【Megatron-DeepSpeed】张量并行工具代码mpu详解(四):张量并行版Embedding层及交叉熵的实现及测试
相关博客
【Megatron-DeepSpeed】张量并行工具代码mpu详解(四):张量并行版Embedding层及交叉熵的实现及测试
【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试
【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化
【Megatron-DeepSpeed】张量并行工具代码mpu详解(二):Collective通信操作的封装mappings
【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
【深度学习】混合精度训练与显存分析
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
Megatron-DeepSpeed是DeepSpeed版本的NVIDIA Megatron-LM。像BLOOM、GLM-130B等主流大模型都是基于Megatron-DeepSpeed开发的。这里以BLOOM版本的Megetron-DeepSpeed为例,介绍其模型并行代码mpu的细节(位于megatron/mpu下)。
理解该部分的代码需要对模型并行的原理以及集合通信有一定的理解,可以看文章:
- 【深度学习】【分布式训练】Collective通信操作及Pytorch示例
- 【深度学习】【分布式训练】一文捋顺千亿模型训练技术:流水线并行、张量并行和3D并行
- 【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
强烈建议阅读,不然会影响本文的理解:
- 【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化
- 【Megatron-DeepSpeed】张量并行工具代码mpu详解(二):Collective通信操作的封装mappings
- 【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试
阅读建议:
- 本文仅会解析核心代码,并会不介绍所有代码;
- 本文会提供一些测试脚本来展现各部分代码的功能;
- 建议实际动手实操来加深理解;
- 建议对Collective通信以及分布式模型训练有一定理解,再阅读本文;
一、总览
mpu目录下核心文件有:
- initialize.py:负责数据并行组、张量并行组和流水线并行组的初始化,以及获取与各类并行组相关的信息;
- data.py:实现张量并行中的数据广播功能;
- cross_entropy.py:张量并行版本的交叉熵;
- layers.py:并行版本的Embedding层,以及列并行线性层和行并行线性层;
- mappings.py:用于张量并行的通信操作;
二、张量并行版Embedding层
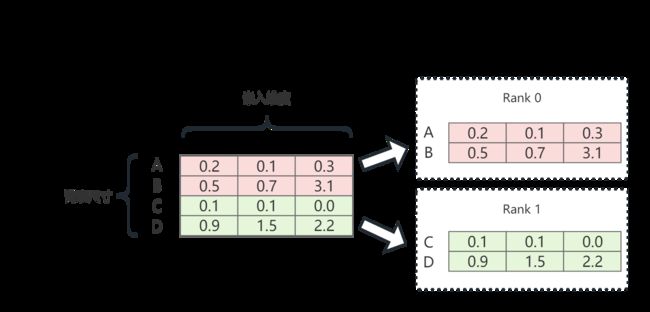
Embedding层本质就是一个查找表。如上图所示,张量并行版embedding层就是将完整的embedding层,在vocab的维度切分。张量并行组中的每个进程仅持有部分embedding层。
1. 实现代码
这里直接在原始的文件(megatron/mpu/layers.py)中,添加一个自定义的并行版Embedding层。其与原始版完全相同,仅添加了一些输出来展示整个过程。
# layers.py
class MyVocabParallelEmbedding(torch.nn.Module):
def __init__(self, num_embeddings, embedding_dim,
init_method=init.xavier_normal_):
super(MyVocabParallelEmbedding, self).__init__()
# 初始化一些参数
self.num_embeddings = num_embeddings # 词表大小
self.embedding_dim = embedding_dim
self.padding_idx = None
self.max_norm = None
self.norm_type = 2.
self.scale_grad_by_freq = False
self.sparse = False
self._weight = None
self.tensor_model_parallel_size = get_tensor_model_parallel_world_size()
# 张量并行组中的每个rank仅持有部分vocab embedding
# 这里会计算当前rank持有的vocab的起始和结束位置
self.vocab_start_index, self.vocab_end_index = \
VocabUtility.vocab_range_from_global_vocab_size(
self.num_embeddings, get_tensor_model_parallel_rank(),
self.tensor_model_parallel_size)
# 当前rank持有的部分vocab的大小
self.num_embeddings_per_partition = self.vocab_end_index - \
self.vocab_start_index
args = get_args()
# embedding层添加LayerNorm
if mpu.is_pipeline_first_stage() and (args.use_bnb_optimizer or args.embed_layernorm):
self.norm = LayerNorm(embedding_dim)
# bnb是指bitsandbytes,该库针对8-bit做了一些cuda函数的封装,这里忽略
if args.use_bnb_optimizer:
# for BNB we ignore the passed init_method and use torch.nn.init.xavier_uniform_
# modified to calculate std on the unpartitioned embedding
init_method = partial(xavier_uniform_tensor_parallel_, tp_degree=self.tensor_model_parallel_size)
# 初始化embedding层的权重
# 每个rank仅初始化自己所持有的那部分
if args.use_cpu_initialization:
self.weight = Parameter(torch.empty(
self.num_embeddings_per_partition, self.embedding_dim,
dtype=args.params_dtype))
_initialize_affine_weight_cpu(
self.weight, self.num_embeddings, self.embedding_dim,
self.num_embeddings_per_partition, 0, init_method)
else:
self.weight = Parameter(torch.empty(
self.num_embeddings_per_partition, self.embedding_dim,
device=torch.cuda.current_device(), dtype=args.params_dtype))
_initialize_affine_weight_gpu(self.weight, init_method,
partition_dim=0, stride=1)
# bnb(忽略)
if args.use_bnb_optimizer:
from bitsandbytes.optim import GlobalOptimManager
GlobalOptimManager.get_instance().override_config(self.weight, 'optim_bits', 32)
GlobalOptimManager.get_instance().register_parameters(self.weight)
def forward(self, input_):
if torch.any(input_ >= self.num_embeddings):
raise ValueError(f"There is an input id in the input that is greater than the highest possible input id.\nInput: {input_}\nnum_embeddings: {self.num_embeddings}")
# 全局rank
global_rank = torch.distributed.get_rank()
# 张量并行组中的rank
tp_rank = get_tensor_model_parallel_rank()
info = f"*"*20 + \
f"\n> global_rank={global_rank}\n" + \
f"> tensor parallel rank={tp_rank}\n" + \
f"> full embedding size={(self.num_embeddings, self.embedding_dim)}\n" + \
f"> partial embedding size={list(self.weight.size())}\n" \
f"> input = {input_}\n" \
f"> vocab_start_index={self.vocab_start_index}, vocab_end_index={self.vocab_end_index}\n"
if self.tensor_model_parallel_size > 1:
# Build the mask.
input_mask = (input_ < self.vocab_start_index) | \
(input_ >= self.vocab_end_index)
# Mask the input.
masked_input = input_.clone() - self.vocab_start_index
masked_input[input_mask] = 0
else:
# input_ is garanted to be in the range [0:self.vocab_end_index - self.vocab_start_index] thanks to the first check
masked_input = input_
info += f"> input_mask={input_mask} \n"
info += f"> masked_input={masked_input} \n"
# 获得embedding
output_parallel = F.embedding(masked_input, self.weight,
self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq,
self.sparse)
# 由于在当前rank上,仅能获得部分输入的embedding
# 因此,将mask掉的input对应的embedding设置为全0
if self.tensor_model_parallel_size > 1:
output_parallel[input_mask, :] = 0.0
info += f"> output_parallel={output_parallel}\n"
# 上一步设置为全0的embedding会在这一步通过allreduce,组装成完整的embedding
output = reduce_from_tensor_model_parallel_region(output_parallel)
info += f"> output={output}\n"
if hasattr(self, 'norm'):
output = self.norm(output)
print(info, end="")
return output
2. 测试脚本
实验设置为:张量并行度为2,流水线并行度也为2。测试脚本比较简单,直接调用上面实现的MyVocabParallelEmbedding。
# test_embedding.py
import sys
sys.path.append("..")
from megatron.mpu import layers
from commons import set_random_seed
from commons import print_separator
from megatron.initialize import _initialize_distributed
from megatron.global_vars import set_global_variables
import megatron.mpu as mpu
from torch.nn.parameter import Parameter
import torch.nn.init as init
import torch
import random
def test_parallel_embedding():
batch_size = 2
seq_length = 4
vocab_size = 6
hidden_size = 8
seed = 123
set_random_seed(seed)
# (2,4)
input_data = torch.LongTensor(
size=(batch_size, seq_length)).random_(0, vocab_size).cuda()
embedding_vocab_parallel = layers.MyVocabParallelEmbedding(
vocab_size, hidden_size, init_method=init.normal_).cuda()
output = embedding_vocab_parallel(input_data)
def main():
set_global_variables(ignore_unknown_args=True)
_initialize_distributed()
world_size = torch.distributed.get_world_size()
print_separator('Test test_parallel_embedding')
test_parallel_embedding()
if __name__ == '__main__':
main()
启动命令:
options=" \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 2 \
--num-layers 10 \
--hidden-size 768 \
--micro-batch-size 2 \
--num-attention-heads 32 \
--seq-length 512 \
--max-position-embeddings 512\
--use_cpu_initialization True
"
cmd="deepspeed test_embedding.py $@ ${options}"
eval ${cmd}
3. 测试结果

- 全局rank为2,在张量并行组中的rank为0;
- 完整的embedding层大小应为(6, 8),当前设备持有的embedding层大小为(3, 8),符合张量并行度为2的假设;
- 当前设备持有的词表id范围介于0到3,输入中超出该词表范围都会被mask;
- 当前设备的输出(output_parallel),会有部分embedding为全0,而完整的输出(output)则将张量并行组中所有的embedding输出都聚合在一起;
三、张量并行版交叉熵
我们以自然语言模型为例,展示交叉熵的计算原理。
若模型针对单个token预测的logit表示为 l ⃗ = [ l 1 , … , l k ] \vec{l}=[l_1,\dots,l_k] l=[l1,…,lk],经过softmax转换后的概率分布为 p ⃗ = [ p 1 , … , p k ] \vec{p}=[p_1,\dots,p_k] p=[p1,…,pk],其中:
p i = e l i ∑ j k e l j p_i=\frac{e^{l_i}}{\sum_{j}^k e^{l_j}} pi=∑jkeljeli
该token的真实标签表示为 y ⃗ = [ y 1 , … , y k ] \vec{y}=[y_1,\dots,y_k] y=[y1,…,yk],由于其是one-hot编码,所以 y ⃗ \vec{y} y中仅有一个值为1,其余均为0。那么该token上的交叉熵损失函数为
loss = − ∑ i = 1 k y i log ( p i ) = − ∑ i = 1 k y i log ( e l i ∑ j k e l j ) = ∑ i = 1 k y i [ log ( ∑ j k e l j ) − log ( e l i ) ] = log ( ∑ j k e l j ) − ∑ i = 1 k y i log ( e l i ) = log ( ∑ j k e l j ) − ∑ i = 1 k y i l i \begin{align} \text{loss}&=-\sum_{i=1}^k y_i\log(p_i) \\ &=-\sum_{i=1}^k y_i\log(\frac{e^{l_i}}{\sum_{j}^k e^{l_j}}) \\ &=\sum_{i=1}^k y_i[\log(\sum_{j}^k e^{l_j})-\log(e^{l_i})] \\ &=\log(\sum_{j}^k e^{l_j})-\sum_{i=1}^k y_i \log(e^{l_i}) \\ &=\log(\sum_{j}^k e^{l_j})-\sum_{i=1}^k y_i {l_i} \end{align} loss=−i=1∑kyilog(pi)=−i=1∑kyilog(∑jkeljeli)=i=1∑kyi[log(j∑kelj)−log(eli)]=log(j∑kelj)−i=1∑kyilog(eli)=log(j∑kelj)−i=1∑kyili
由于模型输出的 l ⃗ \vec{l} l是已知的,那么上式第一项 log ( ∑ j k e l j ) \log(\sum_{j}^k e^{l_j}) log(∑jkelj)是一个固定的常数;由于所有的 y i y_i yi中仅有一个是1,那么第二项 ∑ i = 1 k y i l i \sum_{i=1}^k y_i {l_i} ∑i=1kyili本质上就是正确token对应的logit值。
mpu代码中的交叉熵实现基本上遵循上面的分析,仅是添加了batch size和seq_length维度,但核心思想不变。
1. 实现代码
同样,也是在原始文件(megatron/mpu/cross_entropy.py)中,添加一个自定义的并行版交叉熵。该实现与原版完全相同,仅添加了一些输出来展示整个过程。
# cross_entropy.py
class _MyVocabParallelCrossEntropy(torch.autograd.Function):
@staticmethod
def forward(ctx, vocab_parallel_logits, target):
# vocab_parallel_logits: (batch_size, seq_length, vocab_size)
# target: (batch_size, seq_length)
global_rank = torch.distributed.get_rank()
tp_rank = get_tensor_model_parallel_rank()
# 在vocab维度取最大值,也就是每个token对于logits的最大值
logits_max = torch.max(vocab_parallel_logits, dim=-1)[0]
torch.distributed.all_reduce(logits_max,
op=torch.distributed.ReduceOp.MAX,
group=get_tensor_model_parallel_group())
vocab_parallel_logits.sub_(logits_max.unsqueeze(dim=-1))
info = f"*"*20 + \
f"\n> global_rank={global_rank}\n" + \
f"> tp_rank={tp_rank}\n" + \
f"> size of vocab_parallel_logits={list(vocab_parallel_logits.size())}\n" + \
f"> size of target={list(target.size())}\n"
# 依据当前进程持有的部分词表大小partition_vocab_size,以及张量并行组中rank和world size,
# 确定出当前进程持有词表的起始索引vocab_start_index和结束索引vocab_end_index
get_vocab_range = VocabUtility.vocab_range_from_per_partition_vocab_size
partition_vocab_size = vocab_parallel_logits.size()[-1]
rank = get_tensor_model_parallel_rank()
world_size = get_tensor_model_parallel_world_size()
vocab_start_index, vocab_end_index = get_vocab_range(
partition_vocab_size, rank, world_size)
# 将不在词表中的target遮蔽掉
target_mask = (target < vocab_start_index) | (target >= vocab_end_index)
masked_target = target.clone() - vocab_start_index
masked_target[target_mask] = 0
# ligits_2d: (batch_size*seq_length, vocab_size)
logits_2d = vocab_parallel_logits.view(-1, partition_vocab_size)
# masked_target_1d: (batch_size*seq_length)
masked_target_1d = masked_target.view(-1)
arange_1d = torch.arange(start=0, end=logits_2d.size()[0],
device=logits_2d.device)
# predicted_logits_1d 表示正确token对应的logit
predicted_logits_1d = logits_2d[arange_1d, masked_target_1d]
predicted_logits_1d = predicted_logits_1d.clone().contiguous()
predicted_logits = predicted_logits_1d.view_as(target)
# 将当前进程无法获得的logits设置为0,用于后续allreduce组成完成logits
predicted_logits[target_mask] = 0.0
info += f"> size of logits_2d={list(logits_2d.size())}\n" + \
f"> size of masked_target_1d={list(masked_target_1d.size())}\n" + \
f"> size of predicted_logits={list(predicted_logits_1d.size())}\n"
# 各个进程持有的predicted_logits的大小是完全相同的
# 但是,当前进程持有的predicted_logits仅在当前词表上才有取值,其余值为0
# 通过allreduce即可得到完整的predicted_logits
torch.distributed.all_reduce(predicted_logits,
op=torch.distributed.ReduceOp.SUM,
group=get_tensor_model_parallel_group())
# 求softmax分母的部分
exp_logits = vocab_parallel_logits
torch.exp(vocab_parallel_logits, out=exp_logits)
sum_exp_logits = exp_logits.sum(dim=-1)
torch.distributed.all_reduce(sum_exp_logits,
op=torch.distributed.ReduceOp.SUM,
group=get_tensor_model_parallel_group())
# 对应上面公式推导的最终结果
# loss: (batch_size, seq_length)。
# loss是一个矩阵,矩阵的值对应单个token的交叉熵
loss = torch.log(sum_exp_logits) - predicted_logits
info += f"> size of sum_exp_logits={list(sum_exp_logits.size())}\n" + \
f"> size of loss={list(loss.size())}\n"
print(info, end="")
exp_logits.div_(sum_exp_logits.unsqueeze(dim=-1))
ctx.save_for_backward(exp_logits, target_mask, masked_target_1d)
return loss
@staticmethod
def backward(ctx, grad_output):
# Retreive tensors from the forward path.
softmax, target_mask, masked_target_1d = ctx.saved_tensors
# All the inputs have softmax as thier gradient.
grad_input = softmax
# For simplicity, work with the 2D gradient.
partition_vocab_size = softmax.size()[-1]
grad_2d = grad_input.view(-1, partition_vocab_size)
# Add the gradient from matching classes.
arange_1d = torch.arange(start=0, end=grad_2d.size()[0],
device=grad_2d.device)
grad_2d[arange_1d, masked_target_1d] -= (
1.0 - target_mask.view(-1).float())
# Finally elementwise multiplication with the output gradients.
grad_input.mul_(grad_output.unsqueeze(dim=-1))
return grad_input, None
2. 测试脚本
# test_cross_entropy.py
import sys
sys.path.append("..")
from commons import set_random_seed
from commons import IdentityLayer
from commons import print_separator
from commons import initialize_distributed
from megatron.mpu.cross_entropy import _MyVocabParallelCrossEntropy
import megatron.mpu as mpu
import torch.nn.functional as F
import torch
import random
def test_cross_entropy():
tensor_model_parallel_size = mpu.get_tensor_model_parallel_world_size()
batch_size = 32
seq_length = 128
vocab_size_per_partition = 500
logits_scale = 1000.0
vocab_size = vocab_size_per_partition * tensor_model_parallel_size
seed = 1234
set_random_seed(seed)
identity = IdentityLayer((batch_size, seq_length, vocab_size),
scale=logits_scale).cuda()
logits = identity()
logits_parallel = mpu.scatter_to_tensor_model_parallel_region(logits)
target = torch.cuda.LongTensor(
size=(batch_size, seq_length)).random_(0, vocab_size)
loss = _MyVocabParallelCrossEntropy.apply(logits_parallel, target).mean()
if __name__ == '__main__':
initialize_distributed()
world_size = torch.distributed.get_world_size()
tensor_model_parallel_size = 2
pipeline_model_parallel_size = 2
mpu.initialize_model_parallel(
tensor_model_parallel_size,
pipeline_model_parallel_size)
test_cross_entropy()
启动命名:
deepspeed test_cross_entropy.py
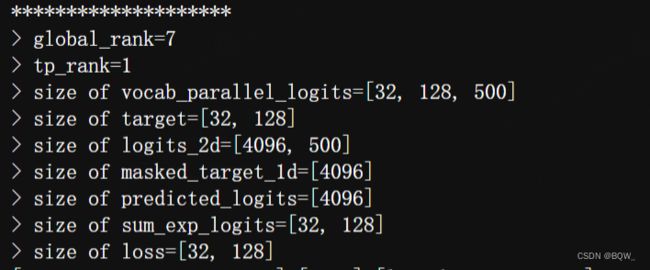
3. 测试结果