ElasticSearch SQL转DSL
前文
Elasticsearch在6.3之后内置SQL查询的功能,猜想本质上应该是将SQL语句转化为原生的DSL语句,再使用原生进行查询,可以让不熟悉ES的用户能通过SQL语句快速查询结果,降低使用门槛减少学习成本。另外,ES也提供Java客户端以JDBC的方式连接查询,但该方式是收费的。所以,如果用户不想购买服务建议使用官方提供的免费的restful的方式去查询,例如Java REST Client。当不熟悉ES原生的DSL语句的时候,可以先使用SQL编写查询语句,然后再使用ES自带的请求将SQL语句翻译成DSL语句,最后使用Java Low Level REST Client或者Java High Level REST Client的方式查询数据。
Sql语句转成DSL有哪些方法
官方参考SQL Translate API
在_sql后面添加/translate
POST /_sql/translate
{
"query": "select * from \"test_0919\""
}在线sql转DSL
但是这种工具只能是作为辅助,不能完全靠它
- 傻瓜式的生成不一定是最优的
- sql有局限性,比如没有高亮、嵌套查询等等。
我们可以生成,再自己优化成最终的json
NLP团体开发的Elasticsearch-sql;
下载地址:https://github.com/NLPchina/elasticsearch-sql
版本要与es版本对应

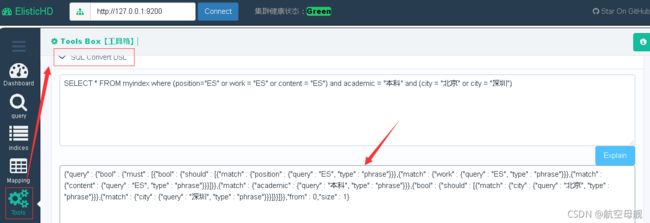
ElasticHQ的自动转换模块
下载地址:https://github.com/ElasticHQ/elasticsearch-HQ
ElasticHQ 是一个基于浏览器的直观和功能强大的 ElasticSearch 管理和监控工具,它提供了对 ElasticSearch 的实时监控、全集群管理、搜索和查询等功能。
ES SQL局限性
因为ES SQL和ES DSL在功能上并非完全匹配,官方文档提到的SQL局限性有:
大的查询可能抛ParsingException
在解析阶段,极大的查询会占用过多的内存,在这种情况下,Elasticsearch SQL引擎将中止解析并抛出错误。
nested类型字段的表示方法
SQL中不支持nested类型的字段,只能使用
[nested_field_name].[sub_field_name]这种形式来引用内嵌子字段。使用举例:
SELECT dep.dep_name.keyword FROM test_emp GROUP BY languages;nested类型字段不能用在where 和 order by 的Scalar函数上
如以下SQL都是错误的
SELECT * FROM test_emp WHERE LENGTH(dep.dep_name.keyword) > 5;
SELECT * FROM test_emp ORDER BY YEAR(dep.start_date);不支持多个nested字段的同时查询
如嵌套字段nested_A和nested_B无法同时使用。
nested内层字段分页限制
当分页查询有nested字段时,分页结果可能不正确。这是因为:ES中的分页查询发生在Root nested document上,而不是它的内层字段上。
keyword类型的字段不支持normalizer
不支持数组类型的字段
这是因为在SQL中一个field只对应一个值,这种情况下我们可以使用上面介绍的 SQL To DSL的API 转化为DSL语句,用DSL查询就好了。
聚合排序的限制
-
排序字段必须是聚合桶中的字段,ES SQL CLI突破了这种限制,但上限不能超过512行,否则在sorting阶段会抛异常。推荐搭配
Limit子句使用,如:SELECT * FROM test GROUP BY age ORDER BY COUNT(*) LIMIT 100; - 聚合排序的排序条件不支持Scalar函数或者简单的操作符运算。聚合后的复杂字段(比如包含聚合函数)也是不能用在排序条件上的。以下是错误例子:
SELECT age, ROUND(AVG(salary)) AS avg FROM test GROUP BY age ORDER BY avg;
SELECT age, MAX(salary) - MIN(salary) AS diff FROM test GROUP BY age ORDER BY diff;子查询的限制
子查询中包含GROUP BY or HAVING 或者比SELECT X FROM (SELECT ...) WHERE [simple_condition]这种结构复杂,都是可能执行不成功的。
TIME 数据类型的字段不支持GROUP BY条件和HISTOGRAM函数
如以下查询是错误的:
SELECT count(*) FROM test GROUP BY CAST(date_created AS TIME);
SELECT HISTOGRAM(CAST(birth_date AS TIME), INTERVAL '10' MINUTES) as h, COUNT(*) FROM t GROUP BY h但是将TIME类型的字段包装为Scalar函数返回是支持GROUP BY的,如
SELECT count(*) FROM test GROUP BY MINUTE((CAST(date_created AS TIME));返回字段的限制
如果一个字段不在source中存储,是无法查询到的。keyword, date, scaled_float, geo_point, geo_shape这些类型的字段不受这种限制,因为他们不是从_source中返回,而是从docvalue_fields中返回。