件重复引用
**sizeof关键字:**不是函数。用来求一个变量、类型的大小。 返回一个 无符号整数。 使用 %u 接收返回值。int a = 20; sizeof(a)
4. 存储类
-
auto
- 所有局部变量默认存储类
- 只能用在函数内
-
register
- 用于定义存储在寄存器而非ram中的局部变量
- 变量最大尺寸为寄存器大小,且并且对其不能用‘&’取值运算
-
static
- 指示编译器在程序生命周期保持局部变量的存在,static修饰的局部变量可以在函数调用之间保持局部变量的值,增加局部变量的生命周期,只被初始化一次。
- static它也可以修饰全局变量,使变量作用域限制在其声明的文件中,其他文件即使声明也无效。只能赋值一次,即可以被任何函数或方法调用
-
extern
- 提供一个全局变量的引用,即在一个文件声明另一个文件中的全局变量或函数
-
volatile
-
防止编译器优化代码。
volatile int flg = 0;
-
还有其他变量修饰符restrict volatile const
5. 运算符
- 算数
- 关系
- 逻辑
- 位运算
- 赋值运算
- 杂项
优先级
6. 程序结构
判断
| 语句 | 描述 |
|---|---|
| if 语句 | 一个 if 语句 由一个布尔表达式后跟一个或多个语句组成。 |
| if…else 语句 | 一个 if 语句 后可跟一个可选的 else 语句,else 语句在布尔表达式为假时执行。 |
| 嵌套 if 语句 | 您可以在一个 if 或 else if 语句内使用另一个 if 或 else if 语句。 |
| switch 语句 | 一个 switch 语句允许测试一个变量等于多个值时的情况。 |
| 嵌套 switch 语句 | 您可以在一个 switch 语句内使用另一个 switch 语句。 |
| ? : 运算符 | (三元运算符) |
循环
- 类型
| 循环类型 | 描述 |
|---|---|
| while 循环 | 当给定条件为真时,重复语句或语句组。它会在执行循环主体之前测试条件。 |
| for 循环 | 多次执行一个语句序列,简化管理循环变量的代码。 |
| do…while 循环 | 除了它是在循环主体结尾测试条件外,其他与 while 语句类似。 |
| 嵌套循环 | 您可以在 while、for 或 do…while 循环内使用一个或多个循环。 |
for 循环执行过程
for(表达式1;条件;表达式2){…}
- 进行表达式1运算
- 判断条件是否为真,真则进行3,否则结束
- 执行{…}中的语句
- 进行表达式2的运算,并转入第2步
表达式1和2可以使用逗号,表达式
break和continue
- 都可以使其后语句停止
- break跳出循环,continue转向条件判断
- 控制语句
| 控制语句 | 描述 |
|---|---|
| break 语句 | 终止循环或 switch 语句,程序流将继续执行紧接着循环或 switch 的下一条语句。 |
| continue 语句 | 告诉一个循环体立刻停止本次循环迭代,重新开始下次循环迭代。 |
| goto 语句 | 将控制转移到被标记的语句。但是不建议在程序中使用 goto 语句。 |
7. 输入输出
输入
-
getchar:输入单个字符,保存到字符变量中。int getchar(void) 函数从屏幕读取下一个可用的字符,并把它返回为一个整数。这个函数在同一个时间内只会读取一个单一的字符。您可以在循环内使用这个方法,以便从屏幕上读取多个字符。
-
gets:输入一行数据,保存到字符串变量中。char *gets(char *s) 函数从 stdin 读取一行到 s 所指向的缓冲区,直到一个终止符或 EOF。
-
scanf:格式化输入函数,一次可以输入多个数据,保存到多个变量中。int scanf(const char *format, …) 函数从标准输入流 stdin 读取输入,并根据提供的 format 来浏览输入。
输出
-
putchar:输出单个字符。int putchar(int c) 函数把字符输出到屏幕上,并返回相同的字符。这个函数在同一个时间内只会输出一个单一的字符。您可以在循环内使用这个方法,以便在屏幕上输出多个字符。
-
puts:输出字符串。int puts(const char *s) 函数把字符串 s 和一个尾随的换行符写入到 stdout。
-
printf:格式化输出函数,可输出常量、变量等。int printf(const char *format, …) 函数把输出写入到标准输出流 stdout ,并根据提供的格式产生输出。
%s:打印字符串, 挨着从字符串的第一个字符开始打印,打印到’\0’结束。
%d:打印整数
%c:打印字符
%x:打印16进制数
%u:打印无符号
%m.n: 打印实型时用到,一共有 m 位(整数、小数、小数点),n位小数。
%0m.nf: 其中 f:表示打印实型,一共有 m 位(整数、小数、小数点),n位小数。 0:表示不足 m 位时,用0凑够m位。
%%: 显示一个%。 转义字符’’ 对 % 转义无效。
%Ns:显示N个字符的字符串。不足N用空格向左填充。
%0Ns:显示N个字符的字符串。不足N用0向左填充。
%-Ns:显示N个字符的字符串。不足N用空格向右填充。
-
sprintf 是将一个格式化的字符串输出到一个目的字符串中;
-
printf 是将一个格式化的字符串输出到屏幕;
-
fprintf 是将一个格式化的字符串写入文件中;
8. 函数
栈 :
当函数调用时,系统会在 stack 空间上申请一块内存区域,用来供函数调用,主要存放 形参 和 局部变量(定义在函数内部)。
当函数调用结束,这块内存区域自动被释放(消失)。
8.1 定义
- 返回类型
- 函数名称
- 参数
- 形参
- 实参
- 函数体
8.2 声明
声明部分必须在实现部分和返回值语句之前
8.3 调用
-
c传值调用:该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数不会影响实际参数。实参将自己的值,拷贝一份给形参。
-
#include#include int main() { int a = 4, b = 6; void Exchg1(int x, int y); Exchg1(a, b); printf("a=%d,b=%d",a,b); gets(); return 0; } void Exchg1(int x, int y) { int tmp;//调用之前,隐含两个赋值操作int x=a;int y=b; tmp = x; x = y; y = tmp; printf("x=%d,y=%d\n",x,y); } x=6,y=4 a=4,b=6
-
参和形参是两个不同的地址空间,参数传递的实质是将原函数中变量的值,复制到被调用函数形参所在的存储空间中,这个形参的地址空间在函数执行完毕后,会被回收掉。整个被调用函数对形参的操作,只影响形参对应的地址空间,不影响原函数中变量的值,因为这两个不是同一个存储空间。
-
(c++)传引用调用:通过指针传递方式,形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作。
-
#include#include void Exchg3(int &x, int &y)//注意定义处的形式参数的格式与值传递不同 { int tmp = x; x = y; y = tmp; printf("x=%d,y=%d\n", x, y); } void main() { int a = 4; int b = 6; Exchg3(a, b);//调用Exchg3时函数会将a,b 分别代替了x,y了,这样函数里头操作的其实就是实参a,b本身 printf("a=%d,b=%d\n", a, b); }
-
形参是引用类型变量,其实就是实参的一个别名,在被调用函数中,对引用变量的所有操作等价于对实参的操作。这样,整个函数执行完毕后,原先的实参的值将会发生改变。
被调函数对形参做的任何操作都影响了主调函数中的实参变量。
内置类型当中三种传递方式的效率上都差不多;
在自定义类型当中,传引用方式效率的更高效一些,因为它没有对形参进行一次拷贝
-
c传地址调用 ,实参将地址值,拷贝一份给形参.
-
#include#include int main() { int a = 4; int b = 6; void Exchg1(int *x, int *y); Exchg1(&a,&b); printf("a=%d,b=%d", a, b); gets(); return 0; } void Exchg2(int *px, int *py) { int tmp;//将a的地址(&a)代入到px,b的地址(&b)代入到py。 tmp = *px;//同上面的值传递一样,函数调用时作了两个隐含的操作:将&a,&b的值赋值给了px,py。 *px = *py;//px=&a; *py = tmp;//py=&b;隐含操作 printf("*px=%d,*py=%d\n", *px,*py); } //这里是将a,b的地址值传递给了px,py,而不是传递的a,b的内容
-
实参是变量的地址,形参是指针类型的变量,在函数中对指针变量的操作,就是对实参(变量地址)所对应的变量的操作,函数调用结束后,原函数中的变量的值将会发生改变。
8.4 作用域规则
局部变量被定义时,系统不会对其初始化,您必须自行对其初始化。定义全局变量时,系统会自动对其初始化
- 局部变量:函数体中定义声明的变量
- 某个函数或代码块的内部声明,局部变量保存在栈中,只有在所在函数被调用时才动态地为变量分配存储单元。
- 作用域在其定义的那对花括号之内
- 局部变量的声明周期:从大括号的第一个语句到最后一条语句结束有效
- 全局变量:函数体之外
- 全局变量保存在内存的全局存储区中,占用静态的存储单元;
- 全局变量作用域在声明定义它的那个源文件
- 从程序执行开始一直到程序执行结束
- 形式参数
- 就近原则:局部变量对全局变量具有覆盖作用
- 与全局变量同名它们会优先使用。
- 当局部变量被定义时,系统不会对其初始化,您必须自行对其初始化。定义全局变量时,系统会自动对其初始化
8.5 复杂参数函数
可变参数
根据具体的需求接受可变数量的参数
使用 stdarg.h 头文件,该文件提供了实现可变参数功能的函数和宏。具体步骤如下:
- 定义一个函数,最后一个参数为省略号,省略号前面可以设置自定义参数。
- 在函数定义中创建一个
va_list类型变量,该类型是在 stdarg.h 头文件中定义的。 - 使用 int 参数和
va_start宏来初始化 va_list 变量为一个参数列表。宏 va_start 是在 stdarg.h 头文件中定义的。 - 使用
va_arg宏和va_list变量来访问参数列表中的每个项。 - 使用宏
va_end来清理赋予va_list变量的内存。
#include 数组参数的函数

void BubbleSort(int arr[10]) == void BubbleSort(int arr[]) == void BubbleSort(int *arr)
传递不再是整个数组,而是数组的首地址(一个指针)。
所以,当整型数组做函数参数时,我们通常在函数定义中,封装2个参数。一个表数组首地址,一个表元素个数。
指针参数的函数

结构体、共同体、枚举参数
main()函数
- 函数定义
C99 标准中,只有以下两种定义方式是正确的:
int main( void ) /* 无参数形式 */
{
...
return 0;
}
int main( int argc, char *argv[] ) /* 带参数形式 */
{
...
return 0;
}
-
函数参数
int argc: 用命令行运行程序时,输入命令包含的字符串个数char* argv[]:一维字符串数组,存储每个字符串的地址
#includeint main(int argc,char* argv[]) { int i; printf("argc = %d\n",argc); for(i=0;i<argc;i++) { printf("argv[%d] = %s\n",i,argv[i]); } } -
main()函数的返回值:
一般main()函数能够正常完后曾需要的功能则返回值0,否则返回其他值。
9. 数组
- 存储固定大小的相同元素的顺序集合
- 由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。
9.1 数组定义
int radius[10];
- 类型
- 数组名
- 表达式:常量或常量表达式
9.2 数组初始化和赋值以及引用
数组初始化:
int arr[12] = { 1, 2 ,4, 6, 76, 8, 90 ,4, 3, 6 , 6, 8 }; 【重点】
int arr[10] = { 1, 2 ,4, 6, 76, 8, 9 }; 剩余未初始化的元素,默认 0 值。 【重点】
int arr[10] = { 0 }; 初始化一个全为 0 的数组。【重点】
int arr[] = {1, 2, 4, 6, 8}; 编译器自动求取元素个数 【重点】
int arr[] = {0}; 只有一个元素,值为0
数组大小: sizeof(arr);
一行大小: sizeof(arr[0]): 二维数组的一行,就是一个一维数组。
一个元素大小:sizeof(arr[0][0]) 单位:字节
行数:row = sizeof(arr)/ sizeof(arr[0])
列数:col = sizeof(arr[0])/ sizeof(arr[0][0])
printf(“%p\n”, arr); == printf(“%p\n”, &arr[0][0]); == printf(“%p\n”, arr[0]);
数组的首地址 == 数组的首元素地址 == 数组的首行地址。
9.3 二维或多维数组
二维数组的初始化:
-
常规初始化:
int arr[3][5] = {{2, 3, 54, 56, 7 }, {2, 67, 4, 35, 9}, {1, 4, 16, 3, 78}}; -
不完全初始化:
int arr[3][5] = {{2, 3}, {2, 67, 4, }, {1, 4, 16, 78}}; 未被初始化的数值为 0 int arr[3][5] = {0}; 初始化一个 初值全为0的二维数组 int arr[3][5] = {2, 3, 2, 67, 4, 1, 4, 16, 78}; 【少见】 系统自动分配行列 -
不完全指定行列初始化:
int arr[][] = {1, 3, 4, 6, 7}; 二维数组定义必须指定列值。 int arr[][2] = { 1, 3, 4, 6, 7 }; 可以不指定行值。
9.4 字符数组–字符串
字符串实际上是使用 null 字符 ‘\0’ 终止的一维字符数组,没有这个 null 的话不能使用 %s 格式控制符打印。
char str1[] = {'h', 'i', '\0'}; 变量,可读可写
char name[10]="xiao ming"; 变量,可读可写
char* p = "123"; //字符串使用双引号 常量,只读,存储首个字符‘h’的地址
字符串以字符‘\0’为结尾,编译器默认加上
str3[1] = ‘H’; // 错误!!
char *str4 = {‘h’, ‘i’, ‘\0’}; // 错误!!!
字符串输入输出
int main()
{
char name[10];
int i;
for(i=0;i<2;i++)
{
scanf("%s",name);
printf("%s",name);
}
}
//字符串初始化
memset(strname,0,sizeof(strname)); // 把全部的元素置为0
printf("=%10s=\n","abcd"); // 输出10个字符宽度,右对齐,执行结果是= abcd=
printf("=%-10s=\n","abcd"); // 输出10个字符宽度,左对齐,执行结果是=abcd =
字符串格式化输入、输出:
sprintf():原来写到屏幕的“格式化字符串”,写到 参数1 str中。
char str[100];
sprintf(str, "%d+%d=%d\n", 10, 24, 10+24); 格式串写入str数组中。
sscanf(): 将原来从屏幕获取的“格式化字符串”, 从 参数1 str中 获取。
char str[]= "10+24=45";
sscanf(str, "%d+%d=%d", &a, &b, &c); a --> 10, b --> 24, c --> 45
字符串操作函数
| 序号 | 函数 & 目的 |
|---|---|
| 1 | strcpy(s1, s2); 复制字符串 s2 到字符串 s1。字符串赋值 |
| 2 | strcat(s1, s2); 连接字符串 s2 到字符串 s1 的末尾。 |
| 3 | strlen(s1); 扫描整个字符串,直到碰到第一个字符串结束符 '\0'为止,然后返回计数器值(长度不包含'\0');。 |
| 4 | strcmp(s1, s2); 如果 s1 和 s2 是相同的,则返回 0;如果 s1 |
| 5 | strchr(s1, ch); 返回一个指针,指向字符串 s1 中字符 ch 的第一次出现的位置。 |
| 6 | strstr(s1, s2); 返回一个指针,指向字符串 s1 中字符串 s2 的第一次出现的位置。 |
| 7 | strtok() 字符串分割 参1: 待拆分字符串,参2: 分割符组成的“分割串”,返回:字符串拆分后的首地址。 “拆分”:将分割字符用 '\0’替换。 |
- char *buf = “hello”; //定义一个字符串,系统自动为它加上了一个 ‘\0’
- int size = sizeof(“hello”); // 6 真实容量,加上结束符号
- int len = strlen(buf); // 5 实际长度,不含结束符号
- int size = sizeof(buf);//8 64位计算机指针长度
- int buff[] = “hello” ;int size = sizeof(buf);//6这样返回
- strtok拆分字符串是直接在 原串 上操作,所以要求参1必须,可读可写,(
char *str = "www.baidu.com"不行!!!)- 第一次拆分,参1 传待拆分的原串。 第1+ 次拆分时,参1传 NULL.
atoi:字符串 转 整数。
int atoi(const char *nptr);
atof:字符串 转 浮点数
atol:字符串 转 长整数
10. 指针
10.1 地址
即内存中的某个位置
- 取地址运算
- 使用&取址运算符
- &变量名
10.2 指针和指针变量
指针指向某个内存地址
地址表示一个位置
指针变量
值为另一个变量的地址,即指针指向的地址
-
类型 *
-
int* address;
-
都是一个代表内存地址长的十六进制数
-
为指针变量赋一个 NULL 值是一个良好的编程习惯。赋为 NULL 值的指针被称为空指针。
-
如需检查一个空指针,您可以使用 if 语句,如下所示:
-
if(ptr) /* 如果 p 非空,则完成 */ if(!ptr) /* 如果 p 为空,则完成 */```
-
void指针
无类型指针
void* address定义一个空指针变量address
可以接收任意一种变量地址。但是,在使用【必须】借助“强转”具体化数据类型。
char ch = 'R';
void *p; // 万能指针、泛型指针
p = &ch;
printf("%c\n", *(char *)p);
野指针:
1) 没有一个有效的地址空间的指针。
int *p;
*p = 1000;
-
p变量有一个值,但该值不是可访问的内存区域。
int *p = 10;
*p = 2000;
const关键字:
-
修饰变量
const int a = 20; int *p = &a; *p = 650; printf("%d\n", a); -
修饰指针
const int *p; 可以修改 p 不可以修改 *p。 int const *p; 同上。 int * const p; 可以修改 *p 不可以修改 p。 const int *const p; 不可以修改 p。 不可以修改 *p。 总结:const 向右修饰,被修饰的部分即为只读。在函数形参内,用来限制指针所对应的内存空间为只读。
10.3 指针运算
- 取指针元素
*指针变量:使用指针取得指针所指内存地址处的数据
对有初始化的变量取地址和取元素进行赋值
- 指针的自增自减
指针的自增自减1表示指针所指数据在内存中所占字节数
整型指针变量自增1 表是加4
void指针不能进项自增自减运算
-
指针的比较
-
数据类型对指针的作用:
1)间接引用:
决定了从指针存储的地址开始,向后读取的字节数。 (与指针本身存储空间无关。)
2)加减运算:
决定了指针进行 +1/-1 操作向后加过的 字节数。 -
指针 * / % : error!!!
-
指针 ± 整数:
1)普通指针变量±整数
char *p; 打印 p 、 p+1 偏过 1 字节。 short*p; 打印 p 、 p+1 偏过 2 字节。 int *p; 打印 p 、 p+1 偏过 4 字节。2)在数组中± 整数
short arr[] = {1, 3, 5, 8}; int *p = arr; p+3; // 向右(后)偏过 3 个元素 p-2; // 向前(左)偏过 2 个元素 -
指针 ± 指针:
指针 + 指针: error!!!
指针 - 指针:
1) 普通变量来说, 语法允许。无实际意义。【了解】
2) 数组来说:偏移过的元素个数。 -
指针实现 strlen 函数:
char str[] = "hello"; char *p = str; while (*p != '\0') { p++; } p-str; 即为 数组有效元素的个数。 -
指针数组:
一个存储地址的数组。数组内部所有元素都是地址。 1) int a = 10; int b = 20; int c = 30; int *arr[] = {&a, &b, &c}; // 数组元素为 整型变量 地址 2) int a[] = { 10 }; int b[] = { 20 }; int c[] = { 30 }; int *arr[] = { a, b, c }; // 数组元素为 数组 地址。 指针数组本质,是一个二级指针。 二维数组, 也是一个二级指针。
指针类型转换
- 强制类型转换
void* addr;
((int*)addr)++
- 隐式类型转换
printf("%x\n",addr);
//指针类型隐式转换为十六进制整型
10.4 数组和指针
- 数组名也是指针
- 数组名即数组第一个元素地址
- 数组名是指针常量,不能做变量使用
- 使用数组名访问数组元素
int radius[5]={1,2,3,4,5};
int* addr;
addr=radius+0;
printf("radius[0] = %d\n",*addr);
三种访问数组元素的方法
-
使用数组下标
element = radius[i]使用下标 -
使用数组名
*(数组名+i)element =*(radius + i) -
使用指针变量
将数组名赋值给指针变量
int *addr;
addr =radius;
element =*addr;
addr++;
\*p++/\*(p)++/*(p++)/*p++运算规律:
- 1.如果
\*和++/--都在指针变量的左边,结合方向为从右到左; - 2.如果
\*和++/--分别在指针变量的左边/右边,结合方向为从左到右; - 3.有括号的先执行括号的表达式,然后在执行规律1或者规律2;
| A = | 第一步 | 第二步 | 得到计算结果 |
|---|---|---|---|
| *p++ | *p | p++ | 先取值,后指针++,A = *p; |
| *++p | ++p | *(++p) | 先指针++,后取值, A = *(++p); |
| ++*p | *p | (*p)+1 | 先取值,后值++ ,A = (*p)+1; |
| (*p)++ | *p | (*p)+1 | 先取值,后值++ ,A = (*p)+1; |
数组指针和指针数组
- 数组指针即为数组的地址
- 指针数组保存指针类型的数组
int*addr[5] - 多为数组中,最后一维保存数据,其他都是指针
用一个指向字符的指针数组来存储一个字符串列表
#include 多维指针和多维数组
-
指向指针的指针
#includeint main () { int var; int *ptr; int **pptr; var = 3000; /* 获取 var 的地址 */ ptr = &var; /* 使用运算符 & 获取 ptr 的地址 */ pptr = &ptr; /* 使用 pptr 获取值 */ printf("Value of var = %d\n", var ); printf("Value available at *ptr = %d\n", *ptr ); printf("Value available at **pptr = %d\n", **pptr);//取多重指针元素 return 0; } 代码被执行产生以下结果 Value of var = 3000 Value available at *ptr = 3000 Value available at **pptr = 300 -
使用数组名访问多维数组

-
使用多维数组指针变量访问数组中的每个元素

*p_addr 相当与num[0],num[1],num[2]
10.5 字符指针
定义一个字符指针变量char * p_str
scanf()和printf()函数和字符指针
使用%s可以直接输入输出字符串,因为其输入输出需要字符指针
char* name = "xiao ming";使用字符指针保存字符串;

10.6 指针和函数
c传递指针给函数
#include 能接受指针作为参数的函数,也能接受数组作为参数
#include C从函数返回指针
C 允许您从函数返回指针。必须先声明一个返回指针的函数,即指针函数
C 语言不支持在调用函数时返回局部变量的地址,除非定义局部变量为 static 变量。
#include 函数指针
-
函数指针是指向函数的指针变量。
-
函数指针可以像一般函数一样,用于调用函数、传递参数。
-
本质是一个指针,指向的是一个函数的地址。
-
函数指针变量的声明:
typedef int (*fun_ptr)(int,int); // 声明一个指向同样参数、返回值的函数指针类型#includeint max(int x, int y) { return x > y ? x : y; } int main(void) { /* p 是函数指针 */ int (* p)(int, int) = & max; // &可以省略 int a, b, c, d; printf("请输入三个数字:"); scanf("%d %d %d", & a, & b, & c); /* 与直接调用函数等价,d = max(max(a, b), c) */ d = p(p(a, b), c); printf("最大的数字是: %d\n", d); return 0; } //输出结果如下: 请输入三个数字:1 2 3 最大的数字是: 3
指针函数
指针函数,即返回指针的函数,其本质是一个函数,而该函数的返回值是一个指针。
回调函数
函数指针作为某个函数的参数,回调函数是由别人的函数执行时调用你实现的函数。
将一个函数作为另一个函数参数
#include 11. 结构体
存储不同类型的数据项。
11.1 定义
struct Books//结构体标签
{
char title[50];//结构体成员格式
char author[50];
char subject[100];
int book_id;
} book;//结构体变量
//三部分至少出现两个
##################################################################
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//同时又声明了结构体变量s1
//这个结构体并没有标明其标签
struct
{
int a;
char b;
double c;
} s1;
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//结构体的标签被命名为SIMPLE,没有声明变量
struct SIMPLE
{
int a;
char b;
double c;
};
//用SIMPLE标签的结构体,另外声明了变量t1、t2、t3
struct SIMPLE t1, t2[20], *t3;
//也可以用typedef创建新类型
typedef struct
{
int a;
char b;
double c;
} Simple2;
//现在可以用Simple2作为类型声明新的结构体变量
Simple2 u1, u2[20], *u3;
结构体的成员可以包含其他结构体,也可以包含指向自己结构体类型的指针,而通常这种指针的应用是为了实现一些更高级的数据结构如链表和树等。
//此结构体的声明包含了其他的结构体
struct COMPLEX
{
char string[100];
struct SIMPLE a;
};
//此结构体的声明包含了指向自己类型的指针
struct NODE
{
char string[100];
struct NODE *next_node;
};
//
struct B; //对结构体B进行不完整声明
//结构体A中包含指向结构体B的指针
struct A
{
struct B *partner;
//other members;
};
//结构体B中包含指向结构体A的指针,在A声明完后,B也随之进行声明
struct B
{
struct A *partner;
//other members;
};
11.2 结构体变量初始化
#include 访问结构体成员
#include 11.3 结构作为函数参数
#include 11.4 指向结构体的指针
- 定义指向结构的指针:
struct Books *struct_pointer; - 指针变量中存储结构变量的地址:
struct_pointer = &Book1; - 使用指向该结构的指针访问结构的成员,您必须使用 -> 运算符:
struct_pointer->title;
#include 11.5 位域
struct bs{
int a:8;
int b:2;
int c:6;
}data;
//位域定义
//说明 data 为 bs 变量,共占两个字节。其中位域 a 占 8 位,位域 b 占 2 位,位域 c 占 6 位。
一个位域存储在同一个字节中,如一个字节所剩空间不够存放另一位域时,则会从下一单元起存放该位域。也可以有意使某位域从下一单元开始。例如:
struct bs{
unsigned a:4;
unsigned :4; /* 空域 */
unsigned b:4; /* 从下一单元开始存放 */
unsigned c:4
}//位域可以是无名位域,这时它只用来作填充或调整位置。无名的位域是不能使用的。例如:
由于位域不允许跨两个字节,因此位域的长度不能大于一个字节的长度,也就是说不能超过8位二进位。如果最大长度大于计算机的整数字长,一些编译器可能会允许域的内存重叠,另外一些编译器可能会把大于一个域的部分存储在下一个字中。
main(){
struct bs{
unsigned a:1;
unsigned b:3;
unsigned c:4;
} bit,*pbit;
bit.a=1; /* 给位域赋值(应注意赋值不能超过该位域的允许范围) */
bit.b=7; /* 给位域赋值(应注意赋值不能超过该位域的允许范围) */
bit.c=15; /* 给位域赋值(应注意赋值不能超过该位域的允许范围) */
printf("%d,%d,%d\n",bit.a,bit.b,bit.c); /* 以整型量格式输出三个域的内容 */
pbit=&bit; /* 把位域变量 bit 的地址送给指针变量 pbit */
pbit->a=0; /* 用指针方式给位域 a 重新赋值,赋为 0 */
pbit->b&=3; /* 使用了复合的位运算符 "&=",相当于:pbit->b=pbit->b&3,位域 b 中原有值为 7,与 3 作按位与运算的结果为 3(111&011=011,十进制值为 3) */
pbit->c|=1; /* 使用了复合位运算符"|=",相当于:pbit->c=pbit->c|1,其结果为 15 */
printf("%d,%d,%d\n",pbit->a,pbit->b,pbit->c); /* 用指针方式输出了这三个域的值 */
}//位域使用
11.6 结构体数组
11.7 结构体占用内存大小
结构体的占用内存的总大小不一定等于全部成员变量占用内存大小之和。在编译器的具体实现中,为了提高内存寻址的效率,各个成员之间可能会存在缝隙。用sizeof可以得到结构体占用内存在总大小,sizeof(结构体名)或 sizeof(结构体变量名)都可以。
#pragma pack(1)
//增加代码可以使结构体成员变量之间的内存没有空隙。
11.8 结构体复制
结构体变量名不是结构体变量的地址
void *memcpy(void *dest, const void *src, size_t n);
- 复制的内容不同,strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
- 用途不同,通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy。
- 复制的方法不同,strcpy不需要指定长度,它遇到被复制字符的串结尾符0才结束,memcpy则是根据其第3个参数决定复制的长度。
11.9 内存空间复制和清零
memset函数:
void *memset(void *s, int v, size_t n);s为内存空间的地址,一般是数组名或结构体的地址。v为要填充的值,填0就是初始化。n为要填充的字节数。
bzero函数
void bzero(void *s, size_t n);s为内存空间的地址,一般是数组名或结构体的地址。n为要清零的字节数。
12. 共同(用)体
- 结构体:将所有数据结合组成
- 共同体:所有数组存在一起
12.1定义
共用体是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型,内部所有成员变量地址一致。等同于整个联合体的地址。。您可以定义一个带有多成员的共用体,但是任何时候只能有一个成员带有值。共用体提供了一种使用相同的内存位置的有效方式。联合体的大小,是内部成员变量中,最大的那个成员变量的大小。修改其中任意一个成员变量的值,其他成员变量会随之修改。
union Data
{
int i;
float f;
char str[20];
} data;
12.2 共同体变量
union Data
{
int i;
float f;
char str[20];
} data;
#include 共用体大小计算,不一定就等于最大成员
union{
char a
[3];
char b;
} A ; // sizeof(A) = 3
union{
char a
[3];
short b;
} B ; // sizeof(B) = 4
union{
char a
[5];
int b;
} C ; // sizeof(C) = 8
//结构体或共用体的内存大小必须为类型体内最大数据类型字节数的整数倍,即地址对齐(这样做的目的是为了更快速高效地访问内存,以空间换时间)。代码中第一个共用体中的最大数据类型为char-1个字节,所以该共用体直接就是3个字节的大小。第二个共用体最大类型为short-2个字节,而char数组a占用3个字节,3不为2的整数倍,所以补齐1个字节,该共用体就是4个字节的大小。第三个共用体最大类型为int-4个字节,char数组a占用5个字节,5不为4的整数倍,所以补齐3个字节,该共用体就是8个字节的大小。
12.3 共同体数组
不可以同时初始化不同类型数据,只能使用赋值的方式在共同体数组保存不同类型数值
12.4 共同体指针
共同体指针变量
用法相当于结构体
13.预处理,文件包含
13.1 程序预处理
控制编译器在编译链接之前,对代码进行的一些前期处理,也叫预编译

预处理原因:
- 修改代码
- 确定程序中没能去欸当年的个东西
- 重复使用某些代码
| 指令 | 描述 |
|---|---|
| #define | 定义宏 |
| #include | 包含一个源代码文件 |
| #undef | 取消已定义的宏 |
| #ifdef | 如果宏已经定义,则返回真 |
| #ifndef | 如果宏没有定义,则返回真 |
| #if | 如果给定条件为真,则编译下面代码 |
| #else | #if 的替代方案 |
| #elif | 如果前面的 #if 给定条件不为真,当前条件为真,则编译下面代码 |
| #endif | 结束一个 #if……#else 条件编译块 |
| #error | 当遇到标准错误时,输出错误消息 |
| #pragma | 使用标准化方法,向编译器发布特殊的命令到编译器中 |
13.2 宏定义
格式:#define 被替换内容 替换为的内容
- 不带参数
#define a b - 带参数
#define add(a,b) a+b:- 类似与函数定义,但是宏定义在预处理阶段进行,函数定义在编译阶段实现,函数调用在函数运行时完成的
- 宏定义直接的替换,函数调用是有参数传递和返回值过程
- 宏定义无数据类型
- 宏定义跨行,需要在宏定义语句后加一个反斜杠
\,最后一行不需要,宏延续运算符(\)

-
字符串常量化运算符(#)
在宏定义中,当需要把一个宏的参数转换为字符串常量时,则使用字符串常量化运算符(#)。在宏中使用的该运算符有一个特定的参数或参数列表。例如:
#include#define message_for(a, b) \ printf(#a " and " #b ": We love you!\n") int main(void) { message_for(Carole, Debra); return 0; } 产生结果如下: Carole and Debra: We love you! -
标记粘贴运算符(##)
宏定义内的标记粘贴运算符(##)会合并两个参数。它允许在宏定义中两个独立的标记被合并为一个标记。例如:
token##34就是等于token34,A##B就是把B放在A后面连起来即为AB#include#define tokenpaster(n) printf ("token" #n " = %d", token##n) int main(void) { int token34 = 40; tokenpaster(34); return 0; } 产生如下结果: token34 = 40 s printf ("token34 = %d", token34); -
defined() 运算符
预处理器 defined 运算符是用在常量表达式中的,用来确定一个标识符是否已经使用 #define 定义过。如果指定的标识符已定义,则值为真(非零)。如果指定的标识符未定义,则值为假(零)。下面的实例演示了 defined() 运算符的用法
#include#if !defined (MESSAGE) #define MESSAGE "You wish!" #endif int main(void) { printf("Here is the message: %s\n", MESSAGE); return 0; } ANSI C 定义了许多宏。在编程中您可以使用这些宏,但是不能直接修改这些预定义的宏。
__DATE__ 当前日期,一个以 “MMM DD YYYY” 格式表示的字符串常量。 __TIME__ 当前时间,一个以 “HH:MM:SS” 格式表示的字符串常量。 __FILE__ 这会包含当前文件名,一个字符串常量。 __LINE__ 这会包含当前行号,一个十进制常量。 __STDC__ 当编译器以 ANSI 标准编译时,则定义为 1;判断该文件是不是标准C程序。 __FUNCTION__ 程序预编译时预编译器将用所在的函数名,返回值是字符串;
13.3 预编译控制
if:其后表达式为真则保留之后的语句块ifdef:其后的标识符是#define中被替换的内容,那么之后的语句块保留,否则删除ifndef:与上一个相反elif:elseendif结束if控制

-
预定义宏
ANSI C 定义了许多宏。在编程中您可以使用这些宏,但是不能直接修改这些预定义的宏。
宏 描述 DATE 当前日期,一个以 “MMM DD YYYY” 格式表示的字符常量。 TIME 当前时间,一个以 “HH:MM:SS” 格式表示的字符常量。 FILE 这会包含当前文件名,一个字符串常量。 LINE 这会包含当前行号,一个十进制常量。 STDC 当编译器以 ANSI 标准编译时,则定义为 1。 #includemain() { printf("File :%s\n", __FILE__ ); printf("Date :%s\n", __DATE__ ); printf("Time :%s\n", __TIME__ ); printf("Line :%d\n", __LINE__ ); printf("ANSI :%d\n", __STDC__ ); } 将产生以下结果: File :test.c Date :Jun 2 2012 Time :03:36:24 Line :8 ANSI :1
13.4 文件包含
-
头文件:公共代码,即头文件,
.h结尾,常用的函数声明,宏定义,公共结构体类型,共同体,枚举类型等,放在头文件中 -
源文件:非公共的宏定义,结构体类型,以及函数定义,都放在源文件中
-
include 头文件包含:- 系统头文件:
#include <头文件名>,从系统设定和用户设定的包含路径查找头文件,没找到直接报错。 - 自定义头文件:
#include “头文件名”,从源文件放置的路径开始查找,没找到再从系统设定和用户设定的包含路径查找头文件,没找到报错。
- 系统头文件:
-
有条件包含:有时需要从多个不同的头文件中选择一个引用到程序中。例如,需要指定在不同的操作系统上使用的配置参数。您可以通过一系列条件来实现这点,如下:
#if SYSTEM_1 # include "system_1.h" #elif SYSTEM_2 # include "system_2.h" #elif SYSTEM_3 ... #endif -
只引用一次:如果一个头文件被引用两次,编译器会处理两次头文件的内容,这将产生错误。为了防止这种情况,标准的做法是把文件的整个内容放在条件编译语句中,如下:
#ifndef HEADER_FILE #define HEADER_FILE the entire header file file #endif -
c语言标准头文件:

14. 文件操作
14.1 文件指针
标识确定文件,保存文件信息所在的内存地址
- 定义一个文件指针变量:
FILE * 文件指针变量名
14.2 文件打开
-
文件打开函数,函数返回一个文件指针
FILE * fopen(const char *fname, const char *mode); -
fname : 字符指针变量,指向文件路径以及文件名
- 绝对路径:路径使用双斜杠,
- 相对路径:程序运行目录开始算
-
mode: 文件打开方式

-
FILE *pfile; pfile = fopen("test.txt","r");
14.3 文件关闭
-
文件关闭函数:关闭成功返回0,否则返回EOF
这个函数实际上,会清空缓冲区中的数据,关闭文件,并释放用于该文件的所有内存。EOF 是一个定义在头文件 stdio.h 中的常量。
C 标准库提供了各种函数来按字符或者以固定长度字符串的形式读写文件。
int fclose( FILE *stream) -
fclose(pfile);
14.4 文件读
-
读写一个字符
fgetc()- 文件读取单个字符函数:
int fgetc( FILE * fp ); - fgetc() 函数从 fp 所指向的输入文件的开头读取一个字符。返回值是读取的字符,如果发生错误则返回 EOF。
- 文件读取单个字符函数:
-
读取一个字符串
fgets()- 读取字符串函数:
char *fgets( char *buf, int n, FILE *fp ); - 函数 fgets() 从 fp 所指向的输入流中读取 n - 1 个字符。它会把读取的字符串复制到缓冲区 buf,并在最后追加一个 null 字符来终止字符串。
- 如果这个函数在读取最后一个字符之前就遇到一个换行符 ‘\n’ 或文件的末尾 EOF,则只会返回读取到的字符,包括换行符。
- 也可以使用
int fscanf(FILE *fp, const char *format, ...)函数来从文件中读取字符串,但是在遇到第一个空格字符时,它会停止读取
- 读取字符串函数:
-
#includeint main() { FILE *fp = NULL; char buff[255]; fp = fopen("../test.txt", "r"); fscanf(fp, "%s", buff); printf("1: %s\n", buff ); fgets(buff, 255, (FILE*)fp); printf("2: %s\n", buff ); fgets(buff, 255, (FILE*)fp); printf("3: %s\n", buff ); fclose(fp); } 结果如下: 1: This 2: is testing for fprintf... 3: This is testing for fputs...
14.5 文件写
-
写入字符
fputc()- 写字符函数:
int fputc( int c, FILE *fp ); - 函数 fputc() 把参数 c 的字符值写入到 fp 所指向的输出流中。如果写入成功,它会返回写入的字符,如果发生错误,则会返回 EOF。
- 写字符函数:
-
写入字符串
fputs()- 写字符串函数:
int fputs( const char *s, FILE *fp ); - 函数 fputs() 把字符串 s 写入到 fp 所指向的输出流中。如果写入成功,它会返回一个非负值,如果发生错误,则会返回 EOF。
- 也可以使用
int fprintf(FILE *fp,const char *format, ...)函数来写把一个字符串写入到文件中。
- 写字符串函数:
-
#includeint main() { FILE* fp = NULL; fp = fopen("../test.txt", "w+"); fprintf(fp, "%s %s %s %d\n", "We", "are", "in", 2022); fputs("This is testing for fputs...\n", fp); fclose(fp); } //当上面的代码被编译和执行时,它会在 /tmp 目录中创建一个新的文件 test.txt,并使用两个不同的函数写入两行
14.6 读一个数据块
二进制读,通常是数组或结构体
-
读一个数据块
fread()-
读数据块函数 ,从一个打开的文件中读取数据,每次调用都读出紧跟已读块之后的一个数据块。
size_t fread(void *buffer, size_t size, size_t number, FILE *file); -
buffer:即读出内容放到buffer指针所指地方
-
size:读出数据块以size字节为单位
-
number: 要读出的数据块为number个size单位,即整个块大小为size*num个字节。
-
file:k即文件指针变量
-
函数返回值为一个整型数据,表示的是读出的数据块的大小,如果数值小于size*num,,表示出错或者已经读取到文件尾部了。这个时候可以用feof()和ferror()函数来检查错误。
-
-
写一个数据块
fwrite()-
写数据块函数:
size_t fwrite(const void *buffer, size_t size, size_t number, FILE *file); -
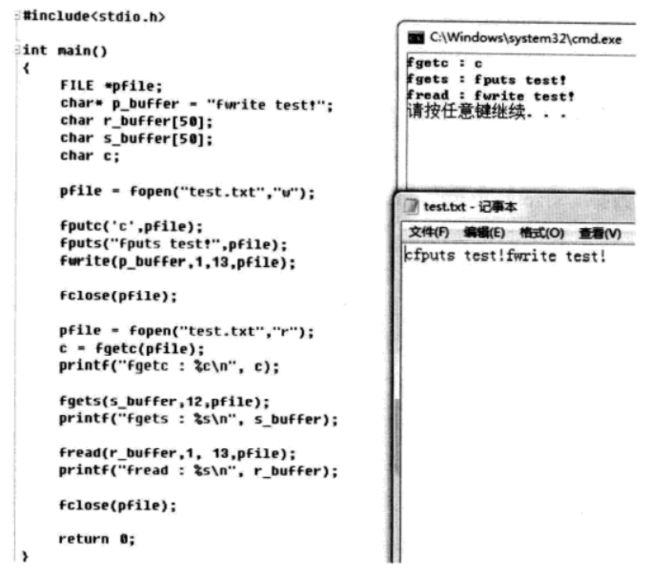
-
14.7 文件其他操作
-
随机读写文件
-
int fseek(FILE *stream, long int offset, int whence) -
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
-
offset – 这是相对 whence 的偏移量,以字节为单位。
-
whence – 这是表示开始添加偏移 offset 的位置。它一般指定为下列常量之一:
-
常量 描述 SEEK_SET 文件的开头 SEEK_CUR 文件指针的当前位置 SEEK_END 文件的末尾 -
如果成功,则该函数返回零,否则返回非零值。
-
int main () { FILE *fp; fp = fopen("file.txt","w+"); fputs("This is runoob.com", fp); fseek( fp, 7, SEEK_SET ); fputs(" C Programming Langauge", fp); fclose(fp); return(0); } //This is C Programming Langauge
-
-
回到文件头
rewind()void rewind(FILE *stream)设置文件位置为给定流 stream 的文件的开头。- stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- fseek(pfile,0,SEEK_SET);
- rewind(pfile);
-
检查上一个文件操作是否有操作错误
ferror(FILE *stream) -
检查是否到达文件尾
feof(FILE * stream)//生成1GB空文件 FILE *file; file=fopen("test.txt","w"); fseek(file,1024*1024*1024,SEEK_SET); fputc('\0',file); fclose(file); -
获取文件读写指针位置。
long ftell(FILE *stream);返回:从文件当前读写位置到起始位置的偏移量。
借助 ftell(fp) + fseek(fp, 0, SEEK_END); 来获取文件大小。 -
获取文件状态:
int stat(const char *path, struct stat *buf);参1: 访问文件的路径
参2: 文件属性结构体
返回值: 成功: 0, 失败: -1;打开文件,对于系统而言,系统资源消耗较大。
-
删除、重命名文件:
int remove(const char *pathname);删除文件。int rename(const char *oldpath, const char *newpath);重名文件
-
手动刷新缓冲区: 实时刷新。
int fflush(FILE *stream);成功:0失败:-1缓冲区刷新: 标准输出-- stdout -- 标准输出缓冲区。 写给屏幕的数据,都是先存缓冲区中,由缓冲区一次性刷新到物理设备(屏幕) 标准输入 -- stdin -- 标准输入缓冲区。 从键盘读取的数据,直接读到 缓冲区中, 由缓冲区给程序提供数据。 预读入、缓输出。 行缓冲:printf(); 遇到\n就会将缓冲区中的数据刷新到物理设备上。 全缓冲:文件。 缓冲区存满, 数据刷新到物理设备上。 无缓冲:perror。 缓冲区中只要有数据,就立即刷新到物理设备。 文件关闭时, 缓冲区会被自动刷新。 隐式回收:关闭文件、刷新缓冲区、释放malloc
15. 匈牙利命名法则
1. 属性部分
g_ 全局变量
c_ 常量
m_ c++类成员变量
s_ 静态变量
2. 类型部分
数组 a
指针 p
长指针 Long Pointer
函数 fn
无效 v
句柄 h
长整型 l
布尔 b
浮点型(有时也指文件) f
双字 dw
字符串 sz
短整型 n
双精度浮点 d
计数 c(通常用cnt)
字符 ch(通常用c)
整型 i(通常用n)
字节 by
字 w
实型 r
无符号 u
3. 描述部分
最大 Max
最小 Min
初始化 Init
临时变量 T(或Temp)
源对象 Src
目的对象 Dest
4. MFC、句柄、控件及结构的命名规范
Windows类型 样本变量 MFC类 样本变量
HWND hWnd CWnd* pWnd
HDLG hDlg CDialog* pDlg
HDC hDC CDC* pDC
HGDIOBJ hGdiObj CGdiObject* pGdiObj
HPEN hPen CPen* pPen
HBRUSH hBrush CBrush* pBrush
HFONT hFont CFont* pFont
HBITMAP hBitmap CBitmap* pBitmap
HPALETTE hPaltte CPalette* pPalette
HRGN hRgn CRgn* pRgn
HMENU hMenu CMenu* pMenu
HWND hCtl CState* pState
HWND hCtl CButton* pButton
HWND hCtl CEdit* pEdit
HWND hCtl CListBox* pListBox
HWND hCtl CComboBox* pComboBox
HWND hCtl CScrollBar* pScrollBar
HSZ hszStr CString pStr
POINT pt CPoint pt
SIZE size CSize size
RECT rect CRect rect
5. 变量命名规范
ch char 8位字符 chGrade
ch TCHAR 如果_UNICODE定义,则为16位字符 chName
b BOOL 布尔值 bEnable
n int 整型(其大小依赖于操作系统) nLengt
n UINT 无符号值(其大小依赖于操作系统) nHeight
w WORD 16位无符号值 wPos
l LONG 32位有符号整型 lOffset
dw DWORD 32位无符号整型 dwRange
p * 指针 pDoc
lp FAR* 远指针 lpszName
lpsz LPSTR 32位字符串指针 lpszName
lpsz LPCSTR 32位常量字符串指针 lpszName
lpsz LPCTSTR 如果_UNICODE定义,则为32位常量字符串指针 lpszName
h handle Windows对象句柄 hWnd
lpfn callback 指向CALLBACK函数的远指针
前缀 符号类型 实例 范围
IDR_ 不同类型的多个资源共享标识 IDR_MAIINFRAME 1~0x6FFF
IDD_ 对话框资源 IDD_SPELL_CHECK 1~0x6FFF
HIDD_ 对话框资源的Help上下文 HIDD_SPELL_CHECK 0x20001~0x26FF
IDB_ 位图资源 IDB_COMPANY_LOGO 1~0x6FFF
IDC_ 光标资源 IDC_PENCIL 1~0x6FFF
IDI_ 图标资源 IDI_NOTEPAD 1~0x6FFF
ID_ 来自菜单项或工具栏的命令 ID_TOOLS_SPELLING 0x8000~0xDFFF
HID_ 命令Help上下文 HID_TOOLS_SPELLING 0x18000~0x1DFFF
IDP_ 消息框提示 IDP_INVALID_PARTNO 8~0xDEEF
HIDP_ 消息框Help上下文 HIDP_INVALID_PARTNO 0x30008~0x3DEFF
IDS_ 串资源 IDS_COPYRIGHT 1~0x7EEF
IDC_ 对话框内的控件 IDC_RECALC 8~0xDEEF
应用程序符号命名规范
Microsoft MFC宏命名规范:
名称 类型
_AFXDLL 唯一的动态连接库(Dynamic Link Library,DLL)版本
_ALPHA 仅编译DEC Alpha处理器
_DEBUG 包括诊断的调试版本
_MBCS 编译多字节字符集
_UNICODE 在一个应用程序中打开Unicode
AFXAPI MFC提供的函数
CALLBACK 通过指针回调的函数
6. 库标识符命名法
标识符 值和含义
u ANSI(N)或Unicode(U)
d 调试或发行:D = 调试,忽略标识符为发行。
静态库版本命名规范:
库 描述
NAFXCWD.LIB 调试版本:MFC静态连接库
NAFXCW.LIB 发行版本:MFC静态连接库
UAFXCWD.LIB 调试版本:具有Unicode支持的MFC静态连接库
UAFXCW.LIB 发行版本:具有Unicode支持的MFC静态连接库
动态连接库命名规范:
名称 类型
_AFXDLL 唯一的动态连接库(DLL)版本
WINAPI Windows所提供的函数
Windows.h中新的命名规范:
类型 定义描述
WINAPI 使用在API声明中的FAR PASCAL位置,如果正在编写一个具有导出API人口点的DLL,则可以在自己的API中使用该类型
CALLBACK 使用在应用程序回叫例程,如窗口和对话框过程中的FAR PASCAL的位置
LPCSTR 与LPSTR相同,只是LPCSTR用于只读串指针,其定义类似(const char FAR*)
UINT 可移植的无符号整型类型,其大小由主机环境决定(对于Windows NT和Windows 9x为32位);它是unsigned int的同义词
LRESULT 窗口程序返回值的类型
LPARAM 声明lParam所使用的类型,lParam是窗口程序的第四个参数
WPARAM 声明wParam所使用的类型,wParam是窗口程序的第三个参数
LPVOID 一般指针类型,与(void *)相同,可以用来代替LPSTR
7. 举例
hwnd : h 是类型描述,表示句柄, wnd 是变量对象描述,表示窗口,所以 hwnd 表示窗口句柄;
pfnEatApple : pfn 是类型描述,表示指向函数的指针, EatApple 是变量对象描述,所以它表示指向 EatApple 函数的函数指针变量。
g_cch : g_ 是属性描述,表示全局变量,c 和 ch 分别是计数类型和字符类型,一起表示变量类型,这里忽略了对象描述,所以它表示一个对字符进行计数的全局变量。
MFC、句柄、控件及结构的命名规范:
Windows类型 样本变量;MFC类 样本变量
HWND hWnd;
CWnd* pWnd;
HDLG hDlg;
CDialog* pDlg;
HDC hDC;
CDC* pDC;
HGDIOBJ hGdiObj;
CGdiObject* pGdiObj;
HPEN hPen;
CPen* pPen;
HBRUSH hBrush;
CBrush* pBrush;
HFONT hFont;
CFont* pFont;
HBITMAP hBitmap;
CBitmap* pBitmap;
HPALETTE hPaltte;
CPalette* pPalette;
HRGN hRgn;
CRgn* pRgn;
HMENU hMenu;
CMenu* pMenu;
HWND hCtl;
CState* pState;
HWND hCtl;
CButton* pButton;
HWND hCtl;
CEdit* pEdit;
HWND hCtl;
CListBox* pListBox;
HWND hCtl;
CComboBox* pComboBox;
HWND hCtl;
CScrollBar* pScrollBar;
HSZ hszStr;
CString pStr;
POINT pt;
CPoint pt;
SIZE size;
CSize size;
RECT rect;
CRect rect;
16. 目录操作(linux)
1. 获取目录
char *getcwd(char * buf,size_t size);getcwd函数把当前工作目录存入buf中,如果目录名超出了参数size长度,函数返回NULL,如果成功,返回buf。
char strpwd[301];
memset(strpwd,0,sizeof(strpwd));
getcwd(strpwd,300);
printf("当前目录是:%s\n",strpwd);
2. 切换工作目录
int chdir(const char *path);返回值:0-切换成功;非0-失败。
3. 目录的创建与删除
int mkdir(const char *pathname, mode_t mode);mode的含义将按open系统调用的O_CREAT选项中的有关定义设置,当然,它还要服从umask的设置况,是不是看不明白?那先固定填0755,注意,0不要省略哦,它表示八进制。
mkdir("/tmp/aaa",0755); // 创建/tmp/aaa目录
删除目录函数的声明:int rmdir(const char *pathname);
4. 获取目录中的文件列表
包含头文件:#include
相关库函数:
打开目录的函数opendir的声明:DIR *opendir(const char *pathname);
读取目录的函数readdir的声明:struct dirent *readdir(DIR *dirp);
关闭目录的函数closedir的声明:int closedir(DIR *dirp);
数据结构:
目录指针DIR:DIR *目录指针名;
struct dirent结构体:每调用一次readdir函数会返回一个struct dirent的地址,存放了本次读取到的内容,它的原理与fgets函数读取文件相同。
struct dirent
{
long d_ino; // inode number 索引节点号
off_t d_off; // offset to this dirent 在目录文件中的偏移
unsigned short d_reclen; // length of this d_name 文件名长
unsigned char d_type; // the type of d_name 文件类型
char d_name [NAME_MAX+1]; // file name文件名,最长255字符
};
d_name文件名或目录名。
d_type描述了文件的类型,有多种取值,最重要的是8和4,8-常规文件(A regular file);4-目录(A directory),其它的暂时不关心。
实例:
/*
* 程序名:book123.c,此程序用于演示读取目录下的文件名信息
* 作者:C语言技术网(www.freecplus.net) 日期:20190525
*/
#include
#include
int main(int argc,char *argv[])
{
if (argc != 2) { printf("请指定目录名。\n"); return -1; }
DIR *dir; // 定义目录指针
// 打开目录
if ( (dir=opendir(argv[1])) == 0 ) return -1;
// 用于存放从目录中读取到的文件和目录信息
struct dirent *stdinfo;
while (1)
{
// 读取一条记录并显示到屏幕
if ((stdinfo=readdir(dir)) == 0) break;
printf("name=%s,type=%d\n",stdinfo->d_name,stdinfo->d_type);
}
closedir(dir); // 关闭目录指针
}
#include
#include
// 列出目录及子目录下的文件
int ReadDir(const char *strpathname);
int main(int argc,char *argv[])
{
if (argc != 2) { printf("请指定目录名。\n"); return -1; }
// 列出目录及子目录下的文件
ReadDir(argv[1]);
}
// 列出目录及子目录下的文件
int ReadDir(const char *strpathname)
{
DIR *dir; // 定义目录指针
char strchdpath[256]; // 子目录的全路径
if ( (dir=opendir(strpathname)) == 0 ) return -1; // 打开目录
struct dirent *stdinfo; // 用于存放从目录读取到的文件和目录信息
while (1)
{
if ((stdinfo=readdir(dir)) == 0) break; // 读取一记录
if (strncmp(stdinfo->d_name,".",1)==0) continue; // 以.开始的文件不读
if (stdinfo->d_type==8) // 如果是文件,显示出来
printf("name=%s/%s\n",strpathname,stdinfo->d_name);
if (stdinfo->d_type==4) // 如果是目录,再调用一次ReadDir
{
sprintf(strchdpath,"%s/%s",strpathname,stdinfo->d_name);
ReadDir(strchdpath);
}
}
closedir(dir); // 关闭目录指针
}

5.文件目录操作扩展
access库函数
access函数用于判断当前操作系统用户对文件或目录的存取权限。
包含头文件
#include
函数声明:
int access(const char *pathname, int mode);
pathname文件名或目录名,可以是当前目录的文件或目录,也可以列出全路径。
mode 需要判断的存取权限。在头文件unistd.h中的预定义如下:
#define R_OK 4 // R_OK 只判断是否有读权限
#define W_OK 2 // W_OK 只判断是否有写权限
#define X_OK 1 // X_OK 判断是否有执行权限
#define F_OK 0 // F_OK 只判断是否存在
返回值:
当pathname满足mode的条件时候返回0,不满足返回-1。
在实际开发中,access函数主要用于判断文件或目录是否是存在。
stat库函数
stat结构体
struct stat结构体用于存放文件和目录的状态信息,如下:
struct stat
{
dev_t st_dev; // device 文件的设备编号
ino_t st_ino; // inode 文件的i-node
mode_t st_mode; // protection 文件的类型和存取的权限
nlink_t st_nlink; // number of hard links 连到该文件的硬连接数目, 刚建立的文件值为1.
uid_t st_uid; // user ID of owner 文件所有者的用户识别码
gid_t st_gid; // group ID of owner 文件所有者的组识别码
dev_t st_rdev; // device type 若此文件为设备文件, 则为其设备编号
off_t st_size; // total size, in bytes 文件大小, 以字节计算
unsigned long st_blksize; // blocksize for filesystem I/O 文件系统的I/O 缓冲区大小.
unsigned long st_blocks; // number of blocks allocated 占用文件区块的个数, 每一区块大小为512 个字节.
time_t st_atime; // time of lastaccess 文件最近一次被存取或被执行的时间, 一般只有在用mknod、 utime、read、write 与tructate 时改变.
time_t st_mtime; // time of last modification 文件最后一次被修改的时间, 一般只有在用mknod、 utime 和write 时才会改变
time_t st_ctime; // time of last change i-node 最近一次被更改的时间, 此参数会在文件所有者、组、 权限被更改时更新
};
struct stat结构体的成员变量比较多,对程序员来说,重点关注st_mode、st_size和st_mtime成员就可以了。注意st_mtime是一个整数表达的时间,需要程序员自己写代码转换格式。
st_mode成员的取值很多,或者使用如下两个宏来判断。
S_ISREG(st_mode) // 是否为一般文件
S_ISDIR(st_mode) // 是否为目录
stat库函数包含头文件:
#include
#include
#include
函数声明:
int stat(const char *path, struct stat *buf);
stat函数获取path指定文件或目录的信息,并将信息保存到结构体buf中,执行成功返回0,失败返回-1。
//实例
#include
#include
#include
// 本程序运行要带一个参数,即文件或目录名
int main(int argc,char *argv[])
{
if (argc != 2) { printf("请指定目录或文件名。\n"); return -1; }
if (access(argv[1],F_OK) != 0) { printf("文件或目录%s不存在。\n",argv[1]); return -1; }
struct stat ststat;
// 获取文件的状态信息
if (stat(argv[1],&ststat) != 0) return -1;
if (S_ISREG(ststat.st_mode)) printf("%s是一个文件。\n",argv[1]);
if (S_ISDIR(ststat.st_mode)) printf("%s是一个目录。\n",argv[1]);
}
utime库函数
utime函数用于修改文件的存取时间和更改时间。
包含头文件:
#include
函数声明:
int utime(const char *filename, const struct utimbuf *times);
函数说明:utime()用来修改参数filename 文件所属的inode 存取时间。如果参数times为空指针(NULL), 则该文件的存取时间和更改时间全部会设为目前时间。结构utimbuf 定义如下:
struct utimbuf
{
time_t actime;
time_t modtime;
};
返回值:执行成功则返回0,失败返回-1。
rename库函数
rename函数用于重命名文件或目录,相当于操作系统的mv命令,对程序员来说,在程序中极少重命名目录,但重命名文件是经常用到的功能。
包含头文件:#include
函数声明:
int rename(const char *oldpath, const char *newpath);
参数说明:
oldpath 文件或目录的原名。
newpath 文件或目录的新的名称。
返回值:0-成功,-1-失败。
remove库函数
remove函数用于删除文件或目录,相当于操作系统的rm命令。
包含头文件:
#include
函数声明:
int remove(const char *pathname);
参数说明:
pathname 待删除的文件或目录名。
返回值:0-成功,-1-失败。
17. 时间操作(linux)
采用1970年1月1日作为UNIX的纪元时间,1970年1月1日0点作为计算机表示时间的是中间点,将从1970年1月1日开始经过的秒数用一个整数存放,这种高效简洁的时间表示方法被称为“Unix时间纪元”,向左和向右偏移都可以得到更早或者更后的时间。
1. time_t别名
用time_t来表示时间数据类型,它是一个long(长整数)类型的别名,在time.h文件中定义,表示一个日历时间,是从1970年1月1日0时0分0秒到现在的秒数。
typedef long time_t;
2. time库函数
time函数的用途是返回一个值,也就是从1970年1月1日0时0分0秒到现在的秒数。
time_t time(time_t *t);
time函数有两种调用方法:
time_t tnow;
tnow =time(0); // 将空地址传递给time函数,并将time返回值赋给变量tnow
=============或
time(&tnow); // 将变量tnow的地址作为参数传递给time函数
3. tm结构体
ime_t只是一个长整型,不符合我们的使用习惯,需要转换成可以方便表示时间的结构体,即tm结构体,tm结构体在time.h中声明,如下:
struct tm
{
int tm_sec; // 秒:取值区间为[0,59]
int tm_min; // 分:取值区间为[0,59]
int tm_hour; // 时:取值区间为[0,23]
int tm_mday; // 日期:一个月中的日期:取值区间为[1,31]
int tm_mon; // 月份:(从一月开始,0代表一月),取值区间为[0,11]
int tm_year; // 年份:其值等于实际年份减去1900
int tm_wday; // 星期:取值区间为[0,6],其中0代表星期天,1代表星期一,以此类推
int tm_yday; // 从每年的1月1日开始的天数:取值区间为[0,365],其中0代表1月1日,1代表1月2日,以此类推
int tm_isdst; // 夏令时标识符,该字段意义不大,我们不用夏令时。
};
4. localtime库函数
localtime函数用于把time_t表示的时间转换为struct tm结构体表示的时间,函数返回struct tm结构体的地址。
struct tm * localtime(const time_t *);
struct tm结构体包含了时间的各要素,但还不是我们习惯的时间表达方式,我们可以用格式化输出printf、sprintf或fprintf等函数,把struct tm结构体转换为我们想要的结果。
#include
#include
int main(int argc,char *argv[])
{
time_t tnow;
tnow=time(0); // 获取当前时间
printf("tnow=%lu\n",tnow); // 输出整数表示的时间
struct tm *sttm;
sttm=localtime(&tnow); // 把整数的时间转换为struct tm结构体的时间
// yyyy-mm-dd hh24:mi:ss格式输出,此格式用得最多
printf("%04u-%02u-%02u %02u:%02u:%02u\n",sttm->tm_year+1900,sttm->tm_mon+1,\
sttm->tm_mday,sttm->tm_hour,sttm->tm_min,sttm->tm_sec);
printf("%04u年%02u月%02u日%02u时%02u分%02u秒\n",sttm->tm_year+1900,\
sttm->tm_mon+1,sttm->tm_mday,sttm->tm_hour,sttm->tm_min,sttm->tm_sec);
// 只输出年月日
printf("%04u-%02u-%02u\n",sttm->tm_year+1900,sttm->tm_mon+1,sttm->tm_mday);
}
5. mktime库函数
mktime函数的功能与localtime函数相反。
localtime函数用于把time_t表示的时间转换为struct tm表示的时间。
mktime 函数用于把struct tm表示的时间转换为time_t表示的时间。
#include
#include
#include
int main(int argc,char *argv[])
{
// 2019-12-25 15:05:03整数表示是1577257503
struct tm sttm;
memset(&sttm,0,sizeof(sttm));
sttm.tm_year=2019-1900; // 注意,要减1900
sttm.tm_mon=12-1; // 注意,要减1
sttm.tm_mday=25;
sttm.tm_hour=15;
sttm.tm_min=5;
sttm.tm_sec=3;
sttm.tm_isdst = 0;
printf("2019-12-25 15:05:03 is %lu\n",mktime(&sttm));
}
6. 程序睡眠
在实际开发中,我们经常需要把程序挂起一段时间,可以使用sleep和usleep两个库函数,需要包含unistd.h头文件中。函数的声明如下:
unsigned int sleep(unsigned int seconds);
int usleep(useconds_t usec);
sleep函数的参数是秒,usleep函数的参数是微秒,1秒=1000000微秒。
sleep(1); // 程序睡眠1秒。
sleep(10); // 程序睡眠10秒。
usleep(100000); // 程序睡眠十分之一秒。
usleep(1000000); // 程序睡眠一秒。
7.精确到微秒的计时器
精确到微秒的timeval结构体
timeval结构体在sys/time.h文件中定义,声明为:
struct timeval
{
long tv_sec; // 1970年1月1日到现在的秒。
long tv_usec; // 当前秒的微妙,即百万分之一秒。
};
时区timezone 结构体
imezone 结构体在sys/time.h文件中定义,声明为:
struct timezone
{
int tz_minuteswest; // 和UTC(格林威治时间)差了多少分钟。
int tz_dsttime; // type of DST correction,修正参数据,忽略
};
gettimeofday库函数
gettimeofday是获得当前的秒和微秒的时间,其中的秒是指1970年1月1日到现在的秒,微秒是指当前秒已逝去的微秒数,可以用于程序的计时。调用gettimeofday函数需要包含sys/time.h头文件。
int gettimeofday(struct timeval *tv, struct timezone *tz )
当前的时间存放在tv 结构体中,当地时区的信息则放到tz所指的结构体中,tz可以为空。
函数执行成功后返回0,失败后返回-1。
在使用gettimeofday()函数时,第二个参数一般都为空,我们一般都只是为了获得当前时间,不关心时区的信息。
#include
#include // 注意,不是time.h
int main()
{
struct timeval begin,end; // 定义用于存放开始和结束的时间
gettimeofday(&begin,0); // 计时器开始
printf("begin time(0)=%d,tv_sec=%d,tv_usec=%d\n",time(0),begin.tv_sec,begin.tv_usec);
sleep(2);
usleep(100000); // 程序睡眠十分之一秒。
gettimeofday(&end,0); // 计时器结束
printf("end time(0)=%d,tv_sec=%d,tv_usec=%d\n",time(0),end.tv_sec,end.tv_usec);
printf("计时过去了%d微秒。\n",\
(end.tv_sec-begin.tv_sec)*1000000+(end.tv_usec-begin.tv_usec));
}
18.调试工具gdb
执行以下命令安装或升级。
yum -y install gdb
用gcc编译源程序的时候,编译后的可执行文件不会包含源程序代码,如果您打算编译后的程序可以被调试,编译的时候要加-g的参数,例如:
gcc -g -o book113 book113.c
在命令提示符下输入gdb book113就可以调试book113程序了。
gdb book113
基本调试命令
| 命令 | 命令****缩写 | 命令说明 |
|---|---|---|
| set args | 设置主程序的参数。例如:./book119 /oracle/c/book1.c /tmp/book1.c设置参数的方法是:gdb book119(gdb) set args /oracle/c/book1.c /tmp/book1.c | |
| break | b | 设置断点,b 20 表示在第20行设置断点,可以设置多个断点。 |
| run | r | 开始运行程序, 程序运行到断点的位置会停下来,如果没有遇到断点,程序一直运行下去。 |
| next | n | 执行当前行语句,如果该语句为函数调用,不会进入函数内部执行。 |
| step | s | 执行当前行语句,如果该语句为函数调用,则进入函数执行其中的第一条语句。注意了,如果函数是库函数或第三方提供的函数,用s也是进不去的,因为没有源代码,如果是您自定义的函数,只要有源码就可以进去。 |
| p | 显示变量值,例如:p name表示显示变量name的值。 | |
| continue | c | 继续程序的运行,直到遇到下一个断点。 |
| set var name=value | 设置变量的值,假设程序有两个变量:int ii; char name[21];set var ii=10 把ii的值设置为10;set var name=“西施” 把name的值设置为"西施",注意,不是strcpy。 | |
| quit | q | 退出gdb环境。 |
19.makefile
make,可以用它来管理多模块程序的编译和链接,直至生成可执行文件。
make程序需要一个编译规则说明文件,称为makefile,makefile文件中描述了整个软件工程的编译规则和各个文件之间的依赖关系。
make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说大多数编译器都有这个命令,使用make可以是重新编译的次数达到最小化。
all:book1 book46
book1:book1.c
gcc -o book1 book1.c
book46:book46.c _public.h _public.c
gcc -o book46 book46.c _public.c
clean:
rm -f book1 book46
第一行
all:book book46
all: 这是固定的写法。
book1 book46表示需要编译目标程序的清单,中间用空格分隔开,如果清单很长,可以用\换行。
第二行
makefile文件中的空行就像C程序中的空行一样,只是为了书写整洁,没有什么意义。
第三行
book1:book1.c
book1:表示需要编译的目标程序。
如果要编译目标程序book1,需要依赖源程序book1.c,当book1.c的内容发生了变化,执行make的时候就会重新编译book1。
第四行
gcc -o book1 book1.c
这是一个编译命令,和在操作系统命令行输入的命令一样,但是要注意一个问题,在gcc之前要用tab键,看上去像8个空格,实际不是,一定要用tab,空格不行。
第六行
book46:book46.c _public.h _public.c
与第三行的含义相同。
book46:表示编译的目标程序。
如果要编译目标程序book46,需要依赖源程序book46.c、_public.h和_public.c三个文件,只要任何一个的内容发生了变化,执行make的时候就会重新编译book46。
第七行
gcc -o book46 book46.c _public.c
与第四行的含义相同。
第九行
clean:
清除目标文件,清除的命令由第十行之后的脚本来执行。
第十行
rm -f book1 book46
清除目标文件的脚本命令,注意了,rm之前也是一个tab键,不是空格。
20. 内存管理
| 序号 | 函数和描述 |
|---|---|
| 1 | void *calloc(int num, int size); 在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了 num*size 个字节长度的内存空间,并且每个字节的值都是0。 |
| 2 | void free(void *address); 该函数释放 address 所指向的内存块,释放的是动态分配的内存空间。 |
| 3 | void *malloc(int num); 在堆区分配一块指定大小的内存空间,用来存放数据。这块内存空间在函数执行完成后不会被初始化,它们的值是未知的。 |
| 4 | void *realloc(void *address, int newsize); 该函数重新分配内存,把内存扩展到 newsize。 |
#include