mysql优化系列:一、准备测试数据
环境:
- widow 11
- mysql 8.0.28
- DBEaver 22.0.3
- node v16.4.2
- mockjs: “^1.1.0”
要测试mysql的性能,必先准备大量的数据,比如,向表中插入100万条数据。。。
为了批量生成这些数据,我再nodejs中使用mockjs每次生成1万条假数据,并写个脚本批量运行100次,mysql中便有了100万条数据。
一、使用mockjs造假数据
我准备了一张表,如下:
create table testdata(
id int primary key auto_increment,
china_name varchar(255),
eng_name varchar(255),
salt varchar(255),
age int,
num float,
dateTime datetime,
image varchar(255),
color varchar(255),
title varchar(255),
cword varchar(255),
cparagraph varchar(255),
region varchar(255),
province varchar(255),
ip varchar(255),
url varchar(255),
identify varchar(255)
)
然后,找个空目录(D:\jackletter\mockbigdata),新建文件index.js,代码如下:
const Mock = require('mockjs')
const fs = require("fs");
const Random = Mock.Random;
var sql = `insert into testdata(china_name,eng_name,salt,age,num,dateTime,image,color,title,cword,cparagraph,region,province,ip,url,identify) values`;
var count = 10000;
for (let index = 0; index < count; index++) {
var data = {
// 中文名字 | 姓 | 名
china_name: Random.cname(),
// 英文名 | firatname | lastname | 带中间字的
eng_name: Random.name(),
// 长度为4的字符串
salt: Random.string(8),
// 数字 最小1 最大100
age: Random.integer(1, 100),
// 数字 浮点数
num: Random.float(1, 10, 1, 4),
// 日期 时间 YYYY-MM-DD HH:mm:ss
dateTime: Random.datetime(),
// 图片
image: Random.image('200x100', '#ffcc33', '#FFF', 'png', '文字'),
// 颜色 hex rgb
color: Random.color(),
// 标题
title: Random.ctitle(),
cword: Random.cword(),
// 一段文本 1段-100段
cparagraph: Random.cparagraph(1, 2),
// 区域
region: Random.region(),
// 省 city zip couty 等
province: Random.province(),
// ip 域名 网址
ip: Random.ip(),
url: Random.url(),
// 身份证
identify: Random.id(),
};
sql += `\r\n\t('${data.china_name}','${data.eng_name}','${data.salt}',${data.age},${data.num},'${data.dateTime}','${data.image}','${data.color}','${data.title}','${data.cword}','${data.cparagraph}','${data.region}','${data.province}','${data.ip}','${data.url}','${data.identify}')`;
if (index == count-1) {
sql += ";";
} else {
sql += ",";
}
}
fs.writeFile("D:\\jackletter\\\mockbigdata\\testFile.sql", sql, function (err) {
if (err) {
console.log(err, "写入sql失败");
} else {
console.log("写入sql成功!!!");
}
});
然后,右键打开终端,如下:
先输入:npm i mockjs,

然后,运行:node .\index.js
最后将,生成的sql执行即可:

二、用c#代码批量执行插入
为了防止mysql客户端卡死,上面只生成了1万条数据,但这远远不够的,所以我用c#代码写了个循环,执行了100次,如下:
[Test]
public void InsertBigData()
{
for (int i = 0; i < 100; i++)
{
var p = Process.Start(@"D:\Applications\nodejs\node.exe", @"D:\jackletter\mockbigdata\index.js");
p.WaitForExit();
var text = File.ReadAllText(@"D:\jackletter\mockbigdata\testFile.sql");
//执行sql插入
db.ExecuteSql(text);
}
}
大概用了1分钟,1百万条数据就造好了:
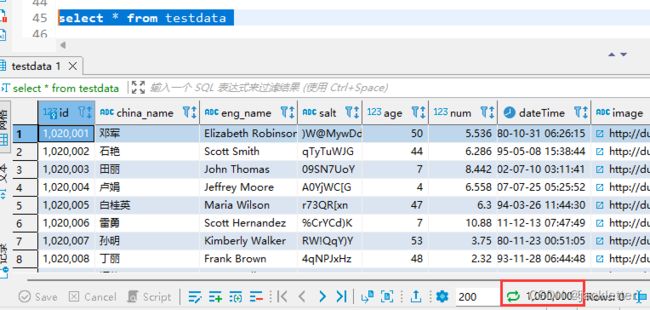
三、验证:分页查询的页码越大,查询的性能越差
select * from testdata limit 0,10 -- 0ms
select * from testdata limit 10000,10 -- 5ms
select * from testdata limit 500000,10 -- 405ms
select * from testdata limit 900000,10 -- 664ms

注意:
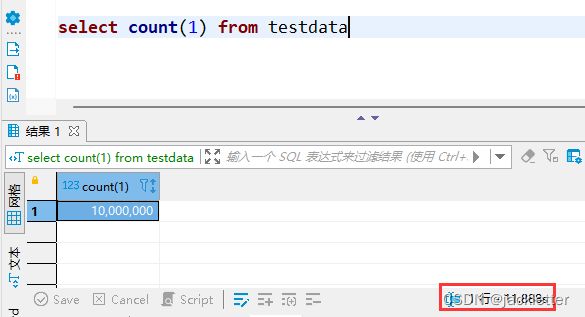
select count(1) from testdata这行语句要执行将近1s,估计是mysql没有存储表的总行数,而是一个一个查的。。。
当数据总量达到1千万的时候,select count(1) from test竟然需要长达12s:

另外,通过查询元数据,我们还发现元数据里面统计的行数和实际的不符:
难道是因为这个表的格式是 Dynamic???

四、验证:走索引查询的性能最优
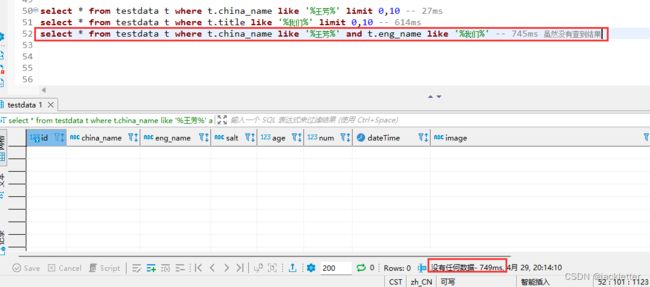
先看不使用索引的查询:
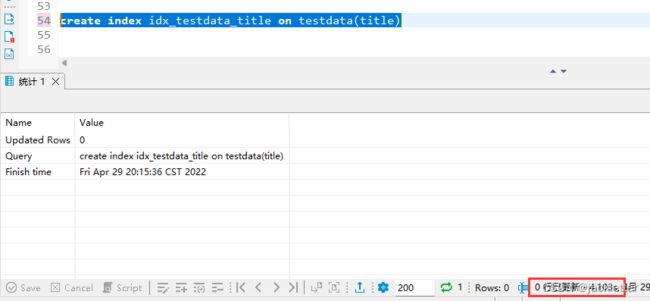
然后,我们在title列上加索引(建立索引耗费4s):
然后,再执行查询:
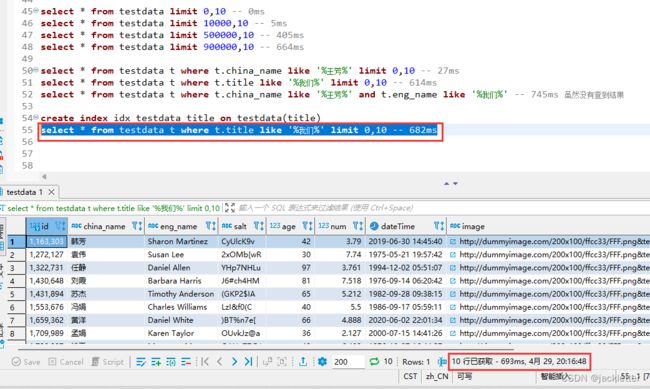
好像比不加索引还慢。。。
不过,换种写法:

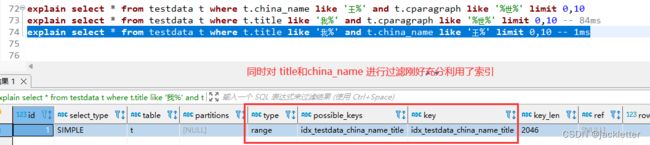
可以看到,性能优化的还是很明显的,即使有在有多个过滤条件,但只有单个命中时,它的效率也是很高的:

从上面,我们可以看出,索引的效率确实很高,而且对于字符串列,必须使用xxx%这种格式才行!
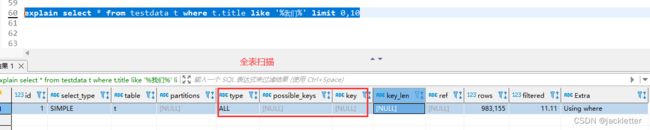
其实,我们可以从查询计划中观察出来:


五、验证:联合列索引分先后顺序
先把上面的索引删除:
drop index idx_testdata_title on testdata
然后,新建索引(注意:china_name列和title列的先后顺序,耗时4.75s):

然后,分别进行,查询:

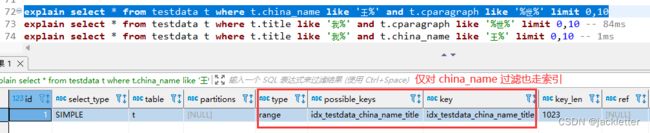
因为索引本身也是有结构的,所以要想使用索引,sql中必须先对china_name进行过滤,然后可以选择再对title过滤。
如果,仅对title进行过滤是不能走索引的。
这就好理解上面的耗时了吧,通过explain的也可以很好的解释: