分布式 - 消息队列Kafka:Kafka消费者分区再均衡(Rebalance)
文章目录
-
-
- 01. Kafka 消费者分区再均衡是什么?
- 02. Kafka 消费者分区再均衡的触发条件?
- 03. Kafka 消费者分区再均衡的过程?
- 04. Kafka 如何判定消费者已经死亡?
- 05. Kafka 如何避免消费者的分区再均衡?
- 06. Kafka 消费者分区再均衡有什么影响?
- 07. Kafka 消费者分区再均衡的两种机制?
- 08. kafka 消费者分区再均衡协议
- 09. kafka 消费者分区再均衡流程
- 10. Kafka 消费者组固定成员是什么?
- 11. Kafka 消费者分区再均衡的4种场景
-
01. Kafka 消费者分区再均衡是什么?
消费者群组里的消费者共享主题分区的所有权。当一个新消费者加入群组时,它将开始读取一部分原本由其他消费者读取的消息。当一个消费者被关闭或发生崩溃时,它将离开群组,原本由它读取的分区将由群组里的其他消费者读取。
分区的所有权从一个消费者转移到另一个消费者的行为称为再均衡。再均衡非常重要,它为消费者群组带来了高可用性和伸缩性(你可以放心地添加或移除消费者)。不过,在正常情况下,我们并不希望发生再均衡。
Rebalance 本质上是一组协议,它规定了一个消费者组是如何达成一致来分配订阅 主题的所有分区的。假设某个组下有20个消费者实例,该组订阅了一个有着100个分区的主题。正常情况下,Kafka会为每个消费者平均分配5个分区。这个分配过程就被称为 Rebalance。
Rebalance 就是说如果消费组里的消费者数量有变化或消费的分区数有变化,kafka 会重新分配消费者消费分区的关系。
02. Kafka 消费者分区再均衡的触发条件?
主题发生变化(比如管理员添加了新分区)会导致分区重分配。Kafka 消费者端的 Rebalance 操作会在以下情况下发生:
① 消费者组中新增或减少了消费者;
② 消费者所订阅的主题的分区数量发生变化;
③ 消费者订阅的主题个数发生变化;
后面两个通常都是运维的主动操作,所以它们引发的 Rebalance 大都是不可避免的。实际上大部分情况下,导致分区再均衡的原因都是消费者组成员数量发生变化。
03. Kafka 消费者分区再均衡的过程?
Rebalance 是通过消费者群组中的称为“群组首领”消费者客户端进行的。
① 选择群组首领:当一个消费者想要加入消费者群组时,它会向群组协调器发送 JoinGroup 请求。第一个加入群组的消费者将成为群组首领。
② 消费者通过向被指派为群组协调器(Coordinator)的 Broker 定期发送心跳来维持它们和群组的从属关系以及它们对分区的所有权。
③ 群组首领从群组协调器获取群组的成员列表(列表中包含了所有最近发送过心跳的消费者,它们被认为还“活着”),并负责为每一个消费者分配分区。它使用实现了PartitionAssignor接口的类来决定哪些分区应该被分配给哪个消费者。
④ 分区分配完毕之后,群组首领会把分区分配信息发送给群组协调器;
⑤ 群组协调器再把这些信息发送给所有的消费者。每个消费者只能看到自己的分配信息,只有群组首领会持有所有消费者及其分区所有权的信息。
04. Kafka 如何判定消费者已经死亡?
消费者会向被指定为群组协调器的broker(不同消费者群组的协调器可能不同)发送心跳,以此来保持群组成员关系和对分区的所有权关系。心跳是由消费者的一个后台线程发送的,只要消费者能够以正常的时间间隔发送心跳,它就会被认为还“活着”。
如果消费者在足够长的一段时间内没有发送心跳,那么它的会话就将超时,群组协调器会认为它已经“死亡”,进而触发再均衡。如果一个消费者发生崩溃并停止读取消息,那么群组协调器就会在几秒内收不到心跳,它会认为消费者已经“死亡”,进而触发再均衡。在这几秒时间里,“死掉”的消费者不会读取分区里的消息。在关闭消费者后,协调器会立即触发一次再均衡,尽量降低处理延迟。
05. Kafka 如何避免消费者的分区再均衡?
真实应用场景中引发 rebalance 最常见的原因就是消费者组中新增或减少了消费者,特别是consumer崩溃的情况。这里的崩溃不一定就是指 consumer进程“挂掉”或consumer进程所在的机器宕机。以下两种情况也被视为消亡,我们要做的就是如何避免这两种不必要的 Rebalance 出现。
① 未及时发送心跳
由于消费者未能及时发送心跳,导致消费者被提出消费者组而导致的Rebalance,因此需要仔细地设置session.timeout.ms 和 heartbeat.interval.ms的值,这里给出一些推荐数值,可以“无脑”地应用在生产环境中。
(1) 设置 session.timeout.ms = 6s。
(2) 设置 heartbeat.interval.ms = 2s。
要保证消费者实例在被判定为死亡之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。将 session.timeout.ms 设置成 6s 主要是为了让 Coordinator 能够更快地定位已经挂掉的 Consumer。毕竟,我们还是希望能尽快揪出那些“尸位素餐”的 Consumer,早日把它们踢出 Group。
② 消费者消费时间过长,无法在指定的时间内完成消息的处理
之前有一个客户,在他们的场景中,消费者消费数据时需要将消息处理之后写入到 MongoDB。显然这是一个很重的消费逻辑。MongoDB 的一丁点不稳定都会导致消费者程序消费时长的增加。此时,max.poll.interval.ms 参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。就拿 MongoDB 这个例子来说,如果写 MongoDB 的最长时间是 7 分钟,那么你可以将该参数设置为 8 分钟左右。
06. Kafka 消费者分区再均衡有什么影响?
① 影响消费者组的消费速度和吞吐量:消费者重新分配分区,可能会导致消费者停止消费一段时间,直到重新分配完成。
② 可能会产生消息重复消费:
因为Consumer消费分区消息的offset提交过程,不是实时的,由参数auto.commit.interval.ms控制提交的最小频率,默认是5000,也就是最少每5s提交一次。我们试想以下场景:提交位移之后的 3 秒发生了 Rebalance ,在 Rebalance 之后,所有 Consumer 从上一次提交的位移处继续消费,但该位移已经是 3 秒前的位移数据了,故在 Rebalance 发生前 3 秒消费的所有数据都要重新再消费一次。虽然可以通过减少 auto.commit.interval.ms 的值来提高提交频率,但这么做只能缩小重复消费的时间窗口,不可能完全消除它。
遗憾的是,目前kafka社区对于Reblance带来的影响,也没有彻底的解决办法。只能通过避免不必要的Rebalance减少影响。
07. Kafka 消费者分区再均衡的两种机制?
根据消费者群组所使用的分区分配策略的不同,再均衡可以分为两种类型。
① 主动再均衡 (range 分区分配策略和 round-robin 分区分配策略)
在进行主动再均衡期间,所有消费者都放弃当前分配到的分区所有权,即停止读取消息。消费者重新加入群组,获得重新分配到的分区,并继续读取消息。这样可以确保消费者群组中的每个消费者都获得相同数量的分区,从而实现负载均衡。但这个过程会导致整个消费者群组在一个很短的时间窗口内不可用,这个时间窗口的长短取决于消费者群组的大小和几个配置参数。
② 协作再均衡(sticky 分区分配策略)
Kafka协作再均衡(也称为增量再均衡)用于在消费者组成员发生变化时重新分配分区。 协作再均衡机制只会重新分配发生变化的分区,而不是所有分区(比如一个消费者退出消费者组后,它所消费的分区会重新分区给其他消费者)。
协作再均衡通常是指将一个消费者的部分分区重新分配给另一个消费者,其他消费者则继续读取没有被重新分配的分区。在协作再均衡中,消费者群组首领会通知所有消费者,它们将失去部分分区的所有权,然后消费者会停止读取这些分区,并放弃对它们的所有权。接着,消费者群组首领会将这些没有所有权的分区分配给其他消费者,从而实现分区的重新分配。虽然这种增量再均衡可能需要进行几次迭代,直到达到稳定状态,但它避免了主动再均衡中出现的“停止世界”停顿。这对大型消费者群组来说尤为重要,因为它们的再均衡可能需要很长时间。
08. kafka 消费者分区再均衡协议
rebalance 本质上是一组协议。group 与 coordinator 共同使用这组协议完成group的rebalance。最新版本Kafka中提供了下面5个协议来处理rebalance相关事宜。
① JoinGroup请求:consumer请求加入组。
② SyncGroup请求:group leader把分配方案同步更新到组内所有成员中。
③ Heartbeat请求:consumer定期向coordinator汇报心跳表明自己依然存活。
④ LeaveGroup请求:consumer主动通知coordinator该consumer即将离组。
⑤ DescribeGroup 请求:查看组的所有信息,包括成员信息、协议信息、分配方案以及订阅信息等。该请求类型主要供管理员使用。coordinator不使用该请求执行rebalance。
在rebalance过程中,coordinator主要处理consumer发过来的JoinGroup和SyncGroup请求。当consumer主动离组时会发送LeaveGroup请求给coordinator。
在成功rebalance之后,组内所有consumer都需要定期地向coordinator发送Heartbeat请求。而每个 consumer也是根据 Heartbeat请求的响应中是否包含REBALANCE_IN_PROGRESS来判断当前group是否开启了新一轮rebalance。
09. kafka 消费者分区再均衡流程
目前 rebalance主要分为两步:加入组和同步更新分配方案。
① 加入组:组内所有 consumer 向 coordinator 发送 JoinGroup请求。当收集全 JoinGroup请求后,coordinator从中选择一个 consumer 担任group的leader,并把所有成员信息以及它们的订阅信息发送给leader。特别需要注意的是,group 的 leader 和coordinator 不是一个概念。leader 是某个consumer 实例,coordinator 通常是Kafka 集群中的一个 broker。另外 leader 而非coordinator负责为整个group的所有成员制定分配方案。

② 同步更新分配方案:group 的 leader 开始制定分配方案,即根据前面提到的分配策略决定每个consumer都负责哪些topic的哪些分区。一旦分配完成,leader会把这个分配方案封装进 SyncGroup 请求并发送给 coordinator。比较有意思的是,组内所有成员都会发送 SyncGroup请求,不过只有 leader发送的 SyncGroup请求中包含了分配方案。coordinator 接收到分配方案后把属于每个 consumer 的方案单独抽取出来作为SyncGroup请求的response返还给各自的consumer。

10. Kafka 消费者组固定成员是什么?
在默认情况下,消费者的群组成员身份标识是临时的。当一个消费者离开群组时,分配给它的分区所有权将被撤销;当该消费者重新加入时,将通过再均衡协议为其分配一个新的成员ID和新分区。
可以给消费者分配一个唯一的group.instance.id,让它成为群组的固定成员。通常,当消费者第一次以固定成员身份加入群组时,群组协调器会按照分区分配策略给它分配一部分分区。当这个消费者被关闭时,它不会自动离开群组——它仍然是群组的成员,直到会话超时。当这个消费者重新加入群组时,它会继续持有之前的身份,并分配到之前所持有的分区。群组协调器缓存了每个成员的分区分配信息,只需要将缓存中的信息发送给重新加入的固定成员,不需要进行再均衡。
如果两个消费者使用相同的group.instance.id加入同一个群组,则第二个消费者会收到错误,告诉它具有相同ID的消费者已存在。
如果应用程序需要维护与消费者分区所有权相关的本地状态或缓存,那么群组固定成员关系就非常有用。如果重建本地缓存非常耗时,那么你肯定不希望在每次重启消费者时都经历这个过程。更重要的是,在消费者重启时,消费者所拥有的分区不会被重新分配。在重启过程中,消费者不会读取这些分区,所以当消费者重启完毕时,读取进度会稍稍落后,但你要相信它们一定会赶上。
需要注意的是,群组的固定成员在关闭时不会主动离开群组,它们何时“真正消失”取决于session.timeout.ms参数。你可以将这个参数设置得足够大,避免在进行简单的应用程序重启时触发再均衡,但又要设置得足够小,以便在出现严重停机时自动重新分配分区,避免这些分区的读取进度出现较大的滞后。
11. Kafka 消费者分区再均衡的4种场景
① 新成员加入组:

② 组成员崩溃:
组成员崩溃和组成员主动离开是两个不同的场景。因为在崩溃时成员并不会主动地告知 coordinator 此事,coordinator 有可能需要一个完整的 session.timeout 周期才能检测到这种崩溃,这必然会造成 consumer 的滞后。可以说离开组是主动地发起 rebalance;而崩溃则是被动地发起rebalance。
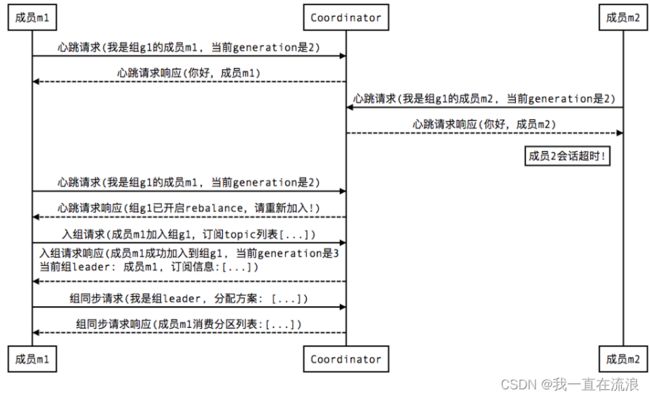
③ 组成员主动离开组:

④ 提交位移:
