PyTorch翻译官网教程-NLP FROM SCRATCH: GENERATING NAMES WITH A CHARACTER-LEVEL RNN
官网链接
NLP From Scratch: Generating Names with a Character-Level RNN — PyTorch Tutorials 2.0.1+cu117 documentation
使用字符级RNN生成名字
这是我们关于“NLP From Scratch”的三篇教程中的第二篇。在第一个教程中 我们使用RNN将名字按其原始语言进行分类。这一次,我们将通过语言中生成名字。
> python sample.py Russian RUS
Rovakov
Uantov
Shavakov
> python sample.py German GER
Gerren
Ereng
Rosher
> python sample.py Spanish SPA
Salla
Parer
Allan
> python sample.py Chinese CHI
Chan
Hang
Iun我们仍然手工制作一个带有几个线性层的小型RNN模型。最大的区别在于,我们不是在读取一个名字的所有字母后预测一个类别,而是输入一个类别并每次输出一个字母。经常预测字符以形成语言(这也可以用单词或其他高阶结构来完成)通常被称为“语言模型”。
推荐阅读:
我假设你至少安装了PyTorch,了解Python,并且理解张量:
- PyTorch 安装说明
- Deep Learning with PyTorch: A 60 Minute Blitz 来开始使用PyTorch
- Learning PyTorch with Examples pytorch使用概述
- PyTorch for Former Torch Users 如果您是前Lua Torch用户
了解rnn及其工作原理也很有用:
- The Unreasonable Effectiveness of Recurrent Neural Networks 展示了一些现实生活中的例子
- Understanding LSTM Networks 是专门关于LSTM的,但也有关于RNN的信息
我还推荐上一篇教程, NLP From Scratch: Classifying Names with a Character-Level RNN
准备数据
从这里(here)下载数据并将其解压缩到当前目录。
有关此过程的更多细节,请参阅最后一篇教程。简而言之,有一堆纯文本文件data/names/[Language].txt 每行有一个名称。我们将每行分割成一个数组,将Unicode转换为ASCII,最后得到一个字典{language: [names ...]}.
from io import open
import glob
import os
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS marker
def findFiles(path): return glob.glob(path)
# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
# Read a file and split into lines
def readLines(filename):
with open(filename, encoding='utf-8') as some_file:
return [unicodeToAscii(line.strip()) for line in some_file]
# Build the category_lines dictionary, a list of lines per category
category_lines = {}
all_categories = []
for filename in findFiles('data/names/*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
if n_categories == 0:
raise RuntimeError('Data not found. Make sure that you downloaded data '
'from https://download.pytorch.org/tutorial/data.zip and extract it to '
'the current directory.')
print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))输出
# categories: 18 ['Arabic', 'Chinese', 'Czech', 'Dutch', 'English', 'French', 'German', 'Greek', 'Irish', 'Italian', 'Japanese', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Scottish', 'Spanish', 'Vietnamese']
O'Neal创建网络
这个网络扩展了上一篇教程的RNN(the last tutorial’s RNN),为类别张量增加了一个额外的参数,它与其他参数连接在一起。category张量是一个独热向量就像输入的字母一样。
我们将把输出解释为下一个字母出现的概率。采样时,最可能的输出字母被用作下一个输入字母。
我添加了第二个线性层o2o(在将hidden和output结合起来之后),让其更有影响力。还有一个dropout层,它以给定的概率(这里是0.1)随机地将部分输入归零,通常用于模糊输入以防止过拟合。在这里,我们在网络的末尾使用它来有意地增加一些混乱和增加采样的多样性。
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, category, input, hidden):
input_combined = torch.cat((category, input, hidden), 1)
hidden = self.i2h(input_combined)
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
训练
训练准备
首先,辅助函数获得(类别,行)的随机对:
import random
# Random item from a list
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
# Get a random category and random line from that category
def randomTrainingPair():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
return category, line对于每个时间步(即对于训练词中的每个字母),网络的输入将是(category, current letter, hidden state),输出将是(next letter, next hidden state)。对于每个训练集,我们需要类别,一组输入字母,和一组输出/目标字母。
由于我们预测每个时间步当前字母的下一个字母,因此字母对是一行中连续字母的组-例如,"ABCD
category张量是一个独热张量,大小为<1 x n_categories>. 当训练时,我们在每个时间步向网络提供它,这是一个设计选择,它可以作为初始隐藏状态的一部分或其他策略。
# One-hot vector for category
def categoryTensor(category):
li = all_categories.index(category)
tensor = torch.zeros(1, n_categories)
tensor[0][li] = 1
return tensor
# One-hot matrix of first to last letters (not including EOS) for input
def inputTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li in range(len(line)):
letter = line[li]
tensor[li][0][all_letters.find(letter)] = 1
return tensor
# ``LongTensor`` of second letter to end (EOS) for target
def targetTensor(line):
letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))]
letter_indexes.append(n_letters - 1) # EOS
return torch.LongTensor(letter_indexes)为了在训练过程中方便起见,我们将创建一个randomTrainingExample函数来获取一个随机的(category, line)对。并将它们转换为所需的(category, input, target)张量。
# Make category, input, and target tensors from a random category, line pair
def randomTrainingExample():
category, line = randomTrainingPair()
category_tensor = categoryTensor(category)
input_line_tensor = inputTensor(line)
target_line_tensor = targetTensor(line)
return category_tensor, input_line_tensor, target_line_tensor训练网络
与只使用最后一个输出的分类相反,我们在每一步都进行预测,因此我们在每一步都计算损失。
自动梯度的魔力让你可以简单地将每一步的损失加起来,并在最后进行反向调用。
criterion = nn.NLLLoss()
learning_rate = 0.0005
def train(category_tensor, input_line_tensor, target_line_tensor):
target_line_tensor.unsqueeze_(-1)
hidden = rnn.initHidden()
rnn.zero_grad()
loss = torch.Tensor([0]) # you can also just simply use ``loss = 0``
for i in range(input_line_tensor.size(0)):
output, hidden = rnn(category_tensor, input_line_tensor[i], hidden)
l = criterion(output, target_line_tensor[i])
loss += l
loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item() / input_line_tensor.size(0)为了跟踪训练需要多长时间,我添加了一个timeSince(timestamp)函数,它返回一个人类可读的字符串:
import time
import math
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)训练和往常一样——调用train多次并等待几分钟,在每个print_every示例中打印当前时间和损失,并在all_losses中保存每个plot_every示例的平均损失,以便稍后绘制。
rnn = RNN(n_letters, 128, n_letters)
n_iters = 100000
print_every = 5000
plot_every = 500
all_losses = []
total_loss = 0 # Reset every ``plot_every`` ``iters``
start = time.time()
for iter in range(1, n_iters + 1):
output, loss = train(*randomTrainingExample())
total_loss += loss
if iter % print_every == 0:
print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss))
if iter % plot_every == 0:
all_losses.append(total_loss / plot_every)
total_loss = 0输出
0m 37s (5000 5%) 3.1506
1m 15s (10000 10%) 2.5070
1m 55s (15000 15%) 3.3047
2m 33s (20000 20%) 2.4247
3m 12s (25000 25%) 2.6406
3m 50s (30000 30%) 2.0266
4m 29s (35000 35%) 2.6520
5m 6s (40000 40%) 2.4261
5m 45s (45000 45%) 2.2302
6m 24s (50000 50%) 1.6496
7m 2s (55000 55%) 2.7101
7m 41s (60000 60%) 2.5396
8m 19s (65000 65%) 2.5978
8m 57s (70000 70%) 1.6029
9m 35s (75000 75%) 0.9634
10m 13s (80000 80%) 3.0950
10m 52s (85000 85%) 2.0512
11m 30s (90000 90%) 2.5302
12m 8s (95000 95%) 3.2365
12m 47s (100000 100%) 1.7113绘制损失
绘制all_losses的历史损失图显示了网络的学习情况:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(all_losses)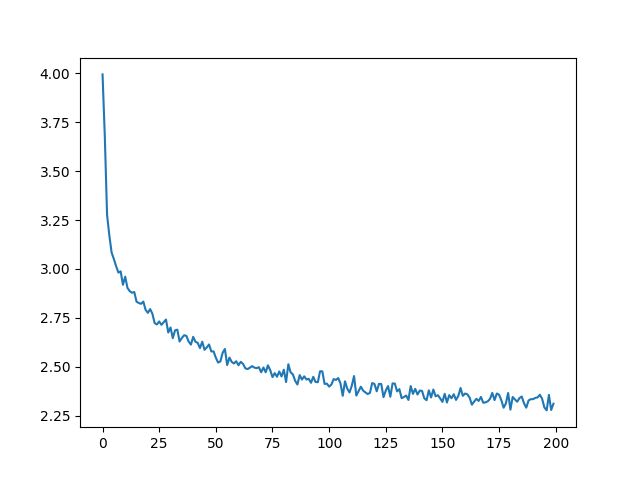
输出
[] 网络采样
为了进行示例,我们给网络一个字母并询问下一个字母是什么,将其作为下一个字母输入,并重复直到EOS令牌。
- 为输入类别、起始字母和空隐藏状态创建张量
- 创建一个以字母开头的字符串output_name
- 最大输出长度
-
- 将当前的字母提供给网络
- 从最高输出中获取下一个字母,以及下一个隐藏状态
- 如果字母是EOS,就停在这里
- 如果是普通字母,添加到output_name并继续
- 返回最终名称
与其给它一个起始字母,另一种策略是在训练中包含一个“字符串起始”标记,并让网络选择自己的起始字母。
max_length = 20
# Sample from a category and starting letter
def sample(category, start_letter='A'):
with torch.no_grad(): # no need to track history in sampling
category_tensor = categoryTensor(category)
input = inputTensor(start_letter)
hidden = rnn.initHidden()
output_name = start_letter
for i in range(max_length):
output, hidden = rnn(category_tensor, input[0], hidden)
topv, topi = output.topk(1)
topi = topi[0][0]
if topi == n_letters - 1:
break
else:
letter = all_letters[topi]
output_name += letter
input = inputTensor(letter)
return output_name
# Get multiple samples from one category and multiple starting letters
def samples(category, start_letters='ABC'):
for start_letter in start_letters:
print(sample(category, start_letter))
samples('Russian', 'RUS')
samples('German', 'GER')
samples('Spanish', 'SPA')
samples('Chinese', 'CHI')输出
Rovaki
Uarinovev
Shinan
Gerter
Eeren
Roune
Santera
Paneraz
Allan
Chin
Han
Ion练习
- 尝试使用不同数据集category -> line,例如,
-
- Fictional series -> Character name
- Part of speech -> Word
- Country -> City
- 使用“start of sentence”标记,这样就可以在不选择起始字母的情况下进行抽样
- 拥有一个更大的和/或更好的网络,可以获得更好的结果
-
- 尝试使用 nn.LSTM 和 nn.GRU 网络层
- 将这些RNN组合成一个更高级的网络