计算机网络——UDP与TCP
一、运输层的作用
运输层在整个网络体系结构中位于面向通信部分的最高层,同时也是用户功能中的最低层。它提供的是应用进程间的逻辑通信。所谓逻辑通信,指的是它屏蔽了下层网络的细节,使得进程看见的就是好像在两个运输层实体之间有一条端到端的逻辑通信信道,但实际上并不存在这样一个信道。
运输层有两种不同的运输协议:面向连接的TCP协议和无连接的UDP协议。当运输层采用面向连接的TCP协议时,尽管下面的网络是不可靠的(只提供尽最大努力服务),但这种逻辑通信信道就相当于一条全双工的可靠信道。但当运输层采用无连接的UDP协议时,这种逻辑通信信道仍然是一条不可靠信道。
二、用户数据报协议UDP
2.1 UDP的特点
UDP协议比较简单,它只是在IP数据报服务之上增加了一点功能,即复用和分用功能以及差错检测功能。UDP的特点如下:
- UDP是无连接的,即发送数据之前不需要建立连接,因此减少了开销和发送数据之前的时延。
- UDP使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的连接状态表。
- UDP是面向报文的。发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。在接收方的UDP,对IP层交上来的UDP用户数据报,在去除首部后就原封不动地交付上层的应用进程。也就是说,UDP一次交付一个完整的报文。
- UDP没有拥塞控制,因此网络出现的拥塞不会使源主机的发送速率降低。
- UDP支持一对一、一对多、多对一和多对多的交互通信。
- UDP的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
2.2 UDP的首部格式
UDP的首部由四个字段组成,每个字段的长度都是两个字节。

其中“校验和”部分是用来检测UDP用户数据报在传输中是否有错,有错就丢弃。但在计算检验和时,要在UDP用户数据报之前增加12个字节的伪首部。
所谓的伪首部并不是UDP用户数据报真正的首部。只是在计算检验和时,临时添加在UDP用户数据报前面,得到一个临时的UDP用户数据报。检验和的计算过程如下:
在发送方,首先是先把全零放入检验和字段。再把伪首部以及UDP用户数据报看成是由许多16位的字串接起来。若UDP用户数据报的数据部分不是偶数个字节,则要填入一个全零字节(但此字节不发送)。然后按二进制反码计算出这些16位字的和。将此和的二进制反码写入检验和字段后,就发送这样的UDP用户数据报。在接收方,把收到的UDP用户数据报连同伪首部(以及可能的填充全零字节)一起,按二进制反码求这些16位字的和。当无差错时其结果应为全1。否则就表明有差错出现,接收方就应丢弃这个UDP用户数据报。

三、传输控制协议TCP
TCP相比于UDP就要复杂的多了,它的特点如下
- TCP是面向连接的运输层协议。这就是说,应用程序在使用TCP协议之前,必须先建立TCP连接。在传送数据完毕后,必须释放已经建立的TCP连接。
- 每一条TCP连接只能有两个端点(endpoint),每一条TCP连接只能是点对点的(一对一)。
- TCP提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达。
- TCP提供全双工通信。TCP允许通信双方的应用进程在任何时候都能发送数据。
- 面向字节流。虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序交下来的数据看成仅仅是一连串的无结构的字节流。TCP并不知道所传送的字节流的含义。
3.1 连接
TCP把连接作为最基本的抽象。TCP的许多特性都与TCP是面向连接的这个基本特性有关。上面说了每条TCP连接都只能有两个端点,这个端点叫做套接字。它由IP地址:端口号构成,比如192.3.4.5:80。每一条TCP连接唯一地被通信两端的两个端点(即两个套接字)所确定。
![]()
3.2 可靠传输
TCP发送的报文段是交给IP层传送的。但IP层只能提供尽最大努力服务,也就是说,TCP下面的网络所提供的是不可靠的传输。那么TCP是如何让两个运输层之间的通信变得可靠的呢?
- 停止等待协议
“停止等待”就是每发送完一个分组就停止发送,等待对方的确认。在收到确认后再发送下一个分组。
如果分组在传输过程中出现了差错,接收方就会丢弃这个分组,然后什么也不做。发送方只要超过一段时间仍没有收到确认,就重发之前那个分组。这种情况叫超时重传。

如果接收方收到了分组,并发送了确认,但这条确认在传输过程中丢失了。但发送方并不知道是接收方没有收到分组,还是自己没有收到确认。所以发送方仍然会进行超时重传。此时接收方会收到一个重复的分组。接收方会丢弃这个重复的分组,并重新发送一条确认。这种情况叫做确认丢失。
还有一种情况是接收方收到了分组,并发出了确认。但这条确认迟到了。在确认还未到达时,发送方进行了超时重传。此时接收方会重复收到分组,因此会丢弃这个分组并再次发送确认。相当于发送方前后会收到两条相同的确认。此时发送方会直接丢弃这个确认。这种情况叫确认迟到。

像上述的这种可靠传输协议常称为自动重传请求(ARQ),它的优点是简单,但缺点是信道利用率太低。
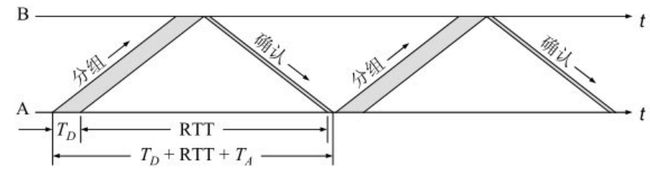
- 连续ARQ协议
为了解决停止等待协议信道利用率低的问题,人们采用了流水线的方式进行传输。即发送方连续发送多个分组,而不是每发送一个分组就停下来等待确认。这种方式可以显著提高信道利用率。但也会使算法更加复杂。

发送方会维护一个发送窗口(如下图)。位于发送窗口内的五个分组可以连续地发送出去而不必等待确认。发送方每收到一个确认,就把发送窗口向前滑动一个分组的位置。

接收方一般都是采用累积确认的方式。这就是说,接收方不必对收到的分组逐个发送确认,而是在收到几个分组后,对按序到达的最后一个分组发送确认,这就表示:到这个分组为止的所有分组都已正确收到了。
这样做的优点是容易实现,但缺点是无法向发送方反映出接收方正确收到的所有分组信息。
3.3 流量控制
如果发送方把数据发送得过快,接收方就可能来不及接收,这就会造成数据的丢失。所谓流量控制(flow control)就是让发送方的发送速率不要太快,要让接收方来得及接收。
通过前面讲的滑动窗口机制,可以很方便地实现流量控制。具体的做法是在接收方发送确认时,设置一个限制窗口大小的值。当发送方收到确认信息时,就会设置发送窗口不超过接收方给出的窗口值。
当窗口值设置为0时,发送方就会停止发送,并等待接收方发送非零窗口通知。但假如接收方发送的非零窗口通知在传输过程中丢失了,就会造成发送方等待非零通知,接收方等待发送方的数据的情况。也就是造成了死锁。
为了避免这种情况,TCP为每一个连接设有一个持续计时器。只要TCP连接的一方收到对方的零窗口通知,就启动持续计时器。若持续计时器设置的时间到期,就发送一个零窗口探测报文段(仅携带1字节的数据),而对方就在确认这个探测报文段时给出了现在的窗口值。如果窗口仍然是零,那么收到这个报文段的一方就重新设置持续计时器。如果窗口不是零,那么死锁的僵局就可以打破了。
某些情况下,发送方可能只需要发送1字节的数据,但经过运输层和网络层后,会被添加40字节的首部。也就是说,1字节的数据在发送时扩大了几十倍。这样显然效率低下。为了处理这种情况,TCP采用了Nagle算法:若发送应用进程把要发送的数据逐个字节地送到TCP的发送缓存,则发送方就把第一个数据字节先发送出去,把后面到达的数据字节都缓存起来。当发送方收到对第一个数据字符的确认后,再把发送缓存中的所有数据组装成一个报文段发送出去,同时继续对随后到达的数据进行缓存。只有在收到对前一个报文段的确认后才继续发送下一个报文段。当数据到达较快而网络速率较慢时,用这样的方法可明显地减少所用的网络带宽。
另外,接收方也可能出现糊涂窗口综合症的问题:TCP接收方的缓存已满,而交互式的应用进程一次只从接收缓存中读取1个字节(这样就使接收缓存空间仅腾出1个字节),然后向发送方发送确认,并把窗口设置为1个字节(但发送的数据报是40字节长)。接着,发送方又发来1个字节的数据(请注意,发送方发送的IP数据报是41字节长)。接收方发回确认,仍然将窗口设置为1个字节。这样进行下去,使网络的效率很低。
要解决这个问题,可以让接收方等待一段时间,使得或者接收缓存已有足够空间容纳一个最长的报文段,或者等到接收缓存已有一半空闲的空间。只要出现这两种情况之一,接收方就发出确认报文,并向发送方通知当前的窗口大小。此外,发送方也不要发送太小的报文段,而是把数据积累成足够大的报文段,或达到接收方缓存的空间的一半大小。
3.4 拥塞控制
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫做拥塞(congestion)。
如果一个路由器没有足够的缓存空间,它就会丢弃一些新到的分组。但当分组被丢弃时,发送这一分组的源点就会重传这一分组,甚至可能还要重传多次。这样会引起更多的分组流入网络和被网络中的路由器丢弃。可见拥塞引起的重传并不会缓解网络的拥塞,反而会加剧网络的拥塞。
所谓拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制可以分为开环控制和闭环控制。
开环控制方法就是在设计网络时事先将有关发生拥塞的因素考虑周到,力求网络在工作时不产生拥塞。但一旦整个系统运行起来,就不再中途进行改正了。
闭环控制是基于反馈环路的概念。属于闭环控制的有以下几种措施:
- 监测网络系统以便检测到拥塞在何时、何处发生。
- 把拥塞发生的信息传送到可采取行动的地方。
- 调整网络系统的运行以解决出现的问题。
具体的进行拥塞控制的算法如下:
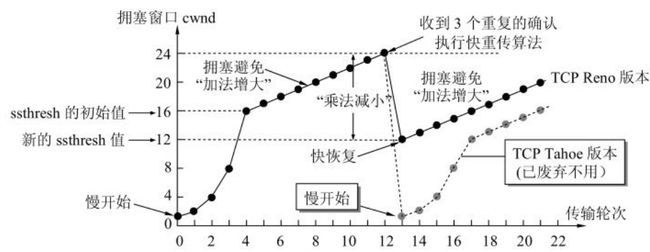
- 慢开始和拥塞避免
所谓的慢开始,就是发送方维持一个叫做拥塞窗口的变量,并让发送窗口等于拥塞窗口。在发送时只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
当慢开始阶段拥塞窗口达到一定的“门限”,就开始执行拥塞避免算法。拥塞避免算法的思路是让拥塞窗口缓慢地增大,即每经过一个往返时间就把发送方的拥塞窗口加1(加法增大)。
当出现网络拥塞时,就将之前设定的“门限”减少一半(乘法减小),然后从头开始执行慢开始算法。

- 快重传和快恢复
如果单纯的使用慢开始和拥塞避免算法,就可能发生如下情况:发送方的超时计时器时限已到但还没有收到确认,此时判断为网络拥塞,并将拥塞窗口设置为1,开始执行慢开始。但现实中出现这种情况并不一定是网络拥塞,而只是单纯的分组丢失。
所以快重传要求接收方,每收到一个失序的报文段后就立即发出重复确认。比如下面这个例子,因为M3丢失,接收方在收到M4后,立刻发送M2的确认消息。后面M5、M6到达后同样发送M2的重复确认。发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段M3,而不必继续等待为M3设置的重传计时器到期。

与快重传配合使用的还有快恢复算法。它要求发送方连续收到三个重复确认时,就执行“乘法减小”,把慢开始的门限减半。然后并不执行慢开始算法,而是直接将拥塞窗口设置为门限大小,然后直接开始执行拥塞避免算法。这样做的原因是在连续收到重复确认的情况下不太可能发生网络拥塞。
3.5 连接控制
TCP是面向连接的协议,因此TCP运输连接的建立和释放是每一次面向连接的通信中必不可少的过程。运输连接共分为三个阶段:连接建立、数据传送、连接释放。
- 连接建立
TCP建立连接的过程需要经过三次握手。客户端首先向服务器发送连接请求报文段。服务器收到请求后向客户端发送一次确认。客户端收到确认后还要向服务器返回一个确认。此时客户端已经进入了“已建立连接”状态。当服务器收到客户端的确认消息后,也进入“已建立连接”状态。

客户端收到确认消息后还要发送一次确认的原因是为了防止已失效的连接请求报文段突然又传送到了服务器,从而产生错误。假如没有第二次确认,可能会出现以下状况:客户端发送了一个连接请求,但因为网络原因延迟到达了服务器。此时服务器会发送确认信息,并进入“已建立连接”状态。但客户端因为之前的请求已经超时,所以即使收到确认也不会理睬。此时,服务器就会一直等待客户端发送数据,从而造成资源的浪费。
- 连接释放
TCP释放连接需要进行四次握手。首先客户端向服务器发送连接释放报文段,并主动关闭TCP连接。服务器收到后发送确认,并进入“关闭等待”状态。此时TCP连接处于半关闭状态,即客户端已经没有数据要发送,但服务器发送数据,客户端仍要接收。客户端收到确认后进入“终止等待2”状态。若服务器没有要发送的数据了,就会发出连接释放报文段,并进入“最后确认”状态。客户端收到连接释放报文后再次发送确认,并进入“时间等待”状态。等待指定时间后才真正进入关闭状态。

为什么最后要等待一段时间呢?
第一是为了防止客户端最后发送的确认在传输过程中丢失。如果丢失,服务器会超时重传之前的连接释放报文段,而此时客户端如果不等待的话,就无法收到这段报文,也就无法重传确认消息。从而服务器无法正常进入关闭状态。
第二是为了防止“已失效的连接请求报文段”出现在本连接中。等待一段时间可以让本次连接中产生的所有报文从网络中消失,从而不会影响到下次连接。
四、参考资料
[1].《计算机网络》谢希仁