图形化界面 图像识别
作者简介:热编程的贝贝,致力于C/C++、Java、Python等多编程语言,热爱跑步健身,喜爱音乐的一位博主。
本文收录于贝贝的日常汇报系列,大家有兴趣的可以看一看
相关专栏深度学习、目标检测系列等,大家有兴趣的可以看一看
C++零基础入门系列,Web入门篇系列正在发展中,喜欢Python、C++的朋友们可以关注一下哦!如有需要此项目工程,请评论区留言哦
前言
1、图形界面结果展示
2、代码结构展示
3、实现源码
前言
本系统是一个添加数据集,自动训练,验证、显示训练结果一体化的软件系统。通过可视化的界面,设置参数,训练,显示结果,推理一体化查看效果。
1、图形界面结果展示
使用步骤:
以下均为默认参数,可以自行设置如下参数
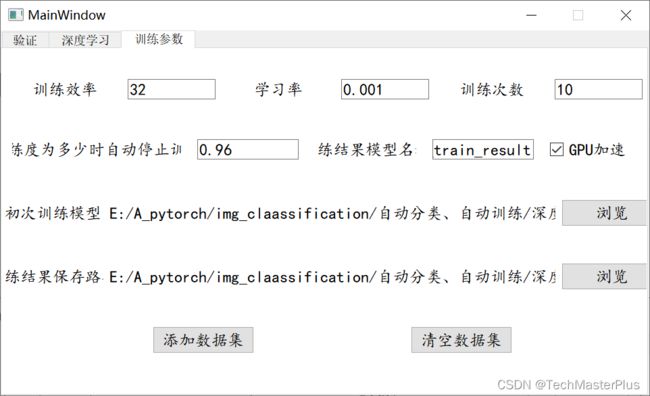
点击深度学习,界面直接点击开始训练 图示折线图结果会自动生成

点击验证,在如下界面,点击上传文件,开始识别验证模型效果

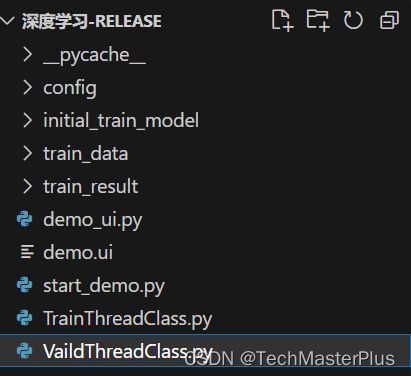
2、代码结构展示
如下是改代码工程的文件结构,此项目包含大量的多线程层编程。训练显示,训练进度条的多线程显示,包含图像分类,配置文件等工程化示例。
3、实现源码
图像分类代码模板
TrainTreadClass.py
from PyQt5 import QtCore
import os
import numpy as np
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
from torchvision import transforms
class TrainThreadClass(QtCore.QThread):
label_2_1_signal = QtCore.pyqtSignal(object,object)
label_2_2_signal = QtCore.pyqtSignal(object,object)
label_2_3_signal = QtCore.pyqtSignal(int,str)
label_2_4_signal = QtCore.pyqtSignal(int,float,float)
label_2_5_signal = QtCore.pyqtSignal(int,float,float,float)
progress_2_1_signal = QtCore.pyqtSignal(int)
pushButton_2_1_enabled_signal = QtCore.pyqtSignal()
pushButton_2_2_enabled_signal = QtCore.pyqtSignal()
tab_3_enabled_signal = QtCore.pyqtSignal()
def __init__(self,train_path,test_path,train_efficiency,
train_result_path,train_result_name,
initial_train_model,GPU_acceleration,
learning_rate,epoches,auto_stop_train_threshold):
super(TrainThreadClass,self).__init__()
self.initialize_train_parameters(
train_path,test_path,train_efficiency,
train_result_path,train_result_name,
initial_train_model,GPU_acceleration,
learning_rate)
self.epoches = epoches
self.train_result_path = train_result_path
self.auto_stop_train_threshold = auto_stop_train_threshold
self.GPU_acceleration = GPU_acceleration
self.train_result_name = train_result_name
self.is_running=True
def run(self):
x = []
train_y = []
test_y = []
for i in range(int(self.epoches)):
if self.is_running:
self.label_2_3_signal.emit(i,"训练")
if not self.GPU_acceleration:
self.model=self.model.cpu()
self.model.train()
total_loss = 0
train_corrects = 0.0
train_loss = 0.0
for k, (image, label) in enumerate (self.trainLoader):
if self.GPU_acceleration:
image = Variable(image.cuda()) # 同理
label = Variable(label.cuda()) # 同理
else:
image=image.cpu()
label=label.cpu()
self.optimizer.zero_grad ()
target = self.model(image)
loss = self.criterion(target, label)
loss.backward()
self.optimizer.step()
total_loss += loss.item()
max_value , max_index = torch.max(target, 1)
pred_label = max_index.cpu().numpy()
true_label = label.cpu().numpy()
train_corrects += np.sum(pred_label == true_label)
self.progress_2_1_signal.emit((int)(k + 1) / len(self.trainLoader) * 100)
train_loss +=total_loss / float(len(self.trainLoader))
#train_corrects += train_corrects / self.train_sum
self.train_loss = train_loss/len(self.trainLoader)
self.train_corrects = train_corrects/self.train_sum
x.append(i+1)
if len(x) > 20:
del x[0]
train_y.append(self.train_corrects)
if len(train_y) > 20 :
del train_y[0]
self.label_2_1_signal.emit(x,train_y)
self.label_2_4_signal.emit(i,self.train_loss,self.train_corrects)
# 测试开始
self.label_2_3_signal.emit(i,"测试")
self.model.eval()
corrects = 0
eval_loss = 0
with torch.no_grad():
for k,(image, label) in enumerate (self.testLoader):
if self.GPU_acceleration:
image = Variable(image.cuda()) # 同理
label = Variable(label.cuda()) # 同理
else:
image=image.cpu()
label=label.cpu()
pred = self.model(image)
loss = self.criterion(pred, label)
eval_loss += loss.item()
max_value, max_index = torch.max(pred, 1)
pred_label = max_index.cpu().numpy()
true_label = label.cpu().numpy()
corrects += np.sum(pred_label == true_label)
self.progress_2_1_signal.emit((int)(k + 1) / len(self.testLoader) * 100)
self.test_loss = eval_loss / len(self.testLoader)
self.test_correct = corrects
self.test_acc = corrects / self.test_sum
test_y.append(self.test_acc)
if len(test_y) > 20 :
del test_y[0]
self.label_2_2_signal.emit(x,test_y)
self.label_2_5_signal.emit(i,self.test_loss,self.test_correct,self.test_acc)
# 保存模型再读取模型
torch.save(self.model, self.train_result_path+"/"+self.train_result_name+".pt")
if self.auto_stop_train_threshold < self.test_acc:
self.stop()
self.model=torch.load(self.train_result_path+"/"+self.train_result_name+".pt")
self.pushButton_2_1_enabled_signal.emit()
self.pushButton_2_2_enabled_signal.emit()
self.tab_3_enabled_signal.emit()
def stop(self) :
self.is_running = False
def initialize_train_parameters(self,train_path,test_path,train_efficiency,
train_result_path,train_result_name,
initial_train_model,GPU_acceleration,
learning_rate):
#数据增强的方式
traintransform = transforms .Compose([
transforms .RandomRotation (20), #随机旋转角度
transforms .ColorJitter(brightness=0.1), #颜色亮度
transforms .Resize([224, 224]), #设置成224×224大小的张量
transforms .ToTensor(), # 将图⽚数据变为tensor格式
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225]),
])
# 将图⽚数据变为tensor格式
transform = transforms .Compose([
transforms .Resize([224, 224]),
transforms .ToTensor(),
])
# 读取训练集,标签就是train⽬录下的⽂件夹的名字,图像保存在格⼦标签下的⽂件夹⾥
trainData = dsets.ImageFolder(train_path, transform =traintransform)
# 读取测试集
testData = dsets.ImageFolder(test_path, transform =transform)
# 将数据集分批次 并打乱顺序
trainLoader = torch.utils.data.DataLoader(
dataset=trainData, batch_size=train_efficiency, shuffle=True)
# 将测试集分批次并打乱顺序
testLoader = torch.utils.data.DataLoader(
dataset=testData, batch_size=train_efficiency, shuffle=False)
#计算 训练集和测试集的图片总数
train_sum = len(trainData)
test_sum = len(testData)
#定义模型
#pretrained表⽰是否加载已经与训练好的参数
#model = models.resnet34(pretrained=True)
#将最后的fc层的输出改为标签数量(如3),512取决于原始⽹络fc层的输⼊通道
num_of_classes =len(os.listdir(train_path))
if os.path.isfile(train_result_path+"/"+train_result_name+".pt"):
model=torch.load(train_result_path+"/"+train_result_name+".pt")
else:
model=torch.load(initial_train_model)
last_layer = model.fc
# 获取最后一层的输出神经元个数
num_neurons = last_layer.out_features
if num_neurons!=num_of_classes:
model.fc = torch.nn.Linear(512, num_of_classes)
# model.fc = torch.nn.Linear(2048, self.num_of_classes)
# 如果有GPU,⽽且确认使⽤则保留;如果没有GPU,请删除
# if torch.cuda.is_available:
if GPU_acceleration:
model = model.cuda()
else:
model=model.cpu()
# 定义损失函数 交叉熵损失
criterion = torch.nn.CrossEntropyLoss()
# 定义优化器 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
self.model = model
self.trainLoader = trainLoader
self.optimizer = optimizer
self.criterion = criterion
self.train_sum = train_sum
self.testLoader = testLoader
self.test_sum = test_sum
如果这份博客对大家有帮助,希望各位给恒川一个免费的点赞作为鼓励,并评论收藏一下⭐,谢谢大家!!!
制作不易,如果大家有什么疑问或给恒川的意见,欢迎评论区留言。