Linux-C++开发项目:基于主从Reactor模式的高性能并发服务器
目录
- 1.项目介绍
-
- 2.1项目部署
- 2.2安装版本较高的编译器
- 2.项目开发过程
-
- 2.1网络库模块开发
-
- 2.1.1简单日志宏的实现
- 2.1.2Buffer模块实现
- 2.1.3Socket模块实现
- 2.1.4Channel模块实现
- 2.1.5Poller模块实现
- 2.1.6TimerWheel模块实现
- 2.1.7EventLoop模块实现
- 2.1.8整合测试1
- 2.1.9LoopThread模块实现
- 2.1.10LoopThreadPool模块实现
- 2.1.11主从Reactor模式
- 2.1.12整合测试2
- 2.1.13Any类实现
- 2.1.14Connection模块实现
- 2.1.15Acceptor模块
- 2.1.16TcpServer模块
- 2.1.17细节补充
- 2.1.18整合测试3
- 2.2HTTP协议模块开发
-
- 2.2.1响应状态码和状态描述、文件后缀和mime的实现
- 2.2.2Util工具类的实现
- 2.2.3HttpRequest模块
- 2.2.4HttpResponse模块
- 2.2.5HttpContext模块
- 2.2.6HttpServer模块
- 2.2.7搭建简易的测试服务器
- 2.2.8整合测试4
- 2.2.9整合测试5
- 2.2.10整合测试6
- 2.2.11整合测试7
- 2.2.12整合测试8
- 2.2.13整合测试9
- 2.2.14整合测试10
- 3.项目总结
1.项目介绍
本项目实现一个基于从属Reactor模式的高性能并发服务器,该服务器能够支持任意应用层协议并且能够随意切换(支持HTTP协议后可以快速搭建一个Web服务器)。并且该服务器可以单独作为一个网络库组件,组件使用者可以利用该网络库组件方便地实现各种各样的服务器。
服务器使用到epoll多路转接模型,并且工作在ET模式下。
2.1项目部署
本项目部署在2核4G带宽为1M的云服务器中,云服务器的操作系统为Centos7.6。本项目不依赖任何第三方库(都使用C++的标准库),所以只要在Linux环境下一般都可以跑通。但是本项目涉及到使用C++11的正则库,所以Centos7.6默认提供的gcc版本较低,所以需要更换软件源并安装一个版本较新的编译器。
2.2安装版本较高的编译器
1.备份Centos的软件源配置文件:
sudo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
2.更换软件源:
sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3.清除yum缓存:
sudo yum clean all
4.创建yun缓存:
sudo yum makecache
5.安装scl软件源:
sudo yum install centos-release-scl-rh centos-release-scl
6.安装版本更高的编译器:
sudo yum install devtoolset-7-all
这里只是做一个演示(虽然我确实是那么做的),在实际的开发过程当中还可以选择更高版本的编译器。
7.配置终端自动执行:
echo "source /opt/rh/devtoolset-7/enable" >> ~/.bashrc
配置文件是跟随终端的,所以将执行配置文件的命令写入"~./bashrc"中,这样就可以在每次打开终端的时候自动执行配置文件。
8.执行配置文件:
source ~/.bashrc
9.确认是否安装成功:
gcc -v
输出结果如图所示:

2.项目开发过程
因为本篇文章的目标是从0到1介绍项目的开发过程,因此本篇文章的叙述过程会站在开发者的角度,所以在某些地方显得略微啰嗦。
回到正题。
该项目涉及到两个大模块,一个是网络库组件模块,一个是应用层协议模块。那么应用层协议模块必须搭建在网络库组件之上,所以这里先只考虑网络库的开发实现。
本项目实现的网络库是超级轻量的,所以它的所有实现放在一个名为Server.hpp的头文件当中。
2.1网络库模块开发
2.1.1简单日志宏的实现
无论是哪个项目都需要日志,它可以在开发过程当中更加方便开发者进行调试和纠错、在项目运行期间可以方便维护。
本项目的日志模块不需要实现的过于复杂,只要能体现出必要信息即可。
下面给出日志宏的实现:
#define NORMAL 0 // 正常
#define DEBUG 1 // 调试
#define ERROR 2 // 错误
#define LOG_LEVEL DEBUG// 控制输出
#define LOG(level,format,...) do{\
if(level < LOG_LEVEL) break;\
time_t t = time(nullptr);\
struct tm *ltm = localtime(&t);\
char tmp[32] = {0};\
strftime(tmp,sizeof(tmp) - 1,"%H:%M:%S",ltm);\
fprintf(stdout,"[thread:%p]--[%s]--[file:%s|line:%d]=> " format "\n",(void *)pthread_self(),tmp,__FILE__,__LINE__,##__VA_ARGS__);\
}while(0)
#define NORMAL_LOG(format,...) LOG(NORMAL,format,##__VA_ARGS__)
#define DEBUG_LOG(format,...) LOG(DEBUG,format,##__VA_ARGS__)
#define ERROR_LOG(format,...) LOG(ERROR,format,##__VA_ARGS__)
该日志宏使用fprintf,可以将日志输出到文件上。该日志的输出格式为:
[线程地址]–[时:分:秒]–[file:发生日志输出的文件名|line:发生日志输出的行号]=> 输出内容
if(level < LOG_LEVEL) break;\
这段代码的作用在于控制日志的输出,即不符合等级的日志输出统统不输出。
2.1.2Buffer模块实现
TCP通信的数据都会被放在套接字的缓冲区当中,但是套接字的缓冲区是有大小限制的,尽管开发者可以控制这些缓冲区的大小,但是这样做很没必要。
可以直接在应用层再提供一层缓冲区,这里把它叫做Buffer。Buffer的作用就是一个处于应用层的缓冲区,它的容量可变,为组件使用者提供一个方便、灵活的缓冲区。
总的来说,Buffer具有以下这么几个特点:
1.Buffer的容量可变,Buffer容量的上限取决于当前内存还剩多少可用空间
2.Buffer具有暂存数据的能力(相对组件使用者来说),使用者从Buffer读取数据后,被读取的数据可以不被立即清除
3.可以按特定要求将数据交给组件使用者,例如组件使用者通常需要读取一行数据(即以’\n’结尾的一行数据),那么组件使用者只需要调用一个Buffer提供的接口就可以实现,组件使用者不需要再做多余的操作
4.Buffer可以适配各种不同类型数据,例如可以是string、vector、char*等等类型的数据向Buffer类写入,相反的,Buffer也可以向string、vector等等之类的写入数据
Buffer类的具体代码实现:
#define BUFFER_DEFAULT_SIZE 1024
class Buffer
{
public:
Buffer()
:_reader(0),_writer(0),_buffer(BUFFER_DEFAULT_SIZE)
{}
char *Begin() {return &(*(_buffer.begin()));}// 获取缓冲区的起始地址
char *WritePosition() {return Begin() + _writer;}// 获取有效数据的结束位置,也就是新数据想要写入的起始位置
char *ReadPosition() {return Begin() + _reader;}// 获取有效数据的起始位置,也就是要读取的数据的起始位置
uint64_t TailFreeSize() {return _buffer.size() - _writer;}// 获取_writer之后的空闲空间大小
uint64_t HeadFreeSize() {return _reader;}// 获取_reader之前的空间空间大小
uint64_t ReadAbleSize() {return _writer - _reader;}// 获取可读数据大小
void OffsetReader(uint64_t len)// _reader向后移动,说明有数据被读走
{
if(len == 0) return;
if(len > ReadAbleSize()) abort();// 最多和_writer处于同一位置,说明Buffer为空,超过_writer就是未定义的行为
_reader += len;
}
void OffsetWriter(uint64_t len)// _writer向后移动,说明有新数据写入
{
if(len == 0) return;
if(len > TailFreeSize()) abort();// 最多移动到当前_buffer的最大容量处,一旦超出就可能造成越界访问
_writer += len;
}
void EnsureWriteSpace(uint64_t len)// 确保空间大小足够容纳新数据
{
if(TailFreeSize() >= len) return;// _writer尾部有足够的空间容纳新数据
if(TailFreeSize() + HeadFreeSize() >= len)// _reader之前、_writer之后的空间足够容纳新数据
{
uint64_t oldsize = ReadAbleSize();// 保存当前有效数据大小
std::copy(ReadPosition(),ReadPosition() + oldsize,Begin());// 将数据往前挪动
_reader = 0;_writer = oldsize;
}
else // 当前Buffer没有足够的空间容纳新数据
{
DEBUG_LOG("Buffer Resize: %ld",_writer + len);
_buffer.resize(_writer + len);// 扩容
}
}
void Write(const void *data,uint64_t len)// 向Buffer写入数据
{
if(len == 0) return;
EnsureWriteSpace(len);
const char *d = (const char *)data;
std::copy(d,d + len,WritePosition());// 将[d,d+len]这段区间的数据拷贝到_writer指向的位置之后
}
void WriteAndPush(const void *data,uint64_t len)// 向Buffer写入并且造成_wirter偏移
{
Write(data,len);
OffsetWriter(len);
}
void WriteString(const std::string &data)// 向Buffer写入string对象
{
Write(data.c_str(),data.size());
}
void WriteStringAndPush(const std::string &data)// 写入string对象并造成_writer偏移
{
WriteString(data);
OffsetWriter(data.size());
}
void WriteBuffer(Buffer &data)// 写入Buffer对象
{
Write(data.ReadPosition(),data.ReadAbleSize());
}
void WriteBufferAndPush(Buffer &data)
{
WriteBuffer(data);
OffsetWriter(data.ReadAbleSize());
}
/*完全可以这么写,但是我不这么干。原因很简单,记性不好,老是会出bug
void Write(const void *data,uint64_t len,bool IsOffset = true)
{
//.....
if(IsOffset) OffsetWriter(len);
}*/
void Read(void *buf,uint64_t len)
{
if(len > ReadAbleSize()) abort();// 只能读取有效的数据
std::copy(ReadPosition(),ReadPosition() + len,(char *)buf);// 将[_reader,_reader+len]之间的数据拷贝到buf之后的位置
}
void ReadAndPop(void *buf,uint64_t len)// 读取数据并且移动_reader,即从Buffer当中删除数据
{
Read(buf,len);
OffsetReader(len);
}
std::string ReadAsString(uint64_t len)// 读取len个数据,在该函数内部封装成string对象返回出去
{
if(len > ReadAbleSize()) abort();
std::string str;
str.resize(len);
Read(&str[0],len);
return std::move(str);// 减少拷贝
}
std::string ReadAsStringAndPop(uint64_t len)
{
if(len > ReadAbleSize()) abort();
std::string str = ReadAsString(len);
OffsetReader(len);
return std::move(str);
}
char *FindEndOfLine()// 寻找一行的结束标志'\n'
{
char *res = (char *)memchr(ReadPosition(),'\n',ReadAbleSize());
return res;
}
std::string GetLine()// 获取一行数据
{
char *pos = FindEndOfLine();
if(pos == nullptr) return "";
return ReadAsString(pos - ReadPosition() + 1);// +1是为了将'\n'一并返回
}
std::string GetLineAndPop()
{
std::string str = GetLine();
OffsetReader(str.size());
return std::move(str);
}
void Clear()// 清空Buffer
{
_reader = 0;
_writer = 0;
}
private:
std::vector<char> _buffer;// 使用vector进行空间管理
uint64_t _reader;// 有效数据的起始位置
uint64_t _writer;// 有效数据的结束位置
};
现在来分析一下Buffer的扩容机制:

2.1.3Socket模块实现
作为一个网络库,套接字编程是必不可少的,但是其中涉及到很多重复切繁琐的过程,所以索性也将其封装起来,方便使用。
Socket模块的代码实现:
#define MAX_LISTEN 64// 全连接队列大小
class Socket
{
public:
Socket(int sockfd = -1):_sockfd(sockfd) {}
~Socket() {}
int GetFd() {return _sockfd;}// 获取套接字文件描述符
bool Create()// 创建套接字
{
_sockfd = socket(AF_INET,SOCK_STREAM,0);// 只支持TCP协议
if(_sockfd < 0)
{
ERROR_LOG("CREATE SOCKET ERROR: %s",strerror(errno));
return false;
}
NonBlock();// 任何套接字都设置非阻塞
return true;
}
bool Bind(const std::string &ip,uint16_t port)
{
struct sockaddr_in local;
memset(&local,0,sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = inet_addr(ip.c_str());
socklen_t len = sizeof(local);
int n = bind(_sockfd,(struct sockaddr *)&local,len);
if(n < 0)
{
ERROR_LOG("BIND SOCKET ERROR: %s",strerror(errno));
return false;
}
return true;
}
bool Listen(int backlog = MAX_LISTEN)
{
int n = listen(_sockfd,backlog);
if(n < 0)
{
ERROR_LOG("SOCKET LISTEN ERROR: %s",strerror(errno));
return false;
}
return true;
}
bool Connect(const std::string &ip,uint16_t port)
{
struct sockaddr_in local;
memset(&local,0,sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = inet_addr(ip.c_str());
socklen_t len = sizeof(local);
int n = connect(_sockfd,(struct sockaddr *)&local,len);
if(n < 0)
{
ERROR_LOG("CONNECT SERVER ERROR: %s",strerror(errno));
return false;
}
return true;
}
int Accept()
{
int connfd = accept(_sockfd,nullptr,nullptr);// 不关心客户端信息
if(connfd < 0)
{
ERROR_LOG("SOCKET ACCEPT ERROR: %s",strerror(errno));
return -1;
}
NonBlock();// 任何套接字都设置非阻塞
return connfd;
}
ssize_t Recv(void *buf,size_t len,int flag = 0)// 默认为阻塞读取
{
ssize_t n = recv(_sockfd,buf,len,flag);
if(n <= 0)
{
if(errno == EAGAIN || errno == EINTR) return 0;
ERROR_LOG("SOCKET RECV ERROR: %s",strerror(errno));
return -1;
}
return n;
}
ssize_t NoBlockRecv(void *buf,size_t len)// 非阻塞式读取
{
return Recv(buf,len,MSG_DONTWAIT);
}
ssize_t Send(const void *buf,size_t len,int flag = 0)// 默认为阻塞式的发送数据
{
ssize_t n = send(_sockfd,buf,len,flag);
if(n < 0)
{
if(errno == EAGAIN || errno == EINTR) return 0;
ERROR_LOG("SOCKET SEND ERROR: %s",strerror(errno));
return -1;
}
return n;
}
ssize_t NoBlockSend(const void *buf,size_t len)
{
return Send(buf,len,MSG_DONTWAIT);
}
void Close()// 关闭套接字
{
if(_sockfd != -1)
{
close(_sockfd);
_sockfd = -1;
}
}
bool CreateServer(uint16_t port,const std::string &ip = "0.0.0.0")// 直接创建一个服务器套接字
{
if(Create() == false) return false;
ReuseAddr();
if(Bind(ip,port) == false) return false;
if(Listen() == false) return false;
return true;
}
bool CreateClinet(const std::string &ip,uint16_t port)// 直接创建一个客户端连接
{
if(Create() == false) return false;// 创建失败
if(Connect(ip,port) == false) return false;// 连接失败
return true;
}
void ReuseAddr()// 开启端口地址重用
{
int val = 1;
setsockopt(_sockfd,SOL_SOCKET,SO_REUSEADDR,(void *)&val,sizeof(val));
val = 1;
setsockopt(_sockfd,SOL_SOCKET,SO_REUSEPORT,(void *)&val,sizeof(val));
}
void NonBlock()// 设置非阻塞
{
int flag = fcntl(_sockfd,F_GETFL,0);// 获取当前属性
fcntl(_sockfd,F_SETFL,flag | O_NONBLOCK);
}
private:
int _sockfd;
};
2.1.4Channel模块实现
本项目的目标是实现一个高性能并发服务器,那么高性能就需要用到多路转接技术。多路转接可以选择select、poll和epoll,本项目选择epoll。并且本项目实现的是工作在ET模式下的服务器。
都知道epoll的效率高,这里给出几个选择epoll的理由:
1.epoll监听的文件描述符数量没有限制
2.保存文件描述符的数据结构并不在应用层而是在内核中,这就意味着用户不需要去维护任何有关文件描述符的数据结构。并且内核使用红黑树来管理该数据结构,CRUD的效率会比较高
3.因为用户不维护数据结构,所以使用epoll时不需要像select那样重复传递参数
4.因为内核使用红黑树来管理每个文件描述符,红黑树的每个节点可以直接与struct_file结构体产生关联,当文件的缓冲区发生变化时,epoll可以很快地感知到,就没有必要像select和poll那样遍历数据结构了
5.epoll有ET(边缘触发)工作模式,这是select和poll所不具有的
因为多路转接技术不仅仅涉及到文件描述符,还涉及到文件描述符的事件,例如一个文件上可以有可读事件、可写事件、连接断开事件、错误事件、异常事件。由此可以得知,文件描述符和其事件是强相关的,那么Channel模块的工作就是将文件描述符和事件进行一个封装整合,方便使用。
当然了,Channel模块涉及到两个大动作:一是事件的设置,二是触发事件之后该做什么。事件的设置很简单,直接把事件和套接字绑定即可;触发事件之后要处理什么动作,这个动作由回调函数决定。
Channel模块的代码实现:
class EventLoop;// 一个声明
class Channel
{
private:
using EventCallbakc = std::function<void ()>;// 触发事件后的回调
public:
Channel(EventLoop *loop,int fd)
:_fd(fd),_loop(loop),_events(0),_revents(0)
{}
int GetFd() {return _fd;}
uint32_t GetEvents() {return _events;}// 获取监控事件
uint32_t GetRevents() {return _revents;}// 获取触发事件
void SetRevents(uint32_t events) {_revents = events;}// 设置就绪事件
void SetReadCallback(const EventCallbakc &cb) {_read_callback = cb;}// 设置读事件触发后的回调函数
void SetWriteCallback(const EventCallbakc &cb) {_write_callback = cb;}
void SetErrorCallback(const EventCallbakc &cb) {_error_callback = cb;}
void SetCloseCallback(const EventCallbakc &cb) {_close_callback = cb;}
void SetEventCallback(const EventCallbakc &cb) {_event_callback = cb;}
bool ReadAble() {return (_events & EPOLLIN);}// 当前文件描述符是否监控了可读事件?
bool WriteAble() {return (_events & EPOLLOUT);}// 当前文件描述符是否监控了可写事件?
void EnableRead() {_events |= EPOLLIN;Update();}// 添加读事件监控
void EnableWrite() {_events |= EPOLLOUT;Update();}// 添加写事件监控
void EnableETMode() {_events |= EPOLLET;Update();}// 开启ET模式
void DisableRead() {_events &= ~EPOLLIN;Update();}// 取消读事件监控
void DisableWrite() {_events &= ~EPOLLOUT;Update();}// 取消写事件监控
void DisableAll() {_events = 0;Update();}// 取消所有事件监控
/*--------------这两个接口的功能不属于Channel模块,因为他们涉及到事件的ADD、MOD、DEL,Channel模块不具备这个功能------------------*/
void Update();// 更新事件监控
void Remove();// 移除监控,区别于DisableAll,Remove是不再对_fd进行监控
/*--------------所以他们的实现被放在了类外,并且需要通过其他模块才能实现(EevntLoop)--------------------------------------------*/
void HandleEvent()// 通过触发的事件判断调用哪个回调
{
if((_revents & EPOLLIN) || (_revents & EPOLLRDHUP) || (_revents & EPOLLPRI))
{
if(_read_callback) _read_callback();
}
if(_revents & EPOLLOUT)
{
if(_write_callback) _write_callback();
}
else if(_revents & EPOLLERR)
{
if(_error_callback) _error_callback();
}
else if(_revents & EPOLLHUP)
{
if(_close_callback) _close_callback();
}
if(_event_callback) _event_callback();// 任意事件触发
}
private:
int _fd;// 文件描述符
EventLoop *_loop;
uint32_t _events;// 需要监控的事件
uint32_t _revents;// 触发的事件
EventCallbakc _read_callback;// 可读事件触发后的回调函数
EventCallbakc _write_callback;// 可写事件触发后的回调函数
EventCallbakc _error_callback;// 错误事件触发后的回调函数
EventCallbakc _close_callback;// 连接断开事件触发后的回调函数
EventCallbakc _event_callback;// 任意事件触发后的回调函数
};
Channle模块的实现还是比较简单的,但是其中出现了一个"EventLoop",现在简单介绍一些EventLoop是什么东西。
顾名思义,EventLoop就是事件循环,也就是说,事件的监听、处理都要通过EventLoop模块来完成。而Channle模块是负责管理文件描述符和其事件的,所以Channel模块是EventLoop的一个子模块。所以上面Channel类当中的"Update()"和"Remove()"方法并不在Channlei类当中实现,而是要等到EventLoop模块实现之后再实现。
2.1.5Poller模块实现
紧跟着的并不是实现EventLoop模块,而是Poller模块,Poller模块也是EventLoop的一个子模块。Poller模块的作用就是进行事件的监控和通知事件触发。说白了,Poller模块就是将"event_wait()"封装起来。
下面给出Poller模块的代码实现:
#define MAX_EPOLLEVENTS 1024
class Poller
{
private:
bool HanChannel(Channel *channle)// 判断Channel对象是否被Poller模块所管理
{
auto it = _channels.find(channle->GetFd());
if(it == _channels.end())
{
return false;
}
return true;
}
void Update(Channel *channel,int op)// 更新epoll的监控事件
{
int fd = channel->GetFd();
struct epoll_event ev;
ev.data.fd = fd;
ev.events = channel->GetEvents();
int n = epoll_ctl(_epfd,op,fd,&ev);
if(n < 0)
{
ERROR_LOG("EPOLLCTL ERROR: %s",strerror(errno));
}
}
public:
Poller()
{
_epfd = epoll_create(20);// 创建epoll例程
if(_epfd < 0)
{
ERROR_LOG("EPOLL CREATE ERROR: %s",strerror(errno));
abort();
}
}
void UpdateEvent(Channel *channel)// 更新事件的监控
{
bool ret = HanChannel(channel);
if(ret == false)// 如果当前Channel对象并不被Poller所管理,那么它就是一个新的Channel
{
_channels.insert(std::make_pair(channel->GetFd(),channel));// 让Poller模块管理起来
Update(channel,EPOLL_CTL_ADD);
return;
}
Update(channel,EPOLL_CTL_MOD);// 如果已经是存在的Channel对象
}
void RemoveEevnt(Channel *channel)// 移除事件对某个Channel的事件监控
{
auto it = _channels.find(channel->GetFd());
if(it != _channels.end())
{
_channels.erase(it);
}
Update(channel,EPOLL_CTL_DEL);
}
void Poll(std::vector<Channel *> *active)// 开始监控,并且返回事件触发的Channel
{
int ret = epoll_wait(_epfd,_evs,MAX_EPOLLEVENTS,-1);
if(ret < 0)
{
if(errno == EINTR) return;
ERROR_LOG("EPOLL WAIT ERROR: %s",strerror(errno));
abort();
}
for(int i=0;i<ret;i++)
{
auto it = _channels.find(_evs[i].data.fd);
if(it == _channels.end()) abort();// 如果触发事件对应的Channel并不被Poller所管理,就说明有问题
it->second->SetRevents(_evs[i].events);// 通知事件
active->push_back(it->second);// 将触发事件的Channel交给外部(这个外部是EventLoop)
}
}
private:
int _epfd;// epoll例程
struct epoll_event _evs[MAX_EPOLLEVENTS];// 存储触发事件的数组
std::unordered_map<int,Channel *> _channels;// Poller模块会负责通知事件,通知的对象就是Channel对象
};
Poller模块实现的难度不大,这里需要强调一下"UpdateEvent()"和"RemoveEvent()"的区别。前者是对监控事件的增加或删除,就比如一开始监听了EPOLLIN事件,此时需要添加一个EPOLLOUT事件,就需要通过UpdateEvent()来完成,亦或是需要取消EPOLLOUT事件的监控,也需要UpdateEvent()模块来完成;而后者的作用是直接取消事件监控,意思就是事件对应的文件描述符,epoll不再对其进行监听了,举个例子来说,假设某个文件描述符的连接断开了,就需要取消该文件描述符的事件监控,就需要通过RemoveEvent()来完成。
2.1.6TimerWheel模块实现
服务器当中有一个非常重要的部分叫做定时器。定时器可以用来定时处理某些任务,在服务器的典型用处就是定时处理一些非活跃的连接,以释放服务器资源。
非活跃连接的定义是:长时间没有事件触发而空占服务器资源的连接。当这一类连接变多时,新的连接可能会无法连接服务器。
下面给出TimerWheel模块的代码实现:
using TaskFunc = std::function<void()>;
using ReleaseFunc = std::function<void ()>;
class TimerTask// 定时任务类
{
public:
TimerTask(uint64_t id,uint32_t timeout,const TaskFunc &cb,int turns)
:_id(id),_timeout(timeout),_task_cb(cb),_canceled(false)// 默认不取消定时任务
,_turns(turns)
{}
~TimerTask()
{
if(_canceled == false) _task_cb();// 对象析构时执行定时任务
_release();// 释放TimerWheel中所管理的TimerTask资源
}
void Cancel() {_canceled = true;}// 取消定时任务
void SetRelease(const ReleaseFunc &cb) {_release = cb;}
uint32_t DelayTime() {return _timeout;}// 返回定时时间
void ReduceTurns() {--_turns;}// 减少圈数
int GetTurns() {return _turns;}// 获得圈数
private:
uint64_t _id;// 定时任务id,方便定位、查询、管理
uint32_t _timeout;// 定时任务的超时时间,即多久之后执行任务
bool _canceled;// 是否取消定时任务
TaskFunc _task_cb;// 定时器任务
ReleaseFunc _release;// 删除TimerWheel当中保存的TimerTask信息,防止内存泄漏
int _turns;// 圈数
};
class TimerWheel
{
private:
using WeakTask = std::weak_ptr<TimerTask>;// 指向TimerTask的弱指针
using PtrTask = std::shared_ptr<TimerTask>;// 指向TimerTask的引用计数型指针
static int CreateTimerfd()
{
int timerfd = timerfd_create(CLOCK_MONOTONIC,0);// 创建定时器
if(timerfd < 0)
{
ERROR_LOG("TIMERFD CREATE ERROR: %s",strerror(errno));
abort();
}
struct itimerspec itime;
itime.it_value.tv_sec = 1;
itime.it_value.tv_nsec = 0;// 第一次超时时间为1s后
itime.it_interval.tv_sec = 1;
itime.it_interval.tv_nsec = 0;// 第一次超时时间过后,每隔1s超时一次
timerfd_settime(timerfd,0,&itime,nullptr);
return timerfd;
}
int ReadTimerfd()
{
uint64_t times;
int n = read(_timerfd,×,8);// 只能8个字节的读
if(n < 0)
{
ERROR_LOG("READ TIMEFD FAILED: %s",strerror(errno));
abort();
}
// 每次从_timerfd当中读取数据后,_timerfd内的内容会被清空,所以读事件不会重复被出发
return times;// 返回值是超时次数
}
void RunTimerTask()
{
_tick = (_tick + 1) % _capacity;// 秒针转动一次
for(auto it = _wheel[_tick].begin();it != _wheel[_tick].end();)
{
if((*it)->GetTurns() >= 1)// 圈数>=1的定时任务不应该被执行,而是减少圈数
{
(*it)->ReduceTurns();
++it;
}
else
{
it = _wheel[_tick].erase(it);// 圈数=0的TimerTask的shared_ptr会被销毁,引用计数会递减
}
}
}
void OnTime()// 超时时间到,读事件触发,读事件触发后的回调函数
{
int times = ReadTimerfd();
for(int i=0;i<times;i++)// 返回的是超时次数,超时几次就处理几次任务
{
RunTimerTask();
}
}
void RemoveTimer(uint64_t id)
{
auto it = _timers.find(id);
if(it != _timers.end())
{
_timers.erase(it);
}
}
/*--------------这三个函数在实现EventLoop之后会自然理解-------------------*/
void TimerAddInLoop(uint64_t id,uint32_t delay,const TaskFunc &cb)
{
int turns = delay / _capacity;// 计算圈数
PtrTask pt(new TimerTask(id,delay,cb,turns));// 创建TimerTask对象
pt->SetRelease(std::bind(&TimerWheel::RemoveTimer,this,id));// 设置TimerTask析构时,取消TimerWheel对其的管理
int pos = (_tick + delay) % _capacity;
_wheel[pos].push_back(pt);// 在时间轮当中找到适当的位置
_timers[id] = WeakTask(pt);
}
void TimerRefreshInLoop(uint64_t id)// 真实的刷新定时器
{
auto it = _timers.find(id);
if(it == _timers.end())
{
return;
}
PtrTask pt = it->second.lock();// 弱指针向shared_ptr转化
int delay = pt->DelayTime();
int turns = delay / _capacity;// 计算圈数
pt->SetTurns(turns);// 设置圈数
int pos = (_tick + delay) % _capacity;
_wheel[pos].push_back(pt);// 重新添加新的定时任务对象
}
void TimerCancelInLoop(uint64_t id)
{
auto it = _timers.find(id);
if(it == _timers.end())
{
return;
}
PtrTask pt = it->second.lock();
if(pt) pt->Cancel();
}
/*-----------------------------------------------------------------------*/
public:
TimerWheel(EventLoop *loop)
:_capacity(60),_tick(0),_wheel(_capacity),_loop(loop),
_timerfd(CreateTimerfd()),_timer_channel(new Channel(_loop,_timerfd))// 每一个文件描述符都会配备一个Channel对象
{
_timer_channel->SetReadCallback(std::bind(&TimerWheel::OnTime,this));
_timer_channel->EnableRead();// 启动读事件监控
}
/*-------------------------这三个函数需要在EventLoop实现后才能实现---------------------------------*/
void TimerAdd(uint64_t,uint32_t timeout,const TaskFunc &cb);
void TimerRefresh(uint64_t id);
void TimerCancel(uint64_t id);
/*-------------------------原因在实现EventLoop时做解释--------------------------------------------*/
bool HasTimer(uint64_t id)
{
auto it = _timers.find(id);
if(it == _timers.end())
{
return false;
}
return true;
}
private:
int _tick;// 秒针,心博,每秒钟变化一次
int _capacity;// 表盘的最大数量,模拟钟表
std::vector<std::list<PtrTask>> _wheel;// 时间轮,存放TimerTask的智能指针
std::unordered_map<uint64_t,WeakTask> _timers;// 管理TimerTask对象
EventLoop *_loop;
int _timerfd;
std::unique_ptr<Channel> _timer_channel;
};
现在介绍一下TimerWheel的工作原理。
从上面的代码当中可以发现时间轮(_wheel)当中并没有存放TimerTask实体,而是存储了指向TimerTask对象的shared_ptr。这么做的原因有几个:
1.shared_ptr是引用计数型的智能指针,当计数为0时,对象会自动调用析构销毁
2.shared_ptr拷贝时不会真实地拷贝一个对象,仅仅是对计数器递增。利用这个特性可以方便的实现定时器的刷新,因为时间轮存放的是shared_ptr,那么刷新之后的定时器的引用计数就为2,旧的定时器shared_ptr被释放了,仅仅会递减一下计数器,不会影响另外一个shared_ptr
那么_timers对象是一个哈希表,它存储的Val值是一个weak_ptr,其原因在于weak_ptr不会增加引用计数,即不会延长TimerTask对象的生命周期,也就不会影响时间轮的工作。并且weak_ptr有一个特性,那便是可以升级成为shared_ptr,这样一来,weak_ptr就具有了探测指向的对象是否存在的功能了。
上述内容理解之后,就可以理解时间轮的工作原理了。本项目模拟的是一个钟表,每个定时任务放在每个钟表刻度上,秒针指向了哪个刻度,哪个定时任务就执行。当然了,还需要考虑到定时任务的延时时间大于60s的定时任务,因为事件轮有限,所以每个TimerTask对象都会一个_truns成员用来表示圈数,只有圈数为0并且被秒针指向的时候才能被删除。
TimerWheel的工作原理图如下:
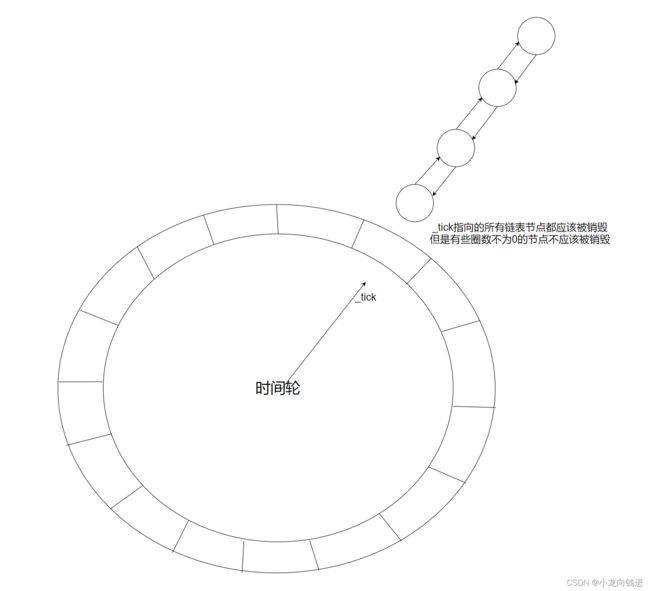
2.1.7EventLoop模块实现
TimerWheel也是EventLoop的子模块。EventLoop的功能是进行事件循环、事件监听、事件处理和定时任务。现在知道进行事件监听的模块是Poller、事件处理的是Channel、定时任务在TimerWheel当中,所以不难推测出EventLoop的设计一定包含前面所说的几个模块。
但是EventLoop模块不仅仅是做一个封装。
可以这么理解,一个EventLoop就是一个Reactor,本项目的设计目标是One Thread One Loop,即一个线程对应一个Reactor。但是对于组件使用者来说他们似乎并不关心这些东西,那么很可能会有如下代码所示的用法:
EventLoop loop;
thread t([&](){loop.AddTimer();});
//.......
这段代码的问题在于组件使用者在不同的线程操作了同一个EventLoop对象,这就很容易导致线程安全问题。而互斥锁是一种解决方案,但是不可取,因为上面的代码仅仅是一个EventLoop对象,如果这个对象是有关连接的Connection对象呢?如果有10000个Connection对象呢?是不是每个对象都要加锁?
所以本项目使用了一种解决方案,那就是在EventLoop当中放一个任务队列。思路是这样的:在执行任何一个有可能导致线程安全问题的函数时都判断一下执行该函数的线程是否是EventLoop对象构造时的线程,如果是,那么直接执行;如果不是,就将函数封装成一个一个任务对象压入任务队列,待EventLoop处理完所有的触发事件后再统一处理任务队列的所有任务。
这样做有两个好处:
1.减少了互斥锁的使用,仅需要对任务队列加锁即可
2.保证了任务对象的串行执行,因为一旦任务被压入任务队列之后,执行任务队列中的任务的线程一定是一个线程(如果不理解,可以看代码来理解)
EventLoop模块的代码实现:
class EventLoop
{
private:
using Functor = std::function<void()>;
void RunAllTask()// 执行任务队列当中的所有任务
{
std::vector<Functor> functor;
{
std::unique_lock<std::mutex> _lock(_mutex);
_tasks.swap(functor);// 交换之后,_tasks就为空了,其他线程就没有任务执行了
}
for(auto &f:functor)
{
f();// 执行任务
}
}
static int CreateEventFd()
{
int efd = eventfd(0,EFD_CLOEXEC | EFD_NONBLOCK);
if(efd < 0)
{
ERROR_LOG("CREATE EVENTFD ERROR: %s",strerror(errno));
abort();
}
return efd;
}
void ReadEventfd()// 从_event_fd当中读取数据
{
uint64_t res = 0;
int ret = read(_event_fd,&res,sizeof(res));
if(ret < 0)
{
if(errno == EINTR || errno == EAGAIN)
{
return;
}
ERROR_LOG("READ EVENTFD ERROR: %s",strerror(errno));
abort();
}
}
void WeakUpEventFd()// 向_evenfd_fd写入数据,即触发_event_fd的可读事件
{
uint64_t val = 1;
int ret = write(_event_fd,&val,sizeof(val));
if(ret < 0)
{
if(errno == EINTR)
{
return;
}
ERROR_LOG("READ EVENTFD ERROR: %s",strerror(errno));
abort();
}
}
public:
EventLoop()
:_thread_id(std::this_thread::get_id()),
_event_fd(CreateEventFd()),
_event_channel(new Channel(this,_event_fd)),
_timer_wheel(this)
{
// _event_fd也需要被监听
_event_channel->SetReadCallback(std::bind(&EventLoop::ReadEventfd,this));
_event_channel->EnableRead();
}
void Start()
{
while(true)
{
std::vector<Channel *> actives;
_poller.Poll(&actives);// 所有事件触发的Channel对象都会被放在actives中
for(auto &channel:actives)
{
channel->HandleEvent();// 挨个处理事件触发之后的任务
}
RunAllTask();// 最后执行任务队列的所有任务
}
}
bool IsInLoop()// 判断当前EventLoop对象是否处于构造线程中
{
return (_thread_id == std::this_thread::get_id());
}
void AssertInLoop()
{
if(_thread_id != std::this_thread::get_id()) abort();
}
void RunInLoop(const Functor &cb)// 所有任务的执行都必须经过这个接口
{
if(IsInLoop())
{
return cb();// 处于构造线程的任务直接执行
}
QueueInLoop(cb);// 否则压入任务队列
}
void QueueInLoop(const Functor &cb)
{
{
std::unique_lock<std::mutex> _lock(_mutex);
_tasks.push_back(cb);
}
WeakUpEventFd();// 任务队列有任务,向_event_fd写入数据,触发读事件,读事件触发后才会执行RunAllTask()继而执行任务队列的任务
}
void UpdateEvent(Channel *channel) {_poller.UpdateEvent(channel);}
void RemoveEvent(Channel *channel) {_poller.RemoveEevnt(channel);}
void TimerAdd(uint64_t id,uint32_t delay,const TaskFunc &cb) {_timer_wheel.TimerAdd(id,delay,cb);}
void TimerRefresh(uint64_t id) {_timer_wheel.TimerRefresh(id);}
void TimerCancel(uint64_t id) {_timer_wheel.TimerCancel(id);}
bool HasTimer(uint64_t id) {_timer_wheel.HasTimer(id);}
private:
std::thread::id _thread_id;// 线程id
int _event_fd;// eventfd的返回值,必须要有这个,如果任务队列当中有任务,但是没有IO事件触发,任务队列的任务就一直不会执行
std::unique_ptr<Channel> _event_channel;
Poller _poller;
std::vector<Functor> _tasks;// 任务队列
std::mutex _mutex;// 保证任务队列的互斥访问
TimerWheel _timer_wheel;// 定时器
};
/*---------------------------------Channel、TimerWheel当中的某些成员函数必须等EventLoop实现之后才能实现----------------------------------*/
void Channel::Remove() {_loop->RemoveEvent(this);}
void Channel::Update() {_loop->UpdateEvent(this);}
void TimerWheel::TimerAdd(uint64_t id,uint32_t delay,const TaskFunc &cb)
{
_loop->RunInLoop(std::bind(&TimerWheel::TimerAddInLoop,this,id,delay,cb));
}
void TimerWheel::TimerRefresh(uint64_t id)
{
_loop->RunInLoop(std::bind(&TimerWheel::TimerRefreshInLoop,this,id));
}
void TimerWheel::TimerCancel(uint64_t id)
{
_loop->RunInLoop(std::bind(&TimerWheel::TimerCancelInLoop,this,id));
}
/*---------------------------------------------------------------------------------------------------------------------------------*/
通过代码可以发现,EventLoop模块要实现事件监控、事件循环和定时任务的处理还是非常简单的。大多数精力被放到了解决线程安全的问题上。
2.1.8整合测试1
项目写到这里就可以做一个简单的整合测试了,这里以实现Echo服务器为例:
EventLoop loop;
void WriteHandle(Socket *sock,Channel *ch,Buffer *buf)
{
sock->Send(buf->ReadPosition(),buf->ReadAbleSize());
ch->DisableWrite();
ch->EnableRead();
}
void ReadHandle(Socket *sock,Channel *ch)
{
char buffer[1024] = {0};
ssize_t n = sock->Recv(buffer,sizeof(buffer) - 1);
buffer[n] = 0;
DEBUG_LOG("接收到%d号连接的消息: %s",sock->GetFd(),buffer);
Buffer *buf = new Buffer;
buf->WriteAndPush(buffer,strlen(buffer));
ch->DisableRead();
ch->SetWriteCallback(std::bind(WriteHandle,sock,ch,buf));
ch->EnableWrite();
}
void AcceptHandle(Socket *sock)
{
int connfd = sock->Accept();
DEBUG_LOG("获得新连接: %d",connfd);
Socket *connsock = new Socket(connfd);
Channel *connch = new Channel(&loop,connsock->GetFd());
connch->SetReadCallback(std::bind(ReadHandle,connsock,connch));
connch->EnableRead();
}
int main()
{
Socket lissock;
bool ret = lissock.CreateServer(9090);
if(ret == false)
{
ERROR_LOG("CREATE SERVER ERROR");
return -1;
}
Channel lisch(&loop,lissock.GetFd());
lisch.SetReadCallback(std::bind(AcceptHandle,&lissock));
lisch.EnableRead();
loop.Start();
return 0;
}
运行结果如下图所示(客户端使用telnet模拟):

2.1.9LoopThread模块实现
前面提到过本项目的目标是实现一个One Thread One Loop,那么LoopThread模块就是负责创建线程和对应的EventLoop。
LoopThread模块的代码实现:
class LoopThread
{
private:
void ThreadEntry()
{
EventLoop loop;
{
std::unique_lock<std::mutex> lock(_mutex);
_loop = &loop;
_cond.notify_all();// 确实创建了一个EventLoop对象,GetLoop()才能返回
}
loop.Start();// 线程内启动loop,loop对象不会被销毁
}
public:
LoopThread()
:_loop(nullptr),_thread(std::thread(&LoopThread::ThreadEntry,this))
{}
EventLoop *GetLoop()
{
EventLoop *loop = nullptr;
{
std::unique_lock<std::mutex> lock(_mutex);
_cond.wait(lock,[&](){return _loop != nullptr;});// 如果_loop为空就一直阻塞
loop = _loop;
}
return loop;
}
private:
std::mutex _mutex;
std::condition_variable _cond;
EventLoop *_loop;// 这个对象需要在线程内实例化
std::thread _thread;
};
2.1.10LoopThreadPool模块实现
LoopThreadPool模块的本质是一个线程池。它的作用就是对LoopThread做管理。
LoopThreadPool的代码实现:
class LoopThreadPool
{
public:
LoopThreadPool(EventLoop *baseloop)
:_thread_count(0),_next_index(0),_baseloop(baseloop)
{}
void SetThreadCount(int count) {_thread_count = count;}// 设置线程数量
void Create()// 启动线程池
{
if(_thread_count > 0)
{
_threads.resize(_thread_count);
_loops.resize(_thread_count);
for(int i=0;i<_thread_count;i++)
{
_threads[i] = new LoopThread();// LoopThread一旦创建就开始工作
_loops[i] = _threads[i]->GetLoop();
}
}
}
EventLoop *NextLoop()// 任务的分发要平均分配给每个线程,这里使用循环轮转的方式分配
{
if(_thread_count == 0) return _baseloop;// 如果线程数量为0,就返回主线程的EventLoop
_next_index = (_next_index + 1) % _thread_count;
return _loops[_next_index];
}
private:
int _thread_count;// 线程数量
int _next_index;// 下标
EventLoop *_baseloop;// 主线程EventLoop
std::vector<LoopThread *> _threads;
std::vector<EventLoop *> _loops;
};
2.1.11主从Reactor模式
项目写到这里就很容易理解One Thread One Loop了,那么主从Reactor模式是什么意思?
首先可以明确一个点,当服务器没有创建任何线程的时候,这个服务器只有一个主线程。如果为服务器创建多个线程的时候,该服务器就是一个多线程程序。
那么一个线程对应一个Reactor,那么就可以规定每个Reactor的处理任务。在本项目当中,主线程负责连接的建立,即,主线程的Reactor负责连接套接字的创建和销毁;其他的从线程,即从线程的Reactor负责连接的业务处理。
主从Reactor模式有几个好处:
1.多线程,并发式的执行任务可以充分利用CPU资源,从而提高服务器的执行效率
2.连接接收和业务处理解耦合,这样做的好处就是业务处理不会影响新连接的接收。试想一下,如果一个Reactor既负责业务处理又负责新连接的接收,如果一个新连接到来,但是它的Reactor要处理一个长达30s的业务逻辑,那么该新连接就要无缘无故地等待30s
3.扩展性和可维护性非常强,因为每个线程的Reactor都是独立运行的,扩展和维护就显得非常简单
主从Reactor模式的逻辑关系图如下所示:
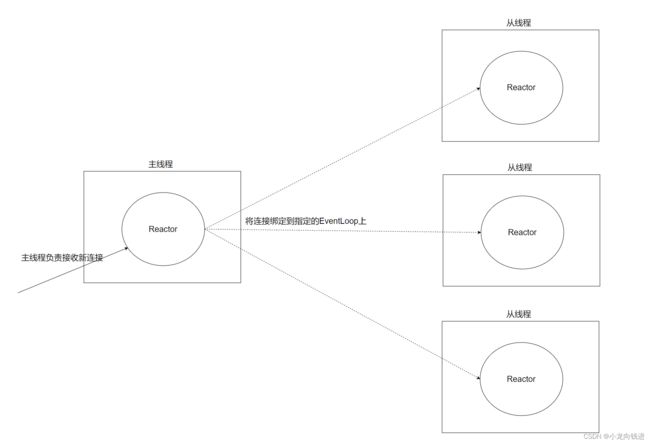
2.1.12整合测试2
还是以Echo服务器为例:
EventLoop loop;
void WriteHandle(Socket *sock,Channel *ch,Buffer *buf)
{
sock->Send(buf->ReadPosition(),buf->ReadAbleSize());
ch->DisableWrite();
ch->EnableRead();
}
void ReadHandle(Socket *sock,Channel *ch)
{
char buffer[1024] = {0};
ssize_t n = sock->Recv(buffer,sizeof(buffer) - 1);
buffer[n] = 0;
DEBUG_LOG("接收到%d号连接的消息: %s",sock->GetFd(),buffer);
Buffer *buf = new Buffer;
buf->WriteAndPush(buffer,strlen(buffer));
ch->DisableRead();
ch->SetWriteCallback(std::bind(WriteHandle,sock,ch,buf));
ch->EnableWrite();
}
void AcceptHandle(Socket *sock, LoopThreadPool *pool)
{
int connfd = sock->Accept();
DEBUG_LOG("获得新连接: %d",connfd);
Socket *connsock = new Socket(connfd);
Channel *connch = new Channel(pool->NextLoop(),connsock->GetFd());
connch->SetReadCallback(std::bind(ReadHandle,connsock,connch));
connch->EnableRead();
}
int main()
{
Socket lissock;
bool ret = lissock.CreateServer(9090);
if(ret == false)
{
ERROR_LOG("CREATE SERVER ERROR");
return -1;
}
LoopThreadPool *pool = new LoopThreadPool(&loop);
pool->SetThreadCount(3);
pool->Create();
Channel lisch(&loop,lissock.GetFd());
lisch.SetReadCallback(std::bind(AcceptHandle,&lissock,pool));
lisch.EnableRead();
loop.Start();
return 0;
}
运行结果:

可以发现,接收连接的线程和业务处理的线程不是同一线程。
2.1.13Any类实现
在C++17当中可以直接使用any类,但本项目主要使用C++11,所以手撕一个Any类。
Any类的作用是存储不同类型的对象。下面的伪代码就是个例子:
Any t;
t = 20;// 存储int类型
t = 2.2;// 存储double类型
t = "hello world";// 存储const char *类型
Any类在本项目中的作用是存储不从同的协议上下文。假设当前使用的协议是HTTP协议,过了一会想要切换成WebSocket协议代价是非常低的,因为只需要协议上下文复制给Any类就可以了。
Any类的代码实现:
class Any
{
public:
Any()
:_content(nullptr)
{}
template <class T>
Any(const T &val)
:_content(new placeholder<T>(val))
{}
Any(const Any &other)// 拷贝构造,深拷贝
:_content(other._content ? other._content->clone() : nullptr)
{}
~Any() {delete _content;}
void swap(Any &other) {std::swap(_content,other._content);}
template <class T>
T *get()// 获得存储的对象的指针
{
if(typeid(T) != _content->type()) abort();
return &((placeholder<T> *)_content->_val);
}
template <class T>
Any &operator=(const T &val)
{
Any(val).swap(*this);
return *this;
}
Any &operator=(const Any &other)
{
Any(other).swap(*this);
return *this;
}
private:
class holder
{
public:
virtual ~holder() {}
virtual const std::type_info &type() = 0;// 纯虚函数,返回类型
virtual holder *clone() = 0;
};
template <class T>
class placeholder : public holder
{
public:
placeholder(const T &val)
:_val(val)
{}
virtual const std::type_info &type() {return typeid(T);}// 虚函数重写
virtual holder *clone() {return new placeholder(_val);}// 拷贝一个placeholder对象
T _val;// 存储的对象
};
holder *_content;// 父类指针,构成多态
};
Any类当中有一个名为"placeholder"的模板类,它继承自父类"holder"。当placehodler被实例化了之后,就可以指定类型并且通过父类指针_content找到对应的placeholder,从而获取存储到Any类当中的值。
下面给出一个测试用例以加深理解:
int main()
{
Any any;
any = 15;// int类型
std::cout << "int:" << *any.get<int>() << std::endl;
any = std::string("hello world");// string类型
std::cout << "string:" << *any.get<std::string>() << std::endl;
return 0;
}
运行结果:
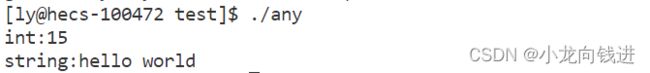
可以把int类型想象成一种应用层协议,过了一段时间之后,可以直接赋值切换成其他的应用层协议(这里用string类代替)。
需要注意的是,本项目实现的Any类只能存储一个对象(对本项目来说是足够了的)。
2.1.14Connection模块实现
Connection就是对连接进行一次封装。一个连接不仅仅只有套接字,还有缓冲区、事件循环等等这一类的东西。组件使用者要想对连接进行业务处理时,必须通过某种方式处理,本项目通过回调函数的方式实现。
总而言之,Connection模块就是对Buffer、Channel、EventLoop等等模块的再一次封装,因为一个连接本身就应该具有这些东西。
Connection模块的代码实现:
typedef enum {DISCONNECTED,CONNECTING,CONNECTED,DISCONNECTING}ConnStatu;// 定义连接的几种状态:未连接、连接种、已连接、正在断开连接
class Connection;
using PtrConnection = std::shared_ptr<Connection>;// Connection对象的智能指针,组件使用使用者操作Connection时只能通过只能指针操控
class Connection : public std::enable_shared_from_this<Connection>// 让this指针能够作为智能指针
{
private:
using ConnectedCallback = std::function<void(const PtrConnection &)>;// 连接建立成功后的回调函数
using MessageCallback = std::function<void(const PtrConnection &,Buffer *)>;// 消息到来后的回调函数
using ClosedCallback = std::function<void(const PtrConnection &)>;// 连接关闭之后的回调函数
using AnyEventCallback = std::function<void(const PtrConnection &)>;// 连接的任意事件触发后的回调函数
/*-----------------------下面这5个函数都是Channel的回调函数------------------------------*/
void HandelRead()// 读事件触发
{
while(true)// ET模式,一次性读完数据
{
char buffer[1024];
ssize_t ret = _socket.NoBlockRecv(buffer,sizeof(buffer) - 1);
if(ret < 0)// 如果读取数据时发生错误
{
ShutdownInLoop();// 需要关闭连接,但并不是立马关闭连接,而是在管理连接之前做一些处理
return;
}
if(ret == 0) break;
_in_buffer.WriteAndPush(buffer,ret);// 将读到的数据写入缓冲区
}
if(_in_buffer.ReadAbleSize() > 0)// 调用回调
{
if(_message_callback) _message_callback(shared_from_this(),&_in_buffer);
}
}
void HandleWrite()// 写事件触发
{
ssize_t ret = _socket.NoBlockSend(_out_buffer.ReadPosition(),_out_buffer.ReadAbleSize());
if(ret < 0)// 如果发送出错
{
if(_in_buffer.ReadAbleSize() > 0)// 如果输入缓冲区还有数据
{
if(_message_callback) _message_callback(shared_from_this(),&_in_buffer);
}
Release();// 释放连接
return;
}
_out_buffer.OffsetReader(ret);// 指针偏移,成功发送数据
if(_out_buffer.ReadAbleSize() == 0)// 如果没有数据可以发送了
{
_channel.DisableWrite();// 取消写事件的监听
if(_statu == DISCONNECTING)// 如果是正在断开的情况下,就需要释放连接
{
Release();
return;
}
}
}
void HandleClose()// 连接断开事件触发
{
if(_in_buffer.ReadAbleSize() > 0)
{
if(_message_callback) _message_callback(shared_from_this(),&_in_buffer);
}
Release();
}
void HandleError()// 异常事件触发
{
HandleClose();// 不做处理,直接关闭连接
}
void HandleEvent()// 任意事件触发
{
if(_enable_inactive_release == true)// 如果启动了非活跃连接定时销毁
_loop->TimerRefresh(_conn_id);// 那么就要刷新定时器
if(_event_callback)
_event_callback(shared_from_this());
}
/*-----------------------上面这5个函数都是Channel的回调函数------------------------------*/
void EstablishedInLoop()// 连接建立成功之后,需要进行一些设置:改变状态、启动事件监听等等
{
if(_statu != CONNECTING) abort();
_statu = CONNECTED;
_channel.EnableRead();
if(_connected_callback) _connected_callback(shared_from_this());
}
void CancelInactiveReleaseInLoop()// 取消非活跃连接定时销毁
{
_enable_inactive_release = false;
if(_loop->HasTimer(_conn_id))
{
_loop->TimerCancel(_conn_id);
}
}
void ReleaseInLoop()// 实际的连接释放接口
{
_statu = DISCONNECTED;
_channel.Remove();
_socket.Close();
if(_loop->HasTimer(_conn_id)) CancelInactiveReleaseInLoop();
if(_closed_callback) _closed_callback(shared_from_this());
if(_server_closed_callback) _server_closed_callback(shared_from_this());
}
void SendInLoop(Buffer buf)// 发送数据
{
if(_statu == DISCONNECTED) return;// 连接关闭状态,不予发送数据
_out_buffer.WriteBufferAndPush(buf);
if(_channel.WriteAble() == false)// 如果Channel并没有开启写事件监听
{
_channel.EnableWrite();
}
}
void ShutdownInLoop()// 暂缓关闭连接,通常是正常关闭连接时,关闭之前需要做一些处理
{
_statu = DISCONNECTING;
if(_in_buffer.ReadAbleSize() > 0)// 如果输入缓冲区还有数据
{
if(_message_callback) _message_callback(shared_from_this(),&_in_buffer);
}
if(_out_buffer.ReadAbleSize() > 0)// 如果输出缓冲区还有数据
{
if(_channel.WriteAble() == false)
{
_channel.EnableWrite();
}
}
if(_out_buffer.ReadAbleSize() == 0)// 数据全部发送完毕了,则关闭连接
{
Release();
}
}
void EnableInactiveReleaseInLoop(int sec)// 启动非活跃连接定时销毁
{
_enable_inactive_release = true;
if(_loop->HasTimer(_conn_id))// 如果已经存在了,就只是刷新一下定时器
{
return _loop->TimerRefresh(_conn_id);
}
_loop->TimerAdd(_conn_id,sec,std::bind(&Connection::Release,this));// 添加定时器,并设置定时销毁任务
}
/*切换协议上下文*/
void UpgradeInLoop(const Any &context,
const ConnectedCallback &conn,
const MessageCallback &msg,
const ClosedCallback &closed,
const AnyEventCallback &event)
{
_context = context;
_connected_callback = conn;
_message_callback = msg;
_closed_callback = closed;
_event_callback = event;
}
public:
Connection(EventLoop *loop,uint64_t conn_id,int sockfd)
:_conn_id(conn_id),_sockfd(sockfd),_enable_inactive_release(false),
_loop(loop),_statu(CONNECTING),_socket(_sockfd),_channel(loop,_sockfd)
{
_channel.SetCloseCallback(std::bind(&Connection::HandleClose,this));
_channel.SetEventCallback(std::bind(&Connection::HandleEvent,this));
_channel.SetReadCallback(std::bind(&Connection::HandelRead,this));
_channel.SetWriteCallback(std::bind(&Connection::HandleWrite,this));
_channel.SetErrorCallback(std::bind(&Connection::HandleError,this));
}
int GetFd() {return _sockfd;}
int GetId() {return _conn_id;}
bool Connected() {return _statu == CONNECTED;}// 判断当前连接是否处于已连接状态
void SetContext(const Any &context) {_context = context;}// 设置协议上下文
Any *GetContext() {return &_context;}
void SetConnectedCallback(const ConnectedCallback &cb) {_connected_callback = cb;}
void SetMessgageCallback(const MessageCallback &cb) {_message_callback = cb;}
void SetClosedCallback(const ClosedCallback &cb) {_closed_callback = cb;}
void SetAnyEventCallback(const AnyEventCallback &cb) {_event_callback = cb;}
void SetServerClosedCallback(const ClosedCallback &cb) {_server_closed_callback = cb;}
void Established()// 连接建立之初要进行一些初始化设置
{
_loop->RunInLoop(std::bind(&Connection::EstablishedInLoop,this));
}
void Send(const char *data,size_t len)
{
Buffer buf;
buf.WriteAndPush(data,len);
_loop->RunInLoop(std::bind(&Connection::SendInLoop,this,buf));
}
void Shutdown()// 连接正常断开时,释放连接之前要处理一些工作
{
_loop->RunInLoop(std::bind(&Connection::ShutdownInLoop,this));
}
void Release()
{
// 任何情况下直接释放连接的操作都应该是最低优先级,即无论什么情况下都应该放在最后执行,即放入任务队列
// 比方说,abcd四个连接,所有连接都设置了30s非活跃定时销毁,如果a的业务处理了40s,恰好b又是定时器任务
// 那么处理b事件的时候必定会释放后续的所有连接(因为都超时了嘛),但是c和d不知道自己被释放了,继续处理任务,就会导致服务器崩溃
// 所以不能这么干,必须让b放到最后执行
_loop->QueueInLoop(std::bind(&Connection::ReleaseInLoop,this));
}
void EnableInactiveRelease(int sec)
{
_loop->RunInLoop(std::bind(&Connection::EnableInactiveReleaseInLoop,this,sec));
}
void Upgrade(const Any &context,
const ConnectedCallback &conn,
const MessageCallback &msg,
const ClosedCallback &closed,
const AnyEventCallback &event)
{
_loop->AssertInLoop();// 切换的任务必须在构造线程立即执行,否则后续的处理可能还是以前的协议
_loop->RunInLoop(std::bind(&Connection::UpgradeInLoop,this,context,conn,msg,closed,event));
}
private:
uint64_t _conn_id;// 标识符,还可以用来作为定时器的id
int _sockfd;// 连接的套接字
bool _enable_inactive_release;// 是否启动非活跃连接定时断开
EventLoop *_loop;// 连接所关联的EventLoop,关联了EventLoop就说明关联了某个线程
ConnStatu _statu;// 当前连接的状态
Socket _socket;// 套接字的管理
Channel _channel;// 套接字的事件管理
Buffer _in_buffer;// 输入缓冲区,存放从TCP读取到数据
Buffer _out_buffer;// 输出缓冲区,存放要发送给对端的数据
Any _context;// 协议上下文
ConnectedCallback _connected_callback;
MessageCallback _message_callback;
ClosedCallback _closed_callback;
AnyEventCallback _event_callback;
/*Connection模块还需要被其他模块所管理,该回调函数的功能与TimerTask的Release类似*/
ClosedCallback _server_closed_callback;
};
Connection模块实现的代码较多,但是并不复杂。
值得强调的是,对连接的操作,例如定时器的增加、刷新,或者是增加、刷新事件的监听还有连接断开等等,都应该保证他们的线程安全。具体方法已经在介绍EventLoop模块时说过了。
组件使用者在操作Connection时必须使用智能指针,因为智能只能能够探测指向的对象是否存在。如果不用智能指针,组件使用者非常有可能操作一个已经销毁了的连接对象。
2.1.15Acceptor模块
Acceptor模块是直接将监听套接字给封装了起来,这样做的话,组件使用者也不需要关心监听套接字的实现了。
Acceptor模块封装监听套接字和其事件,还有其对应的主线程的事件循环(EventLoop),还有监听套接字上有可用连接时的回调函数。
Acceptor的代码实现:
class Acceptor
{
private:
using AcceptCallback = std::function<void(int)>;
int CreateServer(int port)// 监听套接字
{
bool ret = _socket.CreateServer(port);
if(ret == false)
{
ERROR_LOG("ACCEPTOR CREATE SERVER ERROR");
abort();
}
return _socket.GetFd();
}
void HandleRead()// 读事件触发后的回调
{
int connfd = _socket.Accept();
if(connfd < 0) return;
if(_accept_callback) _accept_callback(connfd);
}
public:
Acceptor(EventLoop *loop,int port)
:_socket(CreateServer(port)),_loop(loop),_channel(loop,_socket.GetFd())
{
_channel.SetReadCallback(std::bind(&Acceptor::HandleRead,this));
// 构造函数当中不能直接启动读事件监听,因为此时回调函数还没有设置
// 如果立即有事件触发,就不会调用回调函数,则这个连接得不到处理,从而造成资源泄露
}
void SetAcceptCallback(const AcceptCallback &cb) {_accept_callback = cb;}
void Listen() {_channel.EnableRead();}// 启动监听
private:
Socket _socket;// 用于创建监听套接字
EventLoop *_loop;
Channel _channel;
AcceptCallback _accept_callback;
};
2.1.16TcpServer模块
TcpServer模块是整个服务器的最后一个模块,也是对所有模块进行一次整体封装的模块。
组件使用者仅仅需要使用该模块,就可以完成对连接的所有操作。
TcpServer模块代码实现:
class TcpServer
{
private:
using ConnectedCallback = std::function<void(const PtrConnection &)>;// 连接建立成功后的回调函数
using MessageCallback = std::function<void(const PtrConnection &,Buffer *)>;// 消息到来后的回调函数
using ClosedCallback = std::function<void(const PtrConnection &)>;// 连接关闭之后的回调函数
using AnyEventCallback = std::function<void(const PtrConnection &)>;// 连接的任意事件触发后的回调函数
using Functor = std::function<void()>;
void NewConnection(int fd)// 监听套接字可读事件触发后的回调函数,功能就是封装出一个Connection
{
_next_id++;
PtrConnection conn(new Connection(_pool.NextLoop(),_next_id,fd));
conn->SetMessgageCallback(_message_callback);
conn->SetClosedCallback(_closed_callback);
conn->SetConnectedCallback(_connected_callback);
conn->SetAnyEventCallback(_event_callback);
conn->SetServerClosedCallback(std::bind(&TcpServer::RemoveConnection,this,std::placeholders::_1));
if(_enable_inactive_release == true) conn->EnableInactiveRelease(_timeout);// 如果启动了非活跃连接定时销毁
conn->Established();
_conns.insert(std::make_pair(_next_id,conn));
}
void RemoveConnectionInLoop(const PtrConnection &conn)// 删除对某个Connection的管理
{
int id = conn->GetId();
auto it = _conns.find(id);
if(it != _conns.end())
{
_conns.erase(it);
}
}
void RemoveConnection(const PtrConnection &conn)
{
_baseloop.RunInLoop(std::bind(&TcpServer::RemoveConnectionInLoop,this,conn));
}
void RunAfterInLoop(const Functor &task,int delay)
{
_next_id++;
_baseloop.TimerAdd(_next_id,delay,task);
}
public:
TcpServer(int port)
:_port(port),_next_id(0),_enable_inactive_release(false),
_acceptor(&_baseloop,port),_pool(&_baseloop)
{
_acceptor.SetAcceptCallback(std::bind(&TcpServer::NewConnection,this,std::placeholders::_1));
_acceptor.Listen();// 启动监听
}
void SetThreadCount(int count) {_pool.SetThreadCount(count);}// 设置线程数量
void SetConnectedCallback(const ConnectedCallback &cb) {_connected_callback = cb;}
void SetMessgageCallback(const MessageCallback &cb) {_message_callback = cb;}
void SetClosedCallback(const ClosedCallback &cb) {_closed_callback = cb;}
void SetAnyEventCallback(const AnyEventCallback &cb) {_event_callback = cb;}
void EnableInactiveRelease(int timeout)// 启动非活跃连接定时删除
{
_timeout = timeout;
_enable_inactive_release = true;
}
void RunAfter(const Functor &task,int delay)// 添加定时时间
{
_baseloop.RunInLoop(std::bind(&TcpServer::RunAfterInLoop,this,task,delay));
}
void Start()
{
_pool.Create();// 启动线程池
_baseloop.Start();// 主线程EventLoop启动,服务器正式启动
}
private:
uint64_t _next_id;// 自动增长的连接id
int _port;// 端口号
int _timeout;// 定义多久没有事件触发就是非活跃连接
bool _enable_inactive_release;// 是否启动非活跃连接定时销毁
EventLoop _baseloop;// 主线程的EventLoop
Acceptor _acceptor;// 监听套接字
LoopThreadPool _pool;// 线程池
std::unordered_map<uint64_t,PtrConnection> _conns;// 保存、管理所有的Connection
ConnectedCallback _connected_callback;
MessageCallback _message_callback;
ClosedCallback _closed_callback;
AnyEventCallback _event_callback;
};
至此,网络库组件全部写完,组件使用者只需要使用TcpServer模块就可以完成服务器的搭建。
2.1.17细节补充
在通信的过程当中,难免会想已经关闭的、或者不存在的套接字写入信息。但是这类操作并不足以导致服务器崩溃,所以还需要将管道错误信号设置为忽略。
class NetWork
{
public:
NetWork()
{
DEBUG_LOG("SIGPIPE INIT!");
signal(SIGPIPE,SIG_IGN);
}
};
static NetWork nw;// 包含"Server.hpp"头文件时,该对象自动创建,创建之后就设置了对SIGPIPE信号的忽略
2.1.18整合测试3
网络库组件部分已经全部写完,接下来看看要多少行代码就可以搭建出一个Echo服务器。
void ConnectedHandle(const PtrConnection &conn)
{
DEBUG_LOG("%d号连接已经成功建立!",conn->GetFd());
}
void MessageHandle(const PtrConnection &conn,Buffer *buf)
{
std::string str = buf->ReadAsStringAndPop(buf->ReadAbleSize());
DEBUG_LOG("接收到来自%d号连接的数据: %s",conn->GetFd(),str.c_str());
conn->Send(str.c_str(),str.size());
DEBUG_LOG("回显数据: %s",str.c_str());
}
void AnyHandle(const PtrConnection &conn)
{
DEBUG_LOG("%d号连接有事件触发",conn->GetFd());
}
void CloseHandle(const PtrConnection &conn)
{
DEBUG_LOG("%d号连接断开!",conn->GetFd());
}
int main()
{
TcpServer server(9090);
server.EnableInactiveRelease(10);// 10s没有事件触发就销毁连接
server.SetThreadCount(2);// 2个从属线程
server.SetConnectedCallback(std::bind(ConnectedHandle,std::placeholders::_1));
server.SetMessgageCallback(std::bind(MessageHandle,std::placeholders::_1,std::placeholders::_2));
server.SetClosedCallback(std::bind(CloseHandle,std::placeholders::_1));
server.SetAnyEventCallback(std::bind(AnyHandle,std::placeholders::_1));
server.Start();
return 0;
}
运行截图就不放出来了,大家可以自行测试。
接下来是压力测试,利用到一个名为"Webbench"的软件。它可以模拟多个客户端不断地向服务器发送请求。虽然当前实现的服务器还没有支持HTTP协议,但是接收请求没有问题。
测试环境在1核2G带宽为1M的云服务器下测试(不在本地测试),模拟的客户端为1000个:

当然这里的测试并没有什么实际意义,HTTP模块实现之后将会在虚拟机环境下进行压力测试。
2.2HTTP协议模块开发
在网络库组件的"Connection"类中,预留了一个Any类对象,这就使得在此网络组建之上搭建webserver服务器显得很容易,搭建的过程当中只需要关注HTTP协议本身的处理就好了。
HTTP模块的实现放在一个名为Http.hpp的头文件下。
2.2.1响应状态码和状态描述、文件后缀和mime的实现
HTTP协议当中有两个重要信息,即响应当中的响应状态码和状态描述,例如200对应OK;还有就是文件名后缀对应的mime,例如".html"文件对应的mime为"text/html"。
他们是一一对应的关系,即Key-Val关系,所以可以使用哈希表来进行管理:
std::unordered_map<int, std::string> _statu_msg = {
{100, "Continue"},
{101, "Switching Protocol"},
{102, "Processing"},
{103, "Early Hints"},
{200, "OK"},
{201, "Created"},
{202, "Accepted"},
{203, "Non-Authoritative Information"},
{204, "No Content"},
{205, "Reset Content"},
{206, "Partial Content"},
{207, "Multi-Status"},
{208, "Already Reported"},
{226, "IM Used"},
{300, "Multiple Choice"},
{301, "Moved Permanently"},
{302, "Found"},
{303, "See Other"},
{304, "Not Modified"},
{305, "Use Proxy"},
{306, "unused"},
{307, "Temporary Redirect"},
{308, "Permanent Redirect"},
{400, "Bad Request"},
{401, "Unauthorized"},
{402, "Payment Required"},
{403, "Forbidden"},
{404, "Not Found"},
{405, "Method Not Allowed"},
{406, "Not Acceptable"},
{407, "Proxy Authentication Required"},
{408, "Request Timeout"},
{409, "Conflict"},
{410, "Gone"},
{411, "Length Required"},
{412, "Precondition Failed"},
{413, "Payload Too Large"},
{414, "URI Too Long"},
{415, "Unsupported Media Type"},
{416, "Range Not Satisfiable"},
{417, "Expectation Failed"},
{418, "I'm a teapot"},
{421, "Misdirected Request"},
{422, "Unprocessable Entity"},
{423, "Locked"},
{424, "Failed Dependency"},
{425, "Too Early"},
{426, "Upgrade Required"},
{428, "Precondition Required"},
{429, "Too Many Requests"},
{431, "Request Header Fields Too Large"},
{451, "Unavailable For Legal Reasons"},
{501, "Not Implemented"},
{502, "Bad Gateway"},
{503, "Service Unavailable"},
{504, "Gateway Timeout"},
{505, "HTTP Version Not Supported"},
{506, "Variant Also Negotiates"},
{507, "Insufficient Storage"},
{508, "Loop Detected"},
{510, "Not Extended"},
{511, "Network Authentication Required"}
};
std::unordered_map<std::string, std::string> _mime_msg = {
{".aac", "audio/aac"},
{".abw", "application/x-abiword"},
{".arc", "application/x-freearc"},
{".avi", "video/x-msvideo"},
{".azw", "application/vnd.amazon.ebook"},
{".bin", "application/octet-stream"},
{".bmp", "image/bmp"},
{".bz", "application/x-bzip"},
{".bz2", "application/x-bzip2"},
{".csh", "application/x-csh"},
{".css", "text/css"},
{".csv", "text/csv"},
{".doc", "application/msword"},
{".docx", "application/vnd.openxmlformats-officedocument.wordprocessingml.document"},
{".eot", "application/vnd.ms-fontobject"},
{".epub", "application/epub+zip"},
{".gif", "image/gif"},
{".htm", "text/html"},
{".html", "text/html"},
{".ico", "image/vnd.microsoft.icon"},
{".ics", "text/calendar"},
{".jar", "application/java-archive"},
{".jpeg", "image/jpeg"},
{".jpg", "image/jpeg"},
{".js", "text/javascript"},
{".json", "application/json"},
{".jsonld", "application/ld+json"},
{".mid", "audio/midi"},
{".midi", "audio/x-midi"},
{".mjs", "text/javascript"},
{".mp3", "audio/mpeg"},
{".mpeg", "video/mpeg"},
{".mpkg", "application/vnd.apple.installer+xml"},
{".odp", "application/vnd.oasis.opendocument.presentation"},
{".ods", "application/vnd.oasis.opendocument.spreadsheet"},
{".odt", "application/vnd.oasis.opendocument.text"},
{".oga", "audio/ogg"},
{".ogv", "video/ogg"},
{".ogx", "application/ogg"},
{".otf", "font/otf"},
{".png", "image/png"},
{".pdf", "application/pdf"},
{".ppt", "application/vnd.ms-powerpoint"},
{".pptx", "application/vnd.openxmlformats-officedocument.presentationml.presentation"},
{".rar", "application/x-rar-compressed"},
{".rtf", "application/rtf"},
{".sh", "application/x-sh"},
{".svg", "image/svg+xml"},
{".swf", "application/x-shockwave-flash"},
{".tar", "application/x-tar"},
{".tif", "image/tiff"},
{".tiff", "image/tiff"},
{".ttf", "font/ttf"},
{".txt", "text/plain"},
{".vsd", "application/vnd.visio"},
{".wav", "audio/wav"},
{".weba", "audio/webm"},
{".webm", "video/webm"},
{".webp", "image/webp"},
{".woff", "font/woff"},
{".woff2", "font/woff2"},
{".xhtml", "application/xhtml+xml"},
{".xls", "application/vnd.ms-excel"},
{".xlsx", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"},
{".xml", "application/xml"},
{".xul", "application/vnd.mozilla.xul+xml"},
{".zip", "application/zip"},
{".3gp", "video/3gpp"},
{".3g2", "video/3gpp2"},
{".7z", "application/x-7z-compressed"}
};
2.2.2Util工具类的实现
工具类通常实现一些各个模块都会经常使用的小功能函数。本项目实现的HTTP模块中,会经常用到如下几个操作:
1.字符串分割提取
2.读取文件内容
3.向文件写入数据
4.URL编码
5.URL解码
6.获取响应状态码对应的状态信息
7.获取文件后缀名对应的mime
8.判断一个文件是否是目录
9.判断一个文件是否是普通文件
10.判断一个路径是否是合法路径
每个功能实现的都很简单,但是十个函数组合在一起就显得有点多了。
Utili工具类的代码实现:
class Util
{
public:
// 字符串分割,给定字符串src,在其当中以sep进行分割,分割出来的字符串放入array中
static size_t Split(const std::string &src,const std::string &sep,std::vector<std::string> *array)
{
size_t offset = 0;
while(offset < src.size())
{
size_t pos = src.find(sep,offset);// 从offset处开始向后查找sep
if(pos == std::string::npos)// 没有找到sep
{
array->push_back(src.substr(offset));// 从offset开始作为一个整体放入array
return array->size();
}
if(pos == offset)// offset指向的位置就是sep的起始位置
{
offset = pos + sep.size();
continue;// 跳过
}
array->push_back(src.substr(offset,pos - offset));
offset = pos + sep.size();
}
return array->size();
}
static bool ReadFile(const std::string &filename,std::string *buf)// 读取文件数据
{
std::ifstream ifs(filename,std::ios::binary);
if(ifs.is_open() == false)
{
DEBUG_LOG("OPEN FILE ERROR: %s",filename.c_str());
return false;
}
size_t fsize = 0;
ifs.seekg(0,ifs.end);// 偏移到文件末尾
fsize = ifs.tellg();// 计算文件大小
ifs.seekg(0,ifs.beg);// 便宜到文件起始
buf->resize(fsize);
ifs.read(&(*buf)[0],fsize);
if(ifs.good() == false)
{
DEBUG_LOG("READ FILE ERROR: %s",filename.c_str());
ifs.close();
return false;
}
ifs.close();
return false;
}
static bool WriteFile(const std::string &filename,const std::string &buf)// 向文件写入数据
{
std::ofstream ofs(filename,std::ios::binary | std::ios::trunc);// 覆盖式写入
if(ofs.is_open() == false)
{
DEBUG_LOG("OPEN FILE ERROR: %s",filename.c_str());
return false;
}
ofs.write(buf.c_str(),buf.size());
if(ofs.good() == false)
{
DEBUG_LOG("READ FILE ERROR: %s",filename.c_str());
ofs.close();
return false;
}
ofs.close();
return true;
}
// URL编码,bool类型参数意思为是否要将空格转换成加号
static std::string UrlEncode(const std::string &url,bool conver_space_to_plus)
{
std::string res;
for(auto &c:url)
{
if(c == '.' || c == '-' || c == '_' || c == '~' || isalnum(c))// 这些都是绝对不编码的
{
res += c;
continue;
}
if(c == ' ' && conver_space_to_plus == true)// 如果设置了空格转换成加号(这个情况发生在URL的查询字符串中)
{
res += '+';
continue;
}
// 剩下的字符都要编码,编码的格式的为"%HH",H代码一个十六进制数
char tmp[4] = {0};
snprintf(tmp,4,"%%%02X",c);
res += tmp;
}
return res;
}
static std::string UrlDecode(const std::string &url,bool conver_plus_to_space)// URL解码
{
std::string res;
for(int i=0;i<url.size();i++)
{
if(url[i] == '+' && conver_plus_to_space == true)// 如果加号要转换成空格
{
res += ' ';
continue;
}
if(url[i] == '%' && (i + 2) < url.size())
{
char v1 = HEXTOI(url[i + 1]);
char v2 = HEXTOI(url[i + 2]);
char v = v1 * 16 + v2;
res += v;
i += 2;
continue;
}
res += url[i];
}
return res;
}
static char HEXTOI(char c)// 将十六进制的数转换为十进制的字符
{
if(c >= '0' && c <= '9')
return c - '0';// c就是一个十进制的字符
if(c >= 'a' && c <= 'z')
return c - 'a' + 10;// 假设c='a',c - 'a' = 1,但是'a'对应的十进制为11,所以要+10
if(c >= 'A' && c <= 'Z')
return c - 'A' + 10;
return -1;
}
static std::string StatuDesc(int statu)// 根据响应状态码获取响应描述
{
auto it = _statu_msg.find(statu);
if(it != _statu_msg.end())
{
return it->second;
}
return "Unknow";
}
static std::string ExtMime(const std::string &filename)// 根据文件名后缀获取对应的mime
{
size_t pos = filename.find_last_of('.');
if(pos == std::string::npos)
{
return "application/ectet-stream";// 没有找到'.',就是二进制流
}
std::string ext = filename.substr(pos);
auto it = _mime_msg.find(ext);
if(it == _mime_msg.end())// 如果并没有后缀名对应的mime
{
return "application/ectet-stream";
}
return it->second;
}
static bool IsDirectory(const std::string &filename)// 判断一个文件是否是目录
{
struct stat st;
int ret = stat(filename.c_str(),&st);
if(ret < 0)
{
return false;
}
return S_ISDIR(st.st_mode);
}
static bool IsRegular(const std::string &filename)// 判断一个文件是否是一个普通文件
{
struct stat st;
int ret = stat(filename.c_str(),&st);
if(ret < 0)
{
return false;
}
return S_ISREG(st.st_mode);
}
static bool ValidPath(const std::string &path)// 判断一个路径是否是合法路径
{
// 规定:只能获取"Http.hpp"所属的目录以及更深层的目录中的资源
std::vector<std::string> subdir;
Split(path,"/",&subdir);// 以"/"分割字符串
int level = 0;// 计算层数
for(auto &dir:subdir)
{
if(dir == "..")// 如果碰到了要返回上层目录
{
--level;
if(level < 0) return false;// 如果已经返回到了当前目录的山一层目录
continue;
}
++level;
}
return true;
}
};
2.2.3HttpRequest模块
HttpRequest模块会将HTTP协议的请求部分封装起来,它包含请求方法、资源路径、协议版本等等信息。具体的解析工作并不由该模块处理。
HttpRequst模块代码实现:
class HttpRequest
{
public:
std::string _method;// 请求方法
std::string _path;// 资源路径
std::string _version;// 协议版本
std::string _body;// 请求正文
std::smatch _mathes;// 资源路径的正则提取数据
std::unordered_map<std::string,std::string> _headers;// 头部字段,例如Content-Legth: 100,Content-Length作为key,100作为val
std::unordered_map<std::string,std::string> _params;// 查询字符串,例如user=xxx,user作为key,xxx作为val
public:
HttpRequest()
:_version("HTTP/1.1")// 默认协议版本
{}
void Reset()// 重置
{
_method.clear();
_path.clear();
_version = "HTTP/1.1";
_body.clear();
std::smatch match;
_mathes.swap(match);
_headers.clear();
_params.clear();
}
void SetHeader(const std::string &key,const std::string &val)// 插入头部字段
{
_headers.insert(std::make_pair(key,val));
}
bool HasHeader(const std::string &key) const// 判断是否存在指定的头部字段
{
auto it = _headers.find(key);
if(it == _headers.end())
{
return false;
}
return true;
}
std::string GetHeader(const std::string &key) const// 获取头部字段
{
auto it = _headers.find(key);
if(it == _headers.end())
{
return "";
}
return it->second;
}
void SetParam(const std::string &key,const std::string &val)// 插入查询字符串
{
_params.insert(std::make_pair(key,val));
}
bool HasParam(const std::string &key) const// 判断是否有指定的查询字符串
{
auto it = _params.find(key);
if(it == _params.end())
{
return false;
}
return true;
}
std::string GetParam(const std::string &key) const// 获取指定的查询字符串
{
auto it = _params.find(key);
if(it == _params.end())
{
return "";
}
return it->second;
}
size_t ContentLength() const// 获取请求的正文长度
{
bool ret = HasHeader("Content-Length");
if(ret == false)
{
return 0;
}
std::string clen = GetHeader("Content-Length");
return std::stol(clen);
}
bool Close() const// 判断这个请求是不是短连接请求
{
if(HasHeader("Connection") == true && GetHeader("Connection") == "keep-alive")
{
return false;// 如果存在长连接字段,那么就不是短连接
}
return true;
}
};
注意到这些接口都是公有接口,他们都要被其他模块直接使用。
2.2.4HttpResponse模块
入HttpRequest模块一样,HttpResponse模块封装HTTP响应的必要信息,例如状态码、是否重定向、响应正文等等内容。但是HttpResponse并不是对响应进行解析、设置的模块,它只是保存响应的必要信息,具体的解析、设置功能在其他模块当中。
HttpResponse模块代码实现:
class HttpResponse
{
public:
/*HTTP协议版本在请求当中有,不需要进行设置*/
int _statu;// 响应状态码
bool _redirect_flag;// 是否重定向
std::string _body;// 响应正文
std::string _redirect_url;// 重定向后的url
std::unordered_map<std::string,std::string> _headers;// 头部字段
public:
HttpResponse()
:_redirect_flag(false),_statu(200)// 默认情况下,不启动重定向并且响应状态为OK
{}
HttpResponse(int statu)
:_redirect_flag(false),_statu(statu)
{}
void Reset()// 重置
{
_statu = 200;
_redirect_flag = false;
_body.clear();
_redirect_url.clear();
_headers.clear();
}
void SetHeader(const std::string &key,const std::string &val)// 插入头部字段
{
_headers.insert(std::make_pair(key,val));
}
bool HasHeader(const std::string &key)// 是否存在指定的头部
{
auto it = _headers.find(key);
if(it == _headers.end())
{
return false;
}
return true;
}
std::string GetHeader(const std::string &key)// 获取指定的头部字段
{
auto it = _headers.find(key);
if(it == _headers.end())
{
return "";
}
return it->second;
}
// 设置响应正文,设置响应正文时,必须顺带设置响应正文的类型
void SetContent(const std::string &body,const std::string &type = "text/html")
{
_body = body;
SetHeader("Content-Type",type);
}
void SetRedirect(const std::string &url,int statu = 302)// 设置重定向的url,默认为临时重定向
{
_statu = statu;
_redirect_flag = true;
_redirect_url = url;
}
bool Close()// 判断这个响应是不是短连接请响应
{
if(HasHeader("Connection") == true && GetHeader("Connection") == "keep-alive")
{
return false;// 如果存在长连接字段,那么就不是短连接
}
return true;
}
};
这里稍微说明一下HTTP重定向。通俗的来说,就是客户端请求一个A网页时,可能处于维护者的角度考虑,A网页的资源需要迁移到B网页,那么直接禁用A网页的服务是不可取的,所以采用重定向的方式。即,A网页依然可以正常请求,但是服务器会响应一个重定向状态码(常见的为301永久重定向、302临时重定向)并且响应一个B网页的URL。客户端接收到该响应之后,会自动给网页B发送请求并跳转到网页B。
2.2.5HttpContext模块
HttpContext模块是HTTP请求或响应的上下文模块,其中涉及到HTTP请求的读取和解析,并且对HttpRequest进行设置。
解析的过程利用正则表达式进行解析。
HttpContext模块的代码实现:
typedef enum
{
RECV_HTTP_ERROR,// 接收过程中发生错误
RECV_HTTP_LINE,// 接收请求行
RECV_HTTP_HEAD,// 接收请求头部
RECV_HTTP_BODY,// 接收请求正文
RECV_HTTP_OVER// 接收结束
}HttpRecvStatu;
#define MAX_LINE 8192// 一行数据的最大长度
class HttpContext
{
private:
bool RecvHttpLine(Buffer *buf)// 接收HTTP请求的请求行
{
if(_recv_statu != RECV_HTTP_LINE) return false;// 状态不符
std::string line = buf->GetLineAndPop();// 从Buffer中获取一行数据
if(line.size() == 0)// 如果并没有读取到一行完整的数据
{
if(buf->ReadAbleSize() > MAX_LINE)// 如果缓冲区的可读数据已经超过了单行的最大长度还不足一行,就说明出问题了
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;// URI TOO LONG
return false;
}
return true;// 否则就是Buffer当中真的没有一行完整的数据,下一次进来再接收
}
if(line.size() > MAX_LINE)// 如果接收到一行数据大于最大单行数据的长度,也是有问题的
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;
return false;
}
bool ret = ParseHttpLine(line);// 读取到了完整的一行请求行,进行解析
if(ret == false)
{
return false;
}
_recv_statu = RECV_HTTP_HEAD;// 请求行处理完毕,可以接收请求头部
return true;
}
bool ParseHttpLine(const std::string &line)
{
std::smatch matches;
std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?",std::regex::icase);
bool ret = std::regex_match(line,matches,e);// 匹配的结果放到matches当中去
if(ret == false)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400;// 给的请求有问题
return false;
}
_request._method = matches[1];// 获得请求方法
// [begin(),end()]范围内的所有字符都转换成大写
std::transform(_request._method.begin(),_request._method.end(),_request._method.begin(),::toupper);
_request._path = Util::UrlDecode(matches[2],false);// 进行URL解码
_request._version = matches[4];// HTTP协议版本
// 处理查询字符串
std::vector<std::string> query_string_array;
std::string query_string = matches[3];
Util::Split(query_string,"&",&query_string_array);// 进行字符串分割解析
for(auto &str:query_string_array)
{
size_t pos = str.find("=");
if(pos == std::string::npos)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400;// 解析失败,说明URL的查询字符串格式有问题
return false;
}
std::string key = Util::UrlDecode(str.substr(0,pos),true);
std::string val = Util::UrlDecode(str.substr(pos + 1),true);
_request.SetParam(key,val);
}
return true;
}
bool RecvHttpHead(Buffer *buf)// 接收HTTP请求头部
{
if(_recv_statu != RECV_HTTP_HEAD) return false;
while(true)
{
std::string line = buf->GetLineAndPop();
if(line.size() == 0)
{
if(buf->ReadAbleSize() > MAX_LINE)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;
return false;
}
return true;
}
if(line.size() > MAX_LINE)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;
return false;
}
if(line == "\n" || line == "\r\n") break;// 读取到了空行就结束头部读取
bool ret = ParseHttpHead(line);// 读取到一行头部,就进行一行头部的解析
if(ret == false)
{
return false;
}
}
_recv_statu = RECV_HTTP_BODY;
return true;
}
bool ParseHttpHead(std::string &line)// 解析每一行的HTTP请求头部
{
if(line.back() == '\n') line.pop_back();
if(line.back() == '\r') line.pop_back();
size_t pos = line.find(": ");
if(pos == std::string::npos)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400;
return false;
}
std::string key = line.substr(0,pos);
std::string val = line.substr(pos + 2);
_request.SetHeader(key,val);
return true;
}
bool RecvHttpBody(Buffer *buf)// 读取HTTP请求正文
{
if(_recv_statu != RECV_HTTP_BODY) return false;
size_t content_length = _request.ContentLength();// 先确定请求正文有多少长度'
if(content_length == 0)
{
_recv_statu = RECV_HTTP_OVER;// 没有正文就直接接收请求完毕了
return true;
}
size_t real_len = content_length - _request._body.size();// 还要读取多少长度的数据
if(buf->ReadAbleSize() >= real_len)// 如果缓冲区的数据大小足够
{
_request._body.append(buf->ReadPosition(),real_len);
buf->OffsetReader(real_len);
_recv_statu = RECV_HTTP_OVER;
return true;
}
// 到这里就是缓冲区的数据不够real_len,还要进行下一次读取,所以状态没有发生改变
_request._body.append(buf->ReadPosition(),buf->ReadAbleSize());
buf->OffsetReader(buf->ReadAbleSize());
return true;
}
public:
HttpContext()
:_resp_statu(200),_recv_statu(RECV_HTTP_LINE)// 默认情况下响应状态码200,从请求行开始接收
{}
void Reset()
{
_resp_statu = 200;
_recv_statu = RECV_HTTP_LINE;
_request.Reset();
}
int RespStatu() {return _resp_statu;}// 返回响应状态码
HttpRecvStatu RecvStatu() {return _recv_statu;}// 获取当前的读取状态
HttpRequest &GetRequest() {return _request;}// 获取设置好的请求对象
// 接收解析HTTP请求
void RecvHttpRequest(Buffer *buf)// 接受到的请求信息会放在Buffer当中
{
// 根据不同的状态做不同的事情,实际上就是一个状态机
switch(_recv_statu)
{
case RECV_HTTP_LINE :RecvHttpLine(buf);
case RECV_HTTP_HEAD :RecvHttpHead(buf);
case RECV_HTTP_BODY :RecvHttpBody(buf);
}
}
private:
int _resp_statu;// 响应状态码,因为接收、解析过程中会出错,出错就要设置响应状态码
HttpRecvStatu _recv_statu;// 当前读取到哪个阶段了
HttpRequest _request;// HTTP请求对象
};
HttpContext模块的逻辑稍微有一些复杂,但是它的整体功能就如前面所说:对HTTP请求进行接收和解析,在此过程当中完善HttpRequest的设置。
接下来分析一下这段代码:
std::regex e("(GET|HEAD|POST|PUT|DELET) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?",std::regex::icase);
这是利用了C++11的正则库,为了匹配HTTP请求行而设计的正则表达式对象。它的解析是这样的:
1.(GET|HEAD|POST|PUT|DELET):表示一个括号分组,匹配其中的任意一个字符串,这些字符串是HTTP请求行中的请求方法(GET、HEAD、POST、PUT、DELETE)当中的任意一个字符串
2.([^?]):表示一个括号分组,匹配除了问号(?)之外的任意字符,这代表请求行中的请求路径部分
3.(?:\\?(.*))?:表示一个可选的括号分组,匹配一个问号(?)后面的任意字符,即查询参数部分。由于使用了 (?: ) 的非捕获分组语法,所以此部分的匹配结果不会作为结果的子匹配返回
4.(HTTP/1\\.[01]):表示匹配字符串 “HTTP/1.0” 或 “HTTP/1.1”,这是HTTP请求行中的HTTP协议版本部分
5.(?:\n|\r\n)?:表示一个可选的非捕获括号分组,匹配一个换行符 \n 或者回车换行符 \r\n。此部分是用于处理不同操作系统中换行符的差异
那么1就是匹配了请求方法、2就是匹配了请求路径、3就是匹配了查询字符串、4就是匹配了HTTP协议版本、5就是匹配了换行,表示结束匹配当前行。
2.2.6HttpServer模块
HttpSerer模块是HTTP协议部分的最后一个模块。它相当于封装了TcpServer而搭建出的一个webserver服务器,当然,它会用到之前实现的所有模块,其中就包括了HttpResponse对象的设置。
HttpServer模块的代码实现:
#define DEFAULT_TIMEOUT 120// 默认定时时间,120s
class HttpServer
{
private:
using Handler = std::function<void(const HttpRequest &,HttpResponse *)>;// 回调函数
using Handlers = std::vector<std::pair<std::regex,Handler>>;// 保存Handler的容器
void OnConnected(const PtrConnection &conn)// 连接建立成功后的回调函数
{
conn->SetContext(HttpContext());// 给Connection对象一个协议上下文
DEBUG_LOG("%d号连接连接成功!并且设置了上下文!",conn->GetFd());
}
void ErrorHandler(const HttpRequest &req,HttpResponse *resp)// 错误处理,响应一个HTML页面即可
{
std::string body;
body += "";
body += "";
body += "";
body += "";
body += "";
body += ""
;
body += std::to_string(resp->_statu);
body += " ";
body += Util::StatuDesc(resp->_statu);
body += "";
body += "";
body += "";
resp->SetContent(body,"text/html");// 将响应正文设置到resp中
}
void WriteResponse(const PtrConnection &conn,const HttpRequest &req,HttpResponse &resp)// 发送响应信息
{
if(req.Close() == true)// 如果是短连接,就设置短连接的头部
resp.SetHeader("Connection","close");
else // 长连接就设置长连接的头部
resp.SetHeader("Connection","keep-alive");
if(resp._body.empty() == false && resp.HasHeader("Content-Length") == false)// 如果没有正文长度字段
resp.SetHeader("Content-Length",std::to_string(resp._body.size()));
if(resp._body.empty() == false && resp.HasHeader("Content-Type") == false)// 如果没有正文类型字段
resp.SetHeader("Content-Type","application/octet-stream");
if(resp._redirect_flag == true)// 如果设置了重定向
resp.SetHeader("Location",resp._redirect_url);
// 组织响应字符串
std::string resp_str;
resp_str += req._version + " " + std::to_string(resp._statu) + " " + Util::StatuDesc(resp._statu) + "\r\n";// 响应行
for(auto &head:resp._headers)// 响应头
{
resp_str += head.first + ": " + head.second + "\r\n";
}
resp_str += "\r\n";// 空行
resp_str += resp._body;// 正文
conn->Send(resp_str.c_str(),resp_str.size());
}
bool IsFileHandler(const HttpRequest &req)// 判断一个HTTP请求是否是静态资源请求
{
if(_basedir.empty()) return false;// 如果没有设置静态资源根目录
if(req._method != "GET" && req._method != "HEAD") return false;// 如果不是GET或HEAD方法
if(Util::ValidPath(req._path) == false) return false;// 如果不是一个有效的请求路径
std::string req_path = _basedir + req._path;
if(req._path.back() == '/') req_path += "index.html";// 如果请求的资源是一个目录
if(Util::IsRegular(req_path) == false) return false;// 请求路径和静态资源根目录合并后依然不是一个合法路径
return true;
}
void FileHandler(const HttpRequest &req,HttpResponse *resp)// 处理静态资源请求
{
std::string req_path = _basedir + req._path;
if(req._path.back() == '/') req_path += "index.html";
bool ret = Util::ReadFile(req_path,&resp->_body);// 将HTTP请求当中的指定的路径中的资源读取到响应的正文当中
if(ret == false) return;
std::string mime = Util::ExtMime(req_path);// 根据请求资源的后缀名获得mime,以填充响应头部
resp->SetHeader("Content-Type",mime);
}
void Dispatcher(HttpRequest &req,HttpResponse *resp,Handlers &handlers)// 功能性请求的处理
{
// 在对应请求方法的回调函数容器中,查找是否有对应的处理函数
for(auto &handler:handlers)
{
const std::regex &re = handler.first;
const Handler &functor = handler.second;
bool ret = std::regex_match(req._path,req._mathes,re);
if(ret == false) continue;
return functor(req,resp);
}
resp->_statu = 404;
}
void Route(HttpRequest &req,HttpResponse *resp)
{
if(IsFileHandler(req) == true)
{
FileHandler(req,resp);
return;
}
// 如果不是静态资源请求,那就是有别的任务
if(req._method == "GET" || req._method == "HEAD")
return Dispatcher(req,resp,_get_route);
if(req._method == "POST")
return Dispatcher(req,resp,_post_route);
if(req._method == "PUT")
return Dispatcher(req,resp,_put_route);
if(req._method == "DELETE")
return Dispatcher(req,resp,_delete_route);
resp->_statu = 405;
}
void OnMessage(const PtrConnection &conn,Buffer *buf)
{
while(buf->ReadAbleSize() > 0)// 如果缓冲区当中的可读数据一直存在,那么就一直进行数据读取
{
HttpContext *context = conn->GetContext()->get<HttpContext>();// 获取连接的协议上下文
context->RecvHttpRequest(buf);// 从buf当中读取HTTP请求
HttpRequest &req = context->GetRequest();// 读取完毕之后,拿到请求
HttpResponse resp(context->RespStatu());// 构造出响应对象
if(context->RespStatu() >= 400)// 响应状态码是有错误的
{
ErrorHandler(req,&resp);// 返回一个错误页面
WriteResponse(conn,req,resp);// 发送响应
context->Reset();// 重置上下文
buf->OffsetReader(buf->ReadAbleSize());
conn->Shutdown();// 关闭连接
return;
}
if(context->RecvStatu() != RECV_HTTP_OVER)
{
return;// 如果HTTP请求还没有读完,说明不能处理,因为请求不完整
}
Route(req,&resp);
WriteResponse(conn,req,resp);
context->Reset();// 发送完毕之后重置上下文
if(resp.Close() == true) conn->Shutdown();
}
}
public:
HttpServer(int port,int timeout = DEFAULT_TIMEOUT)
:_server(port)
{
_server.EnableInactiveRelease(timeout);
_server.SetConnectedCallback(std::bind(&HttpServer::OnConnected,this,std::placeholders::_1));
_server.SetMessgageCallback(std::bind(&HttpServer::OnMessage,this,std::placeholders::_1,std::placeholders::_2));
}
void SetBaseDir(const std::string &path)// 设置静态资源根目录
{
if(Util::IsDirectory(path) == false) abort();// 如果设置的根目录不是一个合法的路径
_basedir = path;
}
void Get(const std::string &pattern,const Handler &handler)// 设置GET方法的回调函数
{
_get_route.push_back(std::make_pair(std::regex(pattern),handler));
}
void Post(const std::string &pattern,const Handler &handler)// 设置POST方法的回调函数
{
_post_route.push_back(std::make_pair(std::regex(pattern),handler));
}
void Put(const std::string &pattern,const Handler &handler)// 设置PUT方法的回调函数
{
_put_route.push_back(std::make_pair(std::regex(pattern),handler));
}
void Delete(const std::string &pattern,const Handler &handler)// 设置DELETE方法的回调函数
{
_delete_route.push_back(std::make_pair(std::regex(pattern),handler));
}
void SetThreadCount(int count)// 设置线程数量
{
_server.SetThreadCount(count);
}
void Start()// 启动HTTP服务器
{
_server.Start();
}
private:
Handlers _get_route;// GET方法的回调函数容器
Handlers _post_route;// POST方法的回调函数容器
Handlers _put_route;// PUT方法的回调函数容器
Handlers _delete_route;// DELETE方法的回调函数容器
std::string _basedir;// 静态资源根目录
TcpServer _server;// 网络库组件
};
这里解释一下这句代码的含义:
using Handlers = std::vector<std::pair<std::regex,Handler>>;// 保存Handler的容器
这是一个vector容器,它的元素是一个键值对,其中Key为一个正则表达式对象,Val为一个回调函数。
它在HTTP请求方法为非静态资源请求时起效果。例如客户端发起了一个登录请求,那么这个登录请求显然不是请求一个新的网页,而是通过GET或者POST方法提交一些数据。那么这个时候就需要通过回调函数来调用服务器搭建者所规定的业务处理函数。
正则表达式对象匹配的目标字符串为HTTP请求当中的资源路径,根据资源路径就可以知道客户端想要做什么,服务器搭建者就提前把这些正则表达式对象和回调方法设置在vector容器中,待服务器接收到请求之后,遍历该容器获取正确的回调函数并进行调用。
为什么使用正则表达式的原因很简单,例如有一个登录请求的资源路径为"/login/test/123.txt",那么使用正则表达式的好处就是可以直接设置匹配的字符串为"/login",这样依然能够匹配正确的回调函数。
还需要注意在HttpServer模块当中,默认添加了非活跃连接定时销毁,它的时间设置为120秒。一般的webserver服务器都设置的奥30~120秒之间。
2.2.7搭建简易的测试服务器
搭建一个建议的测试服务器,用做后续的测试。实际上也是一个Echo服务器。
#define WWWROOT "./wwwroot/"
std::string RequestStr(const HttpRequest &req) {
std::stringstream ss;
ss << req._method << " " << req._path << " " << req._version << "\r\n";
for (auto &it : req._params) {
ss << it.first << ": " << it.second << "\r\n";
}
for (auto &it : req._headers) {
ss << it.first << ": " << it.second << "\r\n";
}
ss << "\r\n";
ss << req._body;
return ss.str();
}
void Hello(const HttpRequest &req, HttpResponse *rsp)
{
rsp->SetContent(RequestStr(req), "text/plain");
}
void Login(const HttpRequest &req, HttpResponse *rsp)
{
rsp->SetContent(RequestStr(req), "text/plain");
}
void PutFile(const HttpRequest &req, HttpResponse *rsp)
{
rsp->SetContent(RequestStr(req), "text/plain");
}
void DelFile(const HttpRequest &req, HttpResponse *rsp)
{
rsp->SetContent(RequestStr(req), "text/plain");
}
int main()
{
HttpServer server(9090);
server.SetThreadCount(2);
server.SetBaseDir(WWWROOT);//设置静态资源根目录,告诉服务器有静态资源请求到来,需要到哪里去找资源文件
server.Get("/hello", Hello);
server.Post("/login", Login);
server.Put("/1234.txt", PutFile);
server.Delete("/1234.txt", DelFile);
server.Start();
return 0;
}
2.2.8整合测试4
首先测试一下长连接是否正常工作。是否正常工作的依据是持续向服务器发送数据,直到指定超时时间之后,说明长连接没问题并且定时器刷新也没有问题。
测试用例代码:
int main()
{
Socket clisock;
clisock.CreateClinet("127.0.0.1",9090);
std::string req = "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\nContent-Length: 0\r\n\r\n";
while(true)
{
assert(clisock.Send(req.c_str(),req.size()) != -1);
char buffer[1024] = {0};
clisock.Recv(buffer,sizeof(buffer) - 1);
DEBUG_LOG("[%s]",buffer);
sleep(3);
}
clisock.Close();
return 0;
}
运行截图(只截取一部分):
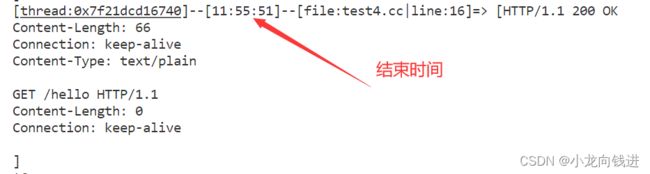
结论是长连接测试正常,定时器刷新功能正常。
2.2.9整合测试5
本次测试非活跃连接是否能正常定时关闭。
测试用例的代码为:
int main()
{
Socket clisock;
clisock.CreateClinet("127.0.0.1",9090);
std::string req = "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\nContent-Length: 0\r\n\r\n";
while(true)
{
assert(clisock.Send(req.c_str(),req.size()) != -1);
char buffer[1024] = {0};
clisock.Recv(buffer,sizeof(buffer) - 1);
DEBUG_LOG("[%s]",buffer);
sleep(300);
}
clisock.Close();
return 0;
}
因为这里设置睡眠300秒(5分钟),所以测试的事件回稍微久一些。它的效果应该是,正常搜发一次数据,然后睡眠5分钟,然后发送数据失败。
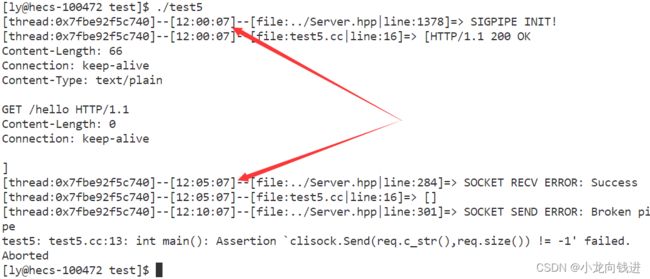
2.2.10整合测试6
本次测试的内容为,发送一个内容不完整的请求,看服务器是否能够保存不完整的请求而等待接收新的数据而凑成一个完整的请求。
测试用例:
int main()
{
Socket clisock;
clisock.CreateClinet("127.0.0.1",9090);
// 请求头指定正文有100个字节,但实际上没有。连续发送多条请求,看服务器是否能够正确拼凑出一条完整的请求
std::string req = "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\nContent-Length: 100\r\n\r\n你好";
while(true)
{
assert(clisock.Send(req.c_str(),req.size()) != -1);
assert(clisock.Send(req.c_str(),req.size()) != -1);
assert(clisock.Send(req.c_str(),req.size()) != -1);
char buffer[1024] = {0};
clisock.Recv(buffer,sizeof(buffer) - 1);
DEBUG_LOG("[%s]",buffer);
sleep(3);
}
clisock.Close();
return 0;
}
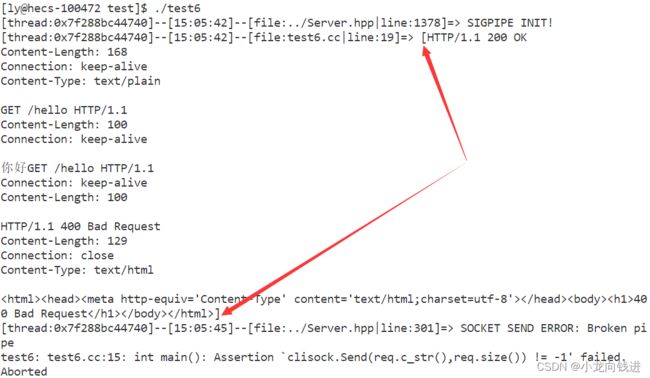
客户端发送一次数据后就断言退出了。原因是服务器在第二次接收请求的时候无法解析来自客户端的数据,因为Buffer当中的数据已经乱套了。
2.2.11整合测试7
连续给服务器发送多条完整的请求,测试服务器是否依然能够正常运行。
测试用例:
int main()
{
Socket clisock;
clisock.CreateClinet("127.0.0.1",9090);
std::string req = "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\nContent-Length: 0\r\n\r\n";
req += "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\nContent-Length: 0\r\n\r\n";
req += "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\nContent-Length: 0\r\n\r\n";
req += "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\nContent-Length: 0\r\n\r\n";
while(true)
{
assert(clisock.Send(req.c_str(),req.size()) != -1);
char buffer[1024] = {0};
clisock.Recv(buffer,sizeof(buffer) - 1);
DEBUG_LOG("[%s]",buffer);
sleep(3);
}
clisock.Close();
return 0;
}
运行结果:

上图是客户端接收到的响应。服务器正常执行,客户端退出后,服务器依然正常运行。
2.2.12整合测试8
大文件传输测试。客户端传输300M的文件给服务器,看服务器是否能够正常接收数据并写入文件当中。被写入数据的文件最终的大小应当和客户端读取的文件大小一致。
创建大文件的命令为:
dd if=/dev/zero of=hello.txt bs=300M count=1 -->创建300M大小的文件
建议服务器的PutFile()函数要改为:
void PutFile(const HttpRequest &req, HttpResponse *rsp)
{
std::string pathname = WWWROOT + req._path;
Util::WriteFile(pathname, req._body);
//rsp->SetContent(RequestStr(req), "text/plain");
}
客户端测试用例代码:
int main()
{
Socket clisock;
clisock.CreateClinet("127.0.0.1",9090);
std::string req = "PUT /1234.txt HTTP/1.1\r\nConnection: keep-alive\r\n";
std::string body;
Util::ReadFile("./hello.txt", &body);
req += "Content-Length: " + std::to_string(body.size()) + "\r\n\r\n";
assert(clisock.Send(req.c_str(), req.size()) != -1);
assert(clisock.Send(body.c_str(), body.size()) != -1);
char buffer[1024] = {0};
clisock.Recv(buffer,sizeof(buffer) - 1);
DEBUG_LOG("[%s]",buffer);
sleep(3);
clisock.Close();
return 0;
}
运行结果(服务端):

服务器最终写入的文件大小:

2.2.13整合测试9
本次测试上面所搭建的HTTP服务器的GET、POST、PUT、DELETE方法是否正常。将建议服务器的PutFIle函数改回:
void PutFile(const HttpRequest &req, HttpResponse *rsp)
{
// std::string pathname = WWWROOT + req._path;
// Util::WriteFile(pathname, req._body);
rsp->SetContent(RequestStr(req), "text/plain");
}
本次测试不需要客户端代码,而是用到一个工具软件——postman。postman模拟浏览器向服务器发送各种不同请求方法的HTTP请求,因为搭建的服务器为简易的Echo服务器,所以postman接收到的响应应当与请求一样。
测试GET方法是否正常:
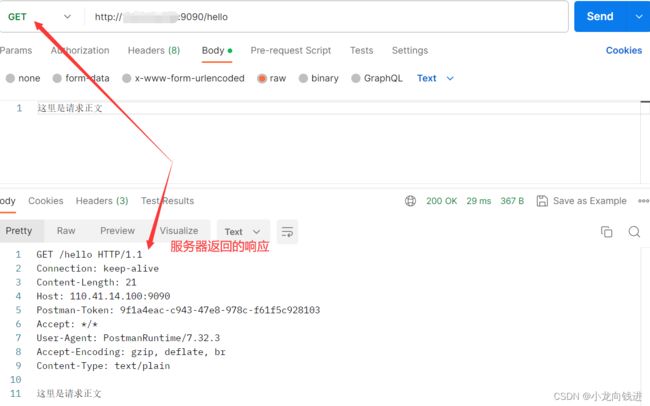
测试POST方法是否正常:

测试PUT方法是否正常:
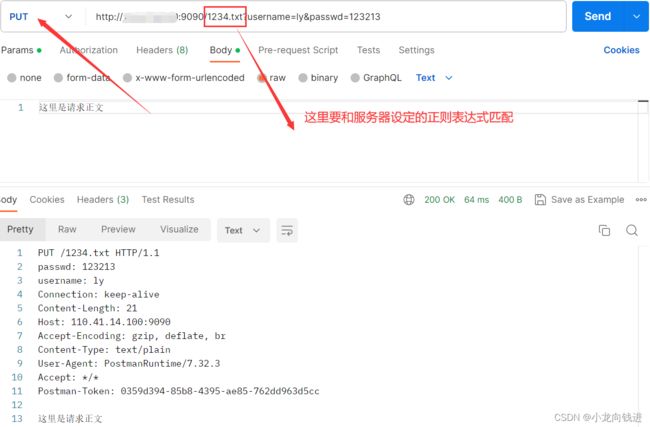
测试DELETE方法是否正常:
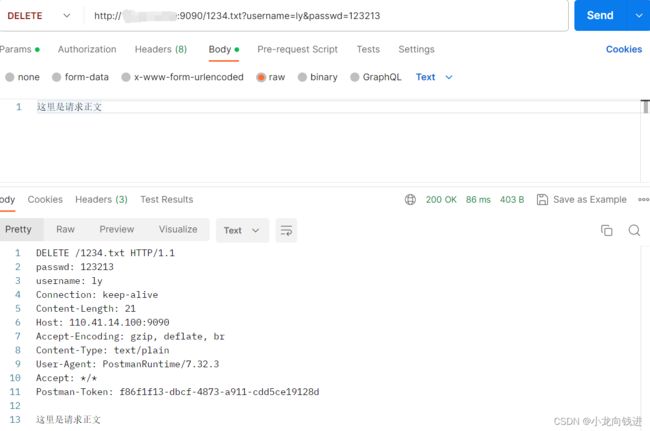
2.2.14整合测试10
本次测试为压力测试,目的是探索本项目的并发极限。本项目的服务器工作线程默认为2个(如上面写的简易服务器那里),加上主线程一共有三个线程。虚拟机的环境为Centos7.6,8核8G,进行60s的压力测试。
webbench模拟5000个客户端:
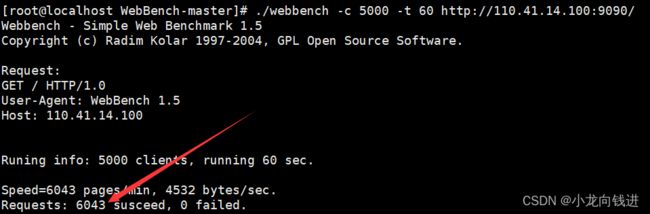
webbench模拟10000个客户端:

webbench模拟20000个客户端:
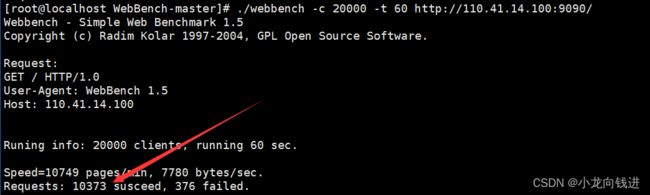
到这里出现了丢包,并且qps达到最大值,约为172。出现了丢包说明服务器超负荷了,即20000个并发连接为本项目实现的服务器的极限(2核4G的情况下)。
这里还认为可能是服务器的线程数量过少导致的超负荷,于是又添加了一个线程,但是最终结果却截然相反:
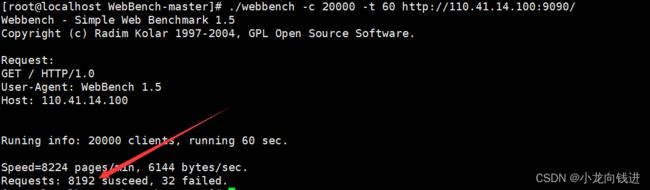
线程数量过多出现了数据倒退的情况(果然线程最好不要超过CPU的核心数)。
3.项目总结
本项目实现了一个高性能并发服务器,项目使用了epoll多路转接技术、并工作在ET模式下。服务器是基于从属Reactor事件处理模式实现的。已经支持了HTTP协议,可以快速搭建一个HTTP服务器。开发过程中没有用到任何第三方库。HTTP协议请求行的解析使用正则表达式完成。
服务器能够极限承受20000个连接的并发量,qps平均为172左右。
项目使用到的技术点:C++11、Reactor事件处理模式、多路转接技术、多线程、线程池、任务队列、互斥量、条件变量、正则表达式、HTTP协议。