Spark:StructStreaming
目录
01:上篇回顾
02:本篇内容
03:SparkStreaming的缺点
04:StructStreaming的设计
05:官方示例WordCount
06:自定义开发WordCount实现
07:Source数据源类型及File Source
08:常用Query查询器选项
09:Sink数据源:支持类型
10:Sink数据源:Foreach Sink
11:StructStreaming容错机制
12:集成Kafka:消费Kafka数据
13:集成Kafka:生产Kafka数据
14:物联网设备分析:需求及环境
15:物联网设备分析:DSL实现
16:物联网设备分析:SQL实现
17:数据去重Deduplication
18:Continuous Processing
19:事件时间处理:需求及实现
20:事件时间处理:延迟数据处理
附录一:Streaming Maven依赖
01:上篇回顾
https://blog.csdn.net/m0_57498038/article/details/119113968
-
DStream的函数有哪些?
-
转换函数:DStream调用转换函数返回一个新的DStream
-
transform:取DStream中每个RDD进行处理,有返回值
-
-
输出函数:主要用于输出保存程序的结果
-
foreachRDD:取DStream中每个RDD进行处理,没有返回值
-
-
-
流式计算的三种计算模式及应用场景是什么?
-
无状态模式:当前批次的计算结果就是当前批次的最终结果,与前面的批次是没有关系的
-
处理数据的范围:当前批次
-
应用场景:ETL
-
-
有状态模式:当前批次的最终结果来自于当前批次的计算结果与前面批次的最终结果进行聚合得到的
-
处理数据的范围:前面所有批次的结果
-
应用场景:所有数据的聚合:统计累计总成交额
-
-
窗口计算模式:对固定窗口大小范围的数据进行聚合
-
处理数据的范围:某个时间段内的数据
-
应用场景:固定处理近期的某个时间范围数据聚合结果:每3s处理近6s的数据
-
1s:批次数据
-
3s:滑动时间
-
6s:窗口大小
-
-
-
-
SparkStreaming集成Kafka的方式和原理是什么?
-
方式
-
Receiver模式
-
Direct模式
-
-
==Direct模式的原理==
-
基本原理:使用Kafka消费者的拉取数据的模式,使用Kafka Consumer的Simple API
-
实现流程
-
step1:没到达一个批次时间,SparkStreaming根据订阅消费的Topic的每个分区到Kafka获取每个分区的最新的offset
-
step2:根据上一次消费的最后的一个Offset【不包含】,与当前这个分区的最新offset,组合一个当前批次要处理的数据范围
-
[fromOffset,utilOffset)
-
-
step3:向Kafka请求本次消费数据的范围的数据,获取这个批次的数据进行处理
-
-
优点
-
简单的并行化模式:Kafka中的1个分区= RDD的1个分区
-
对性能的影响很小:选择拉取模式,不用使用WAL
-
保证一次性语义:允许自己管理offset
-
-
-
-
SparkStreaming程序怎么做容灾?
-
Offset的安全性和顺序性的解决方案:自己管理offset存储
-
step1:消费处理成功,自己将utilOffset存储在外部系统
-
step2:消费故障重启,自己从外部存储中读取上一次正常消费的offset位置,向Kafka提交消费请求
-
-
有状态计算,必须保存之前的状态的结果,如果消费者程序故障,程序重启,不知道上一次的处理的结果,只能重头开始?
-
基本方案:将上一次状态存储在CHK中
ssc.checkpoint -
问题:如果每次重新构建一个ssc,不知道上一次的chk是谁,不能恢复上一次的数据?
-
解决:第一次,构建一个新的ssc,从第二次开始,从chk中恢复ssc
val ssc = StreamingContext.getActiveOrCreate( chkdir,//用于从第二次开始恢复ssc //第一次运行,构建一个新的,配置chk () => { new StreamingContext.checkpoint(chkdir) } ) -
chk作用
-
程序元数据:程序的所有配置信息、DStream所有转换逻辑、未处理的批次信息
-
数据的记录:状态数据的结果
-
-
-
02:本篇内容
-
StructStreaming基本介绍
-
基本设计:SparkStreaming的缺点
-
功能、应用场景
-
为什么需要StructStreaming,它的优点是什么?
-
-
==StructStreaming的使用==
-
驱动接口:SparkSession
-
数据抽象:DataSet
-
开发方式:DSL 、SQL
-
数据源
-
Source:Kafka
-
Sink:Kafka、MySQL、Redis
-
-
物理网设备分析的案例:DSL和SQL
-
-
了解一些其他特性
-
流式数据的去重
-
持续数据处理:真实时计算
-
SparkStreaming:准实时,微小时间的批处理来模拟实时
-
StructStreaming:真实时,产生一条处理一条
-
离线
-
准实时
-
真实时
-
-
-
EventTime:基于数据的事件时间的处理
-
现在的处理都是基于处理时间的结果
-
数据产生的时间【事件时间】与数据处理的时间是否一样?
-
-
03:SparkStreaming的缺点
-
目标:了解SparkStreaming的设计缺点
-
实施
-
缺点1:对于数据分析业务而言,编程复杂,底层都是RDD的函数式编程
-
数据分析最适合的语言:SQL
-
SparkStreaming不支持SQL:RDD的函数式编程
-
-
缺点2:批流代码不统一
-
离线计算:SparkSQL:DSL【函数式编程】、==支持SQL==
-
实时计算:SparkStreaming==不支持SQL==
-
-
缺点3:很难支持流式应用端到端精确性一次语义,需要自己保证Input和Output的Exactly Once
-
只能保证DStream自己的一次性语义
-
-
缺点4:使用的是Processing Time而不是Event Time
-
Processing Time:数据的处理时间的计算
-
Event Time:事件时间,数据产生时间的计算,更精确
-
-
解决:流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年Google发表了The
DataflowModel的论文( https://yq.aliyun.com/articles/73255 )。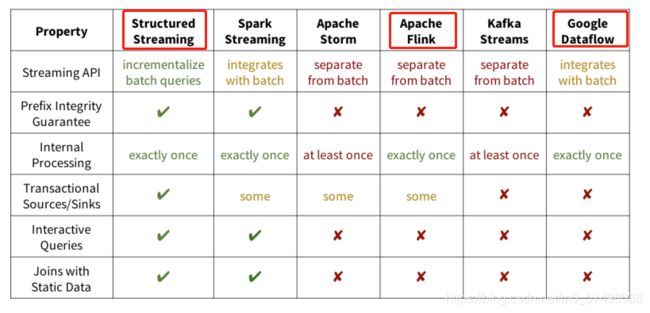
-
-
小结
-
了解SparkStreaming的设计缺点
-
04:StructStreaming的设计
-
目标:了解StructStreaming的设计和功能
-
实施
-
设计
-
==DataFlow论文==:提出了一种新的流式计算模型,用统一化的流式计算代替所有分布式计算,提出一些新的概念:事件时间
-
Spark模块
-
SparkCore:基于代码的离线开发
-
SparkSQL:基于SQL的离线开发
-
SparkStreaming:基于代码的实时计算【本质上还是SparkCore的RDD的编程】
-
基于SparkCore而设计的
-
DStream = Seq【RDD】
-
-
StructStreaming:基于SQL的实时计算
-
基于SparkSQL而设计的
-
DataFrame/DateSet:无边界表
-
数据源源不断的放入无边界的表中
-
通过SQL或者DSL对无边界的表进行计算
-
将结果放入无边界的结果表中
-
通过一个查询器【Query】,根据需求输出对应的结果
-
-
-
-
目的:统一化开发接口和模块,用一个SparkSQL模块来实现离线和实时计算
-
-
官方介绍
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. #你可以使用批处理的开发方式来开发流式计算的程序:可以直接使用之前sparkSQL开发来开发StructStreaming The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. #可以使用SparkSQL对源源不断到达的数据进行持续化或者更新化的数据处理 You can use the Dataset/DataFrame API in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. #你可以使用DSL函数式编程来实现数据的计算 The computation is executed on the same optimized Spark SQL engine. Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write-Ahead Logs. #通过chk和wal来保证程序的健壮性 In short, Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming. #简单点说,用户不需要关心流式计算实现的原理可以实现快速的可扩展高容错的一次性语义的流式计算程序
-
功能
-
功能:实现分布式的结构化数据的实时流式计算
-
基于SparkSQL实现的:将流式计算的应用底层通过sparkSQL来实现
-
-
应用
-
主要用于Spark实现结构化数据的流式计算的处理
-
-
流程
-
step1:读取数据流,将数据流放入一个无边界的数据表中【DataSet】
val ds = spark.readStream.format.load
-
step2:调用DSL或者SQL对DS中的数据进行转换计算,底层还是批处理

-
step3:每次追加计算的结果,放入一个无边界的结果表,不断更新计算的结果

-
step4:根据需求,构建一个查询器,从无边界的结果表中输出我们计算的结果即可
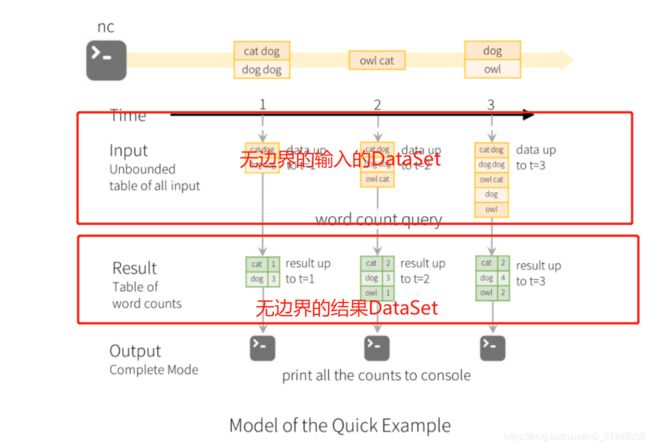
-
-
-
小结
-
了解StructStreaming的设计和功能
-
05:官方示例WordCount
-
目标:实现官方示例程序WordCount的测试
-
实施
-
启动HDFS
start-dfs.sh -
第一台机器运行nc
nc -lk 9999 -
第二台机器运行
/export/server/spark/bin/run-example \ --master local[2] \ --conf spark.sql.shuffle.partitions=2 \ org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount \ node1 9999 -
观察输出

-
没有新的数据,不输出的
-
默认实现了有状态的计算
-
默认时间间隔:默认是没有时间间隔,只要有数据默认是上一个批次执行结束,就执行下一个批次
-
是可以指定时间的规则
-
按照时间间隔:每1s执行一次,跟SparkStreaming是一样的
-
只执行一个批次:就是批处理
-
持续数据处理:不断对数据进行监听处理,不再是微小时间的批处理,真实时计算
-
-
-
-
-
小结
-
实现官方示例程序WordCount的测试
-
06:自定义开发WordCount实现
-
目标:实现StructStreaming自定义开发WordCount程序
-
实施
-
代码开发
package bigdata.spark.struct.wordcount import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.{DataFrame, SparkSession} /** * @ClassName StructWordCount * @Description TODO 使用结构化流计算构建Wordcount程序 */ object StructWordCount { def main(args: Array[String]): Unit = { //todo:1-构建SparkSession val spark = SparkSession .builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") .config("spark.sql.shuffle.partitions",2) .getOrCreate() //日志级别 spark.sparkContext.setLogLevel("WARN") //导包 import spark.implicits._ import org.apache.spark.sql.functions._ //todo:2-处理数据 //step1:读取数据 val inputData: DataFrame = spark.readStream .format("socket") .option("host","node1") .option("port",9999) .load() //step2:处理数据 val rsData = inputData .as[String] .filter(line => line != null && line.trim.length > 0) .select(explode(split($"value","\\s+")).as("word")) .groupBy($"word") .count() .withColumnRenamed("count","cnt") //step3:保存结果:查询器 val query = rsData .writeStream .outputMode(OutputMode.Complete()) //指定输出模式 .format("console") //输出的类型 .start() //流式计算的启动,类似于离线计算的save //todo:3-启动并持久运行 query.awaitTermination() //持久运行 query.stop() //释放资源 } } -
结果

-
与SparkSQL离线的差异
-
输入:调用readStream方法
-
数据源:实时数据源
-
-
-
处理:基本一致
-
输出
-
writeStream:构建输出流
-
outputMode:输出模式,有状态和无状态计算
-
start:构建查询器
-
awaitTermination:持续运行
-
-
-
-
小结
-
实现StructStreaming自定义开发WordCount程序
-
07:Source数据源类型及File Source
-
目标:了解StructStreaming的数据源类型及File Source的实现
-
路径
-
step1:支持Source数据源
-
step2:File Source
-
-
实施
-
支持Source数据源
-
地址:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#input-sources

-
File:动态读取文件
-
Kafka:最常用
-
Socket:监听端口,用于测试,不能用于生产环境,不支持故障恢复
The socket source should not be used for production applications! It does not support recovery.-
常用属性
host: host to connect to, must be specified port: port to connect to, must be specified
-
-
Rate:用于模拟数据做测试的,一般也不用
-
-
File Source
-
功能:动态的监听一个目录,如果目录中出现的新的文件,就会被动态的读取数据的内容
-
Flume:Spooldir
-
-
应用场景:一般用于监听日志文件直接采集处理,用的比较少
-
需求:监听一个信息目录,统计年龄小于25岁的人的兴趣爱好的分布
-
结果:对所有年龄小于25岁的人统计每种兴趣爱好的人数
hobby count running 3 swimming 1 -
代码
-
动态监听信息目录
/** * 实现监听目录读取文件,注意:所有filesource必须指定schema */ //为当前文件创建schema val schema = new StructType() .add("name",StringType,true) .add("age",IntegerType,true) .add("hobby",StringType,true) val inputStream: DataFrame = spark.readStream .format("csv") .option("sep", ";") .schema(schema) //所有file source必须指定文件内容的schema .load("datastruct/filesource")//给定监听的目录的地址 -
实现转换
//todo:2-处理数据:对所有年龄小于25岁的人统计每种兴趣爱好的人数 val rsStream = inputStream .filter( $"age" < 25) .groupBy($"hobby") .count() -
输出
val query = rsStream //保存数据流 .writeStream .outputMode(OutputMode.Complete()) //指定查询输出的模式 .format("console")//指定保存的模式 .option("numRows","10") //打印多少行 .option("truncate","false") //是否省略显示 .start() //启动流式计算,构建查询器 -
结果

-
-
-
-
-
小结
-
了解StructStreaming的数据源类型及File Source的实现
-
08:常用Query查询器选项
-
目标:掌握StructStreaming中常用的Query查询器选项
-
路径
-
step1:输出模式
-
step2:查询器名称
-
step3:触发间隔
-
step4:检查点
-
-
实施
-
输出模式
-
功能:类似于离线计算中保存模式,类似于stream中的业务模式
-
离线计算:Append/Overwrite/ErrorIfExists/Ignor
-
流式计算:无状态【一对一】、有状态【多对一】、窗口【显示最近窗口的计算的结果】
-
-
类型
-
Append mode (default) :追加模式,以追加的方式显示结果
-
Complete mode:完全模式,对所有数据进行聚合输出结果
-
Update mode:更新模式,只输出更新的结果
-
-
==基本规则==
-
如果你的代码中没有聚合:Append,一对一的
-
如果代码中有聚合:Complete或者Update
-
如果你只想显示发生改变的结果:Update
-
-
-
查询器名称
-
可以给查询器取个名字,用于区分不同的查询器
val query = rsStream //保存数据流 .writeStream .outputMode(OutputMode.Complete()) //指定查询输出的模式 .queryName("wcquery")//指定查询器的名称 .format("console")//指定保存的模式 .start() //启动流式计算,构建查询器 -
监控

-
-
触发间隔
-
功能:定义StructStreaming的每个批次运行间隔的规则
-
默认:上个批次结束,自动执行下个批次
-
-
自定义:Trigger
-
ProcessingTime:按照一定的时间间隔来运行每个批次,效果等于SparkStreaming
.trigger(Trigger.ProcessingTime("10 seconds")) -
Once:只执行一个批次,不是流式计算,效果等同于批处理
.trigger(Trigger.Once()) -
Continues:持续数据处理,底层不是微小时间 的批处理,目前还处于试验阶段
.trigger(Trigger.Continuous("5 seconds"))-
注意:这里的5s不代表每5s执行一次,代表每隔一段时间做一次记录
-
-
-
-
检查点checkpoint
-
http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#recovering-from-failures-with-checkpointing
In case of a failure or intentional shutdown, you can recover the previous progress and state of a previous query, and continue where it left off. This is done using checkpointing and write-ahead logs. You can configure a query with a checkpoint location, and the query will save all the progress information (i.e. range of offsets processed in each trigger) and the running aggregates (e.g. word counts in the quick example) to the checkpoint location. This checkpoint location has to be a path in an HDFS compatible file system, and can be set as an option in the DataStreamWriter when starting a query.
-
功能:用于存储整个流式计算程序的所有内容
-
元数据信息
-
数据状态信息
-
-
配置方式一
val query: StreamingQuery = rsData .writeStream //保存模式 .outputMode(OutputMode.Complete()) .format("console") //配置检查点,存储程序的元数据信息,用于程序的恢复 .option("checkpointLocation", "datastruct/output/chk1") //启动 .start() -
配置方式二
/** * step1:先创建SparkSession */ val spark = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[3]") .config("spark.sql.shuffle.partitions","2") //设置检查点方式二 .config("spark.sql.streaming.checkpointLocation","datastruct/output/chk2") .getOrCreate()
-
-
-
小结
-
掌握StructStreaming中常用的Query查询器选项
-
09:Sink数据源:支持类型
-
目标:了解StructStreaming的Sink数据源的支持
-
实施
-
http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#output-sinks

-
File:将结果写入文件,不断追加写入文件
-
Kafka sink:最常用的方式
-
应用场景:ETL
-
-
Foreach sink :自定义输出,一般常用于写入MySQL、Redis、Hbase等
-
应用场景:保存分析结果
-
-
console:在命令行输出,用于测试
-
memory:保存到内存中,用于测试
-
-
小结
-
了解StructStreaming的Sink数据源的支持
-
10:Sink数据源:Foreach Sink
-
目标:掌握StructStreaming中Foreach Sink的使用
-
路径
-
step1:问题与需求
-
step2:foreach sink
-
step3:foreach batch
-
-
实施
-
问题与需求
-
如何将实时计算的结果保存到外部存储系统,例如:MYSQL、Redis等
-
-
foreach sink
-
功能:自定义输出
-
语法:调用foreach函数,传递一个ForeachWriter类的对象
def foreach(writer: ForeachWriter[T])
-
自定义ForeachWriter规则及实现
-
需要开发一个类:MySQLForeachWirter extends ForeachWriter[Row]
-
重写方法
-
open:初始化资源的方法
-
构建连接
-
-
process:实现处理逻辑方法
-
根据数据给SQL赋值
-
执行SQL语句
-
-
close:释放资源的方法
-
释放连接
-
package bigdata.spark.struct.datasink import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.sql.{ForeachWriter, Row} /** * @ClassName MySQLForeachSink * @Description TODO 用于自定义将数据写入MySQL */ class MySQLForeachSink extends ForeachWriter[Row]{ var conn:Connection = null var pstm:PreparedStatement = null val sql = "REPLACE INTO `tb_word_count` (`id`, `word`, `count`) VALUES (NULL, ?, ?)" //用于初始化资源 override def open(partitionId: Long, epochId: Long): Boolean = { Class.forName("com.mysql.cj.jdbc.Driver") conn = DriverManager.getConnection( "jdbc:mysql://node1.itcast.cn:3306/db_spark?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", "root", "123456" ) pstm = conn.prepareStatement(sql) //构建完成 true } //实现处理 override def process(value: Row): Unit = { pstm.setString(1,value.getAs[String]("word")) pstm.setInt(2,value.getAs[Long]("cnt").toInt) pstm.execute() } //释放资源 override def close(errorOrNull: Throwable): Unit = { pstm.close() conn.close() } } -
-
-
测试实现
-
建表
create database if not exists db_spark; use db_spark; drop table if exists `db_spark`.`tb_word_count`; CREATE TABLE `db_spark`.`tb_word_count` ( `id` int NOT NULL AUTO_INCREMENT, `word` varchar(255) NOT NULL, `count` int NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `word` (`word`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; -
代码开发
//step3:保存结果 val query = rsData .writeStream .outputMode(OutputMode.Complete()) // .format("console") // .option("numRows",20) //指定结果显示的行数 // .option("truncate","fasle") //如果字段长度过长,是否省略显示 .foreach(new MySQLForeachSink) .start()
-
-
-
foreach batch
-
功能:将流式计算转换为批处理的接口来保存数据,非常类似于SparkStreaming中的ForeachRDD
-
类似离线的处理方式
rdd.foreach(part => {}) -
代码
val query: StreamingQuery = rsStream .writeStream .outputMode(OutputMode.Complete()) .foreachBatch((dataset,batchId) => { //直接调用批处理的保存数据的方法来实现 dataset.write.jdbc() }) .start()
-
-
-
小结
-
掌握StructStreaming中Foreach Sink的使用
-
11:StructStreaming容错机制
-
目标:了解StructStreaming的容错机制
-
实施
-
如何保证程序计算过程中数据不丢失不重复:实现一次性语义
-
Input:消费读取数据不丢失不重复
-
Process:处理数据过程中不丢失不重复
-
Output:保存结果的数据不丢失不重复
-
-
Source:所有读取数据的source,都被设计为支持offset类型的source,可以通过offset来保证消费数据的位置
-
Kafka【基于Kafka的offset进行消费,自动将Kafka的offset记录在chk中】
-
File【自己记录读取每个文件 的offset】
-
-
处理:checkpoint和WAL机制
-
Sink:所有保存结果的SInk都实现了幂等性机制
-
-
小结
-
了解StructStreaming的容错机制
-
12:集成Kafka:消费Kafka数据
-
目标:掌握StructStreaming与Kafka的集成及实现消费Kafka数据
-
路径
-
step1:集成方式
-
step2:消费规则
-
step3:消费实现
-
-
实施
-
集成方式
-
版本:只支持0.10及以上版本
-
方式:类似于SparkStreaming中Direct方式来实现
-
-
消费规则
-
StructStreaming将消费Kafka的API进行了封装
-
将Kafka中的数据读取以后,放入一张分布式的表中
-
-
官方示例
//消费某一个topic的数据 val df = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("subscribe", "topic1") .load() df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") .as[(String, String)] // 消费多个Topic的数据 val df = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("subscribe", "topic1,topic2") .load() df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") .as[(String, String)] // 消费符合正则表达式的Topic val df = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("subscribePattern", "topic.*") .load() df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") .as[(String, String)] -
消费Topic的数据:每一条数据中都包含以下几列

-
key:数据中的Key
-
value:数据中的value
-
topic:这条数据所属的topic
-
partition:这条数据所属的topic的哪个分区
-
offset:这条数据在这个分区中的offset
-
-
-
消费实现
-
需求:从Kafka消费数据,实现词频统计
-
第一步:先启动三台机器的Zookeeper
zookeeper-daemons.sh start zookeeper-daemons.sh status -
第二步:启动kafka server
kafka-daemons.sh start -
创建Topic
# 查看Topic信息 kafka-topics.sh --list --zookeeper node1:2181/kafka200 # 创建topic kafka-topics.sh --create --zookeeper node1:2181/kafka200 --replication-factor 1 --partitions 3 --topic wordsTopic # 模拟生产者 kafka-console-producer.sh --broker-list node1:9092 --topic wordsTopic -
代码实现
package bigdata.spark.struct.kafka.source import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.{DataFrame, SparkSession} /** * @ClassName StructWordCountKafkaSource * @Description TODO 使用结构化流消费Kafka数据实现WordCount */ object StructWordCountKafkaSource { def main(args: Array[String]): Unit = { //todo:1-构建SparkSession val spark = SparkSession .builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") .config("spark.sql.shuffle.partitions",2) .getOrCreate() //修改日志级别 spark.sparkContext.setLogLevel("WARN") //导包 import spark.implicits._ import org.apache.spark.sql.functions._ //todo:2-处理数据 //step1:读取数据 val inputData: DataFrame = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "node1:9092") .option("subscribe", "wordsTopic") .load() //step2:处理数据 val rsData = inputData .selectExpr("cast(value as string)") //只保留value,并转换为String类型 .as[String] .filter(line => line != null && line.trim.length > 0) .select(explode(split($"value","\\s+")).as("word")) .groupBy($"word") .count() .withColumnRenamed("count","cnt") //step3:保存结果 val query = rsData .writeStream .outputMode(OutputMode.Complete()) .format("console") .start() //todo:3-启动并持久运行 query.awaitTermination() query.stop() } }
-
-
-
常用属性
-
必须指定的属性

-
可选的属性

-
-
-
小结
-
掌握StructStreaming与Kafka的集成及实现消费Kafka数据
-
13:集成Kafka:生产Kafka数据
-
目标:掌握StructStreaming与Kafka的集成实现生产数据到Kafka
-
路径
-
step1:规则
-
step2:实现
-
-
实施
-
规则
-
写Kafka
ProducerRecord(Topic、Key、Value) ProducerRecord(Topic、Value)- Key:可选的,数据中可以没有key这一列 - Key对于Kafka生产者而言,可以不指定 - value:所有的数据中写入Kafka,必须包含一列,叫value - 如果我要将wordcount的结果写入Kafka ```scala val rs = input .groupby(word) .count.as(cnt) rs:两列:word cnt rs .select(conca_ws("-",word,cnt).as("value")) .writeStream .format("kafka")
-
topic:可选的,==数据中可以没有,但是最后输出的时候必须指定==
-
一般不放在数据中
-
-
官方示例
val query = df .selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") .writeStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("topic", "topic1") .start() // Write key-value data from a DataFrame to Kafka using a topic specified in the data val query = df .selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") .writeStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .start()
-
-
实现
-
需求:读Kafka中Topic1的基站数据,对读取到的数据进行ETL,将成功状态的数据写入Kafka的另外一个Topic2中
-
创建Topic
## ================================= stationTopic ================================= kafka-topics.sh --create --zookeeper node1:2181/kafka200 --replication-factor 1 --partitions 3 --topic stationTopic # 模拟生产者 kafka-console-producer.sh --broker-list node1:9092 --topic stationTopic # 模拟消费者 kafka-console-consumer.sh --bootstrap-server node1:9092 --topic stationTopic --from-beginning # 删除topic kafka-topics.sh --delete --zookeeper node1:2181/kafka200 --topic stationTopic ## ================================= etlTopic ================================= # 创建topic kafka-topics.sh --create --zookeeper node1:2181/kafka200 --replication-factor 1 --partitions 3 --topic etlTopic # 模拟生产者 kafka-console-producer.sh --broker-list node1:9092 --topic etlTopic # 模拟消费者 kafka-console-consumer.sh --bootstrap-server node1:9092 --topic etlTopic --from-beginning -
模拟数据
bigdata.spark.struct.kafka.mock.MockStationLog -
代码实现
package cn.spark.kafka.sink import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery} import org.apache.spark.sql.types.StringType import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * 实时从Kafka Topic消费基站日志数据,过滤获取通话转态为success数据,再存储至Kafka Topic中 * 1、从KafkaTopic中获取基站日志数据(模拟数据,JSON格式数据) * 2、ETL:只获取通话状态为success日志数据 * 3、最终将ETL的数据存储到Kafka Topic中 */ object StructKafkaSink { def main(args: Array[String]): Unit = { //构建SparkSession实例对象,相关配置进行配置 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[3]") //设置Shuffle分区数目 .config("spark.sql.shuffle.partitions", "2") .getOrCreate() //导入隐式转换 import spark.implicits._ //todo 1.从KafkaTopic中获取基站日志数据(模拟数据,文本数据) val kafkaStreamDF: DataFrame = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "node1:9092") .option("subscribe", "stationTopic") .option("maxOffsetsPerTrigger", "20000") //设置每批次处理最大数据量 .load() //todo 2.ETC:只获取通话状态为success日志数据 val etlStreamDF: Dataset[String] = kafkaStreamDF //先过滤非null数据 .filter($"value".isNotNull) //转换value值为字符串String .select($"value".cast(StringType)) //数据格式:station_6,18600002250,18900008731,success,1624345036039,2000 .as[String] .filter { message => val array = message.trim.split(",") array.length == 6 && "success".equals(array(3)) } //todo 3.最终将ETL的数据存储到KAFKA TOPIC中 val query: StreamingQuery = etlStreamDF .writeStream .queryName("query-state-etl") .outputMode(OutputMode.Append()) //todo 将数据保存至kafka topic .format("kafka") .option("kafka.bootstrap.servers", "node1:9092") .option("topic", "etlTopic") //todo 设置检查点目录 .option("checkpointLocation", "datas/structured/ckpt-9999") .start() query.awaitTermination() query.stop() } }
-
-
-
-
小结
-
掌握StructStreaming与Kafka的集成实现生产数据到Kafka
-
14:物联网设备分析:需求及环境
-
目标:了解物联网设备分析的需求及环境配置
-
实施
-
数据格式:
-
device:设备名称
-
deviceType:设备类型
-
signal:信号
-
time:时间
{"device":"device_62","deviceType":"db","signal":31.0,"time":1608805779682} {"device":"device_32","deviceType":"kafka","signal":85.0,"time":1608805780208} {"device":"device_65","deviceType":"db","signal":73.0,"time":1608805780724} {"device":"device_98","deviceType":"bigdata","signal":58.0,"time":1608805780914} {"device":"device_43","deviceType":"route","signal":54.0,"time":1608805781028} {"device":"device_71","deviceType":"bigdata","signal":31.0,"time":1608805781320} {"device":"device_20","deviceType":"bigdata","signal":85.0,"time":1608805781481} {"device":"device_96","deviceType":"bigdata","signal":26.0,"time":1608805782002} {"device":"device_96","deviceType":"bigdata","signal":55.0,"time":1608805782411} {"device":"device_62","deviceType":"db","signal":21.0,"time":1608805782980} -
-
需求条件
-
需求:各种设备类型的设备数量和平均信号强度
设备类型 个数 平均信号强度 -
条件:信号强度必须大于30
-
-
创建topic
# 创建topic kafka-topics.sh --create --zookeeper node1:2181/kafka200 --replication-factor 1 --partitions 3 --topic iotTopic # 模拟生产者 kafka-console-producer.sh --broker-list node1:9092 --topic iotTopic # 模拟消费者 kafka-console-consumer.sh --bootstrap-server node1:9092 --topic iotTopic --from-beginning # 删除topic kafka-topics.sh --delete --zookeeper node1:2181/kafka200 --topic iotTopic -
模拟数据
-
创建 DeviceData的Bean对象
-
package bigdata.spark.iot.mock /** * 物联网设备发送状态数据 * * @param device 设备标识符ID * @param deviceType 设备类型,如服务器mysql, redis, kafka或路由器route * @param signal 设备信号 * @param time 发送数据时间 */ case class DeviceData( device: String, // deviceType: String, // signal: Double, // time: Long // )模拟数据代码
-
package cn.bigdata.spark.iot.mock import java.util.Properties import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord} import org.apache.kafka.common.serialization.StringSerializer import org.json4s.jackson.Json import scala.util.Random object MockIotDatas { def main(args: Array[String]): Unit = { // 发送Kafka Topic val props = new Properties() props.put("bootstrap.servers", "node1:9092") props.put("acks", "1") props.put("retries", "3") props.put("key.serializer", classOf[StringSerializer].getName) props.put("value.serializer", classOf[StringSerializer].getName) val producer = new KafkaProducer[String, String](props) val deviceTypes = Array( "db", "bigdata", "kafka", "route", "bigdata", "db", "bigdata", "bigdata", "bigdata" ) val random: Random = new Random() while (true){ val index: Int = random.nextInt(deviceTypes.length) val deviceId: String = s"device_${(index +1) * 10 + random.nextInt(index + 1)}" val deviceType: String = deviceTypes(index) val deviceSignal: Int = 10 + random.nextInt(90) // 模拟构造设备数据 val deviceData = DeviceData(deviceId, deviceType, deviceSignal, System.currentTimeMillis()) // 转换为JSON字符串 val deviceJson: String = new Json(org.json4s.DefaultFormats).write(deviceData) println(deviceJson) Thread.sleep(100 + random.nextInt(500)) val record = new ProducerRecord[String, String]("iotTopic", deviceJson) producer.send(record) } // 关闭连接 producer.close() } } -

小结-
了解物联网设备分析的需求及环境配置
-
-
15:物联网设备分析:DSL实现
-
目标:使用StructStreaming的DSL实现物理网设备分析
-
实施
package bigdata.spark.struct.iot import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.types.{DoubleType, LongType, StringType} import org.apache.spark.sql.{DataFrame, SparkSession} /** * @ClassName StructIOTDSL * @Description TODO 使用结构化流DSL计算构建Wordcount程序 */ object StructIOTDSL { def main(args: Array[String]): Unit = { //todo:1-构建SparkSession val spark = SparkSession .builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") .config("spark.sql.shuffle.partitions",2) .getOrCreate() //修改日志级别 spark.sparkContext.setLogLevel("WARN") //导包 import spark.implicits._ import org.apache.spark.sql.functions._ //todo:2-处理数据 //step1:读取数据 val kafkaData = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "node1:9092") .option("subscribe", "iotTopic") .load() //step2:处理数据 val etlData = kafkaData .selectExpr("cast(value as string)") .as[String] //取出每个字段 .select( //{"device":"device_95","deviceType":"bigdata","signal":96.0,"time":1626849208123} get_json_object($"value","$.device").cast(StringType).as("device"), get_json_object($"value","$.deviceType").cast(StringType).as("deviceType"), get_json_object($"value","$.signal").cast(DoubleType).as("signal"), get_json_object($"value","$.time").cast(LongType).as("time") ) val rsData = etlData .filter($"signal" > 30) .groupBy($"deviceType") .agg( count($"device").as("cnt"), round(avg($"signal"),2).as("avgsignal") ) //step3:保存结果 val query = rsData .writeStream .outputMode(OutputMode.Complete()) .format("console") .start() //todo:3-启动并持久运行 query.awaitTermination() query.stop() } } -
小结
-
使用StructStreaming的DSL实现物理网设备分析
-
16:物联网设备分析:SQL实现
-
目标:使用StructStreaming的SQL实现物理网设备分析
-
实施
package bigdata.spark.struct.iot import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.types.{DoubleType, LongType, StringType} import org.apache.spark.sql.{DataFrame, SparkSession} /** * @ClassName StructIOTSQL * @Description TODO 使用结构化流SQL计算构建Wordcount程序 */ object StructIOTSQL { def main(args: Array[String]): Unit = { //todo:1-构建SparkSession val spark = SparkSession .builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") .config("spark.sql.shuffle.partitions",2) .getOrCreate() //修改日志级别 spark.sparkContext.setLogLevel("WARN") //导包 import spark.implicits._ import org.apache.spark.sql.functions._ //todo:2-处理数据 //step1:读取数据 val kafkaData = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "node1:9092") .option("subscribe", "iotTopic") .load() //step2:处理数据 val etlData = kafkaData .selectExpr("cast(value as string)") .as[String] .select( //{"device":"device_80","deviceType":"bigdata","signal":42.0,"time":1626786347440} get_json_object($"value","$.device").cast(StringType).as("device"), get_json_object($"value","$.deviceType").cast(StringType).as("deviceType"), get_json_object($"value","$.signal").cast(DoubleType).as("signal"), get_json_object($"value","$.time").cast(LongType).as("time") ) //注册视图 etlData.createOrReplaceTempView("tmp_iot") //执行SQL语句 val rsData = spark.sql( """ |select | deviceType, | count(device) as cnt, | round(avg(signal),2) as avgsignal |from tmp_iot |where signal > 30 |group by deviceType """.stripMargin) //step3:保存结果 val query = rsData .writeStream .outputMode(OutputMode.Complete()) .format("console") .start() //todo:3-启动并持久运行 query.awaitTermination() query.stop() } } -
小结
-
使用StructStreaming的SQL实现物理网设备分析
-
17:数据去重Deduplication
-
目标:了解StructStreaming实时数据处理中的数据去重
-
实施
-
问题:实时计算中如何实现数据的去重?
-
离线计算:全量数据的计算
-
实时计算:增量数据的计算
-
-
应用场景:统计UV
-
方案一:对全量数据进行去重
-
方案二:计算的时候实现:维护一个数据值的列表,如果存在,就不处理
-
方案三:存储的时候实现:将所有用户的id存储在Redis的Set集合
-
-
数据
{"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"} {"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"} {"eventTime": "2016-01-10 10:01:55","eventType": "browse","userID":"1"} {"eventTime": "2016-01-10 10:01:55","eventType": "click","userID":"1"} {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"} {"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"} {"eventTime": "2016-01-10 10:02:00","eventType": "click","userID":"1"} {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"} {"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"} {"eventTime": "2016-01-10 10:01:51","eventType": "click","userID":"1"} {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"} {"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"3"} {"eventTime": "2016-01-10 10:01:51","eventType": "click","userID":"2"} -
需求:统计每个用户id对应的每个设备个数
-
代码实现
package bigdataspark.struct.distinct import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery} import org.apache.spark.sql.{DataFrame, SparkSession} object StructuredDeduplication { def main(args: Array[String]): Unit = { // 构建SparkSession实例对象 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") // 设置Shuffle分区数目 .config("spark.sql.shuffle.partitions", "2") .getOrCreate() // 导入隐式转换和函数库 import spark.implicits._ import org.apache.spark.sql.functions._ //设置日志级别 spark.sparkContext.setLogLevel("WARN") // 1. 从TCP Socket 读取数据 val inputTable: DataFrame = spark.readStream .format("socket") .option("host", "node1") .option("port", 9999) .load() // 2. 数据处理分析 val resultTable: DataFrame = inputTable .as[String] .filter(line => null != line && line.trim.length > 0) // 样本数据:{“eventTime”: “2016-01-10 10:01:50”,“eventType”: “browse”,“userID”:“1”} .select( get_json_object($"value", "$.eventTime").as("event_time"), // get_json_object($"value", "$.eventType").as("event_type"), // get_json_object($"value", "$.userID").as("user_id")// ) // 按照UserId和EventType去重 .dropDuplicates("user_id","event_type") .groupBy($"user_id", $"event_type") .count() // 3. 设置Streaming应用输出及启动 val query: StreamingQuery = resultTable.writeStream .outputMode(OutputMode.Complete()) .format("console") .option("numRows", "10") .option("truncate", "false") .start() query.awaitTermination() // 流式查询等待流式应用终止 // 等待所有任务运行完成才停止运行 query.stop() } } -
结果

-
-
小结
-
了解StructStreaming实时数据处理中的数据去重
-
18:Continuous Processing
-
目标:了解StructStreaming的中Continuous Processing
-
路径
-
step1:问题及需求
-
step2:测试
-
-
实施
-
问题与需求
-
SparkStreaming:使用微小时间的批处理来模拟实时计算,准实时计算
-
StructStreaming
-
默认方案:微小时间的批处理
-
延迟:0 ~ 100ms
-
-
可选方案:持续数据处理,2.3版本开始支持,目前还处于试验阶段,不建议使用,建议使用Flink
-
延迟:0 ~ 1ms
-
-

-
缺点
-
不支持有且仅有一次的语义,支持至少一次,可能数据重复
-
目前支持的函数和数据源接口比较少
-
-
-
测试
package bigdata.spark.struct.continueprocess import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger} import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * 从Spark 2.3版本开始,StructuredStreaming结构化流中添加新流式数据处理方式:Continuous processing * 持续流数据处理:当数据一产生就立即处理,类似Storm、Flink框架,延迟性达到100ms以下,目前属于实验开发阶段 */ object StructuredContinuous { def main(args: Array[String]): Unit = { // 构建SparkSession实例对象 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[3]") .config("spark.sql.shuffle.partitions", "3") .getOrCreate() // 导入隐式转换和函数库 import spark.implicits._ spark.sparkContext.setLogLevel("WARN") // 1. 从KAFKA读取数据 val kafkaStreamDF: DataFrame = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "node1:9092") .option("subscribe", "stationTopic") .load() // 2. 对基站日志数据进行ETL操作 // station_0,18600004405,18900009049,success,1589711564033,9000 val etlStreamDF: Dataset[String] = kafkaStreamDF // 获取value字段的值,转换为String类型 .selectExpr("CAST(value AS STRING)") // 转换为Dataset类型 .as[String] // 过滤数据:通话状态为success .filter{log => null != log && log.trim.split(",").length == 6 && "success".equals(log.trim.split(",")(3)) } // 3. 针对流式应用来说,输出的是流 val query: StreamingQuery = etlStreamDF.writeStream .outputMode(OutputMode.Append()) .format("kafka") .option("kafka.bootstrap.servers", "node1:9092") .option("topic", "etlTopic") // 设置检查点目录 .option("checkpointLocation", s"datas/struct/chk3") // TODO: 设置持续流处理 Continuous Processing, 指定CKPT时间间隔 /* the continuous processing engine will records the progress of the query every second 持续流处理引擎,将每1秒中记录当前查询Query进度状态 */ .trigger(Trigger.Continuous("1 second")) .start() // 流式应用,需要启动start // 查询器等待流式应用终止 query.awaitTermination() query.stop() // 等待所有任务运行完成才停止运行 } } -
启动消费者
kafka-console-consumer.sh --bootstrap-server node1:9092 --topic etlTopic --from-beginning
-
-
小结
-
了解StructStreaming的中Continuous Processing
-
19:事件时间处理:需求及实现
-
目标:了解事件时间处理的需求及实现
-
路径
-
step1:问题与需求
-
step2:事件时间处理
-
step3:窗口的生成
-
-
实施
-
问题与需求
-
什么是事件时间?
-
就是数据真实的产生时间
-
-
问题:举个栗子
-
需求:双十一这天,从11-11 00:00:00 ~ 23:59:59,统计所有订单的总成交金额,每5s构建一个批次
-
第一个批次:000000 - 000005
order0 1000万 order1 100万 order2 100万 || 1200万 -
第二个批次:000005 - 000010
order3 100万 order4 100万 || 200万 || 1400万 -
如果有一个人,在10号23:59:58提交一个订单,这个订单的数据11号的00:00:01达到计算系统,订单金额1000万
-
问题出现了:这个订单不属于双十一提交的订单,不应该被计算
-
-
时间的分类
-
事件时间Event Time:数据真正产生的时间,数据本身就有
-
处理时间Process Time:数据到达被计算得到结果的时间
-
正常情况下,这两个时间的差值会很小,但是如果因为网络等原因,导致最终的结果是不准确的
-
-
解决:==不论数据什么时候到达计算系统被计算,计算的结果都应该属于数据的生成时间==
-
基于事件时间的计算方案
-
-
问题:我们怎么知道数据是什么时候产生的呢?
-
一般数据中都会包含这一列,这一列就表示数据产生的时间
-
不论数据是什么时候产生的,计算的结果都属于这个时间
-
-
事件时间处理视图

-
-
事件时间处理
-
需求:基于数据的时间来实现词频统计,每5s计算前10s的数据
-
测试数据:数据生成时间,一行单词
2019-10-12 09:00:02,cat dog 2019-10-12 09:00:03,dog dog 2019-10-12 09:00:07,owl cat 2019-10-12 09:00:11,dog 2019-10-12 09:00:13,owl +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-12 08:59:55, 2019-10-12 09:00:05]|dog |3 | |[2019-10-12 08:59:55, 2019-10-12 09:00:05]|cat |1 | |[2019-10-12 09:00:00, 2019-10-12 09:00:10]|dog |3 | |[2019-10-12 09:00:00, 2019-10-12 09:00:10]|owl |1 | |[2019-10-12 09:00:00, 2019-10-12 09:00:10]|cat |2 | |[2019-10-12 09:00:05, 2019-10-12 09:00:15]|cat |1 | |[2019-10-12 09:00:05, 2019-10-12 09:00:15]|owl |2 | |[2019-10-12 09:00:05, 2019-10-12 09:00:15]|dog |1 | |[2019-10-12 09:00:10, 2019-10-12 09:00:20]|dog |1 | |[2019-10-12 09:00:10, 2019-10-12 09:00:20]|owl |1 | +------------------------------------------+----+-----+ -
代码测试
package bigdata.spark.struct.window import java.sql.Timestamp import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger} import org.apache.spark.sql.{DataFrame, SparkSession} /** * 基于Structured Streaming 模块读取TCP Socket读取数据,进行事件时间窗口统计词频WordCount,将结果打印到控制台 * TODO:每5秒钟统计最近10秒内的数据(词频:WordCount) * * EventTime即事件真正生成的时间: * 例如一个用户在10:06点击 了一个按钮,记录在系统中为10:06 * 这条数据发送到Kafka,又到了Spark Streaming中处理,已经是10:08,这个处理的时间就是process Time。 * */ object StructuredWindow { def main(args: Array[String]): Unit = { // 1. 构建SparkSession实例对象,传递sparkConf参数 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") .config("spark.sql.shuffle.partitions", "2") .getOrCreate() // 导入隐式转换及函数库 import org.apache.spark.sql.functions._ import spark.implicits._ spark.sparkContext.setLogLevel("WARN") // 2. 使用SparkSession从TCP Socket读取流式数据 val inputStreamDF: DataFrame = spark.readStream .format("socket") .option("host", "node1") .option("port", 9999) .load() // 3. 针对获取流式DStream进行词频统计 val resultStreamDF = inputStreamDF // 将DataFrame转换为Dataset操作,Dataset是类型安全,强类型 .as[String] // 过滤无效数据 .filter(line => null != line && line.trim.length > 0) // 将每行数据进行分割单词: 2019-10-12 09:00:02,cat dog .flatMap{line => val arr = line.trim.split(",") arr(1).split("\\s+").map(word => (Timestamp.valueOf(arr(0)), word)) } /** * 2019-10-12 09:00:02,cat * 2019-10-12 09:00:02,dog * 2019-10-12 09:00:03,dog * 2019-10-12 09:00:03,dog */ // 设置列的名称 .toDF("insert_timestamp", "word") // TODO:设置基于事件时间(event time)窗口 -> insert_timestamp, 每5秒统计最近10秒内数据 /* 1. 先按照窗口分组 2. 再对窗口中按照单词分组 3. 最后使用聚合函数聚合 */ .groupBy( //按照数据中的事件时间构建窗口 window($"insert_timestamp", "10 seconds", "5 seconds"), $"word" ) .count() // 按照窗口字段降序排序 .orderBy($"window") /* root |-- window: struct (nullable = true) | |-- start: timestamp (nullable = true) | |-- end: timestamp (nullable = true) |-- word: string (nullable = true) |-- count: long (nullable = false) */ //resultStreamDF.printSchema() // 4. 将计算的结果输出,打印到控制台 val query: StreamingQuery = resultStreamDF.writeStream .outputMode(OutputMode.Complete()) .format("console") .option("numRows", "100") .option("truncate", "false") .trigger(Trigger.ProcessingTime("5 seconds")) .start() // 流式DataFrame,需要启动 // 查询器一直等待流式应用结束 query.awaitTermination() query.stop() } } -
结果:数据的结果属于对应时间的
+------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-12 08:59:55, 2019-10-12 09:00:05]|dog |3 | |[2019-10-12 08:59:55, 2019-10-12 09:00:05]|cat |1 | |[2019-10-12 09:00:00, 2019-10-12 09:00:10]|dog |3 | |[2019-10-12 09:00:00, 2019-10-12 09:00:10]|owl |1 | |[2019-10-12 09:00:00, 2019-10-12 09:00:10]|cat |2 | |[2019-10-12 09:00:05, 2019-10-12 09:00:15]|cat |1 | |[2019-10-12 09:00:05, 2019-10-12 09:00:15]|owl |2 | |[2019-10-12 09:00:05, 2019-10-12 09:00:15]|dog |1 | |[2019-10-12 09:00:10, 2019-10-12 09:00:20]|dog |1 | |[2019-10-12 09:00:10, 2019-10-12 09:00:20]|owl |1 | +------------------------------------------+----+-----+
-
-
窗口的生成
2019-10-12 09:00:02,cat dog 2019-10-12 09:00:03,dog dog 2019-10-12 09:00:07,owl cat 2019-10-12 09:00:11,dog 2019-10-12 09:00:13,owl-
窗口时间:10s
-
滑动时间:5s
-
先计算初始窗口:event-time向上取 能整除 滑动步长的时间) - (最大窗口数×滑动步长)
-
9:00:00 - (2 * 5) = 8:59:50
-
初始窗口: 8:59:50 ~ 9:00:00:==不包含==
-
-
再按照滑动时间来计算运行窗口
-
8:59:55 ~ 9:00:05
-
9:00:00 ~ 9:00:10
-
9:00:05~ 9:00:15
-
9:00:10 ~ 9:00:20
-
-
最后再计算结束窗口
-
9:00:15 ~ 9:00:25:如果最大的事件时间不在这个窗口,不再计算,这个窗口作为结束窗口
-
==不包含==
-
-
-
-
小结
-
什么是基于事件时间的处理?
-
不论数据什么时候到达计算系统,被处理,最后处理的结果都属于数据生成的时间
-
-
代码实现
.groupBy( //按照数据中的事件时间构建窗口 window($"insert_timestamp", "10 seconds", "5 seconds"), $"word" )
-
20:事件时间处理:延迟数据处理
-
目标:了解基于事件时间的延迟数据处理
-
路径
-
step1:设计及规则
-
step2:测试实现
-
-
实施
-
设计及规则
-
思考一个问题:如果一个数据延迟到达计算系统,并且已经迟到很久了,再计算已经没有意义,是否需要参与计算的问题
-
举个栗子:实时的统计双十一的累计成交额
-
订单1: 1亿
-
事件时间:11-11 23:59:58
-
达到时间:11-12 00:00:00
-
-
从业务角度考虑:没有对外公布总成交额,这条要参与计算
-
订单2: 1亿
-
事件时间:11-11 23:59:59
-
达到时间:12-12 00:00:00
-
-
从业务角度考虑:已经对外公布总成交额,这条不参与计算
-
从技术角度考虑:过期的数据计算浪费资源
-
-
==如果一条数据迟到的时间特别的久,已经对结果没有什么影响了,就不参与计算了==
-
==根据业务来设置一个水位线:如果高于水位线的数据就计算,如果低于水位线就不计算了==
-
假设:11-13 00点对外公布
-
如果数据延迟1天达到,计算
-
如果数据延迟超过1天:不计算
-
-
-
延迟时间:1天
-
官方的图例
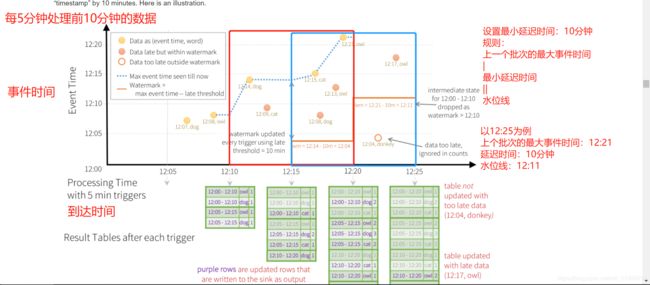
-
水位线的计算规则
水位线 = 上个批次的最大事件时间 - 延迟时间 -
代码中设置水位
// TODO:设置水位Watermark .withWatermark("time", "10 seconds")
-
-
测试实现
-
-
-
dog,2019-10-10 12:00:07 owl,2019-10-10 12:00:08 dog,2019-10-10 12:00:14 cat,2019-10-10 12:00:09 cat,2019-10-10 12:00:15 dog,2019-10-10 12:00:08 owl,2019-10-10 12:00:13 owl,2019-10-10 12:00:21 owl,2019-10-10 12:00:04 owl,2019-10-10 12:00:20 -
代码测试
package bigdata.spark.struct.window import java.sql.Timestamp import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger} import org.apache.spark.sql.{DataFrame, SparkSession} /** * 基于Structured Streaming 读取TCP Socket读取数据,事件时间窗口统计词频,将结果打印到控制台 * TODO:每5秒钟统计最近10秒内的数据(词频:WordCount),设置水位Watermark时间为10秒 */ object StructuredWatermarkUpdate { def main(args: Array[String]): Unit = { // 1. 构建SparkSession实例对象,传递sparkConf参数 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") .config("spark.sql.shuffle.partitions", "2") .getOrCreate() // b. 导入隐式转换及函数库 import org.apache.spark.sql.functions._ import spark.implicits._ spark.sparkContext.setLogLevel("WARN") // 2. 使用SparkSession从TCP Socket读取流式数据 val inputStreamDF: DataFrame = spark.readStream .format("socket") .option("host", "node1") .option("port", 9999) .load() // 3. 针对获取流式DStream设置EventTime窗口及Watermark水位限制 val resultStreamDF = inputStreamDF // 将DataFrame转换为Dataset操作,Dataset是类型安全,强类型 .as[String] // 过滤无效数据 .filter(line => null != line && line.trim.length > 0) // 将每行数据进行分割单词: 2019-10-12 09:00:02,cat dog .map{line => val arr = line.trim.split(",") (arr(0), Timestamp.valueOf(arr(1))) } // 设置列的名称 .toDF("word", "time") // TODO:设置水位Watermark .withWatermark("time", "10 seconds") // TODO:设置基于事件时间(event time)窗口 -> time, 每5秒统计最近10秒内数据 .groupBy( window($"time", "10 seconds", "5 seconds"), $"word" ).count() // 4. 将计算的结果输出,打印到控制台 val query: StreamingQuery = resultStreamDF.writeStream .outputMode(OutputMode.Update()) .format("console") .option("numRows", "100") .option("truncate", "false") .trigger(Trigger.ProcessingTime("5 seconds")) .start() // 流式DataFrame,需要启动 // 查询器一直等待流式应用结束 query.awaitTermination() query.stop() } }
结果
+------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:00, 2019-10-10 12:00:10]|dog |2 | |[2019-10-10 12:00:00, 2019-10-10 12:00:10]|cat |1 | |[2019-10-10 12:00:10, 2019-10-10 12:00:20]|cat |1 | |[2019-10-10 12:00:00, 2019-10-10 12:00:10]|owl |1 | |[2019-10-10 12:00:10, 2019-10-10 12:00:20]|dog |1 | |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|dog |3 | |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|cat |1 | |[2019-10-10 12:00:15, 2019-10-10 12:00:25]|cat |1 | |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|owl |2 | |[2019-10-10 12:00:10, 2019-10-10 12:00:20]|owl |2 | |[2019-10-10 12:00:15, 2019-10-10 12:00:25]|owl |2 | |[2019-10-10 12:00:20, 2019-10-10 12:00:30]|owl |1 | +------------------------------------------+----+-----+ -
-
小结
-
了解基于事件时间的延迟数据处理
-
附录一:Streaming Maven依赖
aliyun
http://maven.aliyun.com/nexus/content/groups/public/
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
jboss
http://repository.jboss.com/nexus/content/groups/public
2.11.12
2.11
2.4.5
2.6.0-cdh5.16.2
1.2.0-cdh5.16.2
2.0.0
8.0.19
3.2.0
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${scala.binary.version}
${spark.version}
org.apache.spark
spark-sql_${scala.binary.version}
${spark.version}
org.apache.spark
spark-sql-kafka-0-10_${scala.binary.version}
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hbase
hbase-server
${hbase.version}
org.apache.hbase
hbase-hadoop2-compat
${hbase.version}
org.apache.hbase
hbase-client
${hbase.version}
org.apache.kafka
kafka-clients
2.0.0
mysql
mysql-connector-java
${mysql.version}
redis.clients
jedis
${jedis.version}
com.alibaba
fastjson
1.2.47
target/classes
target/test-classes
${project.basedir}/src/main/resources
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile