消息中间件 —— 初识Kafka
文章目录
- 1、Kafka简介
-
- 1.1、消息队列
-
- 1.1.1、为什么要有消息队列?
- 1.1.2、消息队列
- 1.1.3、消息队列的分类
- 1.1.4、p2p 和 发布订阅MQ的比较
- 1.1.5、消息系统的使用场景
- 1.1.6、常见的消息系统
- 1.2、Kafka简介
-
- 1.2.1、简介
- 1.2.2、设计目标
- 1.2.3、kafka核心的概念
- 2、Kafka的分布式安装
-
- 2.1 jdk & zookeeper安装
-
- 1、jdk 安装配置
- 2、zookeeper安装
- 2.2、Kafka安装步骤
-
-
- 修改Kafka配置
-
- 3、Kafka集群
-
- 3.1、克隆机配置修改
-
-
-
- broker.id
- listeners
- zookeeper.connect
-
-
- 3.2、kafka集群启动
-
- 1、zookeeper启动
- 2、kafka启动
- 3.3、kafka操作命令
-
- 1、查看主题
- 2、创建主题:
-
- 2.1、创建一个名为“test”的topic,它有一个分区和一个副本
- 2.2、测试再次创建一个主题,设置分区为3,(最好跟主机数量一致):
- 2.3、创建主题cities,复制因子为2,分区为3
- 3、删除主题
- 4、启动生产者端/消费者端
- 4、zokeeper查看kafka日志
-
-
- 段segment
-
- 查看segment
-
1、Kafka简介
1.1、消息队列
1.1.1、为什么要有消息队列?

1.1.2、消息队列
- 消息 Message
网络中的两台计算机或者两个通讯设备之间传递的数据。例如说:文本、音乐、视频等内容。 - 队列 Queue
一种特殊的线性表(数据元素首尾相接),特殊之处在于只允许在首部删除元素和在尾部追加元素(FIFO)。
入队、出队。 - 消息队列 MQ
消息+队列,保存消息的队列。消息的传输过程中的容器;主要提供生产、消费接口供外部调用做数据的存
储和获取。
1.1.3、消息队列的分类
MQ主要分为两类:点对点p2p、发布订阅(Pub / Sub)
-
Peer-to-Peer 一般基于Pull或者Polling接收数据 发送到队列中的消息被一个而且仅仅一个接收者所接受,即
使有多个接收者在同一个队列中侦听同一消息 即支持异步“即发即收”的消息传递方式,也支持同步请求/应答
传送方式

-
发布订阅 发布到同一个主题的消息,可被多个订阅者所接收 发布/订阅即可基于Push消费数据,也可基于Pull
或者Polling消费数据 解耦能力比P2P模型更强

1.1.4、p2p 和 发布订阅MQ的比较
- 共同点
消息生产者生产消息发送到queue中,然后消费者从queue中读取并且消费消息。 - 不同点
p2p模型包括:消息队列(Queue)、发送者(Sender)、接收者(Receiver)
一个生产者生产的消息只有一个消费者(Consumer)(即一旦被消费,消息就不在消息队列中)。比如说打电
话。
pub/Sub包含:消息队列(Queue)、主题(Topic)、发布者(Publisher)、订阅者(Subscriber)
每个消息可以有多个消费者,彼此互不影响。比如我发布一个微博:关注我的人都能够看到。
1.1.5、消息系统的使用场景
- 解耦 各系统之间通过消息系统这个统一的接口交换数据,无须了解彼此的存在
- 冗余 部分消息系统具有消息持久化能力,可规避消息处理前丢失的风险
- 扩展 消息系统是统一的数据接口,各系统可独立扩展
- 峰值处理能力 消息系统可顶住峰值流量,业务系统可根据处理能力从消息系统中获取并处理对应量的请求
- 可恢复性 系统中部分键失效并不会影响整个系统,它恢复会仍然可从消息系统中获取并处理数据
- 异步通信 在不需要立即处理请求的场景下,可以将请求放入消息系统,合适的时候再处理
1.1.6、常见的消息系统
- RabbitMQ Erlang编写,支持多协议AMQP,XMPP,SMTP,STOMP。支持负载均衡、数据持久化。同时支
持Peer-to-Peer和发布/订阅模式。 - Redis 基于Key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言,
Redis对短消息(小于10kb)的性能比RabbitMQ好,长消息性能比RabbitMQ差。 - ZeroMQ 轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,Peer-to-Peer。它实质上是
一个库,需要开发人员自己组合多种技术,使用复杂度高。 - ActiveMQ JMS实现,Peer-to-Peer,支持持久化、XA(分布式)事务
- Kafka/Jafka 高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理
- MetaQ/RocketMQ 纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务
1.2、Kafka简介
1.2.1、简介
Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年12月份
开源,成为Apache的顶级项目。Kafka是一个高吞吐量的、持久性的、分布式发布订阅消息系统。它主要用于处理
活跃live的数据(登录、浏览、点击、分享、喜欢等用户行为产生的数据)。

Kafka三大特点:
- 高吞吐量
可以满足每秒百万级别消息的生产和消费——生产消费。 - 持久性
有一套完善的消息存储机制,确保数据的高效安全的持久化——中间存储。 - 分布式
基于分布式的扩展和容错机制;Kafka的数据都会复制到几台服务器上。当某一台故障失效时,生产者和消
费者转而使用其它的机器——整体
健壮性。
1.2.2、设计目标
- 高吞吐率 在廉价的商用机器上单机可支持每秒100万条消息的读写
- 消息持久化 所有消息均被持久化到磁盘,无消息丢失,支持消息重放
- 完全分布式 Producer,Broker,Consumer均支持水平扩展
- 同时适应在线流处理和离线批处理
1.2.3、kafka核心的概念
一个MQ需要哪些部分?生产、消费、消息类别、存储等等。 对于kafka而言,kafka服务就像是一个大的水池。不
断的生产、存储、消费着各种类别的消息。那么kafka由何组成呢?
Kafka服务:
- Topic:主题,Kafka处理的消息的不同分类。
- Broker:消息服务器代理,Kafka集群中的一个kafka服务节点称为一个broker,主要存储消息数据。存在硬
盘中。每个topic都是有分区的。- Partition:Topic物理上的分组,一个topic在broker中被分为1个或者多个partition,分区在创建topic的时候
指定。- Message:消息,是通信的基本单位,每个消息都属于一个partition
Kafka服务相关
- Producer:消息和数据的生产者,向Kafka的一个topic发布消息。
- Consumer:消息和数据的消费者,定于topic并处理其发布的消息。
- Zookeeper:协调kafka的正常运行。
2、Kafka的分布式安装
下载地址:https://kafka.apache.org/downloads
中文下载官网:https://kafka.apachecn.org/downloads.html
安装包链接:https://pan.baidu.com/s/1G9F8TEfI88wPi_j2-hkK1A?pwd=e9tu
源码包链接:https://pan.baidu.com/s/1LR7X3Is-JRsOOu3DdAp2aw?pwd=7249
2.1 jdk & zookeeper安装
我们知道Kafka是由Zookeeper管理的,那么在安装Kafka之前,先来安装一下Zookeeper吧~
1、jdk 安装配置
首先CentOS7中会默认自带jdk的,我的虚拟机里centos7默认自带的是open jdk 1.8.0_262_b10。
如果想要安装指定版本的jdk,则先下载jdk安装包。
Linux安装jdk的详细步骤
2、zookeeper安装
我的kafka安装包是3.4.0版本的,对应的zookeeper版本是3.6.3,那么去官网下载好压缩包(注意是 bin.tar.gz压缩包):
官网:http://archive.apache.org/dist/zookeeper/
首先,将安装包放到Linux目录下执行以下命令:
$ mkdir zk
# 创建Zookeeper数据存储路径
$ mkdir zk/data
# 创建Zookeeper日志存放路径
$ mkdir zk/logs
# 解压安装包
$ tar -zxvf apache-zookeeper-3.8.1-bin.tar.gz
# 配置环境变量,添加下述内容
$ vi /etc/profile
export ZK_HOME=/home/install_package/apache-zookeeper-3.8.1-bin/bin
export PATH=$ZK_HOME/bin:$PATH
$ source /etc/profile
# 生成Zookeeper配置文件
$ cd apache-zookeeper-3.8.1-bin/conf
$ cp zoo_sample.cfg zoo.cfg # 因为zookeeper默认加载的配置文件名是zoo.cfg
然后修改一下配置(数据目录和日志目录):
vim zoo.cfg
# 心跳间隔时间,时间单位为毫秒值
tickTime=2000
# leader与客户端连接超时时间,设为5个心跳间隔
initLimit=10
# Leader与Follower之间的超时时间,设为2个心跳间隔
syncLimit=5
# 数据存放目录
dataDir=/home/admin/Study/zk/data
# 日志存放目录
dataLogDir=/home/admin/Study/zk/logs
# 客户端通信端口
clientPort=2181
# 清理间隔,单位是小时,默认是0,表示不开启
#autopurge.purgeInterval=1
# 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目,默认是保留3个
#autopurge.snapRetainCount=5
# 单机版不配下述配置
# server.NUM=IP:port1:port2 NUM表示本机为第几号服务器;IP为本机ip地址;
# port1为leader与follower通信端口;port2为参与竞选leader的通信端口
# 多个实例的端口配置不能重复,如下:
#server.0=192.168.101.136:12888:13888
#server.1=192.168.101.146:12888:13888
1、启动zookeeper后台服务:
zkServer.sh start

2、关闭zookeeper后台服务:
zkServer.sh stop
3、查看zookeeper后台服务运行状态:
zkServer.sh status

2.2、Kafka安装步骤
1、首先,在Linux下kafka压缩包所在的目录下,解压:
$ mkdir kafka
# 创建kafka日志存放路径
$ mkdir kafka/logs
# 解压安装包
$ tar -zxvf kafka_2.12-3.4.0.tgz
# 移动到kafka目录下
mv kafka_2.12-3.4.0 kafka
# 配置环境变量,添加下述内容
$ vi /etc/profile
export KAFKA_HOME=/home/admin/Study/kafka/kafka_2.12-3.4.0
export PATH=$KAFKA_HOME/bin:$PATH
$ source /etc/profile
# 修改kafka配置
$ cd kafka_2.12-3.4.0/config
$ vi server.properties
修改Kafka配置
# broker.id每个实例的值不能重复
broker.id=0
# 配置主机的ip和端口
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://192.168.57.30:9092
#advertised.listeners=PLAINTEXT://10.11.0.203:9092
# 配置日志存储路径
log.dirs=/home/admin/Study/kafka/logs
# 配置zookeeper集群
zookeeper.connect=localhost:2181
启动kafka,zokeeper启动的前提下:
bin/kafka-server-start.sh -daemon config/server.properties
判断kafka启动成功:

kafka关闭:
bin/kafka-server-stop.sh -daemon config/server.properties
3、Kafka集群
准备三台虚拟机。这里将上面安装好的虚拟机直接克隆两份。
克隆过程很简单,这里不再赘述。接下来看一下克隆好后需要哪些配置的修改。
3.1、克隆机配置修改
① 修改主机名
关闭全部虚拟机,打开克隆好的第一台,修改主机名为kafka02:
vim /etc/hostname
② 修改网络地址
vim /etc//sysconfig/network-scripts/ifcfg-ens33

③ 重启:
reboot
另一台同样方法修改:
主机名:kafka03
ip地址:192.168.255.214
(题外话:修改命令行背景色和字体色)
打开命令行——> Edit ——> Preferences ——> Colors :取消勾选Use colors from system theme
④ 进入到kafka安装目录下修改kafka server.properties配置文件:
vim config/server.properties


broker.id
该属性⽤于唯⼀标记⼀个Kafka的Broker,它的值是⼀个任意integer值。
当Kafka以分布式集群运⾏的时候,尤为重要。
最好该值跟该Broker所在的物理主机有关的,如主机名为host1.lagou.com,则broker.id=1,如果主机名为192.168.100.101,则broker.id=101等等。
listeners
⽤于指定当前Broker向外发布服务的地址和端⼝。
与advertised.listeners配合,⽤于做内外⽹隔离。
内外⽹隔离配置:
- listener.security.protocol.map
监听器名称和安全协议的映射配置。
⽐如,可以将内外⽹隔离,即使它们都使⽤SSL。
- listener.security.protocol.map=INTERNAL:SSL,EXTERNAL:SSL
每个监听器的名称只能在map中出现⼀次。
- inter.broker.listener.name
⽤于配置broker之间通信使⽤的监听器名称,该名称必须在advertised.listeners列表中。
inter.broker.listener.name=EXTERNAL
listeners
⽤于配置broker监听的URI以及监听器名称列表,使⽤逗号隔开多个URI及监听器名称。
如果监听器名称代表的不是安全协议,必须配置 listener.security.protocol.map。
每个监听器必须使⽤不同的⽹络端⼝。
- advertised.listeners
需要将该地址发布到zookeeper供客户端使⽤,如果客户端使⽤的地址与listeners配置不同。
可以在zookeeper的get /myKafka/brokers/ids/
中找到。 在IaaS环境,该条⽬的⽹络接⼝得与broker绑定的⽹络接⼝不同。
如果不设置此条⽬,就使⽤listeners的配置。跟listeners不同,该条⽬不能使⽤0.0.0.0⽹络端⼝。
advertised.listeners的地址必须是listeners中配置的或配置的⼀部分。
zookeeper.connect
该参数⽤于配置Kafka要连接的Zookeeper/集群的地址。
它的值是⼀个字符串,使⽤逗号分隔Zookeeper的多个地址。Zookeeper的单个地址是host:port形式的,可以在最后添加Kafka在Zookeeper中的根节点路径。
3.2、kafka集群启动
1、zookeeper启动
zkServer.sh start
2、kafka启动
命令:
bin/kafka-server-start.sh -daemon config/server.properties
以下报错信息:

是因为kafka目录下logs文件夹meta.properties文件中的broker.id和server.properties中的不一致了,修改一下即可。

启动成功:

3.3、kafka操作命令
参考官网快速开始:Kafka中文文档
1、查看主题
(新安装kafka是没有主题的)
bin/kafka-topics.sh --list --bootstrap-server 192.168.255.212:9092

2、创建主题:
2.1、创建一个名为“test”的topic,它有一个分区和一个副本
bin/kafka-topics.sh --create --bootstrap-server 192.168.255.212:9092 --replication-factor 1 --partitions 1 --topic test
![]()
此时查看主题:

在另外两台kafka主机上同样可以看到:


此时,我们查看3台kafka的logs目录下:



可以看到创建的test主题。
2.2、测试再次创建一个主题,设置分区为3,(最好跟主机数量一致):
bin/kafka-topics.sh --create --bootstrap-server 192.168.255.212:9092 --replication-factor 1 --partitions 3 --topic city

可以看到3台机器logs目录下分别都有一个主题分区。



2.3、创建主题cities,复制因子为2,分区为3
命令:
bin/kafka-topics.sh --create --bootstrap-server 192.168.255.212:9092 --replication-factor 2 --partitions 3 --topic cities

查看日志目录下可以看到3个分区每个都有两份:



3、删除主题
bin/kafka-topics.sh --delete --bootstrap-server 192.168.255.212:9092 --topic 主题名
4、启动生产者端/消费者端
以下命令:创建一个生产者客户端,产生消息,主题为test。注意,生产者客户端可以在任意主机上只要包含kafka,命令存在即可执行,当前在213这台kafka上,既作为server又充当客户端。
bin/kafka-console-producer.sh --broker-list 192.168.255.213:9092 --topic test
回车,输入消息:
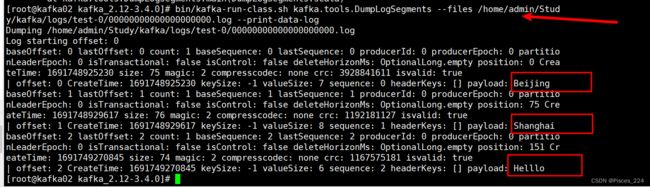
>Beijing
>Shanghai
现在启动一个消费者:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
后面加–from-beginning表示接受所有包括之前的消息;不加表示只接受最新的消息,过往的(消费者启动前)不接受。

![]()
此时,生产一个Hello消息:

两个消费者的接收:


注意:消费者不管消费哪个ip,都可以收到消息~
4、zokeeper查看kafka日志
上述操作命令我们都依次执行并在kafka logs目录下查看到产生的主题。那么实际上我们也可以在zokeeper中查看。
命令:
进入到zookeeper bin目录下
zkCli.sh
ls /
![]()
ls /brokers
ls /brokers/ids
ls /brokers/topics

打开 brokerid = 0,查看数据内容:
ls /brokers/ids/0
get /brokers/ids/0
可以查看到当前主机的信息,以json格式存储。

接下来查看主题内容:
ls /brokers/topics/cities
ls /brokers/topics/cities/partitions
ls /brokers/topics/cities/partitions/0
ls /brokers/topics/cities/partitions/0/state
get /brokers/topics/cities/partitions/0/state

get /brokers/topics/cities

0号主机上有cities-1、cities-2分区。
同理,其他部分也可查看:

段segment
segment 是一个逻辑概念,其由两类物理文件组成,分别为“.index”文件和“.log”文
件。“.log”文件中存放的是消息,而“.index”文件中存放的是“.log”文件中消息的索引。
进入test主题所在主机的logs下:

表示前面有0条消息。
00000000000000001456.log 表示前面有1456条消息。

查看segment
想要查看segment中的log文件,需要通过kafka自带的一个工具查看。
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files
/home/admin/Study/kafka/logs/test-0/00000000000000000000.log --print-data-log
一个用户的一个主题会被提交到一个__consumer_offsets 分区中。使用主题字符串的
hash 值与 50 取模,结果即为分区索引。一般默认为50个分区(0 ~ 49)。
