高级软件工程——学习总结
本学期选修了孟宁老师的《高级软件工程》,在本课程中学习了工具、需求分析设计等内容,让我理解了软件工程的意义。
这门课从一个更高的层面加深了我对软件、对软件工程的认知,软件工程师不是一个只负责写代码的人物,软件工程师需要从各个角度把握软件开发,需要从用户角度、产品角度、管理角度等等。这门课程还通过实验,通过menu的案例逐步深入,从一开始的直接实现到增加linktable,让我实际理解了软件接口,高内聚低耦合的实现,让我更加深刻地理解了软件开发过程中需要注意的事项。
以下是这门课的知识点总结:
CH1 工欲善其事必先利其器
1 VS Code
优点:
•简洁而聚焦的产品定位,贯穿始终
•进程隔离的插件模型
•UI 渲染与业务逻辑隔离,一致的用户体验
•代码理解和调试——LSP和DAP两大协议
•集大成的 Remote Development
VS Code专注于开发者“最常用”的功能:编辑器+代码理解+版本控制+远程开发+调试。这是一个非常节制而平衡的选择
进程隔离:进程隔离的插件模型。
易用性:
UI 渲染与业务逻辑隔离。所有用户的操作被转化为各种请求发送给插件进程,插件能做的就是响应这些请求,插件进程只能专注于业务逻辑处理,从而做到从始至终插件都不能“决定”或者“影响”界面元素如何被渲染
代码理解和调试——LSP和DAP两大协议:
•代码理解和调试,绝大部分功能都是由第三方插件来实现的,这些用于代码理解和调试的第三方插件与VS Code主进程之间的桥梁就是两大协议——Language Server Protocol(LSP)和 Debug Adapter Protocol(DAP)。
LSP
多语言支持的基础就是Language Server Protocol(LSP):可以在一个工作区搞定多种语言(python,go……)且轻量和快速
1、节制的设计 :做最小子集
2、合理的抽象 :LSP 的大部分请求都是在表达”在指定位置执行规定动作“。抽象成请求(Request)和回复(Response),同时规定了它们的规格(Schema)
3、周全的细节。
VSCRD(远程开发)
•响应迅速:VSCRD 所有的交互都在本地 UI 内完成,响应迅速;远程桌面由于传输的是截屏画面,数据往返延迟很大,卡顿是常态。——进程级别隔离的插件模型
•沿用本地设置:VSCRD 的 UI 运行在本地,遵从所有本地设置,所以你依然可以使用自己所习惯的快捷键、布局、字体,避免了工作效率层面的开销。——UI 渲染与插件逻辑隔离,整齐划一的插件行为
•数据传输开销小:远程桌面传输的是视频数据,而 VS Code 传输是操作请求和响应,开销与命令行相仿,卡顿的情况进一步改善。——高效的协议LSP
•第三方插件可用:在远程工作区里,不仅VS Code的原生功能可用,所有第三方插件的功能依然可用;远程桌面的话,你得自己一个个装好。——UI 渲染与插件逻辑隔离,整齐划一的插件行为
•远程文件系统可用:远程文件系统被完整映射到本地,这个两者差不多。——进程级别隔离的插件模型
2 Git
•独立文件方式,比如另存为
•补丁方式,比如diff(只有这两种版本控制方式)
版本控制系统(2种类型)
•中心版本控制系统,比如Concurrent Versions System/cvs和Subversion/svn
•分布式版本控制系统,比如Git,是目前世界上最先进的分布式版本控制系统(没有之一)(利于社区化)
命令

-
可能有多个branch,至少有一个叫master
-
git init # 在一个新建的目录下创建版本库
-
git clone https://github.com/YOUR_NAME/REPO_NAME.git # 通过clone远端的版本库从而在 本地创建一个版本库
-
git add [FILES] # 把文件添加到暂存区(Index)
-
git commit m “wrote a commit log infro” # 把暂存区里的文件提交到仓库
-
git log # 查看当前HEAD之前的提交记录,便于回到过去
-
git reset —hard HEAD^^/HEAD~100/commitid/commitid的头几个字符 # 回退
-
git reflog # 可以查看当前HEAD之后的提交记录,便于回到未来
-
git reset —hard commitid/commitid的头几个字符 # 回退
-
git clone命令官方的解释是“Clone a repository into a new directory”,即克隆一个存储库到一 个新的目录下。
-
git fetch命令官方的解释是“Download objects and refs from another repository”,即下载一个远程存储库数据对象等信息到本地存储库。
-
git push命令官方的解释是“Update remote refs along with associated objects”,即将本地存储 库的相关数据对象更新到远程存储库。
-
git merge命令官方的解释是“Join two or more development histories together”,即合并两个 或多个开发历史记录。
-
git pull命令官方的解释是“Fetch from and integrate with another repository or a local branch”,即从其他存储库或分支抓取并合并到当前存储库的当前分支。
-
过去和未来之间的分界点就是HEAD,即当前工作区所依赖的版本。
-
line diff是形成增量补丁的技术方法,即一个文件按行对比(line diff)将差异的部分制作成一个增量补丁。
commit是存储到仓库里的一个版本,是整个项目范围内的一个或多个文件的增量补丁合并起来,形成项目的增量补丁,是一次提交记录。每个提交(commit)都生成一个唯一的commit ID。
branch是按时间线依次排列的一组提交记录(commit),理论上可以通过当前branch上最初的提交(commit)依次打补丁直到HEAD得到当前工作区里的源代码。
tag标签就是某次提交(commit)的commit ID的别名。
-
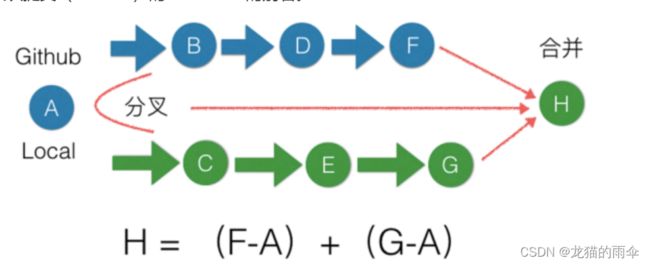
默认的合并方式为”快进式合并”(fastfarward merge):会将分支里commit合并到主分支里,合并成一条时间线,与我们期望的呈现为一段独立的分支线段不符,因此合并时需要使用--no-ff参数关闭"快进式合并"(fast-farward merge)。

-
git checkout b mybranch 创建新的分支
-
git branch 切换分支
-
git rebase i [startpoint] [endpoint]
#团队项目中的分叉合并 git clone https://DOMAIN_NAME/YOUR_NAME/REPO_NAME.git git pull git checkout -b mybranch git branch git add FILES git commit -m "commit log" git checkout master git pull git merge --no-ff mybranch git push
3 正则化
- 通配符“.”将匹配任意一个字符。通配符也可称为 dot 和 period。你可以像正则表达式中的任何其他字符一样使用通配符。例如,如果你想匹配“hug”,“huh”,“hut”和“hum”,可以使用正则表达式hu.来匹配这所有四个字符串。
- 通配符“+”用来查找出现一次或多次的字符,例如hahhhhh,可以使用正则表达式hah+来匹配。
- 通配符“”匹配零次或多次出现的字符,使用正则表达式hah来匹配,还可以匹配ha字符串。
- 通配符“?”指定可能存在的元素,也就是检查前一个元素存在与否,如正则表达式colou?r、favou?rite中通配符“?”前面的u字符存在和不存在两种情况的字符串都会匹配
例子:
要匹配字符串"aaah"中出现 3 到 5 次的 a,你的正则表达式将是a{3,5}h;
仅匹配字符串"haaah"与至少出现 3 次的字母 a,正则表达式将是/ha{3,}h;
为了仅匹配"hah"中出现 3 次的字母 a,你的正则表达式将是/ha{3}h。
贪婪匹配 vs. 懒惰匹配
CH 2 代码中的软件工程 工程化编程实战
menu代码实践
代码风格的原则:简明、易读、无二义性
代码的基本结构分为:•顺序执行•条件分支•循环结构•还有很多语言中支持的递归结构。
通过数据结构简化代码
一定要有错误处理:•肯定如何时用断言;可能发生时用错误处理。
拒绝修修补补要不断重构代码:开闭原则(对扩展开放,对修改关闭)
模块化软件设计(高内聚 低耦合)
模块化是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发
一般我们使用耦合度(Coupling)和内聚度(Cohesion)来衡量软件模块化的程度:追求松散耦合,功能内聚(理想的内聚是功能内聚,也就是一个软件模块只做一件事,只完成一个主要功能点或者一个软件特性(Feather))
KISS(Keep It Simple & Stupid)原则
-
一行代码只做一件事
-
一个块代码只做一件事
-
一个函数只做一件事
-
一个软件模块只做一件事
•使用本地化外部接口来提高代码的适应能力(隔离)
•先写伪代码的代码结构更好一些
可重用软件设计
•消费者重用和生产者重用
通用的模块才有更多重用的机会;
给软件模块设计通用的接口,并对接口进行清晰完善的定义描述;
记录下发现的缺陷及修订缺陷的情况;
使用清晰一致的命名规则;
对用到的数据结构和算法要给出清晰的文档描述;
与外部的参数传递及错误处理部分要单独存放易于修改
接口
接口就是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。
接口具体定义了软件模块对系统的其他部分提供了怎样的服务,以及系统的其他部分如何访问所提供的服务。
在面向过程的编程中,接口一般定义了数据结构及操作这些数据结构的函数;
而在面向对象的编程中,接口是对象对外开放(public)的一组属性和方法的集合。函数或方法具体包括名称、参数和返回值等。
接口规格包含五个基本要素:
•接口的目的;——函数的方法、名称
•接口使用前所需要满足的条件,一般称为前置条件或假定条件;
•使用接口的双方遵守的协议规范;
•接口使用之后的效果,一般称为后置条件;
•接口所隐含的质量属性。
Call-in方式的函数接口和Callback方式的函数接口
见linktable
微服务接口RESTful API
由一系列独立的微服务共同组成软件系统的一种架构模式;系统中的各微服务是分布式管理的,各微服务之间非常强调隔离性
•传统单体集中式架构是适应大型机、小型机单体服务器环境的软件架构模式;微服务架构则是为了适应PC服务器的大规模集群及基于虚拟化技术和分布式计算的云计算环境的架构模式。
•微服务接口一般使用RESTful API来定义接口。RESTful API是目前最流行的一种互联网软件接口定义方式(web)。它结构清晰、符合标准、易于理解、扩展方便,得到了越来越多网站的采用。
•在微服务接口举例之前,我们先需要简单的理解微服务架构和RESTful API的基本概念。
•缺点:传输性能不是很理想——RPC框架可以解决该问题
•很早使用较多的有socket api
http+json一起定义接口
在模块化思想的指导下目前主要有两种软件架构模式,即传统单体集中式(Monolithic)架构与微服务(Microservice)架构
RESTful API状态转化就是通过HTTP协议里定义的四个表示操作方式的动词:GET、POST、PUT、DELETE,分别对应四种基本操作:
-
GET用来获取资源;
-
POST用来新建资源(也可以用于更新资源);
-
PUT用来更新资源;
-
DELETE用来删除资源
我们以手写识别微服务https://api.website.cn/service/ocr-handwriting 为例来理解接口规格包含的五个基本要素。
如下为调用微服务ocr-handwriting的HTTP请求信息简易示意代码。
POST /service/ocr-handwriting?code=auth_code HTTP/1.1 Content-Type: image/png [content of handwriting.png]
-
该微服务接口的目标是手写识别服务,通过微服务命名ocr-handwriting来表明接口的目的;
-
该微服务接口的前置条件包括取得调用该微服务接口的授权auth_code,以及已经有一张手写图片handwriting.png
-
调用该微服务接口的双方遵守的协议规范除HTTP协议外还包括PNG图片格式和识别结果JSON数据格式定义;
-
调用该微服务接口的效果即后置条件为以JSON数据的方式得到了识别的结果;
-
从以上示意代码中该微服务接口的质量属性没有具体指定,但因为底层使用了TCP协议,因此该接口隐含的响应时间质量属性应小于TCP连接超时定时器
通用Linktable模块的接口
与业务分离
优势:
-
上下层分离(业务、数据分离)
-
便于模块化(松散耦合,防止软件危机)
下层只知道传数据(指针),不关心数据本身
call-in callback(作业3:深入理解Callback函数_龙猫的雨伞的博客-CSDN博客)
给Linktable增加Callback方式的接口,需要两个函数接口,一个是call-in方式函数,如SearchLinkTableNode函数,其中有一个函数作为参数,这个作为参数的函数就是callback函数,如代码中Conditon函数。
利用callback函数参数使Linktable的查询接口更加通用
接口与耦合度
一般可以分为紧密耦合(Tightly Coupled)、松散耦合(Loosely Coupled)和无耦合(Uncoupled)
更细致地对耦合度进一步划分的话,耦合度依次递增可以分为无耦合、数据耦合、标记耦合、控制耦合、公共耦合和内容耦合。这些耦合度划分的依据就是接口的定义方式,我们接下来重点分析一下公共耦合、数据耦合和标记耦合。
-
公共耦合(全局)
当软件模块之间共享数据区或变量名的软件模块之间即是公共耦合,显然两个软件模块之间的接口定义不是通过显式的调用方式,而是隐式的共享了共享了数据区或变量名。
-
数据耦合(简单参数值 而非控制参数 公共数据 外部变量)
在软件模块之间仅通过显式的调用传递基本数据类型即为数据耦合。
-
标记耦合
在软件模块之间仅通过显式的调用传递复杂的数据结构(结构化数据)即为标记耦合,这时数据的结构成为调用双方软件模块隐含的规格约定,因此耦合度要比数据耦合高。但相比公共耦合没有经过显式的调用传递数据的方式耦合度要低。
int AddLinkTableNode(tLinkTable *pLinkTable, tLinkTableNode * pNode)
传递的可能是一个隐含的存储区或数据结构,肯定不是数据耦合
通用接口定义的基本方法
-
参数化上下文(使用参数信息,不依赖上下文环境,即不使用封闭闭包)
-
移除前置条件(sum函数中使用数组传递参数,不再限定参数个数)
-
简化后置条件(移除参数之间的关系,使sum返回的是数组全部元素的和)
可重入函数与线程安全
指令乱序(reorder)问题
程序的代码执行顺序有可能被编译器或CPU根据某种策略打乱指令执行顺序,目的是提升程序的执行性能,让程序的执行尽可能并行,这就是所谓指令乱序问题。
软件设计人员可以在正确的位置告诉编译器或CPU哪里可以允许指令乱序,哪里不能接受指令乱序,从而在保证软件正确性的同时允许编译或执行层面的性能优化。
指令乱序问题需要分为三个层次,第1层是多线程编程中的业务逻辑层面的函数可重入性和线程安全问题;第2层是编译器编译优化造成的指令乱序;第3层是CPU乱序执行指令的问题。
线程(thread):操作系统能够进行运算调度的最小单位。它包含在进程之中,是进程中的实际运作单位。一个线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。一般默认一个进程中只包含一个线程。
pthread:创建空间,多个线程共有
多个执行流,共享一个临界区-----》线程安全
可重入函数(多线程)
可重入(reentrant)函数:可以由多于一个任务并发使用,而不必担心数据错误。相反,不可重入(non-reentrant)函数不能由超过一个任务所共享,除非能确保函数的互斥(或者使用信号量,或者在代码的关键部分禁用中断)。可重入函数可以在任意时刻被中断,稍后再继续运行,不会丢失数据。可重入函数要么使用局部变量,要么在使用全局变量时保护自己的数据。
可重入函数的基本要求
-
不为连续的调用持有静态数据;
-
不返回指向静态数据的指针;
-
所有数据都由函数的调用者提供;
-
使用局部变量,或者通过制作全局数据的局部变量拷贝来保护全局数据;
-
使用静态数据或全局变量时做周密的并行时序分析,通过临界区互斥避免临界区冲突;
-
绝不调用任何不可重入函数。
线程安全
线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
函数的可重入性与线程安全之间的关系
•可重入的函数不一定是线程安全的,可能是线程安全的也可能不是线程安全的;可重入的函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题;
• 不可重入的函数一定不是线程安全的。
互斥锁:
pthread_mutex_lock(&gplusplus);
pthread_mutex_unlock(&gplusplus);
但是互斥锁可能不一致
线程安全和指令乱序
可重入函数与线程安全本质上也是指令乱序执行问题,指令乱序问题本质上也是线程安全问题,
CPU指令执行的顺序一致性
因为指令集架构(ISA)中的指令和寄存器作为CPU的对外接口,CPU只需要把内部真实的物理寄存器按照指令的执行顺序,顺序映射到ISA寄存器上,也就是CPU只要将结果顺序地提交到ISA寄存器,就可以保证顺序一致性(Sequential consistency)。(单核单线程CPU上指令乱序问题被指令集架构所屏蔽)
多核多线程CPU上依然存在指令乱序执行的可能性——我们在写程序的时候需要加上内存屏障,例如X86上的mfence指令。
ARM64 CPU指令乱序
ARM64是弱内存序模型,因为精简指令集把访存指令和运算指令分开了,为了性能允许几乎所有的指令乱序,但前提是不影响程序的正确性。因此ARM64架构的指令乱序问题需要引入不同类型的barrier来保证程序的正确性
编译器指令乱序问题
代码定义的宏barrier()编译器屏障(compiler barriers):编译器不要优化重排指令顺序
工程化编程实战总结
三个不同角度来看待软件质量
-
产品的角度,也就是软件产品本身内在的质量特点;
-
用户的角度,也就是软件产品从外部来看是不是对用户有帮助,是不是有良好的用户体验;
-
商业的角度,也就是商业环境下软件产品的商业价值,比如投资回报或开发软件产品的其他驱动因素。
软件设计的方法和原则
设计方法论:不断地重构
几个重要的设计指导原则:
-
Modularity
-
Interfaces
-
Information hiding
-
Incremental development
-
Abstraction
-
Generality
CH3 从需求分析到软件设计
需求
需求分析就是需求分析师对用户期望的软件行为进行表述,并进一步用对象或实体的状态、属性和行为来定义需求。
需求就是对用户期望的软件行为的表述
获取需求就是需求分析师通过关注用户的期望和需要,从而获得用户期望的软件行为,然后对其进行表述的工作;
需求分析是在获取需求的基础上进一步对软件涉及的对象或实体的状态、特征和行为进行准确描述或建模的工作
需求的类型
-
功能需求:根据所需的活动描述所需的行为
-
质量需求或非功能需求:描述软件必须具备的一些质量特性
-
设计约束(设计约束): 设计决策,例如选择平台或接口组件
-
过程约束(过程约束): 对可用于构建系统的技术或资源的限制
高质量的需求
Making Requirements Testable(量化)
Resolving Conflicts(优先级)
Characteristics of Requirements(特性)
对需求进行分析和建模
-
原型化方法(Prototyping)和建模的方法(Modeling)
-
用例建模(Use Case Modeling)
-
面向对象分析涉及的基本概念
-
业务领域建模(Domain Modeling)
-
关联类及关系数据模型
-
关系数据模型的MongoDB设计与实现
原型化方法(Prototyping)和建模的方法(Modeling)是整理需求的两类基本方法。
原型化方法(需求分析+设计)
原型化方法可以很好地整理出用户接口方式(UI,User Interface),比如界面布局和交互操作过程。
需求分析(UI/UX与用户接口交互)+设计(可行性分析,关注软件结构)
建模的方法(可以抽象出key point)
建模的方法可以快速给出有关事件发生顺序或活动同步约束的问题,能够在逻辑上形成模型来整顿繁杂的需求细节
用例(对应用场景建模)
用例(Use Case)的核心概念中首先它是一个业务过程(business process),经过逻辑整理抽象出来的一个业务过程,这是用例的实质。
业务过程:在待开发软件所处的业务领域内完成特定业务任务(business task)的一系列活动就是业务过程。
基本要素:
-
A use case is initiated by (or begins with) an actor. 一个用例应该由业务领域内的某个参与者(Actor)所触发
-
A use case must accomplish a business task (for the actor).用例必须能为特定的参与者完成一个特定的业务任务。
-
A use case must end with an actor. 一个用例必须终止于某个特定参与者,也就是特定参与者明确地或者隐含地得到了业务任务完成的结果
用例的三个抽象层级
-
抽象用例(Abstract use case)。只要用一个干什么、做什么或完成什么业务任务的动名词短语,就可以非常精简地指明一个用例;
-
高层用例(High level use case)。需要给用例的范围划定一个边界,也就是用例在什么时候什么地方开始,以及在什么时候什么地方结束;
-
扩展用例(Expanded use case)。需要将参与者和待开发软件系统为了完成用例所规定的业务任务的交互过程一步一步详细地描述出来,一般我们使用一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来。
四个必要条件
-
必要条件一 :它是不是一个业务过程?
-
必要条件二:它是不是由某个参与者触发开始?
-
必要条件三:它是不是显式地或隐式地终止于某个参与者?
-
必要条件四: 它是不是为某个参与者完成了有用的业务工作?
用例建模的基本步骤
-
•第一步,从需求表述中找出用例,往往是动名词短语表示的抽象用例;
-
•第二步,描述用例开始和结束的状态,用TUCBW和TUCEW表示的高层用例;
-
•第三步,对用例按照子系统或不同的方面进行分类,描述用例与用例、用例与参与者之间的上下文关系,并画出用例图;
-
•第四步,进一步逐一分析用例与参与者的详细交互过程,完成一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来扩展用例。
-
•其中第一步到第三步是计划阶段,第四步是增量实现阶段。
准确提取用例的基本方法(考点)
4个必要条件
面向对象分析涉及的基本概念
-
对象(Object)和属性(Attribute)
-
继承关系(Inheritance Relationship)
-
聚合关系(Aggregation Relationship)
-
关联关系(Association Relationship)
对象(Object)和属性(Attribute)
一个对象作为某个类的实例,在业务领域内是能够独立存在的,属性往往不能独立存在。
显然对象和属性之间有依附关系,属性用来描述对象或存储对象的状态信息。
由于对象能够独立存在,那么对象的创建必须是通过显式地或隐式地调用构造过程(组合关系可独立)
继承关系
•继承关系表达着两个概念之间具有概括化/具体化(generalization/specialization)的关系。所以继承关系也被称为“是一种”(IS-A)关系。
聚合关系
part of关系
关联关系
•关联关系表示继承和聚合以外的一般关系,是业务领域内特定的两个概念之间的关系,
•既不是继承关系也不是聚合关系。比如教授参与了退休计划、讲师教授课程、用户拥有账户等都是两个概念之间一般关系,我们用一个直线连起来来表示教授和退休计划两个业务领域概念之间的关联关系
业务领域建模的基本步骤
业务领域建模是开发团队用于获取业务领域知识的过程。
-
第一步,收集应用业务领域的信息。聚焦在功能需求层面,也考虑其他类型的需求和资料;
-
第二步,头脑风暴。列出重要的应用业务领域概念,给出这些概念的属性,以及这些概念之间的关系;
-
第三步,给这些应用业务领域概念分类。分别列出哪些是类、哪些属性和属性值、以及列出类之间的继承关系、聚合关系和关联关系。
-
第四步,将结果用 UML 类图画出来。
第一步更多地在获取需求的阶段已经完成,这里不做赘述;第四步 UML 类图的画法前面已经给出,接下来我们重点将头脑风暴的做法和业务领域概念分类的方法具体探讨一下
关联类及数据模型
关系数据模型的MongoDB设计与实现
One-to-Few 内嵌文档是很合适
One-to-Many (间接引用 子应用)
这个用例很适合使用间接引用---将零件的objectid作为数组存放在商品文档中(在这个例子中的ObjectID我使用更加易读的2字节,正常是由12个字节组成的)。
One-to-Squillions(父引用)
•我们用一个收集各种机器日志的例子来讨论一对非常多的问题。由于每个mongodb的文档有16M的大小限制,所以即使你是存储ObjectID也是不够的。我们可以使用很经典的处理方法“父级引用”---用一个文档存储主机,在每个日志文档中保存这个主机的ObjectID。
三种基本的设计方案:内嵌,子引用,父引用
在选择方案时需要考虑的两个关键因素:1)一对多中的多是否需要一个单独的实体;2)这个关系中集合的规模是一对很少,很多,还是非常多。
-
一对很少且不需要单独访问内嵌内容的情况下可以使用内嵌多的一方。
-
一对很多且很多的一端内容因为各种理由需要单独存在的情况下可以通过数组的方式引用多的一方的。
-
一对非常多的情况下,请将一的那端引用嵌入进多的一端对象中。
性能优先有一定的代价:时间、空间-----》冗余
传统数据库:DB-------反范式:冗余表达关系,减少查询时间代价
反范式化意味着你不需要执行一个应用层级别的join去显示一个产品所有的零件名字,当然如果你同时还需要其他零件信息那这个应用层的join是避免不了的
双向关联Two-Way Referencing
反范式化
在一个读比写频率高的多的系统里,反范式是有使用的意义的
(子应用,在高并发场景下可以快速得到信息,但是维护成本高)
-
使用双向引用来优化你的数据库架构,前提是你能接受无法原子更新的代价。
-
可以在引用关系中冗余数据到one端或者N端。
-
在决定是否采用反范式化时需要考虑下面的因素:
-
你将无法对冗余的数据进行原子更新。
-
只有读写比比较高的情况下才应该采取反范式化的设计。
-
业务概念原型

从需求分析到软件设计
•敏捷统一过程(Agile Unified Process)
•对象交互建模(Object Interaction Modeling)
•形成软件设计方案的基本方法
瀑布模型
瀑布模型是最基本的过程模型,它把整个软件过程按顺序划分成了需求、设计、编码、测试和部署五个阶段。瀑布模型的根本特点是按顺序划分阶段。
统一过程
统一过程的核心要义是用例驱动、以架构为中心、增量且迭代的过程。用例驱动就是我们前文中用例建模得到的用例作为驱动软件开发的目标;以架构为中心的架构是后续软件设计的结果,就是保持软件架构相对稳定,减小软件架构层面的重构造成的混乱;增量且迭代
(开闭原则:开--用例;闭--架构)
敏捷统一过程的计划阶段
敏捷统一过程(Agile Unified Process)进一步将软件过程中每一次迭代过程划分为计划阶段和增量阶段
-
首先明确项目的动机、业务上的实际需求,以及对项目动机和业务需求可供替代选择的多种可能性;
-
然后充分调研获取需求并明确定义需求规格;
-
在明确需求规格的基础上进行项目的可行性研究;
-
如果项目可行,接下来接着进行用例建模并给出用例图;
-
同时明确需求和用例之间的可跟踪矩阵;
-
从而形成项目的概念模型草案;
-
以及项目可能的日程安排、需要的资源以及大致的预算范围。
-
第一,确定需求;
-
第二,通过用例的方式来满足这些需求;
-
第三,分配这些用例到各增量阶段;
-
第四,具体完成各增量阶段所计划的任务。
显然,第一到第三步主要是计划阶段的工作,第四步是接下来要进一步详述的增量阶段的工作。
敏捷统一过程将增量阶段分为五个步骤:
-
用例建模(Use case modeling);
-
业务领域建模(Domain modeling);
-
对象交互建模(Object Interaction modeling);
-
形成设计类图(design class diagram);
-
软件的编码实现和软件应用部署;
整个敏捷统一过程中每一次迭代过程的增量阶段的工作流程我们可以总结成如流程示意图:

对象交互建模
-
找出关键步骤进行剧情描述(scenario)
-
将剧情描述(scenario)转换成剧情描述表(scenario table)
-
将剧情描述表转换成序列图的基本方法
-
从分析序列图到设计序列图
-
一个完整用例的对象交互建模
从分析序列图到设计序列图
首先我们需要理解分析和设计的区别,我们可以大致总结成如下几点:
-
目的不同。分析为了搞清楚应用问题;而设计为了找出软件解决方案;
-
建模的对象不同。分析是对应用业务领域建模;而设计是对待开发的软件系统建模;
-
一个是描述(describes),一个说明(prescribes)。分析是对应用业务实际情况的描述,业务实际情况是客观存在;设计是待开发的软件解决方案如何实现应用业务的说明,软件实际上还不存在;
-
决策的依据不同;分析是基于应用问题的项目做决策;设计是基于待开发的软件系统做决策;
-
分析时应该允许多种不同的设计方案;而设计通常会减少实现上的可选择性。
总结
•这一部分我们以面向对象的分析和设计为思想方法的主线,提供了一种从需求分析到软件设计的基本建模方法,相信您完整地学习了这种从需求分析到软件设计的基本建模方法之后,您对面向对象的概念有了切身体会。
•以对象作为基本元素构建起来了一种主流的看待软件的范型,形成了从编程语言、UML、开发方法、设计模式、软件架构以及工程思想方法等一系列成果。
面向对象方法本身也引入了不是软件所固有的一些复杂性,试图以坚实的科学模型基础来建构软件世界的努力逐渐重新走入经验主义的巢臼。比如设计模式就是典型的经验模型;再比如最新的一些语言特性融合了面向过程编程的优点以及函数式编程的优点;甚至软件开发方法也走向了颇具工匠精神的思路,不断迭代和重构来优化软件设计以及代码结构。这些都让我们重新审视将抽象的对象作为认识软件的基础是否根基牢固
CH4 软件科学基础概论
软件
软件的基本构成元素
-
对象(Object)
-
函数和变量/常量
-
指令和操作数
-
0和1是什么?
1 对象(Object)
一个对象作为某个类的实例,是属性和方法的集合。对象和属性之间有依附关系,属性用来描述对象或存储对象的状态信息,属性也可以是一个对象。对象能够独立存在,对象的创建和销毁显式地或隐式地对应着构造方法(constructor)和析构方法(destructor) 。
面向对象是一种对软件抽象封装的方法
2 函数和变量/常量
函数和变量/常量作为软件基本元素的抽象方法。
面向对象是一种更高层的软件抽象封装的方法,其中方法大致对应函数,属性大致对应变量/常量。
从低地址到高地址分别内存区分别为代码段、已初始化数据段、未初始化数据段(BSS)、堆、栈和命令行参数和环境变量
-
全局常量(const)、字符串常量、函数以及编译时可决定的某些东西一般存储在代码段(text);
-
初始化的全局变量、初始化的静态变量(包括全局的和局部的)存储在已初始化数据段;
-
未初始化的全局变量、未初始化的静态变量(包括全局的和局部的)存储在未初始化数据段(BSS);
-
动态内存分配(malloc、new等)存储在堆(heap)中;
-
局部变量(初始化以及未初始化的,但不包含静态变量)、局部常量(const)存储在栈(stack)中;
-
命令行参数和环境变量存储在与栈底紧挨着的位置。
如果我们堆和栈扩大,把命令行参数和环境变量作为调用main函数的栈空间,把已初始化数据段和未初始化数据段(BSS)作为扩大的堆空间的一个部分,我们就可以简单化为代码+堆栈的地址空间分布,而且这种简单化与面向过程的软件抽象元素函数和变量/常量保持逻辑一致。
3 指令和操作数
指令(instruction)是由 CPU 加载和执行的软件基本单元。一般指令可以表述为指令码+操作数。
指令码可以是二进制的机器指令编码,也可以是八进制的编码,程序员更喜欢用汇编语言指令助记符,如 mov、add 和 sub,给出了指令执行操作的线索。
操作数有 3 种基本类型:立即数,用数字文本表示的数值;寄存器操作数,使用 CPU 内已命名的寄存器;内存操作数,引用内存位置
4 0/1
哲学问题
软件的基本结构
-
顺序结构
-
分支结构
-
循环结构
-
函数调用框架
-
继承和对象组合
2 分支结构(向后跳转)
利用影响标志寄存器上标志位的指令和跳转指令组合起来借助于标志寄存器或特定寄存器暂存条件状态实现分支结构
goto语句有害
3 循环结构(向前跳转)
4 函数调用框架(栈)
函数调用框架是以函数作为基本元素,并借助于堆叠起来的堆栈数据,所形成的一种更为复杂的程序结构。堆叠起来的堆栈数据用来记录函数调用框架结构的信息,是函数调用框架的灵魂
-
esp,堆栈指针寄存器(stack pointer)。
-
ebp,基址指针寄存器(base pointer)。
-
eip,指令指针寄存器,为了安全考虑程序无权修改该寄存器,只能通过专用指令修改该寄存器,比如call和ret。
-
push,压栈指令,由于X86体系结构下栈顶从高地址向低地址增长,所以压栈时栈顶地址减少4个字节。
-
popl,出栈指令,栈顶地址增加4个字节。
-
call,函数调用指令,该指令负责将当前eip指向的下一条指令地址压栈,然后设置eip指向被调用程序代码开始处,即pushl eip和eip = 函数名(指针)。
-
ret,函数返回指令,该指令负责将栈顶数据放入eip寄存器,即popl eip,此时的栈顶数据应该正好是call指令压栈的下一条指令地址。
(ret与popl:程序不可修改eip,所以用ret)
-
注意以e开头的寄存器位32位寄存器,指令结尾的l是指long,也就是操作4个字节数据的指令。
•函数调用过程中ebp寄存器用作记录当前函数调用基址,当调用一个函数时首先建立该函数的堆栈框架,函数返回时拆除该函数的堆栈框架,大致如下示意图所示。
•随着函数调用一层层深入,堆栈上依次建立一层层逻辑上的堆栈堆叠起来;随着函数一层层返回上一级函数,堆叠起来的逻辑上的堆栈也一层层拆除。
•就这样函数调用框架借助堆叠起来的函数堆栈框架形成了一种复杂而缜密的程序结构。
5 继承和对象组合
继承:紧密耦合(在代码上无明确界线,造成父类与子类紧密耦合);对象组合:松耦合
但是面向对象的真正威力是封装,而非继承
继承可以重用代码,但是破坏了代码的封装特性,增加了父类与子类之间的代码模块耦合,因此我们需要避免使用继承,在大多数情况下,应该使用对象组合替代继承来实现相同的目标。
软件中的一些特殊机制
面向对象有三个关键的概念:继承(Inheritance)、对象组合(object composition)和多态(polymorphism),其中多态是一种比较特殊的机制,另外还有回调函数(callback)、闭包(closure)、异步调用和匿名函数也经常用到特殊机制。
-
回调函数
-
多态
-
闭包
-
异步调用
-
匿名函数
1 回调函数(函数指针 callin callback)
回调函数是一个面向过程的概念,是代码执行过程的一种特殊流程。回调函数就是一个通过函数指针调用的函数。把函数的指针(地址)作为参数传递给另一个函数,当这个指针调用其所指向的函数时,就称这是回调函数。回调函数不是该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
callback没有打破函数调用框架
2 多态
在面向对象语言中,接口的多种不同的实现方式即为多态。多态是实例化变量可以指向不同的实例对象,这样同一个实例化变量在不同的实例对象上下文环境中执行不同的代码表现出不同的行为状态,而通过实例化变量调用实例对象的方法的那一块代码却是完全相同的,这就顾名思义,同一段代码执行时却表现出不同的行为状态,因而叫多态。简单的说,可以理解为允许将不同的子类类型的对象动态赋值给父类类型的变量,通过父类的变量调用方法在执行时实际执行的可能是不同的子类对象方法,因而表现出不同的执行效果。
3 闭包
闭包是变量作用域的一种特殊情形,一般用在将函数作为返回值时,该函数执行所需的上下文环境也作为返回的函数对象的一部分,这样该函数对象就是一个闭包。
函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起构成闭包(closure)。也就是说,闭包可以让你从内部函数访问外部函数作用域
4 异步调用(java)
Promise对象可以将异步调用以同步调用的流程表达出来,避免了通过嵌套回调函数实现异步调用。
5 匿名函数
lamda函数、比如无参数的代码块{ code },或者箭头函数 { x => code }
软件的内在特性
软件的基本特点是前所未有的复杂度和易变性(软件危机),为了降低复杂度我们在不同层面大量采用抽象方法建立软件概念模型;为了应对易变性我们努力保持软件设计和实现上的完整性和一致性。
-
前所未有的复杂度
-
抽象思维 vs. 逻辑思维
-
唯一不变的就是变化本身
-
难以达成的概念完整性和一致性
系统分成三种类型:

S系统、P系统和E系统。
S:不怎么需要维护
P:解决近似问题
E:E系统很好地解释了软件易变性的本质原因。我们常见的绝大多数软件都属于E系统
软件设计模式初步
设计模式涉及的基本概念
在面向对象分析中我们涉及到了类、对象、属性以及类与类之间的关系,在此基础上我们进一步理解面向对象设计和实现所涉及的基本术语之间的关系
继承(Inheritance)和对象组合(object composition)
•继承可以重用代码,但是破坏了代码的封装特性,增加了父类与子类之间的代码模块耦合,因此我们需要避免使用继承,在大多数情况下,应该使用对象组合替代继承来实现相同的目标。
多态Polymorphism
回调函数(callback)、闭包(closure)和lamda函数
什么是设计模式?
设计模式的本质是面向对象设计原则的实际运用总结出的经验模型。对类的封装性、继承性和多态性以及类的关联关系和组合关系的充分理解的基础上才能准确理解设计模式。
正确使用设计模式具有以下优点。
-
可以提高程序员的思维能力、编程能力和设计能力。
-
使程序设计更加标准化、代码编制更加工程化,使软件开发效率大大提高,从而缩短软件的开发周期。
-
使设计的代码可重用性高、可读性强、可靠性高、灵活性好、可维护性强。
设计模式要解决的问题
代码的复杂性和易变性
包容变化
用模块化来包容变化,使用模块化封装的方法,按照模块化追求的高内聚低耦合目标,借助于抽象思维对模块内部信息的隐藏并使用封装接口对外只暴露必要的可见信息,利用多态、闭包、lamda函数、回调函数等特殊的机制方法,将变化的部分和不变的部分进行适当隔离。
设计模式一般由四个部分组成
-
该设计模式的名称;
-
该设计模式的目的,即该设计模式要解决什么样的问题;
-
该设计模式的解决方案;
-
该设计模式的解决方案有哪些约束和限制条件。
设计模式的分类
主要用于根据模式是主要用于类上还是主要用于对象上来划分的话,可分为类模式和对象模式两种类型的设计模式:
-
类模式:用于处理类与子类之间的关系,这些关系通过继承来建立,是静态的,在编译时刻便确定下来了。比如模板方法模式等属于类模式。
-
对象模式:用于处理对象之间的关系,这些关系可以通过组合或聚合来实现,在运行时刻是可以变化的,更具动态性。由于组合关系或聚合关系比继承关系耦合度低,因此多数设计模式都是对象模式
根据设计模式可以完成的任务类型来划分的话,可以分为创建型模式、结构型模式和行为型模式 3 种类型的设计模式:
-
创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。比如单例模式、原型模式、建造者模式等属于创建型模式。
-
单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点供外部获取该实例,典型的应用如数据库实例。
-
原型(Prototype)模式:将一个对象作为原型,通过对其进行复制而克隆出多个和原型类似的新实例,原型模式的应用场景非常多,几乎所有通过复制的方式创建新实例的场景都有原型模式。
-
建造者(Builder)模式:将一个复杂对象分解成多个相对简单的部分,然后根据不同需要分别创建它们,最后构建成该复杂对象。主要应用于复杂对象中的各部分的建造顺序相对固定或者创建复杂对象的算法独立于各组成部分。
-
-
结构型模式:用于描述如何将类或对象按某种布局组成更大的结构,比如代理模式、适配器模式、桥接模式、装饰模式、外观模式、享元模式、组合模式等属于结构型模式。结构型模式分为类结构型模式和对象结构型模式,前者采用继承机制来组织接口和类,后者釆用组合或聚合来组合对象。由于组合关系或聚合关系比继承关系耦合度低,所以对象结构型模式比类结构型模式具有更大的灵活性。
-
代理(Proxy)模式:为某对象提供一种代理以控制对该对象的访问。即客户端通过代理间接地访问该对象,从而限制、增强或修改该对象的一些特性。代理模式是不要和陌生人说话原则的体现,典型的应用如外部接口本地化将外部的输入和输出封装成本地接口,有效降低模块与外部的耦合度。
-
适配器(Adapter)模式:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。继承和对象组合都可以实现适配器模式,但由于组合关系或聚合关系比继承关系耦合度低,所以对象组合方式的适配器模式比较常用。
-
装饰(Decorator)模式:在不改变现有对象结构的情况下,动态地给对象增加一些职责,即增加其额外的功能。装饰模式实质上是用对象组合的方式扩展功能,因为比继承的方式扩展功能耦合度低。装饰模式在 Java 语言中的最著名的应用莫过于 Java I/O 标准库的设计了
-
外观(Facade)模式:为复杂的子系统提供一个一致的接口,使这些子系统更加容易被访问。
-
享元(Flyweight)模式:运用共享技术来有效地支持大量细粒度对象的复用。比如线程池、固定分配存储空间的消息队列等往往都是该模式的应用场景。
-
-
行为型模式:用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。比如模板方法模式、策略模式、命令模式、职责链模式、观察者模式等属于行为型模式。行为型模式分为类行为模式和对象行为模式,前者采用继承在类间分配行为,后者采用组合或聚合在对象间分配行为。由于组合关系或聚合关系比继承关系耦合度低,所以对象行为模式比类行为模式具有更大的灵活性。
-
策略(Strategy)模式:定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的改变不会影响使用算法的客户。策略模式是多态和对象组合的综合应用。
-
命令(Command)模式:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行储存、传递、调用、增加与管理。
-
模板方法(TemplateMethod)模式:定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。模版方法是继承和重载机制的应用,属于类模式。
-
职责链(Chain of Responsibility)模式:为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。通过这种方式将多个请求处理者串联为一个链表,去除请求发送者与它们之间的耦合。
-
中介者(Mediator)模式:定义一个中介对象来简化原有对象之间的交互关系,降低系统中对象间的耦合度,使原有对象之间不必相互了解。在 MVC 框架中,控制器(C)就是模型(M)和视图(V)的中介者,采用“中介者模式”大大降低了对象之间的耦合性,提高系统的灵活性。
-
观察者模式(见后,考点)
-
七大原则
-
单一职责原则 (Single Responsibility Principle)
-
开放关闭原则 (OpenClosed Principle) (软件应当对扩展开放,对修改关闭)
-
Liskov替换原则 (Liskov Substitution Principle)
子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。如果通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的概率会非常大
-
依赖倒转原则 (Dependence Inversion Principle)
高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节 应该依赖抽象 由于在软件设计中,细节具有多变性,而抽象层则相对稳定,因此以抽象为基础搭建 起来的架构要比以细节为基础搭建起来的架构要稳定得多。 依赖倒置原则在模块化设计中降低模块之间的耦合度和加强模块的抽象封装提高模块 的内聚度上具有普遍的指导意义
-
迪米特法则(Law Of Demeter)
可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性
-
合成复用原则 (Composite/Aggregate Reuse Principle)
它要求在软件复用时,要尽量先使用组合或者聚合关系来实现
继承:破坏类的封装性;父类子类耦合度高;限制复用灵活性
合成:维持类的封装性;耦合度低;灵活性高
观察者模式
观察者(Observer)模式:指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,把这种改变通知给其他多个对象,从而影响其他对象的行为,这样所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式。
notify()
参考资料:
nc观察者模式 | 菜鸟教程
创建Watcher在模型中监听视图中出现的占位符/表达式的每一个成员
常见的软件架构举例
三层架构
层次化架构是利用面向接口编程的原则将层次化的结构型设计模式作为软件的主体结构。
MVC架构----中介者模式
MVC即为Model-View-Controller(模型-视图-控制器),MVC是一种设计模式,以MVC设计模式为主体结构实现的基础代码框架一般称为MVC框架
MVC中M、V和C所代表的含义如下:
Model(模型)代表一个存取数据的对象及其数据模型。
View(视图)代表模型包含的数据的表达方式,一般表达为可视化的界面接口。
Controller(控制器)作用于模型和视图上,控制数据流向模型对象,并在数据变化时更新视图。控制器可以使视图与模型分离开解耦合。
模型和视图有着业务层面的业务数据紧密耦合关系,控制器的核心工作就是业务逻辑处理,显然MVC架构和三层架构有着某种对应关系,但又不是层次架构的抽象接口依赖关系,因此为了体现它们的区别和联系,我们在MVC的结构示意图中将模型和视图上下垂直对齐表示它们内在的业务层次及业务数据的对应关系,而将控制器放在左侧表示控制器处于优先重要位置,放在模型和视图的中间位置是为了与三层架构对应与业务逻辑层处于相似的层次。
为了包容需求上的变化而导致的用户界面的修改不会影响软件的核心功能代码,可以采用将模型(Model)、视图(View)和控制器(Controller)相分离的思想。采用MVC设计模式的话往往决定了整个软件的主体结构,因此我们称该软件为MVC架构。
模型用来封装核心数据和功能,它独立于特定的输出表示和输入行为,是执行某些任务的代码,至于这些任务以什么形式显示给用户,并不是模型所关注的问题。模型只有纯粹的功能性接口,也就是一系列的公开方法,这些方法有的是取值方法,让系统其它部分可以得到模型的内部状态,有的则是写入更新数据的方法,允许系统的其它部分修改模型的内部状态。
视图用来向用户显示信息,它获得来自模型的数据,决定模型以什么样的方式展示给用户。同一个模型可以对应于多个视图,这样对于视图而言,模型就是可重用的代码。一般来说,模型内部必须保留所有对应视图的相关信息,以便在模型的状态发生改变时,可以通知所有的视图进行更新。
控制器是和视图联合使用的,它捕捉鼠标移动、鼠标点击和键盘输入等事件,将其转化成服务请求,然后再传给模型或者视图。软件的用户是通过控制器来与系统交互的,他通过控制器来操纵模型,从而向模型传递数据,改变模型的状态,并最后导致视图的更新。
应用MVC架构的软件其基本的实现过程
控制器创建模型;
控制器创建一个或多个视图,并将它们与模型相关联;
控制器负责改变模型的状态;
当模型的状态发生改变时,模型会通知与之相关的视图进行更新。
MVVM架构
即 Model-View-ViewModel
优点:
-
低耦合。视图(View)可以独立于Model变化和修改,一个ViewModel可以绑定到不同的"View"上,当View变化的时候Model可以不变,当Model变化的时候View也可以不变。
-
可重用性。你可以把一些视图逻辑放在一个ViewModel里面,让很多View重用这段视图逻辑。
-
独立开发。开发人员可以专注于业务逻辑和数据的开发(ViewModel),设计人员可以专注于页面设计。
-
可测试。界面素来是比较难于测试的,测试可以针对ViewModel来写。
MVVM框架与MVC框架的区别
mvc 和 mvvm 其实区别并不大。都是一种设计思想,主要区别如下:
1.mvc 中 Controller演变成 mvvm 中的 viewModel
2.mvvm 通过数据来驱动视图层的显示而不是节点操作。
3.mvc中Model和View是可以直接打交道的,造成Model层和View层之间的耦合度高。而mvvm中Model和View不直接交互,而是通过中间桥梁ViewModel来同步
4.mvvm主要解决了:mvc中大量的DOM 操作使页面渲染性能降低,加载速度变慢,影响用户体验
创建Watcher在模型中监听视图中出现的占位符/表达式的每一个成员
将Compiler的解析结果,与Observer所观察的对象连接起来建立关系,在Observer观察到对象数据变化时,接收通知,同时更新DOM,称之为Watcher;
软件架构风格与描述方法
大多数的设计工作都是通过复用(Reuse)相似项目的解决方案,两种复用方法:
-
克隆(Cloning),完整地借鉴相似项目的设计方案,甚至代码,只需要完成一些细枝末节处的修改适配工作。
-
重构(Refactoring),构建软件架构模型的基本方法,通过指引我们如何进行系统分解,并在参考已有的软件架构模型的基础上逐步形成系统软件架构的一种基本建模方法。
软件架构的重要性
-
首先,软件架构模型有助于项目成员从整体上理解整个系统;
-
其次,给复用提供了一个高层视图,既可以辅助决定从其他系统中复用设计或组件,也给我们构建的软件架构模型未来的复用提供了更多可能性;
-
再次,软件架构模型为整个项目的构建过程提供了一个蓝图,贯穿于整个项目的生命周期;
-
最后,软件架构模型有助于理清系统演化的内在逻辑、有助于跟踪分析软件架构上的依赖关系、有助于项目管理决策和项目风险管理等。
构建软件架构模型的基本方法就是在不同层次上分解(decomposition)系统并抽象出其中的关键要素。
分解
-
面向功能的分解方法,用例建模即是一种面向功能的分解方法;
-
面向特征的分解方法,根据数量众多的某种系统显著特征在不同抽象层次上划分模块的方法;
-
面向数据的分解方法,在业务领域建模中形成概念业务数据模型即应用了面向数据的分解方法;
-
面向并发的分解方法,在一些系统中具有多种并发任务的特点,那么我们可以将系统分解到不同的并发任务中(进程或线程),并描述并发任务的时序交互过程;
-
面向事件的分解方法,当系统中需要处理大量的事件,而且往往事件会触发复杂的状态转换关系,这时系统就要考虑面向事件的分解方法,并内在状态转换关系进行清晰的描述;
-
面向对象的分解方法,是一种通用的分析设计范式,是基于系统中抽象的对象元素在不同抽象层次上分解的系统的方法。
分解和视图
在合理的分解和抽象基础上抽取系统的关键要素,进一步描述关键要素之间的关系,比如面向数据分解之后形成的数据关系模型,都是软件架构模型中的某种关键视图(Views)。
软件架构模型是通过一组关键视图来描述的,同一个软件架构,由于选取的视角不同(Perspective)可以得到不同的视图。一般来说,我们常用的几种视图有分解视图、依赖视图、泛化视图、执行视图、实现视图、部署视图和工作任务分配视图。
软件架构风格与策略
管道-过滤器
管道-过滤器风格的软件架构是面向数据流的软件体系结构,最典型的应用是编译系统。 管道-过滤器风格示意图,对源代码处理的过滤器通过管道连接起来,实现了端到端的从源代码到编译目标的完整系统。
客户-服务
Client/Server(C/S)和Browser/Server(B/S)是我们常用的对软件的网络结构特点的表述方式。
客户-服务模式的架构风格是指客户代码通过请求和应答的方式访问或者调用服务代码。这里的请求和应答可以是函数调用和返回值,也可以是TCP Socket中的send和recv,还可以是HTTP协议中的GET请求和响应。
在客户-服务模式中,客户是主动的,服务是被动的。
客户-服务模式的架构风格具有典型的模块化特征,降低了系统中客户和服务构件之间耦合度,提高了服务构件的可重用性。
P2P
P2P(peer-to-peer)架构是客户-服务模式的一种特殊情形,P2P架构中每一个构件既是客户端又是服务端,即每一个构件都有一种接口,该接口不仅定义了构件提供的服务,同时也指定了向同类构件发送的服务请求。这样众多构件一起形成了一种对等的网络结构。
P2P架构典型的应用有文件共享网络、比特币网络等。
发布-订阅(观察者)
在发布-订阅架构中,有两类构件:发布者和订阅者。如果订阅者订阅了某一事件,则该事件一旦发生,发布者就会发布通知给该订阅者。观察者模式体现了发布-订阅架构的基本结构。
在实际应用中往往会需要不同的订阅组,以及不同的发布者。由于订阅者数量庞大往往在消息推送时采用消息队列的方式延时推送。
CRUD
CRUD 是创建(Create)、 读取(Read)、更新(Update)和删除(Delete)四种数据库持久化信息的基本操作的助记符,表示对于存储的信息可以进行这四种持久化操作。CRUD也代表了一种围绕中心化管理系统关键数据的软件架构风格。一般常见的各类信息系统,比如ERP、CRM、医院信息化平台等都可以用CRUD架构来概括。
层次化
较为复杂的系统中的软件单元,仅仅从平面展开的角度进行模块化分解是不够的,还需要从垂直纵深的角度将软件单元按层次化组织,每一层为它的上一层提供服务,同时又作为下一层的客户。
通信网络中的OSI(Open System Interconnection)参考模型是典型的层次化架构风格,在OSI参考模型中每一层都将相邻底层提供的通信服务抽象化,隐藏它的实现细节,同时为相邻的上一层提供服务。
软件架构的描述方法
-
分解视图 Decomposition View
-
依赖视图 Dependencies View(关系)
-
泛化视图 Generalization View(继承、组合)
-
执行视图 Execution View(时序)
-
实现视图 Implementation View(代码)
-
部署视图 Deployment View
-
工作任务分配视图 Work-assignment View
1 分解视图
分解是构建软件架构模型的关键步骤,分解视图也是描述软件架构模型的关键视图,一般分解视图呈现为较为明晰的分解结构(breakdown structure)特点。分解视图用软件模块勾划出系统结构,往往会通过不同抽象层级的软件模块形成层次化的结构。
-
子系统(Subsystem),一个系统可能有一些列子系统组成;
-
包(Package),子系统又由包组成;
-
类(Class),包又由类组成;
-
组件(Component),一般用来表示一个运行时的单元;
-
库(Library)是具有明确定义的接口的共享软件代码的集合,可以是代码库,也可以是由代码库编译打包后的静态库,还可以构建成动态链接库;
-
软件模块(Module)用来指软件代码的结构化单元,模块化(modular)是在软件架构中各部分都被明确定义的接口所描述时使用,也就是可以明确无误地指定各部分的外部可见行为。
-
软件单元(Software unit)是在不明确该部分的类型时使用。
2 依赖视图
依赖视图展现了软件模块之间的依赖关系。比如一个软件模块A调用了另一个软件模块B,那么我们说软件模块A直接依赖软件模块B。如果一个软件模块依赖另一个软件模块产生的数据,那么这两个软件模块也具有一定的依赖关系。
依赖视图在项目计划中有比较典型的应用。比如它能帮助我们找到没有依赖关系的软件模块或子系统,以便独立开发和测试,同时进一步根据依赖关系确定开发和测试软件模块的先后次序。
3 泛化视图
泛化视图展现了软件模块之间的一般化或具体化的关系,典型的例子就是面向对象分析和设计方法中类之间的继承关系。值得注意的是,采用对象组合替代继承关系,并不会改变类之间的泛化特征。因此泛化是指软件模块之间的一般化或具体化的关系,不能局限于继承概念的应用。
泛化视图有助于描述软件的抽象层次,从而便于软件的扩展和维护。比如通过对象组合或继承很容易形成新的软件模块与原有的软件架构兼容。
4 执行视图
执行视图展示了系统运行时的时序结构特点,比如流程图、时序图等。执行视图中的每一个执行实体,一般称为组件(Component),都是不同于其他组件的执行实体。如果有相同或相似的执行实体那么就把它们合并成一个。
执行实体可以最终分解到软件的基本元素和软件的基本结构,因而与软件代码具有比较直接的映射关系。在设计与实现过程中,我们一般将执行视图转换为伪代码之后,再进一步转换为实现代码。
5 实现视图
实现视图是描述软件架构与源文件之间的映射关系
通过目录和源文件的命名来对应软件架构中的包、类等静态结构单元,这样典型的实现视图就可以由软件项目的源文件目录树来呈现。
实现视图有助于码农在海量源代码文件中找到具体的某个软件单元的实现。实现视图与软件架构的静态结构之间映射关系越是对应的一致性高,越有利于软件的维护,因此实现视图是一种非常关键的架构视图。
6 部署视图
部署视图是将执行实体和计算机资源建立映射关系。这里的执行实体的粒度要与所部署的计算机资源相匹配,比如以进程作为执行实体那么对应的计算机资源就是主机,这时应该描述进程对应主机所组成的网络拓扑结构,这样可以清晰地呈现进程间的网络通信和部署环境的网络结构特点。
部署视图有助于设计人员分析一个设计的质量属性,比如软件处理网络高并发的能力、软件对处理器的计算需求等。
7 工作分配视图
工作分配视图将系统分解成可独立完成的工作任务,以便分配给各项目团队和成员。分配视图对于进度规划、项目评估和经费预算都能起到有益的作用。
每个视图都是从不同的角度对软件架构进行描述和建模,比如从功能的角度、从代码结构的角度、从运行时结构的角度、从目录文件的角度,或者从项目团队组织结构的角度。
高质量软件
软件质量的含义
IEEE将软件质量定义为,一个系统、组件或过程符合指定要求的程度,或者满足客户或用户期望的程度
产品视角下的软件质量
McCall软件质量模型
主要面向的是系统开发人员和系统开发过程。通过一系列的软件质量属性指标来弥合开发人员与最终用户之间的鸿沟。McCall 质量模型从三个角度来定义和识别软件产品的质量:
• • Product revision (ability to change).
• • Product transition (adaptability to new environments).
• • Product operations (basic operational characteristics).
三个角度总结出了11个质量要素,用来描述软件的外部视角,也就是客户或使用者的视角;这11个质量要素又关联着23个质量标准,用来描述软件的内部视角,也就是开发人员的视角。
质量的生命周期
在外部和内部的软件产品质量基础上给出了质量的生命周期,向前是过程质量,向后是使用质量。使用质量是在特定的使用场景中,软件产品使得特定用户能达到有效性、生产率、安全性和满意度的特定目标的能力
过程视角下的软件质量(管理)
软件过程主要是指开发和维护的过程,过程质量和产品质量同样重要,因此也需要对此仔细地建模、研究和分析。过程质量更关注持续不断的过程改进,因此过程质量模型一般称为过程改进模型
CMM/CMMI
CMM/CMMI的全称为能力成熟度模型(Capability Maturity Model)或能力成熟度模型集成(Capability Maturity Model Integration),评估软件能力与成熟度的一套标准,它侧重于软件开发过程的管理及工程能力的提高与评估,是国际软件业的质量管理标准
CMMI共有5个级别,代表软件团队能力成熟度的5个等级,数字越大,成熟度越高,高成熟度等级表示有比较强的软件综合开发能力。
-
CMMI一级,初始级。在初始级水平上,软件组织对项目的目标与要做的努力很清晰,项目的目标可以实现。但是由于任务的完成带有很大的偶然性,软件组织无法保证在实施同类项目时仍然能够完成任务。项目实施能否成功主要取决于实施人员。
-
CMMI二级,管理级。在管理级水平上,所有第一级的要求都已经达到,另外,软件组织在项目实施上能够遵守既定的计划与流程,有资源准备,权责到人,对项目相关的实施人员进行了相应的培训,对整个流程进行监测与控制,并联合上级单位对项目与流程进行审查。二级水平的软件组织对项目有一系列管理程序,避免了软件组织完成任务的偶然性,保证了软件组织实施项目的成功率。
-
CMMl三级,已定义级。在已定义级水平上,所有第二级的要求都已经达到,另外,软件组织能够根据自身的特殊情况及自己的标准流程,将这套管理体系与流程予以制度化。这样,软件组织不仅能够在同类项目上成功,也可以在其他项目上成功。科学管理成为软件组织的一种文化,成为软件组织的财富。
-
CMMI四级,量化管理级。在量化管理级水平上,所有第三级的要求都已经达到,另外,软件组织的项目管理实现了数字化。通过数字化技术来实现流程的稳定性,实现管理的精度,降低项目实施在质量上的波动。
-
CMMI五级,持续优化级。在持续优化级水平上,所有第四级的要求都已经达到,另外,软件组织能够充分利用信息资料,对软件组织在项目实施的过程中可能出现的问题予以预防。能够主动地改善流程,运用新技术,实现流程的优化。
有两种通用的评估方法用以评估组织软件过程的成熟度:软件过程评估和软件能力评价。
-
软件过程评估:用于确定一个组织当前的软件工程过程状态及组织所面临的软件过程的优先改善问题,为组织领导层提供报告以获得组织对软件过程改善的支持。软件过程评估集中关注组织自身的软件过程,在一种合作的、开放的环境中进行。评估的成功取决于管理者和专业人员对组织软件过程改善的支持。
——软件过程改进是一个持续的、全员参与的过程
-
软件能力评价:用于识别合格的软件承包商或者监控软件承包商开发软件的过程状态。软件能力评价集中关注识别在预算和进度要求范围内完成开发出高质量的软件产品的软件合同及相关风险。评价在一种审核的环境中进行,重点在于揭示组织实际执行软件过程的文档化的审核记录。
——评估过程主要分成三个阶段:准备阶段、评估阶段和报告阶段
CMMI共有25个过程域
价值视角下的软件质量(商业环境)
新项目的估值:一个预估市场规模,一个是预估开发成本。
重要的软件质量属性(重要性从大到小)
-
易于修改维护(Modifiability)——包容变化:高内聚(通用性)低耦合(接口)的模块化设计
-
良好的性能表现(Performance)——响应时间、吞吐量、负载
提高策略:
提高资源的利用率
更有效地管理资源分配
先到先得:按收到请求的顺序处理
显式优先级:按其分配优先级的顺序处理请求
最早截止时间优先:按收到请求的截止时间的顺序处理请求
减少对资源的需求
-
安全性(Security)——系统的免疫力(Immunity)(安全漏洞)和系统的自我恢复能力(Resilience)(在软件设计中要包含异常检测机制,一旦发现攻击导致的异常能启动自我恢复程序)。
-
可靠性(Reliability)——如果软件系统在假定的条件下能正确执行所要求的功能,则软件系统是可靠的(reliable)。可靠性与软件内部是否有缺陷(Fault)密切相关
与故障(Failure)相比,缺陷是人为错误(Human Error)的结果,而故障是可观察到的偏离要求的行为表现,是缺陷在某种条件下造成的系统失效
故障恢复的方法则是根据系统设计中创建的应急方案执行撤销、回退、备份、服务降级、修复或报告等。
被动缺陷检测,等待执行期间发生故障。
主动缺陷检测:定期检查症状或尝试预测故障何时发生。
-
健壮性(Robustness)——适应环境或具有故障恢复等机制,可靠性和软件内部是否有缺陷有关,而健壮性与软件容忍错误或外部环境异常时的表现有关
-
易用性(Usability)——用户操作软件的容易程度
-
商业目标(Business goals)
外部购买还是独立构建;开发成本和维护成本;采用新技术还是采用已知的成熟技术?
CH5 软件危机和软件过程
软件危机
没有银弹——断言“在10年内无法找到解决软件危机的杀手锏(银弹)。
软件概念结构(conceptual structure)的复杂性,无法达成软件概念的完整性和一致性,自然无法从根本上解决软件危机带来的困境。
软件过程模型
软件的生命周期概述
软件的生命周期划分为:分析、设计、实现、交付和维护这么五个阶段。
-
分析阶段的任务是需求分析和定义,比如在敏捷统一过程中用例建模和业务领域建模就属于分析阶段。分析阶段一般会在深入理解业务的情况下,形成业务概念原型,业务概念原型是业务功能和业务数据模型的有机统一体。
-
设计阶段分为软件架构设计和软件详细设计,前者一般和分析阶段联系紧密,一般合称为“分析与设计”;后者一般和实现阶段联系紧密,一般合称为“设计与实现”。
-
实现阶段分为编码和测试,其中测试又涉及到单元测试、集成测试、系统测试等。
-
交付阶段主要是部署、交付测试和用户培训等。
-
维护阶段一般是软件生命周期中持续时间最长的一个阶段,而且在维护阶段很可能会形成单独的项目,从而经历分析、设计、实现、交付几个阶段,最终又合并进维护阶段。
软件的故障率曲线
软件开发过程从形成软件概念原型到实现、交付使用和维护的整个过程,软件的故障率有着一定的规律,软件在维护阶段往往会出现故障率上升的情况。
软件过程又分为描述性的(descriptive)过程和说明性的(prescriptive)过程
描述性的过程和说明性的过程
描述性的过程试图客观陈述在软件开发过程中实际发生什么。比如测试时发现了一个bug是对需求的错误理解造成的,那必须返回到分析阶段重新调整软件概念模型,比如用户使用过程中出现闪退现象,我们需要返回到系统测试试图重现闪退,乃至回到设计阶段调整设计方案从根本上解决闪退的根源问题
说明性的过程试图主观陈述在软件开发过程中应该会发生什么。显然说明性的过程是抽象的过程模型,有利于整个软件项目团队对软件开发过程形成一致的理解,能够在与实际软件开发过程比较时找出项目过程中的问题。
不同的模型适用于不同的情况,我们常见的过程模型,比如瀑布模型、V模型、原型化模型等都有它们所能达到的过程目标和适用的情况。
瀑布模型
瀑布模型(Waterfall Model)是第一个软件过程开发模型,对于能够完全透彻理解的需求且几乎不会发生需求变更的项目瀑布模型是适用的。瀑布模型能够将软件开发过程按顺序组织过程活动,非常简单和易于理解,因此瀑布模型被广泛应用于解释项目进展情况及所处的阶段。瀑布模型中的主要阶段通过里程碑(milestones)和交付产出来划分的。
瀑布模型是一个过程活动的顺序结构,没有任何迭代,而大多数软件开发过程都会包含大量迭代过程。瀑布模型不能为处理开发过程中的变更提供任何指导意义
原型化的瀑布模型
显然瀑布模型会将整个软件开发过程中的众多风险积累到最后才能暴露出来,为了尽早暴露风险和控制风险,在瀑布模型的基础上增加一个原型化(prototyping)阶段,可以有效将风险前移,改善整个项目的技术和管理上的可控性。
比较常见的有用户接口原型和软件架构原型。
-
在需求分析阶段,原型可能是软件的用户接口部分,比如用户交互界面,用户接口原型可以有效地整理需求,在需求分析的过程提供直观的反馈形式,有利于确认需求是否被准确理解。
-
在设计阶段,原型可能是软件架构的关键部分,比如采用某种设计模型解决某个问题,软件架构原型可以有效地评估软件设计方案是否能够有效解决特定问题,有利于验证技术方案的可行性,为大规模投入开发提供技术储备和经验积累。
V模型
V模型也是在瀑布模型基础上发展出来的,我们发现单元测试、集成测试和系统测试是为了在不同层面验证设计,而交付测试则是确认需求是否得到满足。也就是瀑布模型中前后两端的过程活动具有内在的紧密联系,如果将模块化设计的思想拿到软件开发过程活动的组织中来,可以发现通过将瀑布模型前后两端的过程活动结合起来,可以提高过程活动的内聚度,从而改善软件开发效率。这就是V模型。
生死相依原则:开始一项工作之前,先去思考验证该工作完成的方法
比如创建一个对象和销毁一个对象的代码成对出现便于代码的组织和管理,
V模型是开始一个特定过程活动和评估该特定过程的过程活动成对出现,从而便于软件开发过程的组织和管理
分阶段的增量和迭代开发过程
分阶段开发可以让客户在没有开发完成之前就可以使用部分功能,也就是每次可以交付系统的一小部分,从而缩短开发迭代的周期。
分阶段开发的交付策略分为两种,一是增量开发,二是迭代开发:
-
增量开发就是从一个功能子系统开始交付,每次交付会增加一些功能,这样逐步扩展功能最终完成整个系统功能的开发。
-
迭代开发是首先完成一个完整的系统或者完整系统的框架,然后每次交付会升级其中的某个功能子系统,这样反复迭代逐步细化最终完成系统开发。
优点:
-
能够在系统没有开发完成之前,开始进行交付和用户培训;
-
频繁的软件发布可以让开发者敏捷地应对始料未及的问题;
-
开发团队可以在不同的版本聚焦于不同的功能领域,从而提升开发效率;
-
还有助于提前布局抢占市场。
螺旋模型
兼顾了快速原型的迭代的特征以及瀑布模型的系统化与严格监控。螺旋模型最大的特点在于引入了其他模型不具备的风险管理,使软件在无法排除重大风险时有机会停止,以减小损失。同时,在每个迭代阶段构建原型是螺旋模型用以减小风险的基本策略。
每一次迭代过程分为四个主要阶段:
-
Plan
-
Determine goals, alternatives and constraints
-
Evaluate alternatives and risks
-
Develop and test
个人软件过程PSP(过程模型)
PSP提供了一个不断成长进阶的参考路径,即个人软件过程PSP框架。
•从个软件过程PSP框架的概要描述中,可以清楚地看到,如何作好项目规划和如何保证产品质量,是任何软件开发过程中最基本的问题。
•PSP可以帮助软件工程师在运用软件过程的方法和原则,借助于一些度量和分析工具,了解自己的技能水平,控制和管理自己的工作方式,使自己日常工作中的评估、计划和预测更加准确、更加有效,进而改进个人的工作表现,提高个人的工作质量和产量,积极而有效地参与高级管理人员和过程人员推动的团队范围的软件工程过程改进。
•个体软件过程PSP为软件工程师提供了发展个人技能的结构化框架和必须掌握的方法。在软件行业,开发人员如果不经过PSP训练,就只能靠在开发中通过实践逐步摸索掌握这些技能和方法,这不仅周期很长,而且要付出很大的代价。
团队软件过程TSP
软件团队的组织分为高度结构化的组织和松散结构化的组织
团队必须计划项目、跟踪进展、协调工作,还必须有一致的工作目标,共同的工作过程,并且经常自由沟通。
项目失败最根本的原因是团队问题。
- 缺乏有效的领导和管理;
- 不能做出妥协、安排或不善于合作;
- 缺少参与;
- 拖拉与缺乏信心;
- 质量低劣;
- 功能多余;
- 无效的组员互评;
团队的基本要素
-
团队规模
-
团队的凝聚力
-
团队协作的基本条件
敏捷方法
很多软件都是通过网络服务器端实现的,有各种方便的推送渠道快速直达客户端。互联网使得知识的获取变得更加容易,很多软件可以由一个小团队来实现。同时,技术更新的速度在加快,用户需求的变化也在加快,开发流程必须跟上这些快速变化的节奏。
敏捷宣言
-
个体和互动 高于 流程和工具
-
工作的软件 高于 详尽的文档
-
客户合作 高于 合同谈判
-
响应变化 高于 遵循计划
敏捷方法所遵循的原则
最重要的目标,是通过持续不断地及早交付有价值的软件使客户满意。
面对需求变化,即使在开发后期也一样。为了客户的竞争优势,敏捷过程掌控变化。
经常地交付可工作的软件,倾向于采取较短的周期。
业务人员和开发人员必须相互合作,项目中的每一天都不例外。
激发个体的斗志,以他们为核心搭建项目。
Scrum敏捷开发方法
Scrum是一种迭代的增量软件项目管理方法,是敏捷方法中最为常见的软件开发模型之一
在Scrum中将团队角色分为:项目经理(Scrum Master)、产品经理(Product Owner)和团队(Team)。
Scrum中每一轮迭代称为一个冲刺(Sprint),每个冲刺包括如下活动形式:
-
• • 冲刺规划会议(Sprint Plan Meeting)
•确定并细分每一个索引卡的故事(Story)
-
• • 每日站立会议(Scrum Daily Meeting)
-
• • 冲刺评审会议(Sprint Review Meeting)
演示是跨团队的,会产生不同团队之间的交流
不要关注太多的细节,以主要的功能为主
让老板和客户看到演示效果
刺评审会议非常的重要,绝对不可以被忽略
-
• • 冲刺回顾会议(Sprint Retrospective Meeting)
基本流程
•第一步:找出完成产品需要做的事情 — Product Backlog。产品经历领导大家对于这个Backlog中的条目进行分析、细化、理清相互关系,估计工作量等工作。每一项工作的时间估计单位为“天”。
•第二步:决定当前的冲刺(Sprint)需要解决的事情 — Sprint Backlog。 整个产品的实现被划分为几个互相联系的冲刺(Sprint)。订单上的任务是团队成员根据自己的情况来认领。团队成员能主导任务的估计和分配,他们的主观能动性得到较大的发挥。
•第三步:冲刺(Sprint)。团队按照backlog任务执行。在冲刺阶段,外部人士不能直接打扰团队成员。一切交流只能通过项目经理(Scrum Master)来完成。
•第四步:得到软件的一个增量版本,冲刺评审会议,发布给用户。然后在此基础上又进一步计划增量的新功能和改进。
总结:
• • 全员规划,分块并行
• • 文档为纲,当面交流
• • 迭代开发,分块检查,持续交付
• • 优先开发,讲究实效
DevOps
一套旨在缩短从提交变更到变更后的系统投入正常生产之间的时间,同时确保产品高质量的实践方法
可以把DevOps看作开发(软件工程)、技术运营和质量保障(QA)三者的交集。
DevOps看成是敏捷方法从技术开发领域扩展到业务运维领域,也就是实现业务上全周期的敏捷性,在业务运营者作出决策、开发者进行响应和IT运维上线部署之间能够紧密互动和快速反馈,从而形成与业务需求始终努力保持一致的持续改进过程。
DevOps使得敏捷方法的优势可以体现在整个企业业务组织机构层面。通过实现反应灵敏且稳定部署持续交付的业务运维,使其能够与开发过程的创新保持同步,DevOps可以做到整个业务实现过程的敏捷性。
DevOps和精益原则
精益生产(追求零库存、追求快速反应、把企业的内部活动和外部的市场(顾客)需求和谐地统一于企业的发展目标、强调人力资源的重要性);精益创业(提升效益;全过程、全员化、标准化、责任化);最小可行产品(MVP,Minimum Viable Product)(把产品最核心的功能用最小的成本实现出来(或者描绘出来),然后快速征求用户意见获得反馈进行改进优化)
在敏捷和精益原则的指导下,全栈自动化(Full Stack Automation)是DevOps得以实现的重要支撑。
总结
-
为了应对软件危机,首先想到的是通过简化和抽象的方法“就事论事”地处理软件本身的问题,从而诞生了结构化程序设计、面向对象分析和设计、模块化方法、设计模式、软件架构等一系列技术。这些技术本质上都是通过对软件本身的抽象来有效管控软件的复杂性。但在大型复杂软件系统中,这些技术依然力有不逮。
-
行有不得,反求诸己。难以为复杂软件建立完整且一致的抽象概念模型,这一本质问题显现出来后,逐渐认识到相对于软件本身的管理这一局部问题,项目管理上的全局问题是更为主要的矛盾,因此将软件过程改进纳入到应对软件危机的视野中,从而提出了各种软件生命周期模型及软件过程改进方法,以PSP和TSP的基本方法为支撑的CMM/CMMI软件成熟度模型最具有代表性。
-
随着互联网、移动互联网以及虚拟化、云计算等技术的发展,软件要依赖的环境发生显著变化,当然这些变化本身也是软件塑造的结果。软件从复杂单体软件的以架构为中心向微服务架构的分布式软件转变,软件过程从CMM/CMMI向敏捷方法和DevOps转变。
-
重构作为编程的一种基本方法得到业界的普遍认同和采纳;微服务结构则有利于在更高的设计抽象层级上对软件进行重构;敏捷方法则进一步有利于在软件开发过程层面进行迭代和重构;DevOps则终极性地在业务、运维和效益层面进行快速迭代重构。
参考资料《代码中的软件工程》代码中的软件工程: 《代码中的软件工程》一书的配套ppt和源代码
学号:095