TCP/IP网络编程 - 基础学习
1. 创建Socket
#include
#include
int sock = ::socket(PF_INET, SOCK_STREAM, 0); 原型:int socket(int domain, int type, int protocol);
domain: 协议族,可以是PF_INET,PF_INET6,PF_UNIX
type: socke类型,可以是SOCK_STREAM,SOCK_DGRAM,SOCK_RAW,可以或(|)上SOCK_NONBLOCK(非阻塞), SOCK_CLOEXEC(close on exec: fork的子进程在执行exec的时候自动关闭已经打开的sock)
其中:SOCK_STREAM:传输层,TCP
SOCK_DGRAM:传输层,UDP
SOCK_RAW:网络层(处理ICMP、IGMP等网络报文、特殊的IPv4报文、可以通过IP_HDRINCL套接字选项由用户构造IP头)
protocol: 在对应domain中对应的协议类型,通常为一一对应,设为0
参考:
SOCK_RAW 与 SOCK_STREAM 、SOCK_DGRAM 的区别_zhu2695的博客-CSDN博客
2. 设置socket的options
struct linger opt = {1, 1};
setsockopt(sock, SOL_SOCKET, SO_LINGER, (void *)&opt, sizeof(opt));原型:int setsockopt(int sockfd, int level, int optname,
const void *optval, socklen_t optlen);
sockfd:创建的fd
level:需要设置option所在的协议层,可以是SOL_SOCKET(套接字选项),IPPROTO_IP(IP选项),IPPROTO_TCP(TCP选项), IPPROTO_UDP(UDP选项)
其中一些SOL_SOCKET选项有:man 7 socket
SO_REUSEADDR: bind()时,即使需要绑定的地址被其他处于TIME_WAIT状态的socket占用,也可以立刻重用(也可以改/proc/sys/net/ipv4/tcp_tw_recycle来快速回收TIME_WAIT的socket,不建议)
SO_KEEPALIVE: tcp keepalive,设置后,如果tcp连接在7200s内没有数据交互,会触发tcp keepalive机制,(通常服务器端)会给对端主机发送keep-alive probe的tcp数据包(包含1个字节或者不含数据):
如果对方回复ack,则再次等7200s发送keep-alive;
如果对方崩溃以重启会回复RST,此时socket待处理错误被置为ECONNRESET,socket本身则被关闭;
如果对方没有回复,会每隔75s发送一次,发送9次,如果仍然没有应答,会断掉tcp连接,socket待处理错误被置为ETIMEOUT并且被关闭,如ICMP错误是“host unreachable(主机不可达)”,说明对方主机并没有崩溃,但是不可达,这种情况下待处理错误被置为 EHOSTUNREACH。
SO_LINGER: 控制socket在close或shutdown时,是否需要在缓冲区的数据发送出去后再返回
默认情况,在调用close()后,close会立即返回,内核的TCP模块会负责把socket对应缓冲区的数据发给对方。
如果l_onoff为0,则SO_LINGER不起作用,close用默认的行为关闭socket
如果l_onoff为1,l_linger为0,则close立即返回,TCP模块会丢弃发送缓冲区的数据,并且给对方发一个RST报文(可避免TIME_WAIT,但是可能会丢失数据)
如果l_onoff为1,l_linger大于0:
如果close是阻塞的,close会等待l_linger的时间,直到TCP模块把缓冲区的数据发完并收到ACK,如果在l_linger时间内,没有发送并确认完,close会返回-1,并且errno置为EWOULDBLOCK。
如果close是非阻塞的,close立即返回并且丢弃缓冲区数据。
struct linger { int l_onoff; /* linger active */ int l_linger; /* how many seconds to linger for */ };SO_OOBINLINE:在常规数据流中接收带外数据
SO_SNDBUF:发送缓冲区大小(udp没用,因为直接发到网络中去了)
SO_RCVBUF:接收缓冲区大小(socket级别,所以可以tcp/udp)
SO_SNDLOWAT:发送缓冲区的低水平标记位 (performance优化措施,防止cpu一直占用)
只对non-blocking的socket起作用,对于non-blocking的socket,send只能发送全部的数据或者SO_SNDLOWAT以上的数据(如果SO_SNDLOWAT为100,如果发送50字节,send会成功发送50字节或者返回失败,如果发送200字节,send可能成功发送100到200字节之间大小的数据,或者返回失败。默认SO_SNDLOWAT为1,send能发送1字节或者返回EWOULDBLOCK)
如果socket是block的,如果send不能发送全部的数据,会block,一直到有足够的缓冲区空间或者timeout(SO_SNDTIMEO)。
如果是select/poll/epoll,只有在缓冲区至少SO_SNDLOWAT的数据可写之后,才会返回socket可写。
SO_RCVLOWAT:接收缓冲区的低水平标记位
(非阻塞如何?值得验证) 对于阻塞recv会返回request的字节数或者超过SO_RCVLOWAT字节的数据
select/poll/epoll,只有在缓冲区至少有SO_RCVLOWAT的数据可读之后,才会返回socket可读
SO_RCVTIMEO:接收数据的超时时间。如果设置了该选项,recv/recvfrom函数会有一个block的时限,如果超过该时间就仍没有接收到更多的数据,会返回部分数据或者没有收到数据,返回失败(errno置为EWOULDBLOCK或EAGAIN),默认值为0(一直不会超时)。使用的结构体为struct timeval
#includestruct timeval { time_t tv_sec; /* seconds */ suseconds_t tv_usec; /* microseconds */ }; SO_SNDTIMEO:发送数据的超时时间。类似SO_RCVTIMEO
optname:上面提到的SO_SOCKET选项
optval:选项对应的结构体,通常为int/bool
SO_LINGER/SO_SNDTIMEO/SO_RCVTIMEO分别有专门的结构体
optlen:optval的字节大小
参考:
setsockopt
Network Sockets and Communication (Guile Reference Manual)
setsockopt 详解_张忠琳的博客-CSDN博客_linux setsockopt
10.2. Changing Network Kernel Settings Red Hat Enterprise Linux 5 | Red Hat Customer Portal
linux - What's the purpose of the socket option SO_SNDLOWAT - Stack Overflow
Related:
更改TCP keep-alive时间间隔:
TCP keepalive的详解(解惑) - 翔云123456 - 博客园
方法1 - 整个系统范围:
7200秒, 75秒, 9次这3个值可以通过更改这几个值
/proc/sys/net/ipv4/tcp_keepalive_time /proc/sys/net/ipv4/tcp_keepalive_intvl /proc/sys/net/ipv4/tcp_keepalive_probes或者在Linux中我们可以通过修改 /etc/sysctl.conf 的全局配置, 添加完下面的配置后输入
sysctl -p使其生效,并使用命令sysctl -a | grep keepalive 来查看当前的默认配置net.ipv4.tcp_keepalive_time=7200 net.ipv4.tcp_keepalive_intvl=75 net.ipv4.tcp_keepalive_probes=9方法2 - TCP单个连接的:man 7 tcp
使用tcp options:
TCP_KEEPCNT、TCP_KEEPIDLE、TCP_KEEPINTVL#include#include #include int keepalive = 1; int count = 5; setsockopt(sock, SOL_SOCKET, SO_KEEPALIVE, (void *)&keepalive, sizeof(keepalive)); setsockopt(sock, IPPROTO_TCP, TCP_KEEPCNT, (void *)&count, sizeof(count));
TCP keep-alive与HTTP keep-alive的区别:
面试官:TCP Keepalive 和 HTTP Keep-Alive 是一个东西吗?_小林coding的技术博客_51CTO博客
两者实现在不同的层次,作用也不同:
TCP keep-alive是TCP层(内核态)实现的,称为 TCP 保活机制,用于确保TCP连接的有效性,检测连接错误;
HTTP keep-alive是在应用层(用户态)实现的,称为 HTTP 长连接,用于HTTP连接复用,同一个连接上串行方式传递请求-响应数据,减少HTTP短连接需要多次建立/释放TCP连接消耗的资源;
有TCP keep-alive,仍需要应用层的心跳包的原因:
TCP中已有SO_KEEPALIVE选项,为什么还要在应用层加入心跳包机制?? - 知乎
- tcp keepalive只能检测连接是否存活,不能检测连接是否可用。比如服务器因为负载过高导致无法响应请求但是连接仍然存在,或者出现进程死锁或阻塞,此时keepalive可以正常收发,但检测出连接出错。
- 客户端与服务器之间有四层代理或负载均衡,即在传输层之上的代理,只有传输层以上的数据才被转发,例如socks5等
- 如果TCP连接中的另一方因为停电突然断网,我们并不知道连接断开,此时发送数据失败会进行重传,由于重传包的优先级要高于keepalive的数据包,因此keepalive的数据包无法发送出去。只有在长时间的重传失败之后我们才能判断此连接断开了。
TCP读写缓冲区大小:man tcp
通过sysctl -a | grep tcp_rmem 和 tcp_wmem
net.ipv4.tcp_rmem = 4096 131072 6291456 net.ipv4.tcp_wmem = 4096 16384 4194304或者cat /proc/sys/net/ipv4/tcp_rmem cat /proc/sys/net/ipv4/tcp_wmem
# cat /proc/sys/net/ipv4/tcp_rmem 4096 131072 6291456 # cat /proc/sys/net/ipv4/tcp_wmem 4096 16384 4194304这三个数值左中右分别是系统中tcp接收和发送缓冲区的最小值,默认值,最大值。用getsockopt可以得到默认值。
int wmem = 0; socklen_t wmem_len = sizeof(wmem); getsockopt(sock, SOL_SOCKET, SO_SNDBUF, (void *)&wmem, &wmem_len);可以通过设置SO_SNDBUF/SO_RCVBUF值设置单个socket的tcp发送/接收缓冲区。验证后,在一定范围内,系统会将设置值加倍,比如设置10240后,通过getsockopt得到的为20480
int wmem = 10240; setsockopt(sock, SOL_SOCKET, SO_SNDBUF, (void *)&wmem, sizeof(wmem));
UDP的读缓冲区,没有写缓冲区(因为没用):
通过sysctl -a | grep rmem
net.core.rmem_default = 212992 net.core.rmem_max = 212992可以通过设置SO_RCVBUF值设置单个udp socket(SOCK_DGRAM)的接收缓冲区,和tcp缓冲区一样,系统会将设置值加倍
int rmem = 10240; socklen_t rmem_len = sizeof(rmem); setsockopt(sock, SOL_SOCKET, SO_RCVBUF, (void *)&rmem, sizeof(rmem)); getsockopt(sock, SOL_SOCKET, SO_RCVBUF, (void *)&rmem, &rmem_len);
SO_SNDBUF/SO_RCVBUF与滑动窗口的关系:
SO_SNDBUF和SO_RCVBUF_库昊天的博客-CSDN博客_so_rcvbuf 设置上限
TCP滑动窗口(发送窗口和接受窗口) - hongdada - 博客园
【大厂面试必备系列】滑动窗口协议 - 飞天小牛肉 - 博客园
TCP/IP学习笔记:TCP拥塞控制 - 明明1109 - 博客园
3. socket绑定地址(命名socket)
1. 几种不同的地址结构:
- 通用的socket地址
//总长度16字节
struct sockaddr {
sa_family_t sa_family; // unsigned short int,16bit,2字节,AF_xxx
char data[14];
};
//总长度128字节
struct sockaddr_storage {
sa_family_t sa_family;
char __ss_padding[_SS_PADSIZE];
__ss_aligntype __ss_align; /* Force desired alignment. */
};- 专用的socket地址
// IP协议族 IPv4
// 总长度16字节
struct sockaddr_in {
sa_family_t sin_family; // AF_INET
uint16_t sin_port; // 网络字节序,需要从主机字节序转换 e.g. htons(3490)
struct in_addr sin_addr;
/* Pad to size of `struct sockaddr'. 8 字节*/
unsigned char sin_zero[sizeof (struct sockaddr)
- sizeof (sa_family_t)
- sizeof (uint16_t)
- sizeof (struct in_addr)];
};
struct in_addr {
uint32_t s_addr;
};
// IP协议族 IPv6
// 总长度28字节
struct sockaddr_in6 {
sa_family_t sin6_family; // AF_INET6
uint16_t sin6_port; /* Transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* IPv6 scope-id */
};
struct in6_addr {
union {
uint8_t __u6_addr8[16];
uint16_t __u6_addr16[8];
uint32_t __u6_addr32[4];
} __in6_u;
};
//UNIX本地协议族
struct sockaddr_un {
sa_family_t sun_family; // AF_LOCAL/AF_UNIX
char sun_path[108];
};以上地址之间转换通常使用强制转换。
2. sin_addr等地址与人类可读的point形式的IP转换:
#include
#include
char addr_point[] = "192.168.1.1";
char addr_bytes[sizeof(struct in_addr)];
int rc = inet_pton(AF_INET, addr_point, addr_bytes);
char buf[INET_ADDRSTRLEN];
if(inet_ntop(AF_INET, addr_bytes, buf, INET_ADDRSTRLEN) == NULL) {
std::cout << "Error" << std::endl;
return -1;
}
std::cout << "addr:" << buf << std::endl; 其中, 可以使用宏来设置point形式的地址长度:
#define INET_ADDRSTRLEN 16
#define INET6_ADDRSTRLEN 46函数原型:
- int inet_pton(int af, const char *src, void *dst);
af - 地址族,AF_INET或AF_INET6
src - point形式的地址
dst - 网络字节序地址
返回值 - 成功返回1,失败 - 返回0表明src中不存在可转换的地址,返回-1表示af不支持并且设置errno为EAFNOSUPPORT
- const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);
af - 地址族,AF_INET或AF_INET6
src - 网络字节序地址
dst - point形式的地址
size - dst的长度,INET_ADDRSTRLEN或INET6_ADDRSTRLEN
返回值 - 成功,返回非空的地址;失败返回空,并设置errno,ENOSPC表明地址超过size,EAFNOSUPPORT表明af不支持
PF_INET: 协议族,AF_INET:地址族
参考:
illumos: manual page: sockaddr_storage.3socket
Implementing AF-independent application
3. bind绑定地址(命名socket)
#include
#include
struct sockaddr_in address;
address.sin_family = AF_INET;
address.port = htons(666);
address.sin_addr.s_addr = htonl(INADDR_ANY);
int rt = bind(sock, (struct sockaddr *)&address, sizeof(address));
if (rt == -1 ) {
return -1;
} 函数原型:
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockfd - 需要绑定地址的socket
addr - 需要绑定的地址
addrlen - addr的长度
返回值 - 成功返回0,失败返回-1,并且置errno
bind的作用:
通常用在server端,来绑定具体的地址-端口,因为只有sever绑定了地址之后,客户端才知道需要connect哪里。
bind的使用:
绑定的时候,有时会使用INADDR_ANY来为地址赋值,是由于有时会有多个网卡,直到connect的时候才能确定具体使用的是哪个地址。使用INADDR_ANY可以是bind延迟绑定。
当addr的port设置为0时,系统会随机分配一个port
为什么socket server端需要bind, client端一般不需要bind - 王洪军个人博客
4. listen socket
#include
#include
int rc = listen(sock, 5); 原型:
int listen(int sockfd, int backlog);
sockfd - 已经绑定了地址的socket
backlog - 存放已经建立established连接,并且等待accept返回的socket的queue的最大长度。如果backlog超过了 /proc/sys/net/core/somaxconn中的值,那么backlog会设置成这个值。对于incomplete连接的socket的queue的最大长度可以通过设置 /proc/sys/net/ipv4/tcp_max_syn_backlog来实现(after Linux 2.2)
返回值 - 成功返回0,失败返回-1,并且设置errno
How TCP backlog works in Linux
深入探索 Linux listen() 函数 backlog 的含义_杨博东的博客的博客-CSDN博客_linux listen函数
SYN与Accept队列:
处于Listening状态的socket有两个队列:SYN队列和Accept队列
1. SYN队列(半连接队列): kernel收到客户端发送的SYN消息连接,后,建立SYN连接(struct inet_request_sock)并且把该连接存入SYN队列并且发送SYN+ACK,kernel会负责将SYN队列中连接没有收到ACK消息的超时重传,直至超过重传次数。存储在该队列的连接处于SYN-RECV状态。
2. Accept队列(全连接队列):kernel收到ACK消息之后,会找到SYN队列中匹配的连接,然后将该连接从SYN队列删除,并且建立完整连接(struct inet_sock)存放到Accpet队列,等待应用程序取走连接。存储在该队列的连接处于ESTABLISHED状态。在应用程序调用accept返回后,该连接会从Accept队列删除。
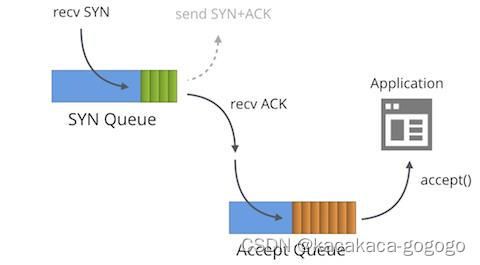
查看在SYN队列中的连接个数:ss -n state syn-recv sport = :80 | wc -l //查看端口80的SYN队列
查看在Accept队列中的连接个数:ss -plnt sport = :6443
查看SYN队列与Accept队列是否溢出:nstat -az | grep -E 'TcpExtListenOverflows|TcpExtListenDrops'
其中TcpExtListenOverflows:Accept queue队列超过上限时加1
TcpExtListenDrops:任何原因,包括Accept queue超限,创建新连接,继承端口失败等,加1
socket和tcp什么关系(TCP socket SYN队列和Accept队列区别原理解析) - 开心学习
https://blog.cloudflare.com/syn-packet-handling-in-the-wild/
怎么从Linux源码看Socket TCP的Listen及连接队列 - 系统运维 - 亿速云
万级并发服务器内核调优总结_Zwjsec的博客-CSDN博客
在Linux系统下的ss命令(socket statistics)各种使用示例_Linux命令_云网牛站
5. accept连接
#include
#include
int fd;
struct sockaddr_in addr;
socklen_t addr_len = sizeof(addr);//需设置,告诉内核要返回的地址长度,如果不设置会EINVAL
fd = accept(sock, (struct sockaddr *)&addr, &addr_len);
if (fd < 0) {
return -1;
} 原型:
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
sockfd - 用bind绑定的socket
addr - accpet成功后,存放对端的地址,如果对对端地址不感兴趣,可以置空。
addrlen - accept成功后,存放对端地址的长度,如果对对端地址不感兴趣,可以置空。
返回值 - 成功返回新的文件描述符(用该fd与客户端沟通),失败返回-1,并且置errno
accept()函数 Unix/Linux -Unix/Linux系统调用
accept的用法(man 2 accept):
用于面向连接的socket种类(SOCK_STREAM, SOCK_SEQPACKET),会从listening socket的队列中的第一个,创建新的连接,并返回文件描述符(用于与客户端的数据传输)。
如果listening socket队列中没有连接请求:
1.socket是阻塞的,那么accept会一直阻塞,直到有连接请求
2.socket是非阻塞的,那么accept会返回失败,errno:EAGAIN或EWOULDBLOCK
为了收到新的连接请求通知,可以使用:
1. select,poll,epoll:当发起了新的request时候,会返回可读事件(readable event)
2. SIGIO: 在listen socket上的连接请求完成的时候,会产生SIGIO
信号驱动式I/O - 故事, - 博客园
accept返回非致命错误并重试的情况:
1. 在linux中,accept会返回网络中already-pending的错误,因此需要在accept失败,把errno设置的这些错误当作EAGAIN并重试。在TCP/IP网络中,这些错误包括:ENETDOWN, EPROTO, ENOPROTOOPT, EHOSTDOWN, ENONET, EHOSTUNREACH, EOPNOTSUPP, and ENETUNREACH (man 2 accept - Error Handling)
2. 对于信号中断导致的accept失败,errno设置为EINTR,同样需要重试
3. accept返回前连接终止:连接状态已经变成ESTABLISHED,并且在accept返回之前,客户端发送了RST消息。(虽然UNIX网络编程说是ECONNABORT或EPROTO, 但是在Ubuntu中,会成功返回,但是在read时,会出错ECONNRESET,表明收到了RST),可以忽略该错误。
21-非阻塞accept_songly_的博客-CSDN博客_accept 非阻塞
UNIX网络编程卷一:套接字联网API
半连接/全连接队列满时,可以怎么做:
半连接队列满:(满后并且没有开启syncookies,kernel默认丢弃后续sync请求)
- 增大半连接队列长度 /proc/sys/net/ipv4/tcp_max_syn_backlog
- 开启/proc/sys/net/ipv4/tcp_syncookies (syncookies是服务器返回给客户端的ACK+SYN中的seq number)
- 降低sync+ack的重传次数/proc/sys/net/ipv4/tcp_syncack_retries
全连接队列满:(满后,kernel默认会丢弃后续的sync请求,如果把tcp_abort_on_overflow设置为1,会发送RST包)
- 增大全连接队列长度,全连接队列长度=min(backlog, /proc/sys/net/core/somaxconn)
TCP 半连接队列和全连接队列满了会发生什么?又该如何应对? - 小林coding - 博客园
TCP SYN cookie的作用、原理、缺陷_想做一只开心的菜鸡的博客-CSDN博客_syncookie
深入浅出TCP中的SYN-Cookies - SegmentFault 思否
6. connect连接
#include
#include
#include // for inet_pton & htons
char address_p[] = "127.0.0.1";
struct in_addr address_bytes;
inet_pton(AF_INET, address_p, &address_bytes);
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(6666);
addr.sin_addr.s_addr = address_bytes.s_addr;
int rc = connect(sock, (struct sockaddr *)&addr, sizeof(addr));
if (rc == -1) {
return -1;
} 原型:
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen) ;
sockfd - client创建的fd
addr - 将要连接的server的地址
addrlen - addr的长度
返回值 - 成功返回0,失败返回-1,并设置errno,man 2 connect
connect的使用:
面向连接(SOCK_STREAM or SOCK_SEQPACKET)和非面向连接(SOCK_DGRAM)的socket都可以使用connect
1. 对于SOCK_DGRAM类型的socket:
connect表示socket发送数据的默认地址,和唯一接收数据的地址。
如果想改变地址,可以重新调用connect。
如果想断开与地址的连接,可以重新调用connect并把参数addr的sa_family设置为AF_UNSPEC。
2. 对于SOCK_STREAM/SOCK_SEQPACKET类型的socket:
创建与addr地址绑定的socket的连接
connect失败的原因:
1. 收到了server的RST包,导致server发送RST包的原因:
- connect的server端口并没有处于监听状态
- 该端口处于TIME_WAIT状态
2. 超时没有收到server的回复
- server负载过高,服务端收到了客户端的SYN报文却来不及响应(eg,半连接队列满了)
- 网络拥塞,服务端发送的响应报文在网络传输过程中丢失,导致客户端收不到确认
- 路由不可达,中间的路由出问题,丢弃了SYN包,并给客户端发送了Destination unreachable的ICMP差错报文
ps:在没有收到回复的时候,linux kernel会多次尝试,尝试的最大次数通过更改tcp_syn_retries,默认值为6
https://blog.csdn.net/weixin_42226134/article/details/104284380
4-从tcp连接建立的角度分析connect函数_songly_的博客-CSDN博客
tcp(7) - Linux manual page
TCP源码分析 - 三次握手之 Connect 过程-51CTO.COM
7. close/shutdown断开连接
8. 传输数据
recv/send
recvfrom/sendto
UDP传输 :recvfrom 函数与 sendto 函数分析 - 知乎
recvfrom 辅助数据
recvmsg(2) - OpenBSD manual pages
UNIX网络编程读书笔记:辅助数据 - ITtecman - 博客园
unix(7) - Linux manual page
Linux msghdr结构讲解 | Ivanzz